摘要:本文介绍了C++对象模型的特殊之处,包括与C兼容的朴素模型,以及能支持多态的虚表模型,同时还带大家了解了构造函数与析构函数相关的一些特性与陷阱。这些内容能够帮助大家更好地学习和使用C++。
数十款阿里云产品限时折扣中,赶紧点击这里,领劵开始云上实践吧!
演讲嘉宾简介:
付哲(花名:行简),阿里云高级开发工程师,哈尔滨工业大学微电子学硕士,主攻方向为分布式存储与高性能服务器编程,目前就职于阿里云表格存储团队,负责后端开发。
以下内容根据演讲嘉宾视频分享以及PPT整理而成。
本次的分享主要围绕以下两个方面:
一、C++对象模型的特殊之处
二、构造函数与析构函数相关的一些特性与陷阱
大家都知道,做好云服务,项目首先要保持稳定,不能总出现bug,另外,还要提供好的性能,而要达到这两点,项目开发人员需要深入理解C++这门语言以及语言背后的实现原理,即编译器如何实现这些C++语言带来的特性。
下面首先介绍一下什么是对象模型。
第一个问题,什么是对象模型?
C++ Primer的一位作者Lippman在他的另一部非常经典的作品《深入探索C++对象模型》中有如下总结:有两种概念可以解释C++对象模型,一是语言中直接支持面向对象的程序设计的部分;二是对于各种支持的底层实现机制。说得直白一点,对象模型就是要在我们脑海中建立起一种模型,这种模型能告诉我们C++对象为什么要设计成这个样子,这种设计带来的优缺点以及编译器在背后做了什么事情。
上面介绍了对象模型的含义,那么学习对象模型的意义是什么呢?——当我们脑海里建立起了这个模型,对象就不再神秘,它的行为我们自己都可以推理出来。总而言之,对象模型能告诉我们如何正确而高效地使用对象。另一点,C++是一门多范式语言,不只有面向对象这一块。但其它部分也还是建立在对象模型基础上的,因此了解对象模型,对学习其它C++特性也很有帮助。
一、C++对象模型的特殊之处
现在流行的面向对象语言非常多,比如Java、C#、Python、Ruby、JavaScript,以及先行者SmallTalk,这些语言都有自己的对象模型。那么相比这些模型,C++对象模型有什么特殊之处吗?
