循环神经网络(RNN),长短期记忆(LSTM),这些红得发紫的神经网络——是时候抛弃它们了!
LSTM和RNN被发明于上世纪80、90年代,于2014年死而复生。接下来的几年里,它们成为了解决序列学习、序列转换(seq2seq)的方式,这也使得语音到文本识别和Siri、Cortana、Google语音助理、Alexa的能力得到惊人的提升。
另外,不要忘了机器翻译,包括将文档翻译成不同的语言,或者是神经网络机器翻译还可以将图像翻译为文本,文字到图像和字幕视频等等。
在接下来的几年里,ResNet出现了。ResNet是残差网络,意为训练更深的模型。2016年,微软亚洲研究院的一组研究员在ImageNet图像识别挑战赛中凭借惊人的152层深层残差网络(deep residual networks),以绝对优势获得图像分类、图像定位以及图像检测全部三个主要项目的冠军。之后,Attention(注意力)模型出现了。
虽然仅仅过去两年,但今天我们可以肯定地说:
“不要再用RNN和LSTM了,它们已经不行了!”
让我们用事实说话。Google、Facebook、Salesforce等企业越来越多地使用了基于注意力模型(Attention)的网络。
所有这些企业已经将RNN及其变种替换为基于注意力的模型,而这仅仅是个开始。比起基于注意力的模型,RNN需要更多的资源来训练和运行。RNN命不久矣。
为什么
记住RNN和LSTM及其衍生主要是随着时间推移进行顺序处理。请参阅下图中的水平箭头:
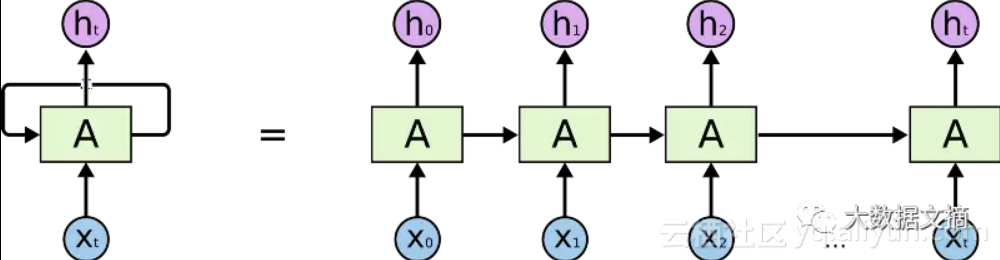
RNN中的顺序处理
水平箭头的意思是长期信息需在进入当前处理单元前顺序遍历所有单元。这意味着其能轻易被乘以很多次<0的小数而损坏。这是导致vanishing gradients(梯度消失)问题的原因。
为此,今天被视为救星的LSTM模型出现了,有点像ResNet模型,可以绕过单元从而记住更长的时间步骤。因此,LSTM可以消除一些梯度消失的问题。
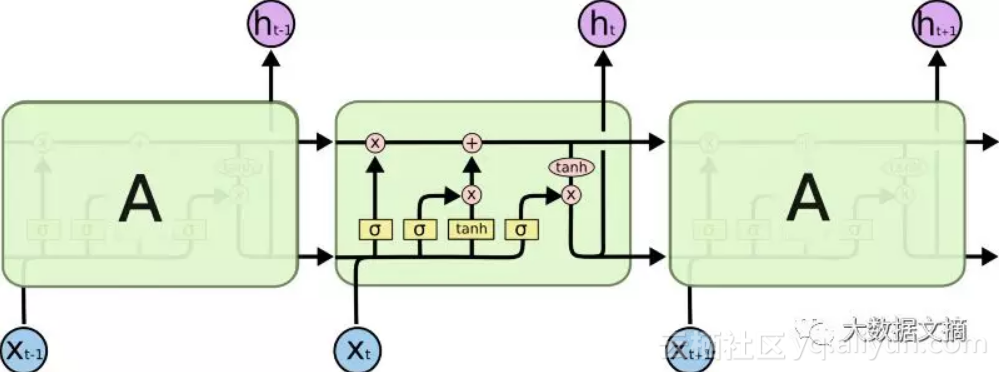
LSTM中的顺序处理
从上图可以看出,这并没有解决全部问题。我们仍然有一条从过去单元到当前单元的顺序路径。事实上,这条路现在更复杂了,因为它有附加物,并且忽略了隶属于它上面的分支。
毫无疑问LSTM和GRU(Gated Recurrent Uni,是LSTM的衍生)及其衍生能够记住大量更长期的信息!但是它们只能记住100个量级的序列,而不是1000个量级,或者更长的序列。
还有一个RNN的问题是,训练它们对硬件的要求非常高。另外,在我们不需要训练这些网络快速的情况下,它仍需要大量资源。同样在云中运行这些模型也需要很多资源。
考虑到语音到文本的需求正在迅速增长,云是不可扩展的。我们需要在边缘处进行处理,比如Amazon Echo上处理数据。
该做什么?
