演讲嘉宾简介:谢宣松(星瞳),谢宣松(星瞳),阿里巴巴机器智能技术实验室资深算法专家,专注于视觉生成、智能医疗、图像搜索、信息抽取等方面技术研发和落地;阿里巴巴智能设计(鲁班)的创始成员和技术负责人,医疗影像智能诊断方向负责人,图像搜索拍立淘的早期创始成员。
本次分享主要分为以下几个部分:
l 定义、目标和愿景
l 设计行业现状
l 使用场景
l 技术框架和生产流程
l 关键算法
l 业务进展
l 案例展示
l 鲁班(新零售UED、淘宝技术部以及达摩院MIT共创的典型案例)
l 前景展望
一、定义、目标和愿景
视觉生成的定义:可控视觉内容设计和生成,聚焦满足用户、场景需求的数字视觉内容制造,包括针对图像、视频及图形的增强、编辑、渲染、生成、评估等视觉内容设计与制作。用技术赋能和改革设计、广告及数娱行业。
目标:可控视觉内容设计和生成,让AI做设计,使数字内容制造变得高质、高效、普惠、低成本;
愿景:所想,即所见。

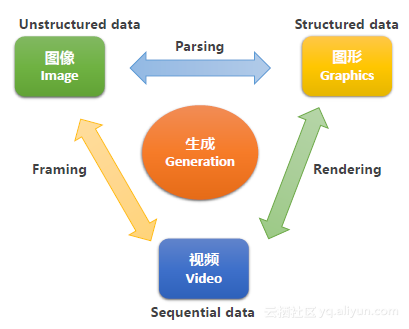
视觉生成主要分成三个方向。第一,针对非结构化的图像,如图像。第二,针对结构化的图形。第三,针对序列化的视频。
二、设计行业现状
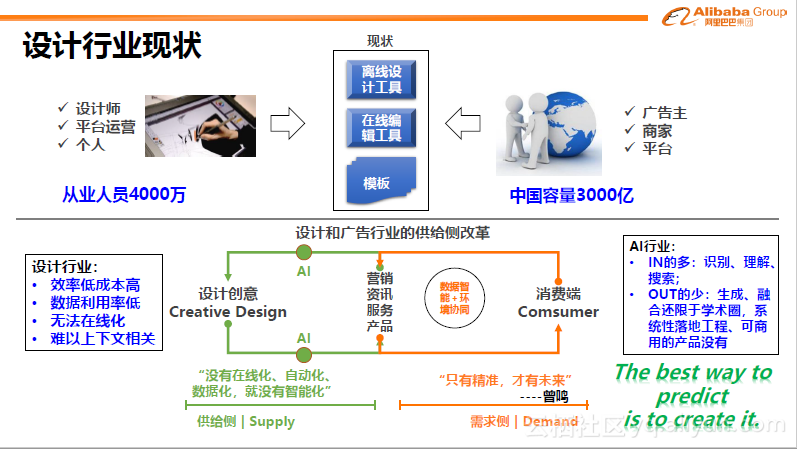