C++在最开始的时候,目标是成为C with class,这体现了它的两大卖点:一是与C兼容,二是面向对象,也就是要有多态。而另一方面,C++的一个设计哲学就是零开销抽象,即开发人员做一个抽象,或者说一个特性,不会给不使用它的用户带来额外的开销。C++对象模型就深受这三条的影响,形成了它的特点——既要与C兼容;同时要能表达面向对象的理念,即体现多态;也要保证零开销抽象。因此C++的对象既可以像C的结构体,又可以像Java/C#中的对象。它既可以有复杂的功能,又可以在不同场景下都保持很高的执行效率,这就是它的特殊之处。
下面先从先从兼容C那部分介绍:Niklaus Wirth有句非常著名的话,叫“数据结构加算法等于程序”,这也是他的一本书的名字。C的抽象数据结构就体现了这句话,它就是数据结构加上操作这个数据结构的若干个函数。这就相当于是C的对象模型。把它搬到C++里,就是C++的朴素对象模型,数据结构,也就是C++的类,加上成员函数,就等于对象。朴素对象模型是完整的C++对象模型的一个子集,也是基础,它体现了面向对象中封装的部分。下图说明了C++的数据结构。

我们看TreeNode类型,它代表了红黑树中的一个节点。它既是C的结构体,也是C++的类,两者是兼容的,那么也能够分配在栈上,也不会初始化成员变量的值。对于这么一个类,没有任何成员函数,只关心两个东西,一个是它占多少空间,一个是它的空间结构是什么样的,或者说它的每个成员变量在类里的偏移是多少。在64位环境中执行下图左侧的代码,右侧展示了代码的输出结果。
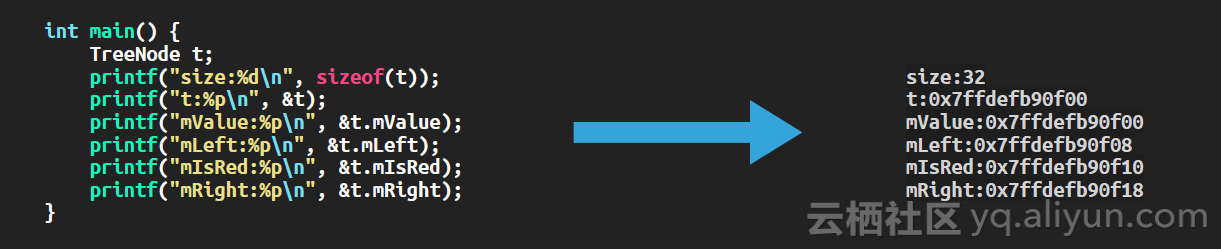
输出结果显示,这个对象占32个字节,其中mValue的偏移是0,mLeft的偏移是8,mIsRed的偏移是16,mRight的偏移是24。
是不是看出问题了,为什么每个成员的偏移都比上个成员大8字节?我们知道64位环境中指针是占8个字节的,int32_t是占4个字节的,bool是占1个字节的,为什么后一个成员的地址减去前一个成员的地址,结果不等于前一个成员占的空间大小呢?这是因为编译器为我们做了对齐和填充。编译器为什么要做这个事情?cpu有个概念叫字长,是它处理数据的一个单位。有些cpu甚至要求访问内存时,内存地址必须是字长的整数倍,否则就报错。