深度学习目前是一个非常活跃的领域---每天都会有许多应用出现。进一步学习Deep Learning最好的方法就是亲自动手。尽可能多的接触项目并且尝试自己去做。这将会帮助你更深刻地掌握各个主题,成为一名更好的Deep Learning实践者。
这篇文章将和大家一起看一个有趣的多模态主题,我们将结合图像和文本处理技术来构建一个有用的深度学习应用,即看图说话(Image Captioning)。看图说话是指从一个图像中基于其中的对象和动作生成文本描述的过程。例如:

这种过程在现实生活中有很多潜在的应用场景。一个明显的应用比如保存图片的描述字幕,以便该图片随后可以根据这个描述轻松地被检索出来。
我们开始吧!
注意: 本文假定你了解深度学习的基础知识,以前曾使用CNN处理过图像问题。如果想复习这些概念,可以先阅读下面的文章:
目录
什么是Image Captioning问题?
设想你看到了这张图:

你首先想到的是什么?下面是一些人们可以想到的句子:
A man and a girl sit on the ground and eat . (一个男人和一个女孩坐在地上吃东西)
A man and a little girl are sitting on a sidewalk near a blue bag eating . (一个男人和一个小女孩坐在蓝色包旁边的人行道上吃东西)
A man wearing a black shirt and a little girl wearing an orange dress share a treat .(一个穿黑色衬衣的男人和一个穿橘色连衣裙的小女孩分享美食)
快速看一眼就足以让你理解和描述图片中发生的事情。从一个人造系统中自动生成这种文字描述就是Image Captioning的任务。
该任务很明确,即产生的输出是用一句话来描述这幅图片中的内容---存在的对象,属性,正在发生的动作以及对象之间的互动等。但是与其他图像处理问题一样,在人造系统中再现这种行为也是一项艰巨的任务。因此需要使用像Deep Learning这样先进复杂的技术来解决该任务。