视觉生成较年轻。起初,基本都是通过人工方式完成。小到海报或毕业设计封面的设计这样的小需求,大到阿里巴巴中海量商家的投放渠道及效果这样的大型需求都与其相关。从业人员数量庞大,市场与广告、商家关系紧密,市场容量非常大。
从技术上说,近几年,大家常提到供给侧改革,以前的供给侧基本都是通过人或工具来形成图像、视频等,但这样有很大的局限性,包括:
l 效率低成本高
l 数据利用率低,比如去年双十一和今年双十一由于主题不同,需要全盘重做。
l 无法在线化,从提出需求到得到结果无法做到实时。
l 难以上下文相关,设计师不会结合用户的个性化需求,形成与上下文相关的结果。
而在消费端,对个性化、精准度、实时性有很高的需求。因此,在供给和需求之间还存在差距。在AI行业中,IN的多:识别、理解、搜索。OUT的少:生成、融合还限于学术圈,系统性落地工程、可商用的产品没有。
因此,“The best way to predict is to create.”。
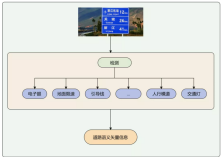
三、使用场景
视觉生成引擎的使用场景大致可抽象成下图。以显式输入而言,用户可以输入标签需要的风格、色彩、构图等,或者输入一个例子,或者进行一些交互的输入。除显式输入之外还可以有隐式输入,比如人群信息、场景信息、上下文信息等。总的来说,输入可以是千变万化的,但通过规范化之后就会减少变化,使得生成过程可控,输出质量可控。
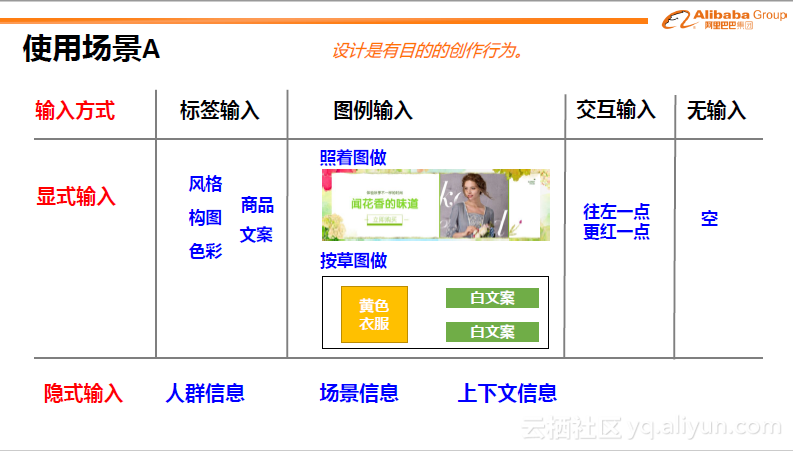
对视觉生成引擎来说,它要求输入是规范化的。但在输入前,可以加入各种交互方式,如自然语言处理,语音识别等,将其转化成规范化输入。最后输出结构化信息或可视成图。

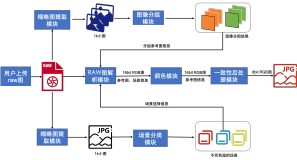
四、技术框架和生产流程
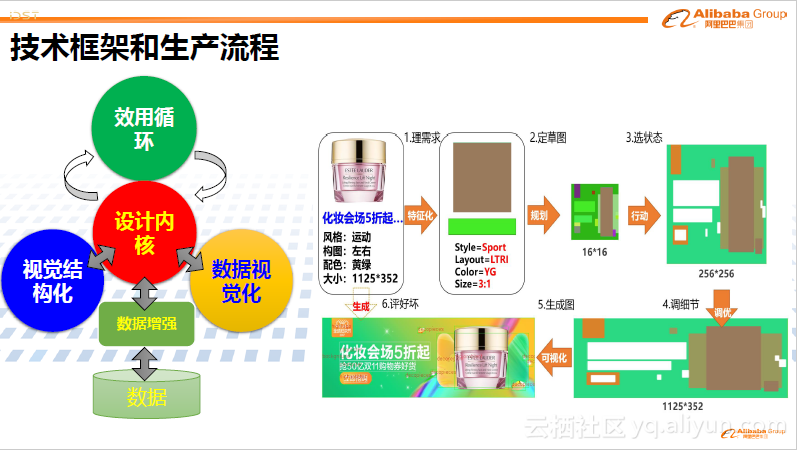
其技术框架如下图左侧。首先对视觉内容进行结构化理解,如分类、量化、特征化。其次通过一系列学习、决策变成满足用户需求的结构化信息即数据,最后将数据转化成可视的图像或视频。这一框架依赖于大量的现有数据。其核心是一个设计内核。同时,引入效用循环,利用使用后的反馈来不断迭代和改进系统。
其生产流程分成六个步骤,如下图右侧所示。首先用户提出需求,将需求特征化转变成系统可以理解的结构化信息。其次将信息进行规划得到草图。有了粗略的草图后再将其转变成相对更精确的图,然后调整细节,最后通过数据可视化形成最终的图。当然其中还有很多的trick,以及各部分的优化。