有些cpu不报错,但访问跨字长的数据时,会将一次操作拆成多次操作,影响性能。x86-64下这些问题倒是没有,但编译器为了兼容以前的代码,还是会按x86的标准调整每个变量的位置,使其能对齐。这样一来不同变量之间就不是紧凑布局了,就会有空隙。x86的标准是,大小为1、2、4、8字节的变量,内存地址也要能被1、2、4、8整除。结构体的话如果没有成员,是个空结构体,那么就按1处理,如果有成员,就按里面对齐标准最严格的那个处理。
因此我们看到的TreeNode类,它的内存布局实际是这样的,如下图所示。编译器在mValue和mIsRed后面都加了填充,以此来保证每个成员都按各自的标准是对齐的。

可以看到,TreeNode的成员排列似乎不太合理,填充太多,如果调整一下成员的顺序,把mIsRed前提,与另一个比较小的成员mValue排在一起(如下图所hi),这样填充就变少了, TreeNode对象也变小了,从32个字节降到了24个字节。如下图所示。

如果想添加一个前序遍历树节点的函数Visit,有两种方式,一种是像C一样,定义一个全局函数,它的参数是TreeNode的指针。这种我们叫非成员函数,意思是它不是任何类的成员。而另一种方式是把Visit加到TreeNode类里面去,这样它就不需要有参数了。这种我们叫成员函数。如下图所示。

加完了成员函数后,我们重新跑一下前面的main函数,结果就不贴出来了。可以看到TreeNode对象仍然占24个字节,这说明成员函数不占用对象的体积。换句话说,成员函数不位于对象内部,也是在外部。
我们在gcc5.4.0下编译这两个函数,打开优化,对比它们的汇编指令,结果有点长,就不贴了。结论是成员函数版本的Visit与非成员函数版本的Visit汇编指令是完全相同的。这说明成员函数与非成员函数是等效的,我们把函数移到类里面不会给对象的使用带来任何额外的开销。
以上两条结论,充分显示了C++的朴素对象模型就是一种零开销抽象。
朴素对象模型就介绍到这里。接下来我们开始探索支持多态的对象模型。
本文说到的多态指的是一种运行期的多态,C++中是通过继承和虚函数来支持的。一般模式是基类有虚函数,然后派生类继承自基类,并改写这个虚函数。之后可以把派生类的指针或者引用传给需要基类的指针或者引用的地方,这些地方去调用这个虚函数时,会去执行派生类改写的那个版本。这就是运行期多态。
