作为阿里新人职场旧人第一次参会,之前工作局限于GPU下游和底层,跟硬件和驱动打交道比较多,如今参加GTC有机会抬头看看,近距离接触蓬勃朝气的新技术新领域,感受到了如日中天的人工智能,各种机器学习,深度学习,自动驾驶,HPC,GPU Cloud,GPU in Container等新技术扑面而来。完全觉得进入了一个新世界,深刻体验到技术的革新迭代之快速,大有取代CPU 摩尔定理的趋势。
GTC大会相当有规模,keynote,讲座,海报,展台等。光参会讲座就有近千个主题。近百个海报(POSTER),近百展台(Booth)。参与人员估计好几千吧。个人参会者只能在上千个session里面挑选自己最感兴趣的十几个session参加。 
Keynote介绍
Keynote video: https://www.ustream.tv/gpu-technology-conference
几个关键信息:
发布GV100的RTX技术,发布了$399K DGX2史上最强计算平台,NVIDIA GPU CLOUD(NGC)和GPU kubernetes容器化的落地,NVIDIA自动驾驶的真实路况模拟系统,最后超炫的在会场远程驾驶场外一辆自动驾驶车辆,开了十几米。
具体参见下方NVIDIA正式新闻稿。此处不累述。
阿里参会同去的有几个人,每个人背景和研究方向都不一样。AI和Machine Learning相关主题有同事专职跟进,本人就选择性的参加了近15个主题讲座分别对应与GPU不同应用场景
15个讲座归类并简单整理如下:
1. vGPU虚拟化相关
GRID vGPU是NVIDIA的GPU虚拟化方案,很早就被VMWare所采用。
