摘要:函数式编程是一种“编程范式”,也就是如何编写程序的方法论,其主要思想是把运算过程尽量写成一系列嵌套的函数调用。那么在函数式编程比较火爆的今天,我们为什么要学习它呢?学习函数式编程究竟能为我们带来什么呢?本文或许能给你一点启发。
视频回顾地址: https://yq.aliyun.com/video/play/1415
PPT下载地址: https://yq.aliyun.com/download/2571
演讲嘉宾简介
陶云峰,阿里云高级技术专家,上海交通大学理论计算机科学博士,专注数据存储、分布式系统与计算等领域,写了20多年程序。2000年参加ACM/ICPC大赛,实现亚洲队伍进World Final前十的突破。
以下内容根据演讲视频以及PPT整理而成。
首先实现一个sum函数,在sum函数中传入一个vector<int>,sum所做的工作就是将vector<int>里面的int通过累加器加到一起并返回。

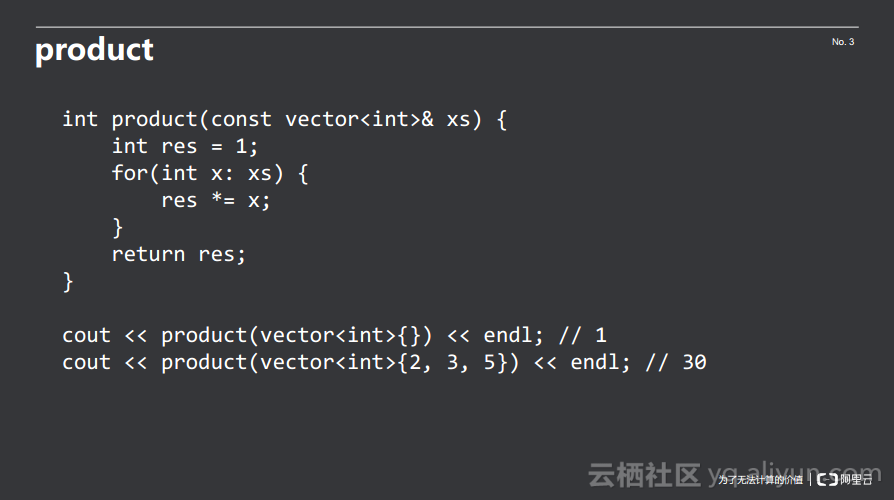
如下代码中实现了一个累乘器。同样传入一个vector<int>,product所做的工作就是将vector<int>里面的int通过累乘起来并返回。
如下代码实现了一个concat,其所做的就是将vector<string>中的每一个string拼接到一起形成一个大的string并返回,其做法与上述的sum和product类似。

可以看到上述所做的累加器、累乘器以及字符串拼接函数都具有相同的结构,那么需要思考如何将其抽象出来。从面向对象的角度来讲,这就是一个策略模式,需要将策略和执行策略的上下文分离开,从函数式编程的角度来讲,可以通过reduce函数来抽象代码结构。
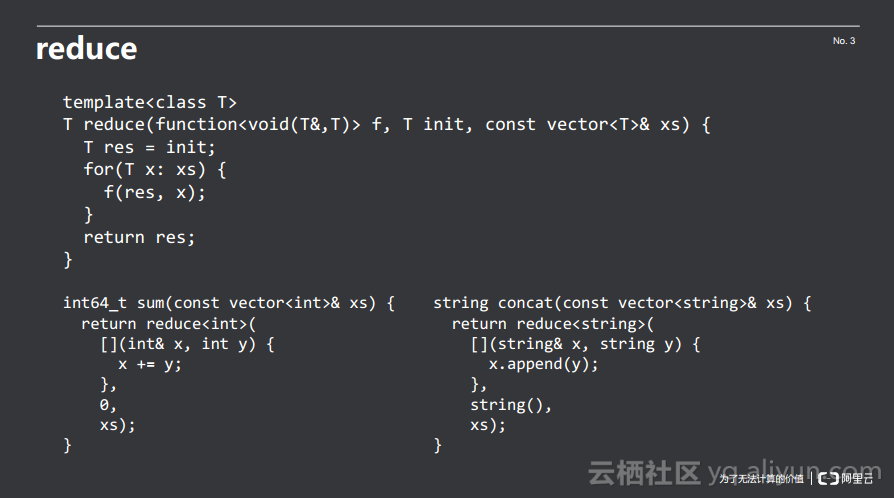
reduce函数具有三个参数,最后一个参数是待处理的数组,其第一个参数是一个函数,该函数接受一个累积的变量和数组中某一个元素,就可以将元素累积到结果上,此外还需要一个初始值init。过程可以被抽象成如上述代码所示。这样sum的实现只需要调用reduce<int>并且初始值赋0,concat的实现只需要调用reduce<string>并且使得初始值为空串即可。这里用到了函数式编程中的技巧——高阶函数。高阶函数在这里面就是把一个函数作为参数传递给另外一个函数。
在下列示例代码中定义了一个树形结构,每个树节点上面都有整数值mPayload,并且还有零到若干个子树可以放到vector里面。现在想要将这颗树上所有节点的值全部加到一起,根据上述的做法可以知道,在实现时可以使用一个reduceTree。reduceTree同样接受三个参数,reduce用的函数、初始值和树的根节点。整个过程大致就是将累积变量定义好,将根节点的mPayload作用上去,然后将每个子树reduce好的结果作用到累积器上。此时想要实现树上节点的值全部加在一起的sum可以通过在累积函数参数上传递一个加法,初始值传递一个0即可。
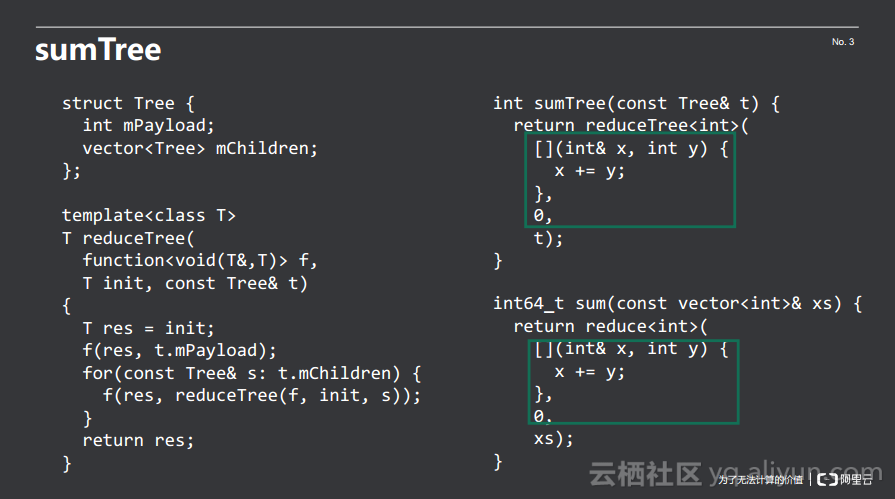
这样就会发现sumTree函数和sum函数内部传递的东西是一模一样的,那么如何将这一部分抽象出来呢?其实可以使用bind函数。首先把加法变成一个函数,然后将add和0绑定到reduce<int>和reduceTree<int>上面去就可以得到所需要的sum和sumTree。这里值得注意的就是bind也是高阶函数的一种,其特征是返回值是函数。通过bind这样的高阶函数可以将代码更进一步地简化。