刚才本文在朴素对象模型中讲的是非虚的成员函数,编译器在编译时就能决定到底调用哪个函数,这叫做静态绑定。而参与多态的虚函数,编译时是不知道具体要调用哪个函数的,是基类的还是派生类的,要在运行期才能确定,这叫做动态绑定。
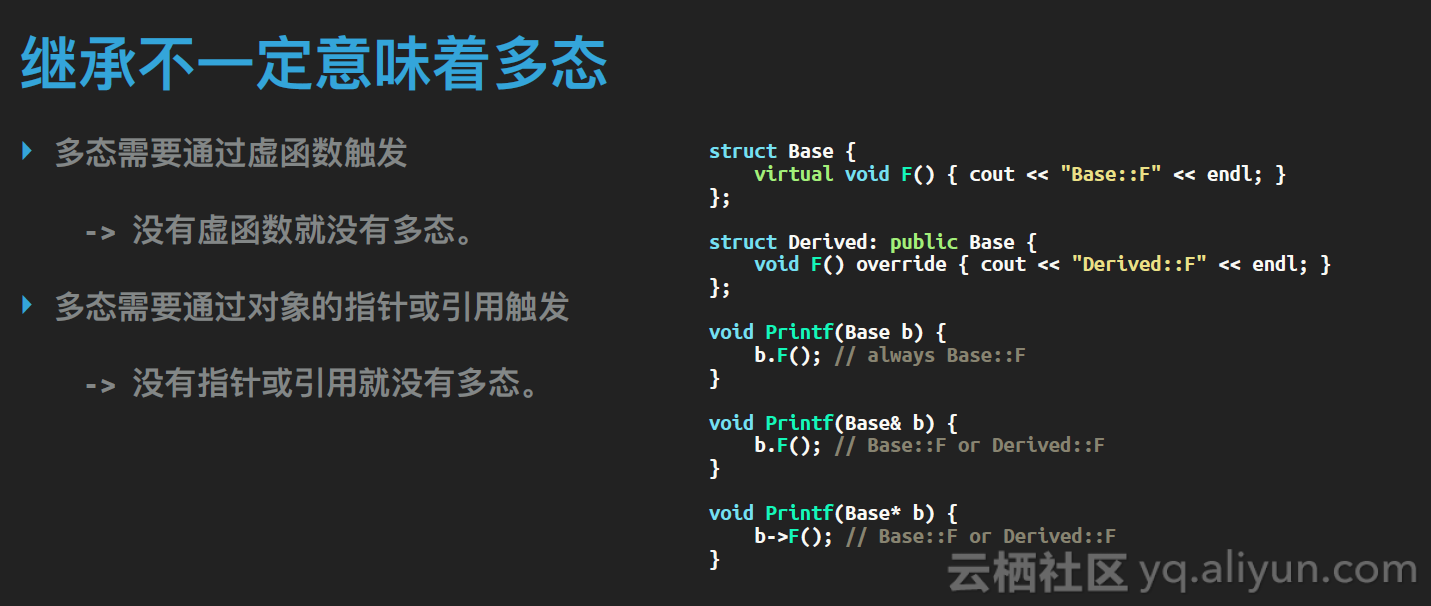
另外我们要明确的是,继承不一定意味着多态。多态有两个触发条件,一个是必须要通过虚函数触发,那么如果我们调用的基类成员函数不是虚函数,就只会有静态绑定。下图的例子中,Base有个成员函数F,不是虚函数,那么Derived就没办法改写它,只能重载它,这里就不会有多态。

多态的另一个触发条件是它一定要通过指针或者引用去调用,如果直接通过对象的话是没办法触发多态的。这个的原因是C++不同类型有着不同的大小,如果直接传对象的话,它的大小是固定的,类型也就固定了,基类就是基类,不会是派生类。而指针和引用就不同了,无论什么类型的指针和引用都是8个字节,这样我们才能让一个指针或引用可能扮演多个类型的对象。
下图的例子中,三个函数里,第一个就没办法触发多态,而后两个就可以。
我们再回到数据结构。当我们让一个派生类去继承自一个基类,这个过程中派生类的数据结构发生了什么变化呢?C++标准规定,派生类的对象里面,每个基类都要对应有一个基类子对象。它就像是派生类自己的一个成员,要求是这个基类子对象要与一个独立的基类对象完全相同。
我们可以看下图的例子:
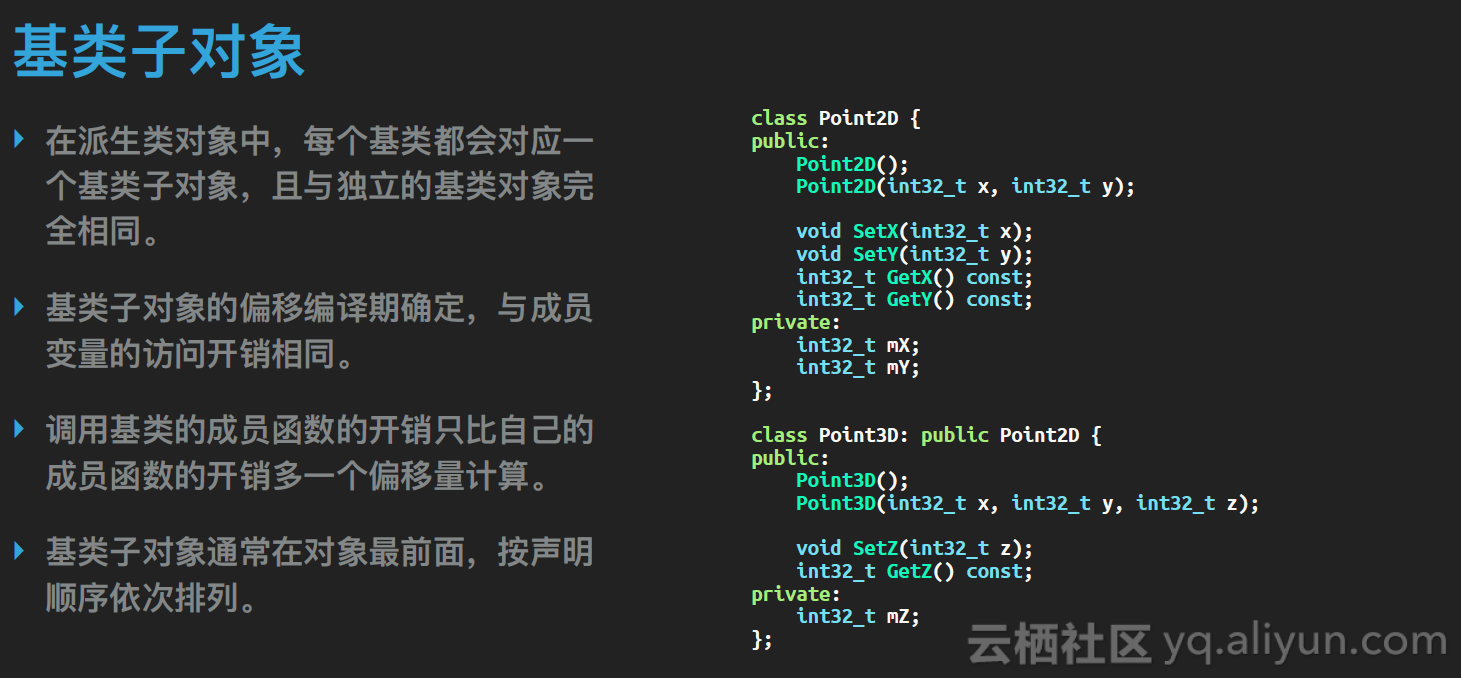
Point2D是一个表示二维的点的类型,而Point3D扩展了它,加了一个维度,变成了三维的点。为了重用代码,我们选择Point2D作为基类,而Point3D继承自它。Point3D对象里面就可以认为有一个Point2D的子对象,且与一个单独的Point2D对象在各方面都是相同的。
每个基类子对象在派生类对象中的偏移在编译期就固定下来了。这个值标准中没有规定,但常见的编译器都选择把基类子对象放到派生类对象的头部,如果有多个基类,那么它们的子对象按声明顺序依次排列。第0个基类子对象的偏移是0,也就是它与派生类对象共享相同的内存地址。