一般的GPU应用可以分为:Graphics,GPGPU,Machine Learning(ML),Media Codec等等。本讲座主要讨论了针对GPU虚拟化下,尤其是vGPU分片虚拟化方案下,同时把这些workload通过不同的VM运行在同一个物理GPU上那么会发生什么样的性能影响。
为了做性能对比,讲座讨论了几种vGPU的调度方案,其中“best-effort”就是vSphere采用的其中一种。在这种调度方法会力求每个VM最大可能的运用GPU资源。(题外话:事实上每个GPU的GPGPU,Graphics Render,Media pipeline都是独立的,GPU是可以做到一边编解码H265,一边做3D渲染的)
有趣的结论就是:
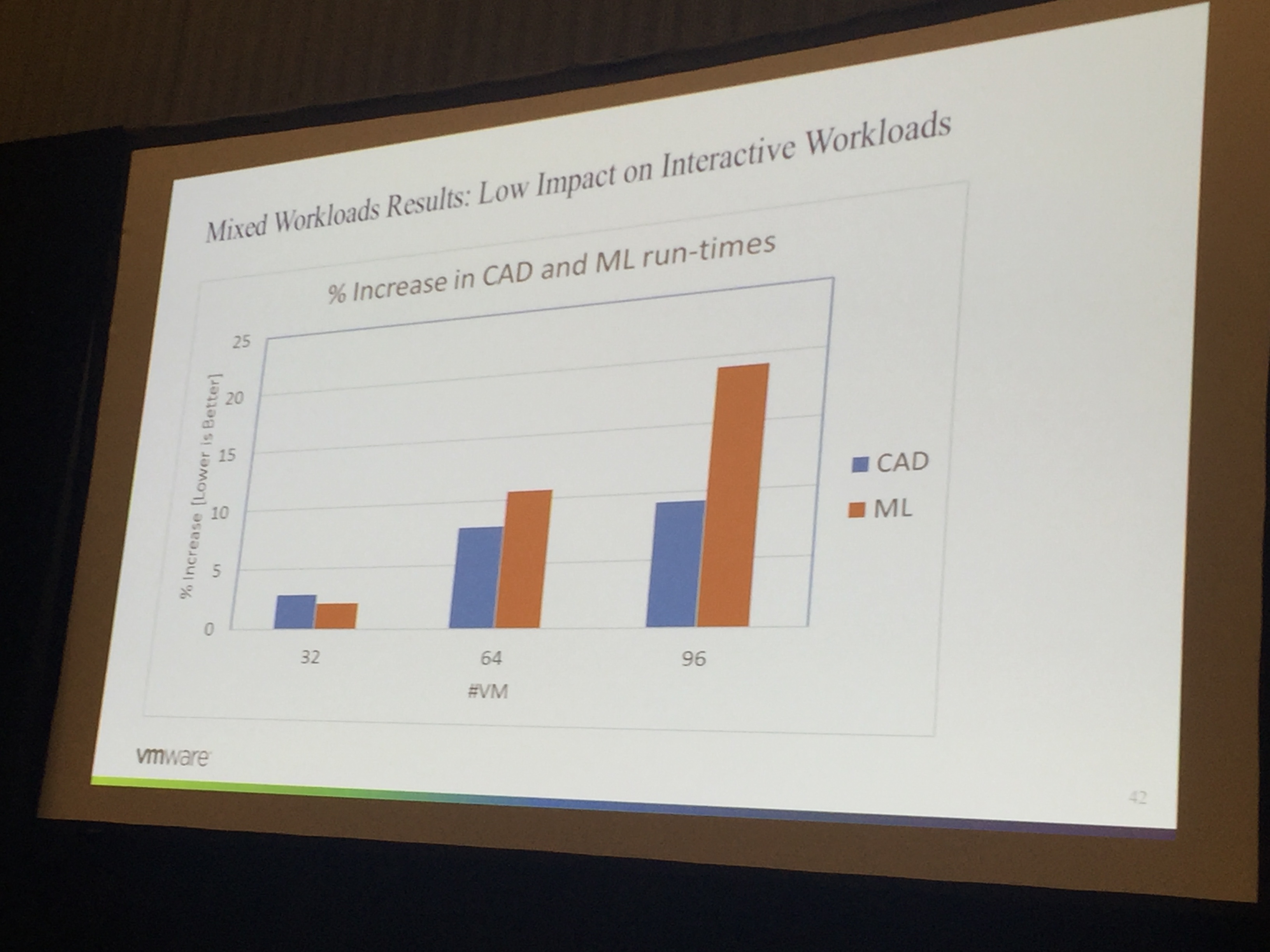
- 同时运行不同种类的workload:比如CAD+ML,随着VM数量的增加,对交互性应用程序的性能影响有限,而对于ML等workload,则受影响较大。
- 在支持vGPU suspend/resume的地方,可以统一调度在白天满足日常交互性的应用(类似CAD),晚上则运行ML等workload来充分利用GPU资源。前提应该是支持Live Migration才行。
此处也给了很多公有云提供GPU服务的厂商一个启示,未来在实现vGPU颗粒度调度的情况下,可以尽量把Graphics用户和Computing用户安排在一个GPU上实现各自最大资源利用。
2. HPC与container相关