在继续下文之前,我想特别感谢Andrej Kartpathy等学者,他们富有洞察力的课程CS231n帮助我理解了这个主题。
解决任务的方法
可以把image captioning任务在逻辑上分为两个模块——一个是基于图像的模型,从图像中提取特征和细微的差别, 另一个是基于语言的模型,将第一个模型给出的特征和对象翻译成自然的语句。
对于基于图像的模型而言(即编码器)我们通常依靠CNN网络。对于基于语言的模型而言(即解码器),我们依赖RNN网络。下图总结了前面提到的方法:
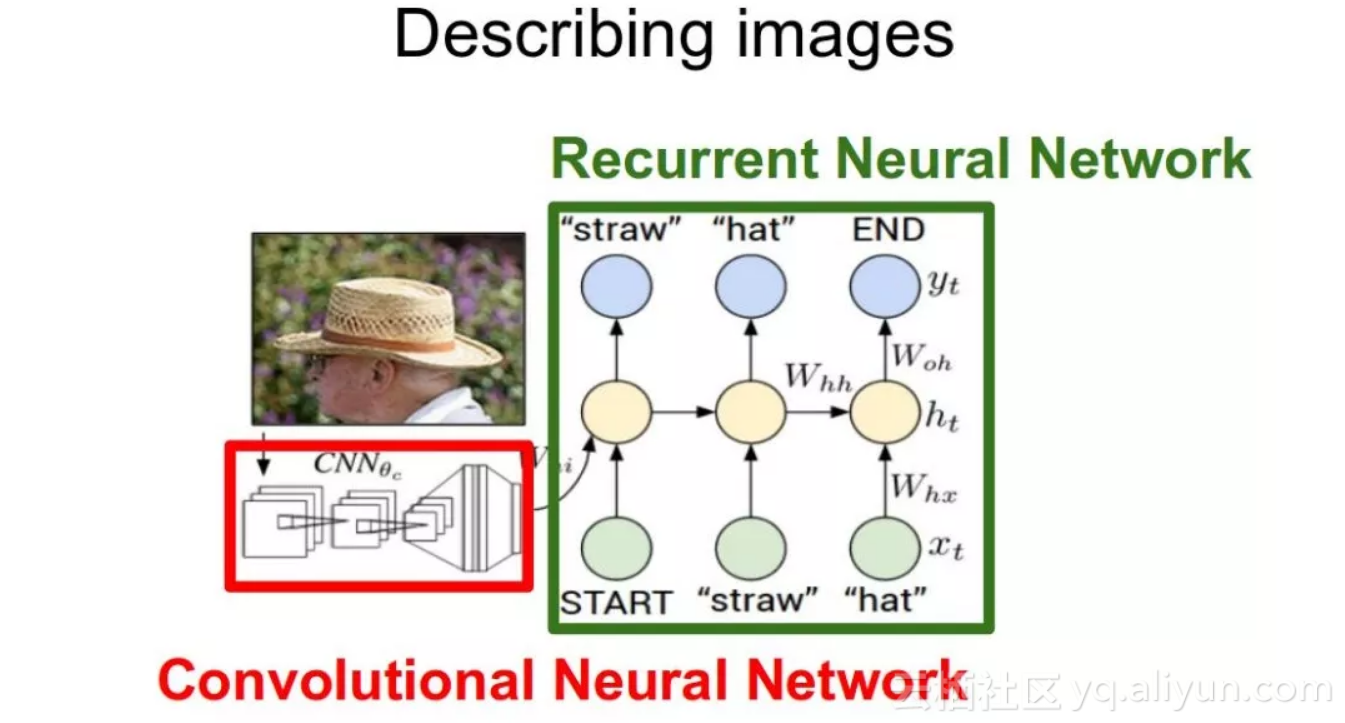
通常,一个预先训练好的CNN网络从输入图像中提取特征。特征向量被线性转换成与RNN/LSTM网络的输入具有相同的维度。这个网络被训练作为我们特征向量的语言模型。
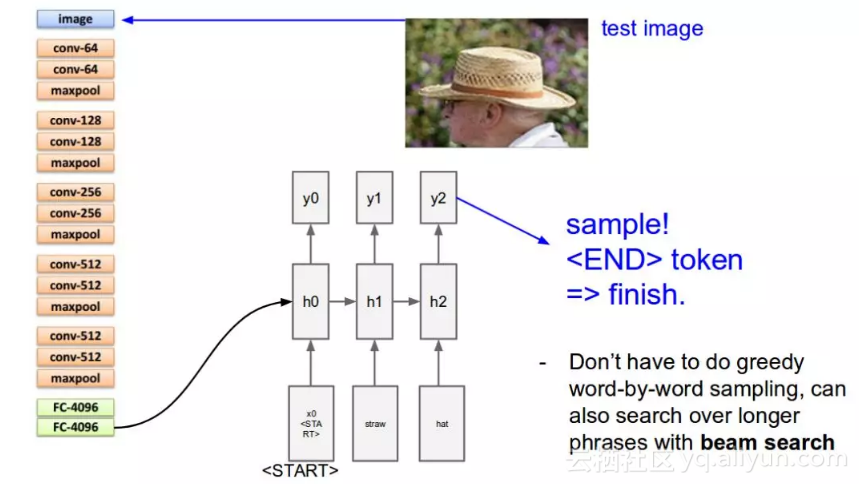
为了训练LSTM模型,我们预先定义了标签和目标文本。比如,如果字幕是A man and a girl sit on the ground and eat .(一个男人和一个女孩坐在地上吃东西),则我们的标签和目标文本如下:

这样做是为了让模型理解我们标记序列的开始和结束。
具体实现案例
让我们看一个Pytorch中image captioning的简单实现。我们将以一幅图作为输入,然后使用深度学习模型来预测它的描述。
例子的代码可以在GitHub上找到。代码的原始作者是Yunjey Choi 向他杰出的pytorch例子致敬。
在本例中,一个预先训练好的ResNet-152被用作编码器,而解码器是一个LSTM网络。
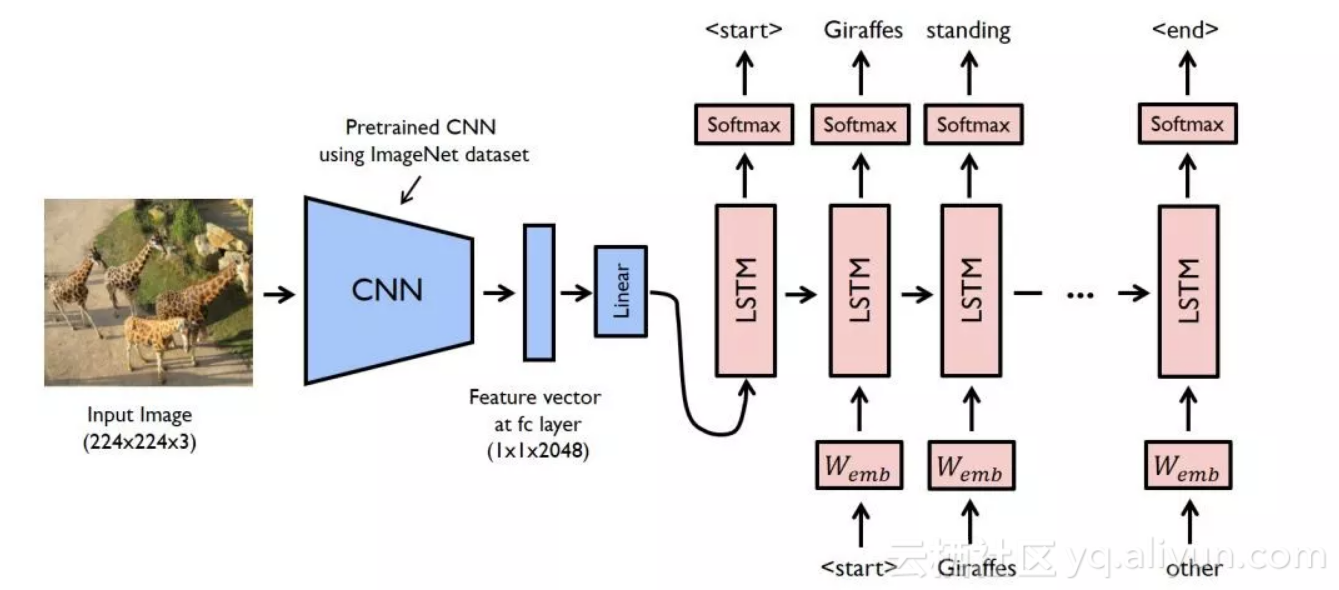
要运行本例中的代码,你需要安装必备软件,确保有一个可以工作的python环境,最好使用anaconda。然后运行以下命令来安装其他所需要的库。
git clone https://github.com/pdollar/coco.git
cd coco/PythonAPI/
make
python setup.py build
python setup.py install
cd ../../
git clone https://github.com/yunjey/pytorch-tutorial.git
cd pytorch-tutorial/tutorials/03-advanced/image_captioning/
pip install -r requirements.txt设置完系统后,就该下载所需的数据集并且训练模型了。这里我们使用的是MS-COCO数据集。可以运行如下命令来自动下载数据集:
chmod +x download.sh
./download.sh
现在可以继续并开始模型的构建过程了。首先,你需要处理输入:
# Search for all the possible words in the dataset and
# build a vocabulary list
python build_vocab.py
# resize all the images to bring them to shape 224x224
python resize.py
现在,运行下面的命令来训练模型:
python train.py --num_epochs 10 --learning_rate 0.01来看一下被封装好的代码中是如何定义模型的,可以在model.py文件中找到:
import torch
import torch.nn as nn
import torchvision.models as models
from torch.nn.utils.rnn import pack_padded_sequence
from torch.autograd import Variable
class EncoderCNN(nn.Module):
def __init__(self, embed_size):
"""Load the pretrained ResNet-152 and replace top fc layer."""
