引出主题
近年来,深度学习之所以取得如此大的成功,主要在于目前拥有的海量数据和强大计算资源,尤其是在图像识别方面。因此,如何实现深度学习的快速学习,是深度学习研究的一大难题。
对于人而言,在识别物体的时候,仅需要少量图像或不需要图像,而根据对物体的描述就能基于以往的经验知识实现对物体的识别,这是为什么呢?因为我们有先验知识,我们会利用自己的先验知识来进行学习。例如,经常使用老式诺基亚手机的人也能很快地学会如何使用智能机。
如何实现这种快速学习呢?元学习就是实现方法之一。元学习,英文名叫 Meta Learning,也叫做 Learning to Learn,即学会学习。如何让神经网络实现元学习?这里提供了元学习的相关知识 [1]。
本文利用对比关系来实现元学习,作者认为人在识别图像时是通过比较图像与图像之间的特征来实现识别的,即少样本学习。
如对于刚出生没多久的小孩子来说,他们也能很快地识别出什么是“鸭”和“鹅”,即使他们并没有见过几次,因为我们的视觉细胞可以自动地提取图像的特征(如轮廓、光照等),然后对比我们以往的经验就能对图像进行识别了。这篇论文的 Relation Network(RN)就是根据这种思想设计的。
系统结构与方法
数据处理
本文将数据分为 training set、support set 和 testing set 三部分,其中 support set 作为对比学习的样例,它拥有和测试数据一样的标签,在测试过程中,可以通过与测试数据的对比来实现对测试数据的识别。
对于包含 C 个不同的类别,每个类别有 K 个样本的 support set,本文称其为 C-way,K-shot。为了实现对网络的训练,本文将 training set 分成和 support set 及 testing set,文中将其分别称为 sample set 与 query set。
模型
one-hot
本文提出的 RN 包含两部分,一部分为嵌入单元 fφ,用来提取图像的特征,另一部分为关联单元,用来计算两个图像的相似度,如图 1 所示。