S8642 - HPC in Containers - Why Containers, Why HPC, How and Why NVIDIA
此Session为初级讲座,没有介绍技术细节,介绍了NVIDA GPU Cloud(NGC)在HPC上的容器化的应用。解释了为什么用Container在HPC上提供服务。用container原因很简单:统一配置,统一更新,统一标准平台,缩小app的deploy难度等,对非专业人士友好。此处用的基础架构就是NVIDIA GPU Cloud(NGC)on HPC。从介绍看,NGC正在与多家大学和厂商合作。

NGC 合作方
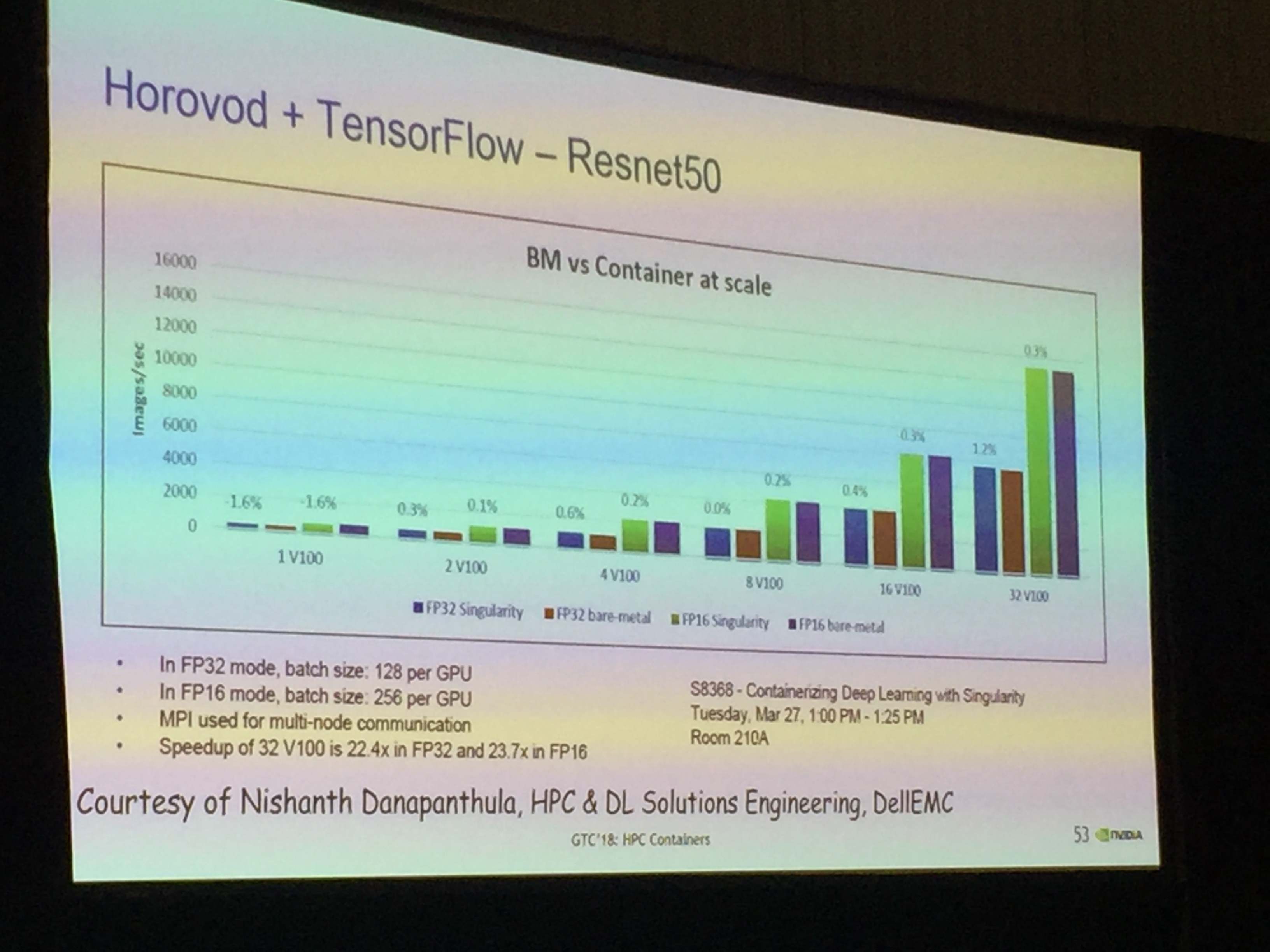
最后提供了一些performance数据。比如v100在NGC上面的scability:32v100的加速比为22.4左右。
S81017 - Spectre/Meltdown Impact on High Performance Workloads
对前一阵子著名安全漏洞(Spectre/Meltdown漏洞)在HPC上的一些性能对比。我关注的是对GPU典型computing workload的影响。可以看到下图,对于IBRS的修复方案大概有1.26%的性能下降,而Retpoline修复方案基本认为对性能无影响。
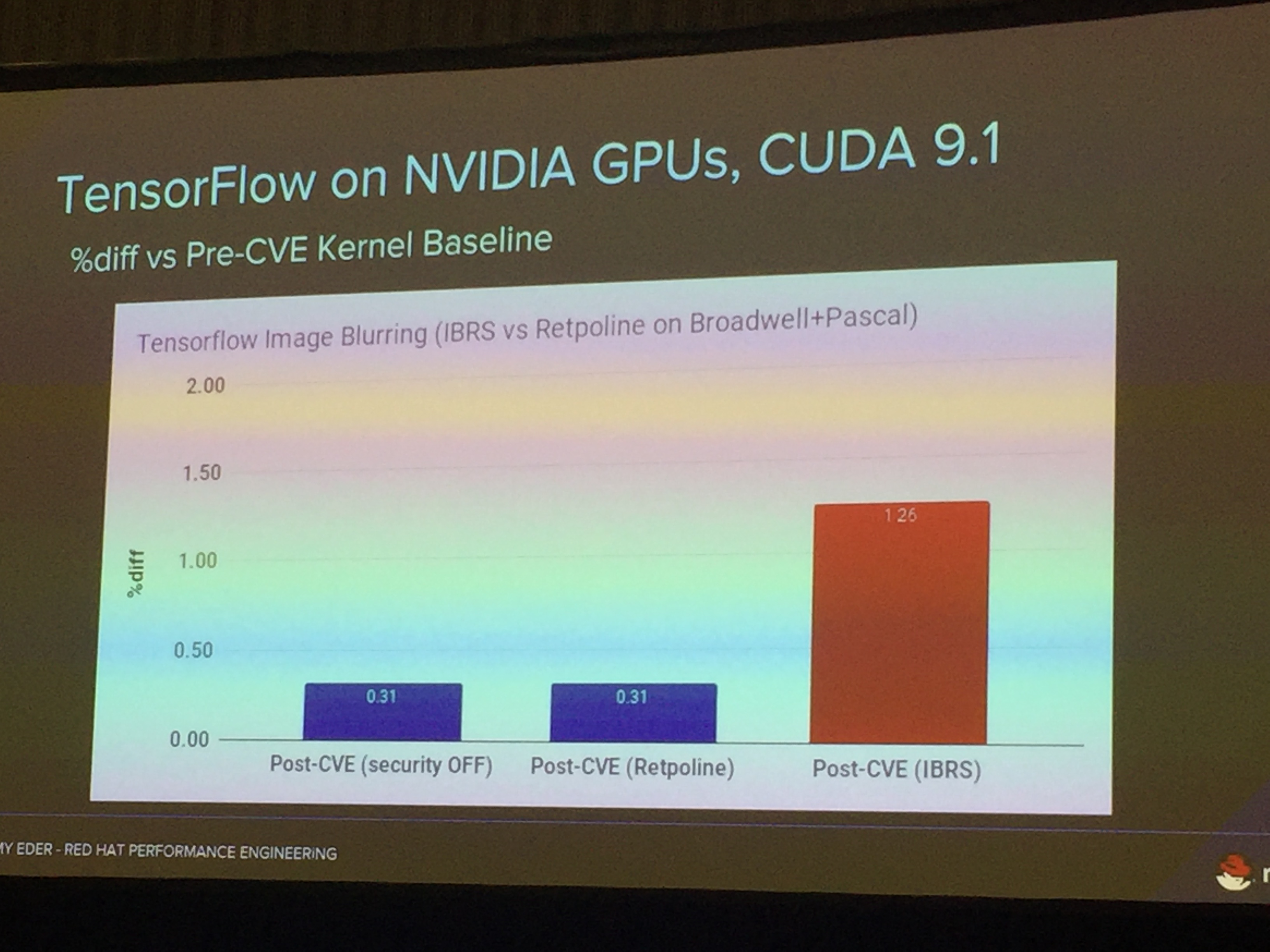
Session也对DPDK等网络场景做了对比,基本上影响有限。
个人理解:对于安全漏洞主要影响的是用户态到内核态切换性能(尤其涉及到TLB的刷新)。所以如果有PCID支持的话TLB flush将大大减少,进一步配合hugepage的支持,那么安全漏洞的性能影响将非常有限。当然对于HPC的应用场景来说,1%的性能损耗也是弥足珍贵的。