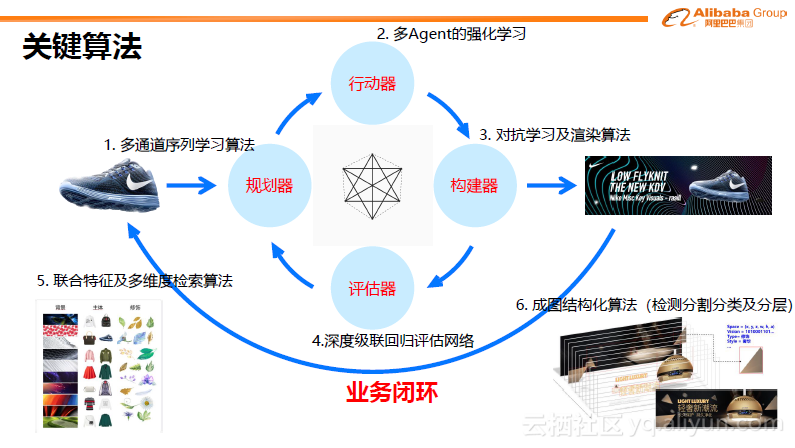
五、关键算法
下面介绍一些关键算法。我们希望基于下图最左的耐克鞋生成最右的图。先通过规划器得到草图,再通过强化学习获得相对细致的结果,再通过对抗学习及渲染算法得到图片,再通过评估器进行评估,最后形成业务闭环,其中还会有一些基础的能力,包含更强的联合特征(非普通 CNN特征)及多维度检索算法等。
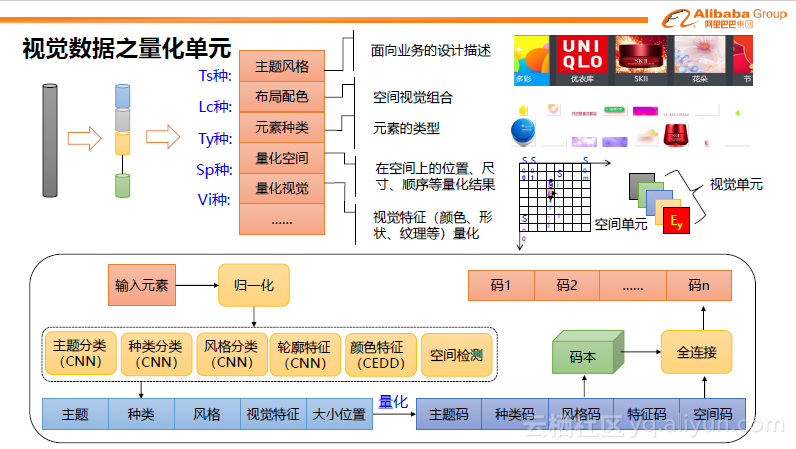
基本上,处理的第一步是将图片中的信息结构化,这也是与现有的识别理解技术结合最紧密的地方。其中的难点和重点包括,对图像中多目标的识别、遮挡和互包含情况如何得到分割的信息等,下图只是个简单的示例。
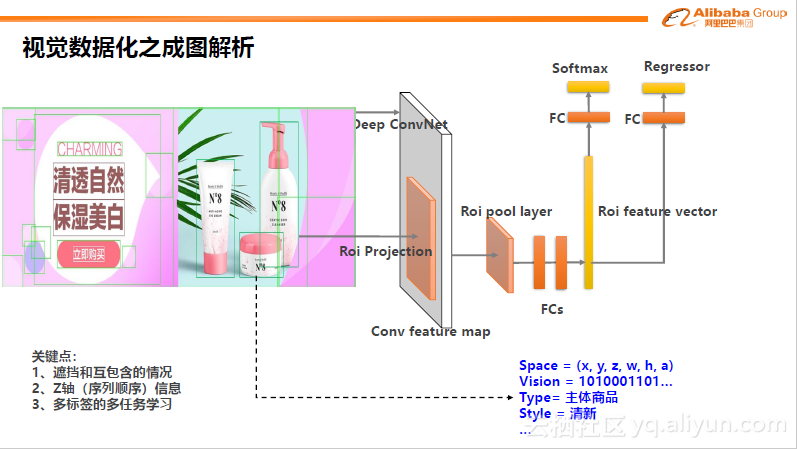
有了结构化信息之后,需要对信息进行量化。可以量化成特征或量化图。量化过程中会包含很多信息,比如主题风格、布局配色、元素种类、量化空间等。有了这些信息后可以在主题、种类、风格、视觉特征大小位置上,量化成各种码,用相对有限的特征来表达无限的图。