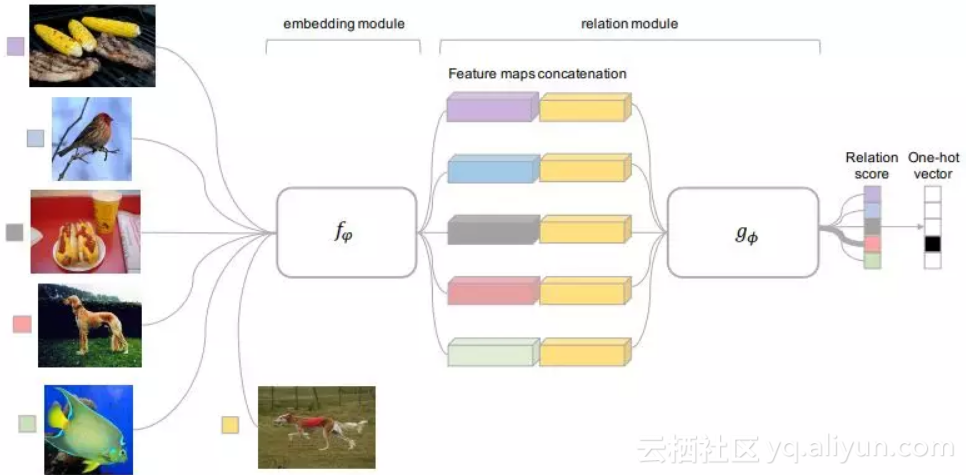
▲ 图1
这是一个明显的 5-way,1-shot 模型。在训练时,利用 training set 来对网络进行元学习,用 sample set 中的数据与 query set 中的数据做对比。在嵌入单元分别获得两者的特征、然后对特征进行连接后送入到关联单元计算关联系数,如公式 1 所示。
![]()
其中,fφ 代表嵌入单元,C(fφ(xi),fφ(xj)) 代表将特征连接一起,gϕ 代表连接单元。
K-shot
对于各类数据,如果仅有 K(K>1) 个样本,则将同一类的 feature_map 相加,few-shot 的网络模型下图所示。
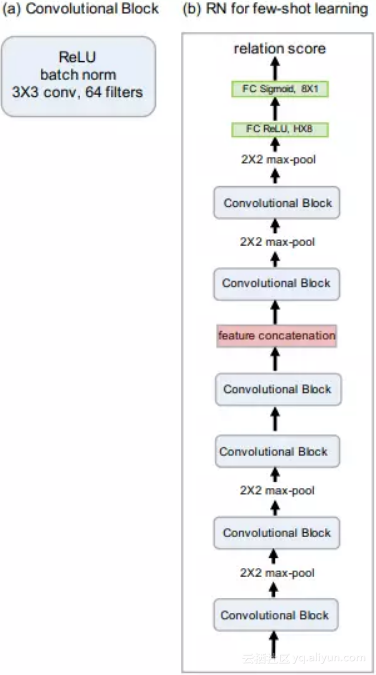
▲ 图2
Zero-shot
zero-shot 和 one-shot 类似,只不过这里将 support set 中的图像换成了语义向量,嵌入单元也做了修改。zero-shot 的网络结构如图 3 所示,DNN 表示训练好的模型,如 VGG、Inception 等。
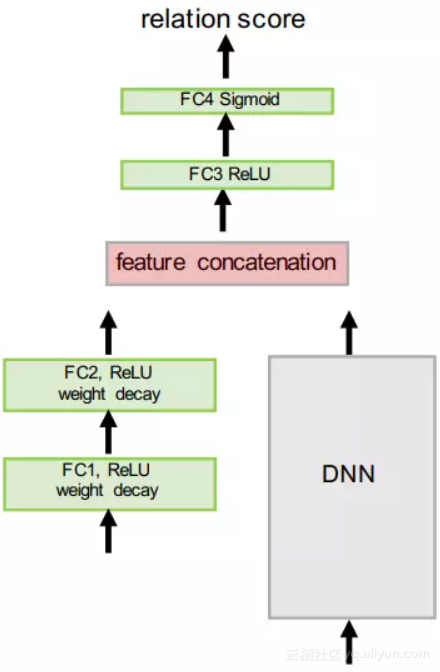
▲ 图3
实验结果与分析
作者分别在 Omniglot 和 miniImageNet 数据集上测试了 few-shot,在 Animals with Attributes (AwA) 和 Caltech-UCSD Birds-200-2011 (CUB) 上测试了 zero-shot。所有的程序都是基于 PyTorch 实现的。
Few-shot
Omniglot
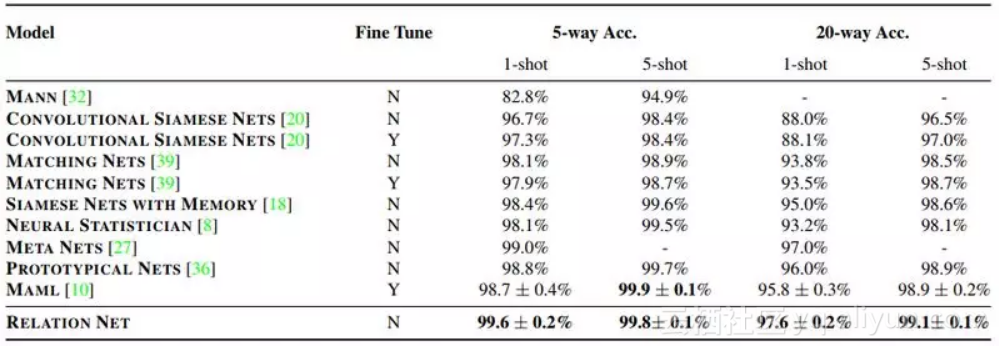
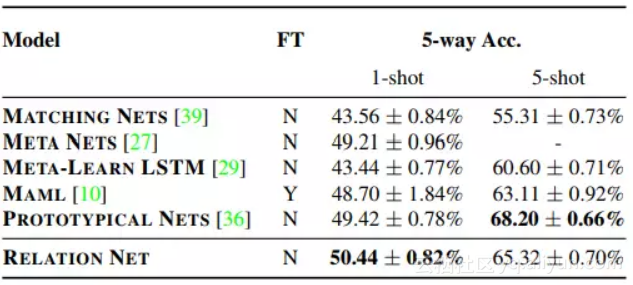
Omniglot 包含 50 个不同的字母,共计 1623 类字符,每一类由 20 个不同的人创作。为了增加数据量,本文还对图像进行了旋转变换,分别对 5-way 1-shot、5-way 5-shot、20-way 1-shot 和 20-way 5-shot 集中情况展开了实验,实验结果如下表所示。