S8893 - The Path to GPU as a Service in Kubernetes
Kubernetes对NVIDIA GPU的支持是本届GTC的keynote里面的重要一项。此session介绍了NVIDIA在Kubernetes的社区工作,支持程度。GPU 容器化的优点此处略过。GPU资源管理和监控是通过在每一个Kubernetes node上安排一个NVIDIA Device Plugin组件来完成。细节略过不提。来看一下roadmap:

可以看到在2018年GPU as Service on top of Kubernetes将相对成熟并达到基本可用。比如说对GPU的可用性检测(health check),容器对异构计算支持,GPU topology的支持等。而这些也正是目前所有公有云GPU服务器集群上都会碰到的问题。有参考价值。
题外话:NGC已经落户阿里云(Link)
3. GPU新应用场景
了解GPU在新领域的应用场景是本人参会的主要目的。包括GPU在数据库领域,在基因匹配领域,GPU与FPGA的关系等等。介绍如下:
3.1 GPU在数据库领域的应用
介绍了GPU加速在数据库上的应用。主要推荐了MAPD的一款GPU加速的快速分析产品。MAPD是一家数据库公司,MAPD core是一个开源GPU加速的SQL引擎(号称全球最快)。所有的应用都基于这个MAPD core。而MAPD Core的设计理念以充分利用GPU vRAM的高速带宽为基础实现。