这样当我们通过派生类对象调用基类的成员函数时,编译器只需要简单的计算一下偏移,移到对应的基类子对象地址,再调用函数就可以了。相比独立的基类对象去调用函数,没有什么多出来的开销。
而且无论我们继承几层,都只是计算一次偏移,不会随着继承层数的增加而导致调用开销也跟着增加。这又是一个体现C++对象模型是零开销抽象的地方。
接下来,我们真正进入面向多态的对象模型。
首先我们要明确的是,一种发生在运行期的特性,一定是有运行期开销的,尤其是对于C++这种几乎把运行开销降到最低的语言。那么对象模型要支持发生在运行期的多态,就需要付出一些代价。比如在对象中记录一些信息,比如函数调用路径变长,等等。但C++保证了,如果开发人员不用多态,就不会有这些运行期开销,也就是前面介绍的朴素对象模型。即使有了多态,它也尽量将这种开销降到了最低。下面我们来看三个可以支持多态的模型。我们以下图中这个类为例:
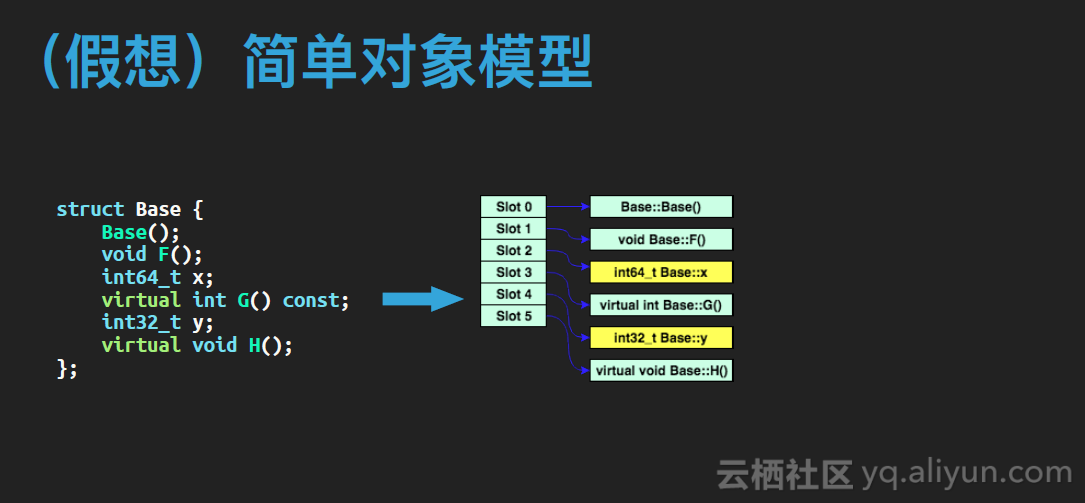
这种模型很简单,它认为对象就是一个表格,其中每个位置都是一个指针,指向一个成员,这个成员包括成员变量和成员函数,我们在访问成员时就是根据这个表格中这个成员的位置,找到这个指针,再跳转过去访问真正的成员。这种模型很简单,编译器实现难度很低。而且我们注意到,这个模型可以不需要区分虚函数或非虚函数,因为大家都要跳转一次,都是动态绑定。它的缺点也很明显,首先是不与朴素模型兼容,其次是访问成员要至少一次间接寻址,开销比较大。因此没有编译器真的采用过简单对象模型。
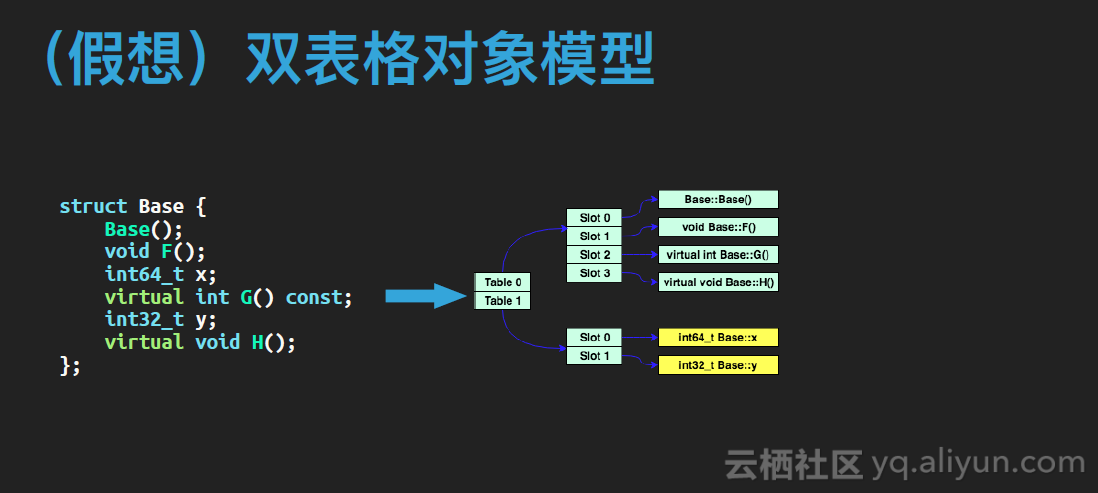
接下来这种模型类似于简单对象模型,但它把成员变量和成员函数分到了两个表格中。这么做的好处是这样无论什么类型的对象,大小和布局都一样了。模型如下图所示。当然双表格模型也有着与简单模型相同的缺点,就是不兼容朴素模型,且开销较大。