miniImageNet
miniImageNet是从 ImageNet 分割得到的,具体分割方法参照 [2]。本文在 miniImageNet 上进行了 5 way 1-shot 及 5 way 5-shot 的实验,实验结果如下表所示。
Zero-shot
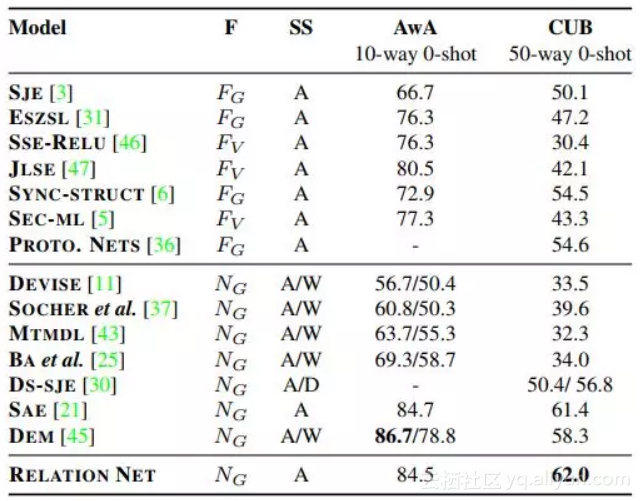
RN 在 AwA 及 CUB 上的准确率和其他方法的对比如下表所示。
0-way 1-shot 和 20-way 5-shot 集中情况展开了实验,实验结果如下表所示。
RN为什么能工作
这部分为本论文最核心的内容,论文指出,之前的 few-shot 工作都是预先指定好度量方式的,如欧式距离或余弦距离,学习部分主要体现在特征嵌入方面。
但是该论文同时学习了特征的嵌入及非线性度量矩阵(相似度函数),这些都是端到端的调整。通过学习到的相似性矩阵比人为选定的矩阵更具有灵活性,更能捕获到特征之间的相似性。
为了证明 RN 的有效性,作者分别使用马哈拉诺比斯度量矩阵方法 4(c)、马哈拉诺比斯度量矩阵 + 多层感知机 4(d) 及 RN4(b) 对 query set 的匹配情况,通过和 4(a) 相对比可以看出,RN 的匹配效果最好。
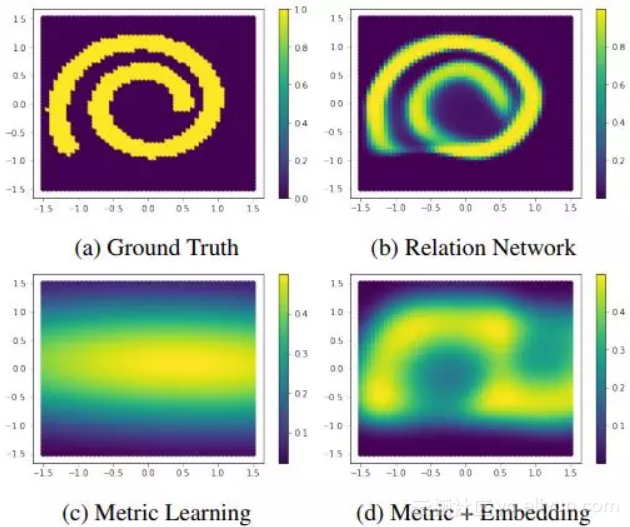
▲ 图4
图 5 左边是原始情况下 Omniglot 中图的关系,其中青色是和样例点(黄色)相匹配的图像,紫色是和样本点不匹配的图像。
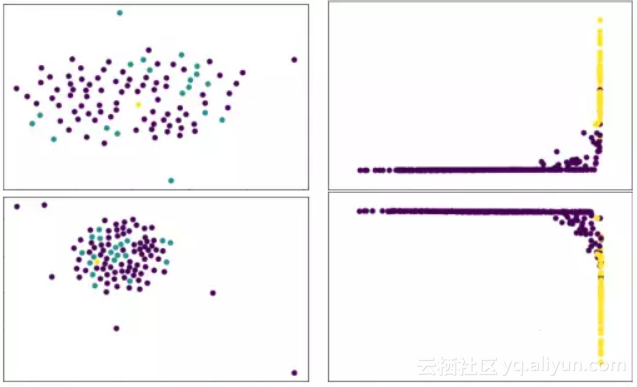
▲ 图5
从图中可以看出,使用欧式距离或余弦距离都不能实现对样例点的正常匹配。但通过对 RN 的倒数第二层进行 PCA 降维,得到的分布图如图 5(右)所示,可以看出匹配的与无法匹配的两类样本变成线性可分的。
原文发布时间为:2018-05-2
本文作者:吴仕超