如下图,利用GPU RAM每秒高达8000GB/s的带宽来处理Hot Data,而利用CPU RAM来做2级缓存(System RAM的带宽相对最高只有200GB/s)处理Warn data,而NVRAM/SSD则作为3级缓存。

其中涉及相当多的技术细节,比如让一个数据库Query可以跨GPU和CPU等。MAPD是如何构建一个通用应用框架等。因为对数据库应用不是特别了解,所以此处就没办法深入下去。
其他的GPU加速的数据库基本上也都在2014年以后出现。比如GPUDB,OmniDB等等。
GPU在数据库的应用尚需比较深入细致的研究才行。此处只是提供了一个可能的思路。
S8289 - How to Get the Most out of GPU Accelerated Database Operators
此讲座介绍相对多的技术细节。由NVIDIA工程师提供。
从一个TPC-H query 入手分析了数据库性能瓶颈。
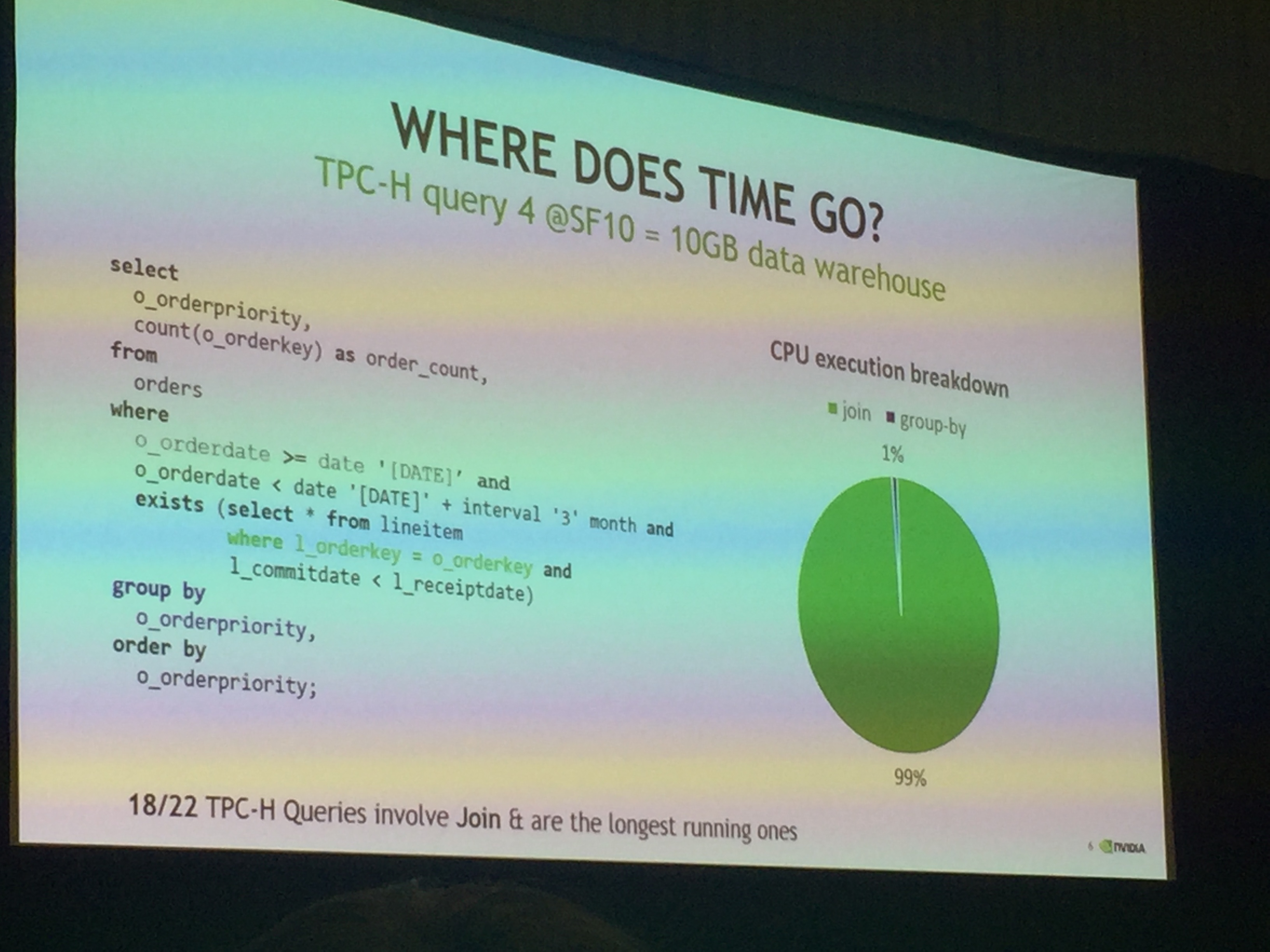
数据采样表明,性能瓶颈在Query的“Join”阶段(对数据query的整理合并的过程)。
讲座对此过程做了CPU和GPU的优化结果对比(算法细节此处不再累述,有兴趣的可以等到GTC发布PPT的时候再研究)。
结论就是利用GPU对一个query有80x的性能加速。
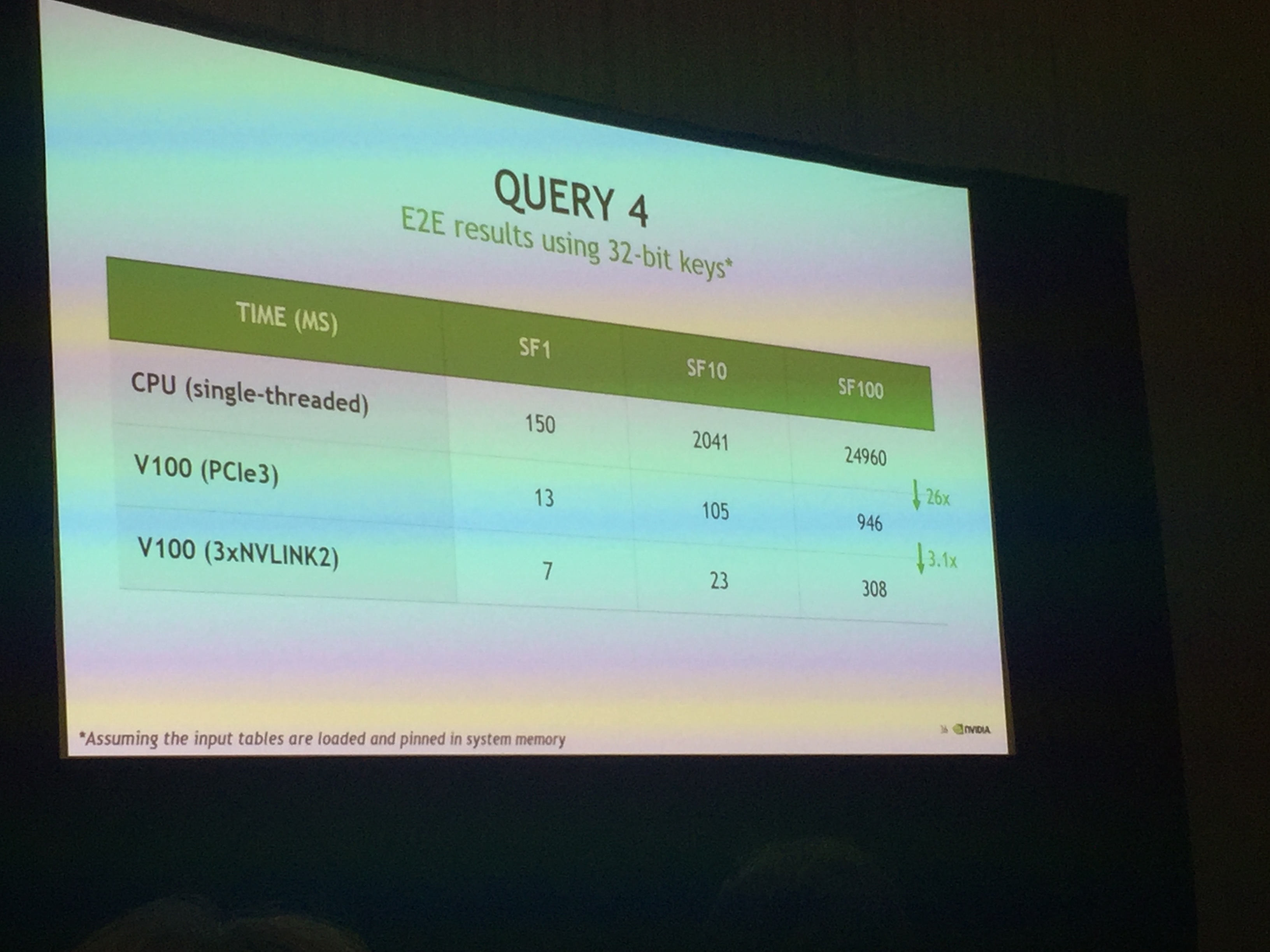
几个性能关键因素:
Memory 带宽
CPU: peak memory BW: 120GB/s