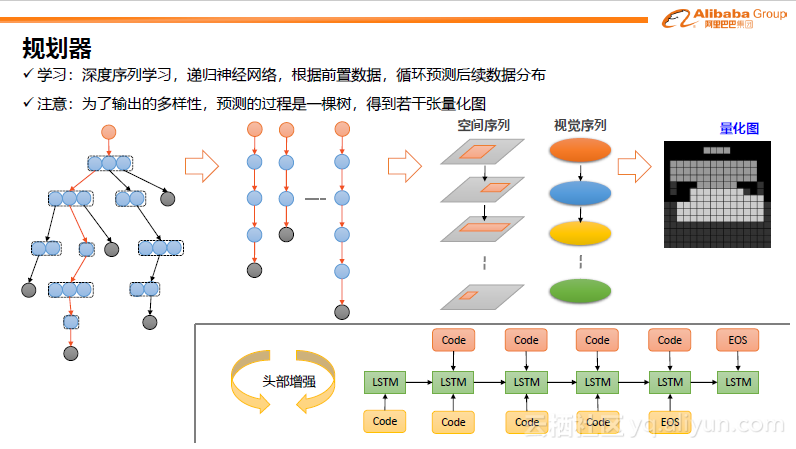
下一步是通过用户的输入,得到一个相对粗略的结果即草图。目前主要使用的是深度序列学习。从图像角度,首先选定一个点的像素颜色再选择位置,再迭代进行操作,最后形成一张图。规划器模拟的就是这个过程。本质上预测过程是一棵树,当然也可以拆成一条条路径。为了简化,可以分成几步进行,比如空间序列,视觉序列。最后形成量化特征模型,主要应用的是LSTM模型。它把设计的过程转化成基于递归、循环的过程。
得到草图后,利用行动器将草图细化。如果将图中的每个元素看作一个Agent,那么它将有若干个可选的行动空间。
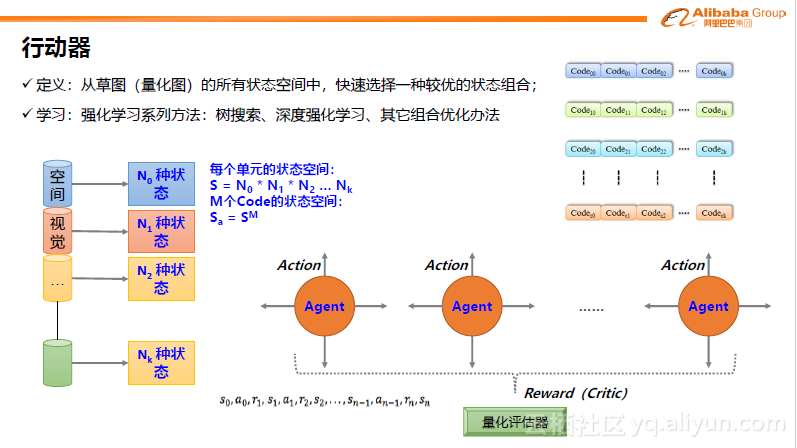
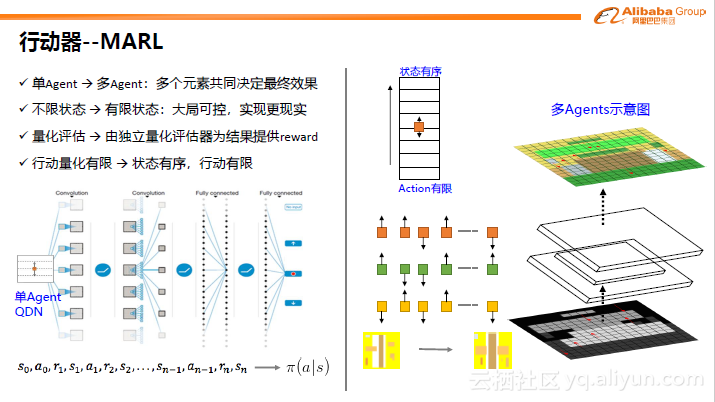
假设一张图中有20个元素,每个元素在视觉上有多种可选的行动空间,由其组合成的可选行动空间非常庞大。我们有很多trick可以解决这一问题,比如在空间上,只允许在有限范围内进行变动,且行动方向有序,即状态有序,行动有限。