实际上,所有编译器都采用了虚表模型。它相比朴素模型,只有一个区别:对象里会增加一个虚表指针。这个虚表指针实际会指向一个表格,这个表格有N+1个位置,分别放指向这个对象本身的信息的指针,类型为type_info*,和N个指向虚函数的指针。模型如下所示,每个类型都有自己的虚表,其中派生类的虚表会与基类的虚表兼容,但指向类型信息那个指针会指向派生类自己的类型信息。这个模型的优点就是首先与朴素模型兼容,如果类没有虚函数,它的对象中就不会有虚表指针,此时就与朴素模型完全相同了。
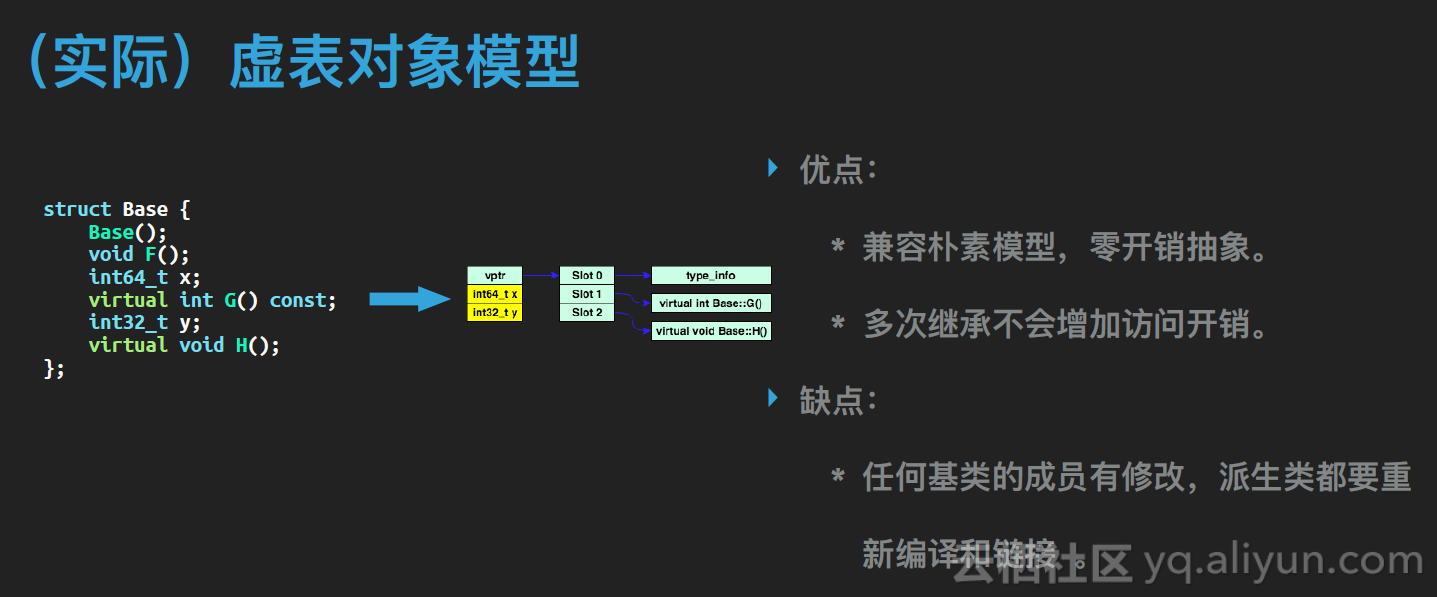
第二个优点是这是一个平铺的结构,如果我们多次继承,多次改写一个虚函数,它的访问开销始终只会有一次间接寻址,不会随着继承层数增加而增加。
它的缺点实际上也是朴素模型的缺点,就是每个派生类都要知道它的每个基类的内存布局,无论哪个基类修改都会导致派生类也要跟着重新编译和链接。
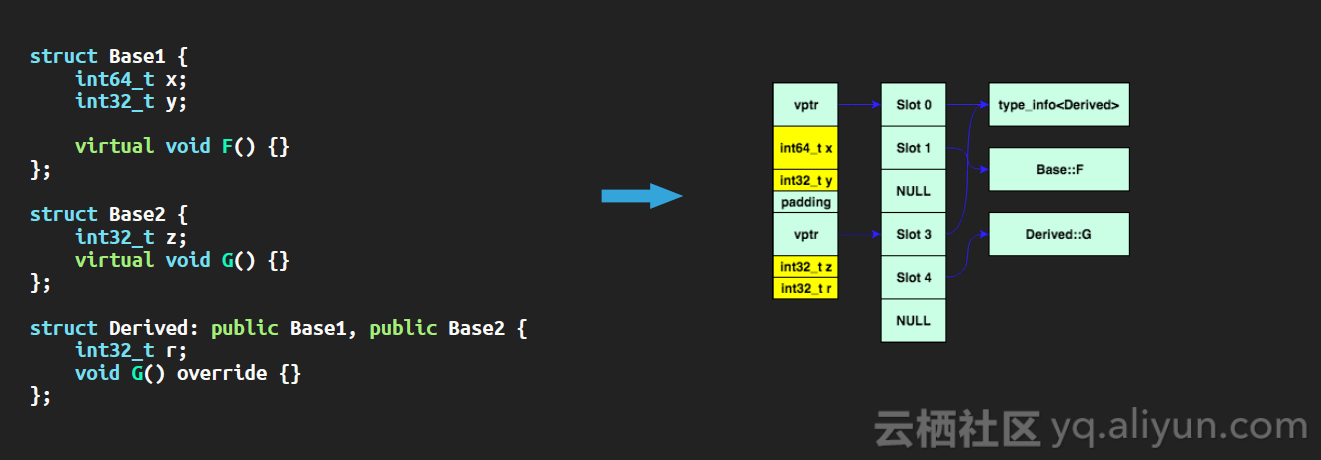
下面,我们介绍一下多基类下的虚表对象模型,如下图所示中的例子:

这里面Derived有两个基类,且都有虚函数,因此两个基类子对象都需要一个虚表指针。这里值得注意的是这两个虚表指针实际指向的是同一个虚表的不同位置。派生类的虚表会同时包含每个基类的虚表,只要指向不同位置,就能兼容不同基类的虚表。因此这个多基类例子里,Derived的对象实际如下所示。
我们知道C++有四种转换,static_cast、dynamic_cast、const_cast和reinterpret_cast,另外C++还允许用C风格的转换,就是圆括号里写上目标类型。在支持多态的对象模型下,我们有两种转换需求,一种是派生类的指针或引用到基类的指针或引用的转换,称为up-cast,一种是基类的指针或引用到派生类的指针或引用的转换,称为down-cast。
up-cast与派生类指针或引用到基类的指针或引用的隐式转换实际是相同的,这里我们应该用的是static_cast,它会根据基类子对象的偏移,应用到源对象的地址上,生成一个指向这个基类子对象的指针或引用。C风格的转换也会修正偏移,但我们还是推荐用static_cast,因为它更醒目。dynamic_cast不适用于这种场景,而reinterpret_cast用在这里是错的,它不会考虑基类子对象的偏移,在多基类时实际会得到一个错误的地址。