如果要避免顺序处理,那么我们可以找到“前进”或更好“回溯”单元,因为大部分时间我们处理实时因果数据,我们“回顾过去”并想知道其对未来决定的影响(“影响未来”)。在翻译句子或分析录制的视频时并非如此,例如,我们拥有完整的数据,并有足够的处理时间。这样的回溯/前进单元是神经网络注意力(Neural Attention)模型组。
为此,通过结合多个神经网络注意力模型,“分层神经网络注意力编码器”出现了,如下图所示:
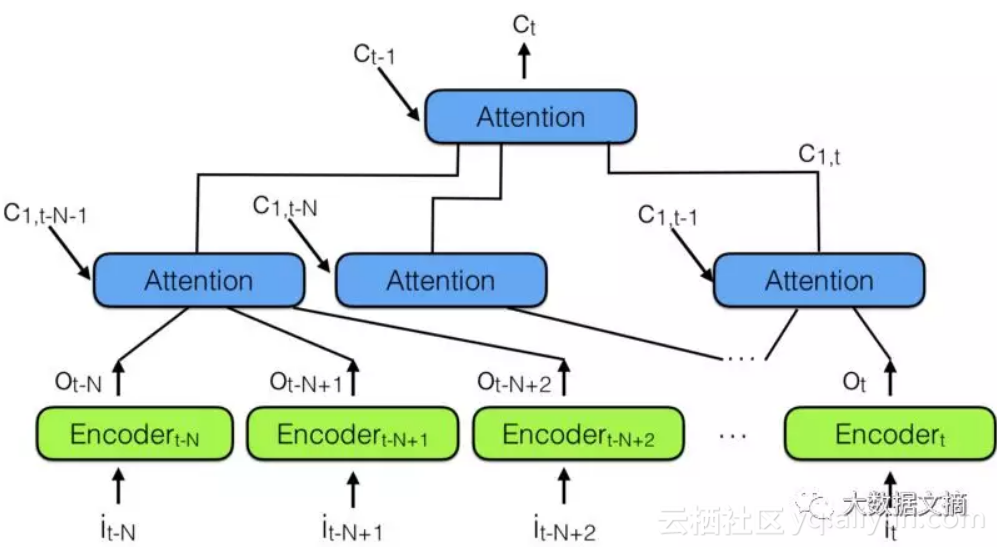
分层神经网络注意力编码器
“回顾过去”的更好方式是使用注意力模型将过去编码向量汇总到语境矢量 CT中。
请注意上面有一个注意力模型层次结构,它和神经网络层次结构非常相似。这也类似于下面的备注3中的时间卷积网络(TCN)。
在分层神经网络注意力编码器中,多个注意力分层可以查看最近过去的一小部分,比如说100个向量,而上面的层可以查看这100个注意力模块,有效地整合100 x 100个向量的信息。这将分层神经网络注意力编码器的能力扩展到10,000个过去的向量。
这才是“回顾过去”并能够“影响未来”的正确方式!
但更重要的是查看表示向量传播到网络输出所需的路径长度:在分层网络中,它与log(N)成正比,其中N是层次结构层数。这与RNN需要做的T步骤形成对比,其中T是要记住的序列的最大长度,并且T >> N。
跳过3-4步追溯信息比跳过100步要简单多了!
这种体系结构跟神经网络图灵机很相似,但可以让神经网络通过注意力决定从内存中读出什么。这意味着一个实际的神经网络将决定哪些过去的向量对未来决策有重要性。
但是存储到内存怎么样呢?上述体系结构将所有先前的表示存储在内存中,这与神经网络图灵机(NTM)不同。这可能是相当低效的:考虑将每帧的表示存储在视频中——大多数情况下,表示向量不会改变帧到帧,所以我们确实存储了太多相同的内容!
我们可以做的是添加另一个单元来防止相关数据被存储。例如,不存储与以前存储的向量太相似的向量。但这确实只是一种破解的方法,最好的方法是让应用程序指导哪些向量应该保存或不保存。这是当前研究的重点
看到如此多的公司仍然使用RNN/LSTM进行语音到文本的转换,我真的十分惊讶。许多人不知道这些网络是如此低效和不可扩展。
训练RNN和LSTM的噩梦
RNN和LSTM的训练是困难的,因为它们需要存储带宽绑定计算,这是硬件设计者最糟糕的噩梦,最终限制了神经网络解决方案的适用性。简而言之,LSTM需要每个单元4个线性层(MLP层)在每个序列时间步骤中运行。
线性层需要大量的存储带宽来计算,事实上,它们不能使用许多计算单元,通常是因为系统没有足够的存储带宽来满足计算单元。而且很容易添加更多的计算单元,但是很难增加更多的存储带宽(注意芯片上有足够的线,从处理器到存储的长电线等)。
因此,RNN/LSTM及其变种不是硬件加速的良好匹配,我们在这里之前和这里都讨论过这个问题。一个解决方案将在存储设备中计算出来,就像我们在FWDNXT上工作的一样。
总而言之,抛弃RNN吧。注意力模型真的就是你需要的一切!
原文发布时间为:2018-05-2
本文作者:文摘菌