GPU: Peak memory BW:900GB/s
此处也利用了GPU的超高Memory 吞吐能力。
GPU query的性能主要取决于CPU-GPU直接的带宽,因此利用NVLink可以额外提升3x以上的性能。
3.2 GPU在基因匹配领域的应用
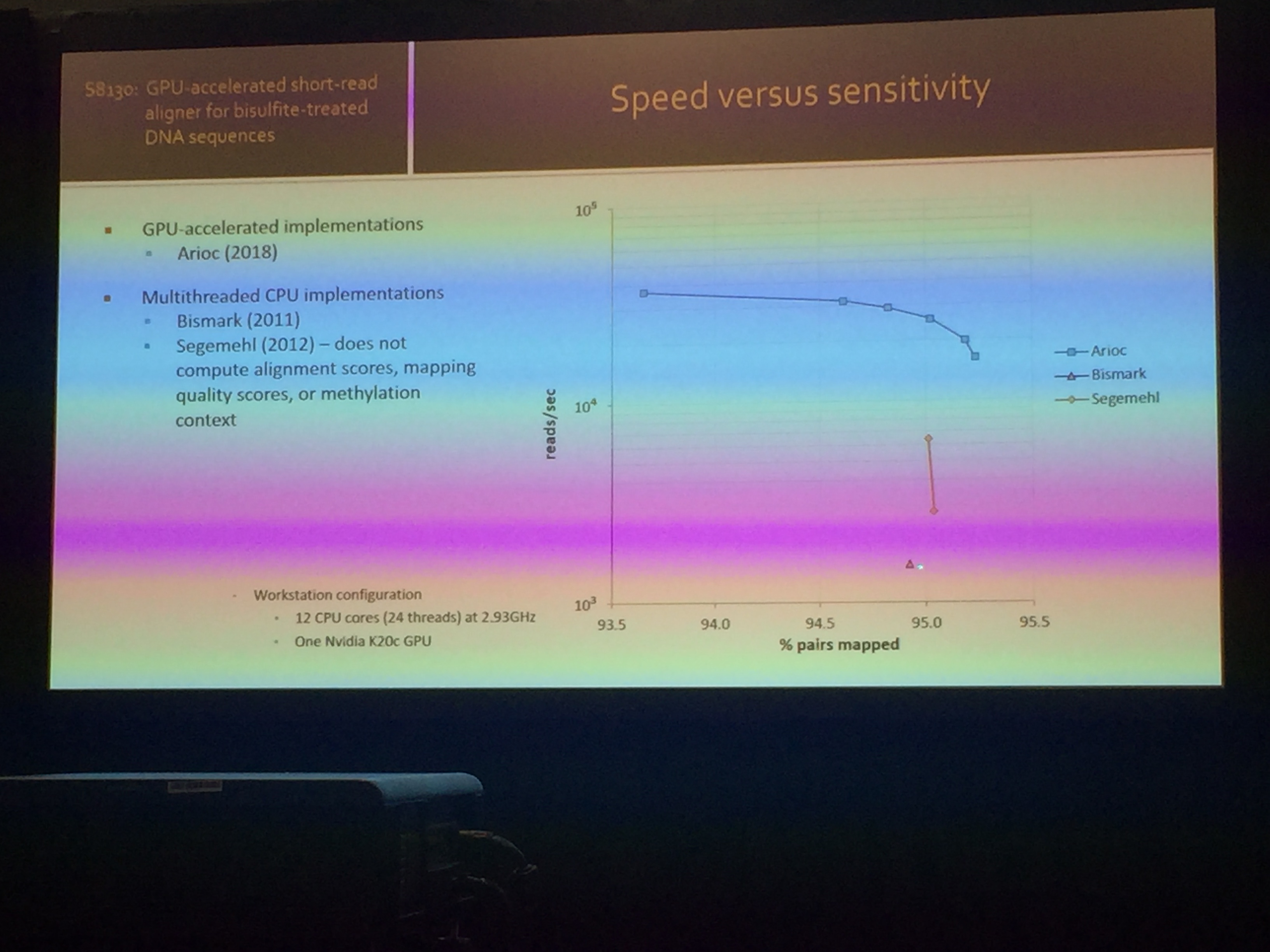
S8130 - Building a GPU-Accelerated Short-Read Aligner for Bisulfite-Treated DNA Sequences
这个是GTC里面针对基因匹配的少数几个topic。利用二代基因短序列匹配(Short-read alignment)算法来寻找匹配硫化处理的DNA序列,目前最新的是三代基因序列,序列长度可以上千个AGCT。但是硫化过的DNA都是短序列。
Short-read alignment GPU 加速的实现有:
SOAP3-DP(2013)
NVBIO(2015)
Arioc(2015)
一般来说对于复杂的串行序列做CUDA的并行化非常难。此topic采用了现成的CUDA加速的短序列匹配算法,但是针对硫化DNA做了一遍预处理,以方便采用通用CUDA加速的基因匹配算法。处理细节略过。与CPU的算力对比和匹配度如下:
NVIDIA对CUDA在基因工程上面的应用也非常重视,官网上面有专门主页介绍相关加速算法和当前状况,包括专门针对三代基因对齐算法smith-Watherman CUDASW等加速算法。
http://www.nvidia.com/object/bio_info_life_sciences.html