down-cast场景应该用的是dynamic_cast,它首先会根据基类子对象的偏移,计算出目标的派生类地址,并且还会拿出这个地址对应的类型信息,看到底能不能转换成功,如果转换失败就返回一个空指针。而static_cast和C风格的转换只能做到前面一点,它会计算偏移量,但识别不出来转换失败。reinterpret_cast就更不能用了,它连偏移量都不会算。
二、构造函数与析构函数相关的一些特性与陷阱
接下来我们简单介绍一下构造函数与析构函数。构造函数会在一个对象被构造时触发,这个对象可能构造在栈上,也可能构造在堆上,后者一般就是通过new来构造。而析构就是与构造相对,当一个栈上对象离开定义的作用域时,这个对象会自动析构,而对于堆上构造的对象,我们也可以通过delete来手动析构。
构造函数会依次做这么几件事情:
* 按声明顺序依次构造每个基类子对象。
* 设置虚表指针,指向正确的虚表位置。
* 按声明顺序依次构造每个成员变量。
* 依次调用构造函数体中的语句。
而析构函数则是反过来,做这几件事:
* 依次调用析构函数体中的语句。
* 按声明逆序依次析构每个成员变量。
* 按声明逆序依次析构每个基类子对象。
构造函数和析构函数有一个特别的地方,它们的执行过程中没有多态,虚函数的调用也会走静态绑定。如果不这么做,当构造基类子对象时,我们调用到了一个被派生类改写过的虚函数,它可能会访问到派生类自己的成员变量,但此时这些成员变量还没有构造,产生的行为是不可预期的。因此构造函数期间不能有动态绑定。而析构函数也是相同原因。
一般来说对象的构造时间都是比较好确定的,而它的析构时间则有些值得注意的点:
* 全局/静态变量在main函数之后析构。
* 局部变量在出定义的作用域后析构。
* 临时变量在其所在的最外层表达式执行完成后析构。
* 被赋值给const引用的临时变量,在引用出作用域后析构。
* 被赋值给右值引用的临时变量,在引用出作用域后析构。
接下来我们来看几个构造函数和析构函数的陷阱。
1. 成员初始化列表要按声明顺序
第一个陷阱是在写构造函数的初始化列表时成员顺序与声明顺序不同,如果其中还有声明靠前的成员依赖声明靠后的成员的值,那会产生未定义行为。下图展示一个例子。原因是成员会按声明顺序而非列表顺序构造。如果初始化列表顺序不同于声明顺序,编译器会警告。因此不能依赖声明顺序靠后的其它成员。为了避免这个问题,推荐严格按照成员的声明顺序写初始化列表。