下一步是如何衡量结果的好坏。图像的评估相对比较主观,主要可以从美学和效果两方面来评估。美学角度可以包括是否对齐、色系搭配是否合理、有无遮挡这些较低级别的判断标准,以及较高级的,比如风格是否一致,是否切合主题。从效果上,产品投放后是否会在点击率等方面实现提升。最后将多个指标形成对应权重并形成多个DeepLR联合模型。
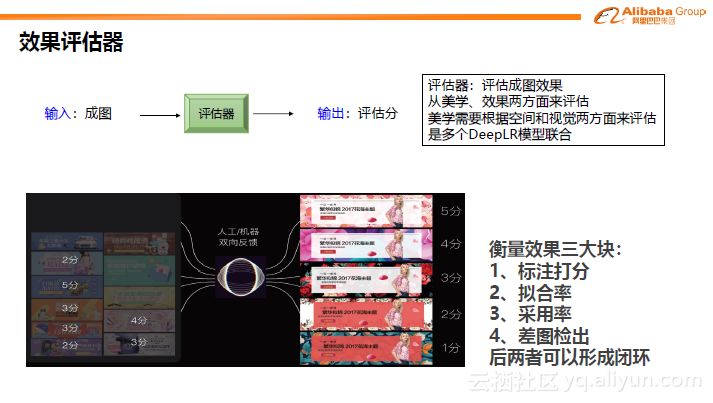
但在衡量结果之前,需要形成像素级别可见的图。这里有以下几种构造器分类,包临摹、迁移、创造、搭配与生成。

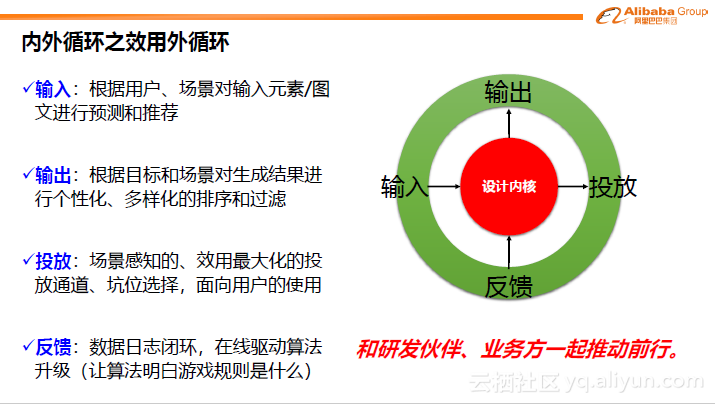
前面介绍了,如何通过用户的需求形成可见的图。后续还需要进行投放和反馈并进行优化,形成效用外循环。这样才能使得系统效用不断得到提升,形成一个在线闭环,这也是智能设计相对设计师的一大优势。
六、业务进展
下面是一些实际的例子。

在这个系统中也加入了大量的人的信息,知识图谱。设计师在进行设计时都会存在一些共性的东西,包括在色彩、复杂度、风格、结构上的应用,这与自然语言处理有些相似,但自然语言处理方面的知识图谱已经非常成熟,而设计上的还需要不断探索打磨。
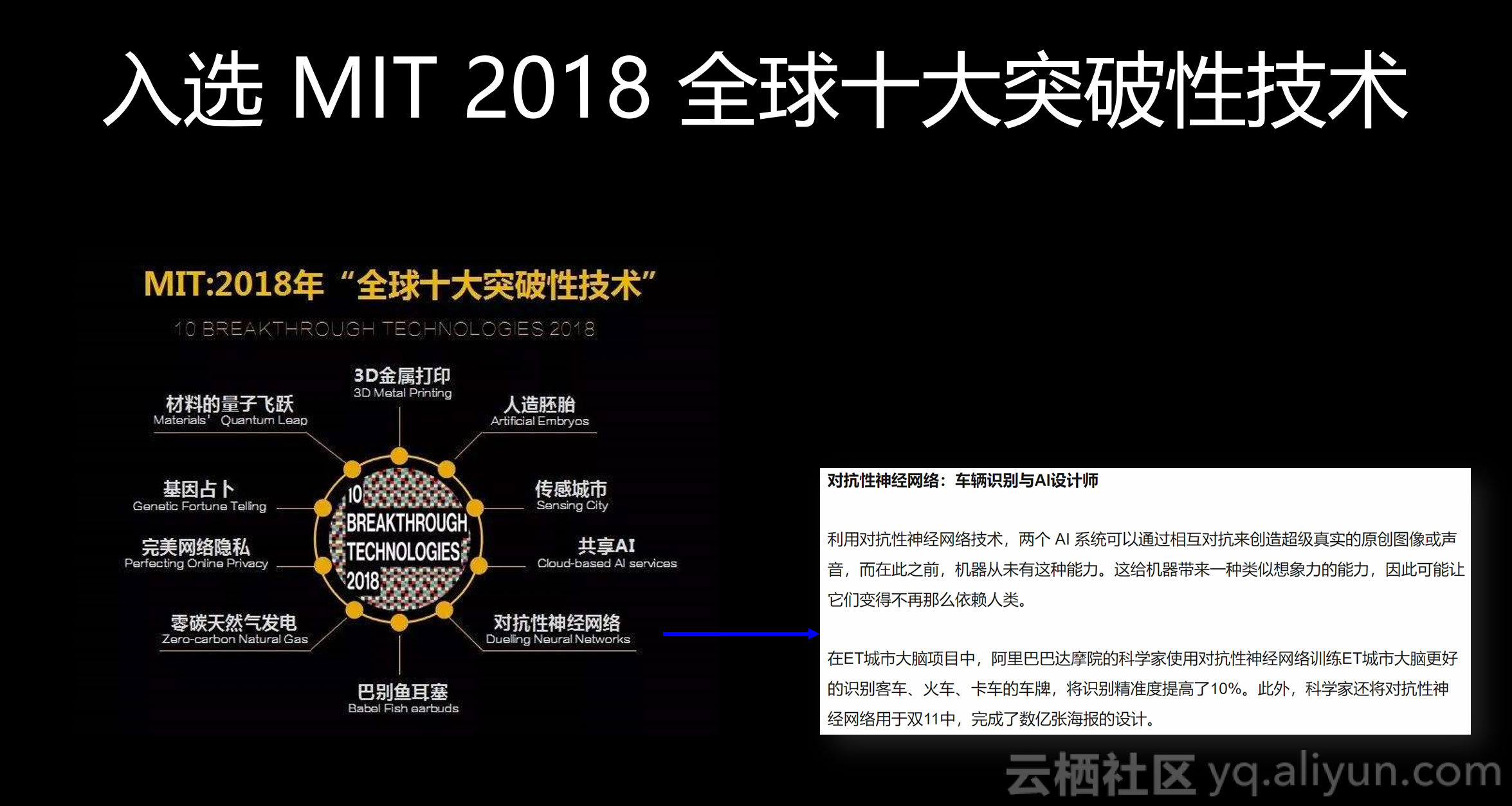