3.3 FPGA和GPU对比
S8310 - Can FPGAs Compete with GPUs?
讨论了FPGA的优缺点,及适用场景。总结下来,FPGA有高能效优点,但不善于复杂HPC应用,编码太难,这些缺点在Intel的Altera FPGA上有了很大的改善。编程不再依赖VHDL而是可以用通用的OpenCL,并内嵌FP Unit,与CPU core紧密结合。如果没有记错的话,是直接使用QPI链接FPGA与CPU。这使得FPGA在某些方面可以媲美GPU运算。
总结下来:是否采用FPGA依赖是什么类型的application。对于I/O密集型的应用应当使用FPGA,而最求高FLOPS的应该使用Volta GPU

3.4 GPU在医疗领域的应用
无实质性内容,AIMED公司提炼了几个AI的自动决策能力在未来医疗领域的应用场景,貌似比较遥远。
4. 竞品信息
AWS介绍了TOYOTA公司采用AWS的P3,G3,F1三种类型的实例来做汽车自动驾驶的开发。这些实例主要用于上亿公里真实路况的模拟测试。
P3是支持NVLInk的8卡V100 GPU。按量$24.48/hr
G3是支持图形渲染的4卡M60 GPU。(带GRID License)
F1是8卡Xillinx FPGA。
值得一提的是AWS在2017年10月就已经正式提供V100,阿里云GPU团队目前v100尚在公测中。相差半年左右。
其他的G3和F1实例基本上阿里云异构计算团队现有产品对应。
S8978 - Advantages of a Bare-Metal Cloud for CUDA Workloads (Presented by Oracle)