super(EncoderCNN, self).__init__()
resnet = models.resnet152(pretrained=True)
modules = list(resnet.children())[:-1] # delete the last fc layer.
self.resnet = nn.Sequential(*modules)
self.linear = nn.Linear(resnet.fc.in_features, embed_size)
self.bn = nn.BatchNorm1d(embed_size, momentum=0.01)
self.init_weights()
def init_weights(self):
"""Initialize the weights."""
self.linear.weight.data.normal_(0.0, 0.02)
self.linear.bias.data.fill_(0)
def forward(self, images):
"""Extract the image feature vectors."""
features = self.resnet(images)
features = Variable(features.data)
features = features.view(features.size(0), -1)
features = self.bn(self.linear(features))
return features
class DecoderRNN(nn.Module):
def __init__(self, embed_size, hidden_size, vocab_size, num_layers):
"""Set the hyper-parameters and build the layers."""
super(DecoderRNN, self).__init__()
self.embed = nn.Embedding(vocab_size, embed_size)
self.lstm = nn.LSTM(embed_size, hidden_size, num_layers, batch_first=True)
self.linear = nn.Linear(hidden_size, vocab_size)
self.init_weights()
def init_weights(self):
"""Initialize weights."""
self.embed.weight.data.uniform_(-0.1, 0.1)
self.linear.weight.data.uniform_(-0.1, 0.1)
self.linear.bias.data.fill_(0)
def forward(self, features, captions, lengths):
"""Decode image feature vectors and generates captions."""
embeddings = self.embed(captions)
embeddings = torch.cat((features.unsqueeze(1), embeddings), 1)
packed = pack_padded_sequence(embeddings, lengths, batch_first=True)
hiddens, _ = self.lstm(packed)
outputs = self.linear(hiddens[0])
return outputs
def sample(self, features, states=None):
"""Samples captions for given image features (Greedy search)."""
sampled_ids = []
inputs = features.unsqueeze(1)
for i in range(20): # maximum sampling length
hiddens, states = self.lstm(inputs, states) # (batch_size, 1, hidden_size),
outputs = self.linear(hiddens.squeeze(1)) # (batch_size, vocab_size)
predicted = outputs.max(1)[1]
sampled_ids.append(predicted)
inputs = self.embed(predicted)
inputs = inputs.unsqueeze(1) # (batch_size, 1, embed_size)
sampled_ids = torch.cat(sampled_ids, 1) # (batch_size, 20)
return sampled_ids.squeeze()现在测试我们的模型:
python sample.py --image='png/example.png'对于样例图片,我们的模型给出了这样的输出:

<start> a group of giraffes standing in a grassy area . <end>
<start>一群长颈鹿站在草地上<end>以上就是如何建立一个用于image captioning的深度学习模型。
下一步工作
以上模型只是冰山一角。关于这个主题已经有很多的研究。目前在image captioning领域最先进的模型是微软的CaptionBot。可以在他们的官网上看一个系统的demo.
我列举一些可以用来构建更好的image captioning模型的想法:
结语
这篇文章中,我介绍了image captioning,这是一个多模态任务,它由解密图片和用自然语句描述图片两部分组成。然后我解释了解决该任务用到的方法并给出了一个应用演练。 对于好奇心强的读者,我还列举了几条可以改进模型性能的方法。
希望这篇文章可以激励你去发现更多可以用深度学习解决的任务,从而在工业中出现越来越多的突破和创新。如果有任何建议/反馈,欢迎在下面的评论中留言!
原文发布时间为:2018-04-25
本文作者:FAIZAN SHAIKH