在影响力方面,鲁班作为业界首创的AI设计系统,成为集团双十一的一个AI协同典型案例,获得了大量的报道。在其中,运用了对抗学习,该技术是MIT018全球十大突破性技术之一。
七、案例展示
从多样性看,生成的图片可以是多主体、多主体、多配色和类型自适应的。

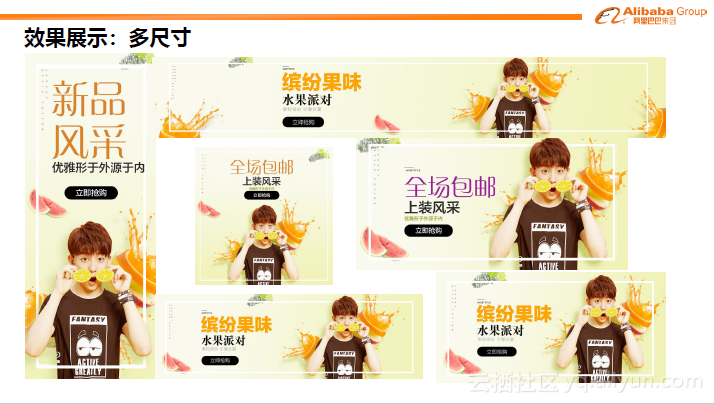
同时,也可以生成多种尺寸的图片。
八、前景展望
上面所说的基本都是平面设计层面的。但在视频和图形上是另一片蓝海。如果说人工做一张图片的成本比较高,而制作视频的成本则远高于图片。

下图是目前的行业市场空间展示。

下图是在视频中进行广告植入的案例。需要检测视频中哪个位置适合插入广告,对位置进行优化。


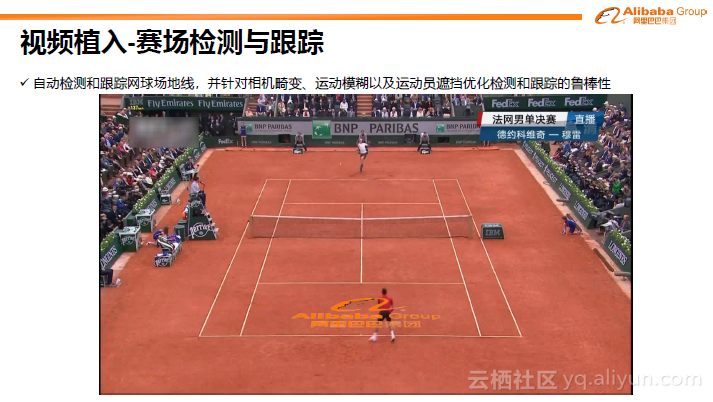
下图是网球赛中将阿里巴巴的品牌logo无缝投影到赛场中。
为了强调视频中的一部分,可以生成整体静止局部运动的可循环视频。

在游戏领域中,现在的游戏场景需要大量的美工、设计师等。如果希望生成的结果能满足多样性,那么纯靠人工进行需要大量的成本,并且由于游戏的生命周期通常较短,因此批量高效的场景制作是一个很有前景的应用。

九、结语
通过视觉生成引擎,我们希望能基于用户的所想,使得一切皆可生成。长远的目标就是:所想,即所见。
谢谢大家。