Oracle提供的一种bare-metalGPU云服务以满足高性能计算密集型业务。坐在最后一排基本上没听清楚讲了啥。
5. 应用
S8839 - Adding GPU Acceleration to Pixar Renderman
Pixar是非常酷的一家动画公司,所有著名Pixar的动画电影都是通过旗下RenderMan实时渲染出来的。
此session介绍了RenderMan下一代渲染架构:XPU架构=CPU+GPU,XPU可以让同一份code有选择的利用CPU,GPU或者both。XPU框架采用了C++的TEMPLATE功能来实现CPU或者GPU对象的统一。Session过程中展示了很多动画渲染的惊艳过程。下图是其演示之一:从Geometry processing->shading->Texture->完图。

S8879 - Combining VR, AR, Simulation, and the IoT to Create a Digital Twin
另外一个非常酷的session,通过物体的真实数据,安装IoT等传感器到真实物体中:比如安装到船体,直升飞机等,并融合VR,AR在实验室里模拟出了一个与真实物体一摸一样的数字模型。
其原理如下图:

非常酷的是,session speaker在现场演示了一架数字直升机通过AR/VR等技术与现场观众融合的场景。通过头盔会让人觉得这个直升机就是在会议室上空盘旋。

总结
GTC2018 的所有PPT,POSTER都在https://www.nvidia.com/en-us/gtc/