2. 尽量在初始化列表中构造成员
第二个陷阱是对于有构造函数的成员,如果我们在构造函数体内去做赋值,可能会浪费之前的构造。如下图中展示的例子。看这个例子:

原因是:进入构造函数体前所有成员都已构造完,另外,构造函数体中再赋值会浪费一次构造。为了避免这个问题,推荐成员的构造都通过初始化列表来做,尽量不要放到构造函数体中做赋值。
3.不同编译单元全局变量构造不能相互依赖
第三个陷阱是一个cpp文件中的全局变量,用于构造它的值来自另一个cpp文件中的全局变量,也可能会产生未定义行为。我们来看下图中的例子:

原因是:全局变量在main函数前串行构造;不同编译单元的构造顺序随机;A可能早于依赖的B构造,结果未定义。静态变量本质上也是全局变量,因此也会遇到这个问题。
我们并不推荐程序中使用全局变量或静态变量,但如果真要用的话,可以参考上图箭头下方的用法。
4. 单参数构造函数应声明为explicit
第四个陷阱是如果我们写了一个单参数的构造函数,但未声明为explicit,那么可能会产生预期之外的隐式转换。如下图所示:

因此我们推荐所有单参数的构造函数都声明为explicit,如上图箭头下方所示。
5. 析构函数的陷阱
第五个陷阱是析构函数的陷阱,它实际包含两部分。一是类有虚函数,但析构函数不是虚的,它的问题是当一个基类指针指向派生类对象,我们去delete这个指针,它实际只会调用基类的析构函数,因为析构函数不是虚的,没办法有多态行为。这会导致资源泄漏。例子如下图所示:

二是一个纯虚的基类,析构函数也是纯虚的。这会导致派生类析构时,它调用到了这个纯虚基类的析构函数,但没有定义。这会导致构建时链接失败。
因此我们推荐,有虚函数的类,就要有一个虚的析构函数,且要给一个定义,而不管类本身是不是纯虚类。
对于默认构造函数与析构函数,有一个特性,就是编译器在必要时会为没有的类型生成这两个函数。
生成构造函数的条件是:没有自定义的构造函数,且代码中调用了默认构造函数。
生成析构函数的条件是:没有自定义的析构函数,且代码中调用了析构函数。
本文由云栖志愿小组沈金凤整理,编辑百见