牛顿-拉夫森迭代
平方根有很多种算法,其中一种就是牛顿-拉夫森迭代,这种方法是一种非常高效的迭代方法。其大致就是如果想要对于x求平方根,那么可以根据迭代的前一项使用这个公式算法来得到后一项。如下代码所实现的就是牛顿-拉夫森迭代,所传入的两个参数分别是所要求平方根的数值和所要误差。在代码中首先定义一个初始值,每次使用牛顿-拉夫森公式计算下一个值,如果前后两个值的偏差小于传入的要求误差就可以返回当前值,否则当前值就变成下一个值继续进行下一次迭代。

求导数
求导数其实就是不停地求斜率,当h逼近0的时候,斜率也就逼近f(x)的导数了。在代码实现中,参数分别是需要求导的函数、函数求导的位置以及误差。h从1.0开始,每一次都会折半,比较当前的斜率和下一次的斜率,如果前后两个斜率误差足够小,结果就可以返回了,否则就继续执行。

这样大家就会发现求导数和牛顿-拉夫森迭代算法都有相同的结构,总体而言,就是都有一个循环迭代,另外循环的终止条件都是由误差决定的。两者的细微差别就是牛顿-拉夫森迭代算法的迭代变量最终返回的结果就是给用户看到的结果,而求导数的迭代变量是h,最终看到是使用h计算出的斜率,而不是h本身。那么如何抽象上述两个算法呢?
方案一
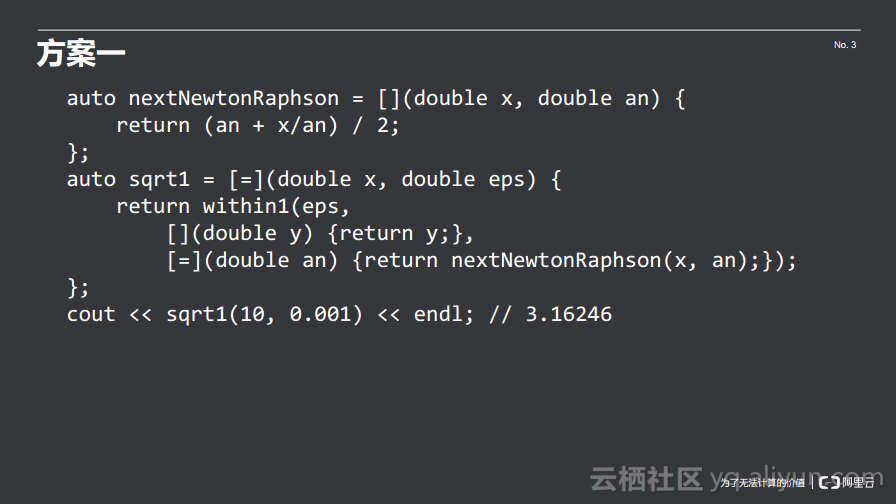
下面定义了within1函数,其参数分别是误差和所要传递的表观函数和状态转移函数。每一次迭代中,状态转移函数负责将当前这个状态变成下一个状态,而表观函数则负责将状态转化成用户需要看到的值,最后利用用户需要看到的前后两个值的差来判断其误差,如果误差足够小就返回,否则就继续迭代。

对于牛顿-拉夫森迭代来讲,其状态转移函数就直接使用牛顿-拉夫森函数即可,其表观函数实际上则不需要,这里可以放置一个恒等函数,输入什么就输出返回什么。
对于求导数而言,状态转移函数就是每次取半,表观函数就是求斜率。这里的示例代码中之所以使用的"sin_"是因为sin()函数是一个重载的函数,其有多重重载方案,所以如果在调用时直接写"sin",编译器无法知道重载哪一个版本,这也是重载函数不如模板特化函数的一点,所以重载函数需要做一个lambda表达式将其包进里面,通过输入的类型为double的x告诉编译器要使用double版本的sin()函数。

从面相对象的角度来讲,方案一的within1函数实际上是一个strategy pattern,配合转移和表观两个strategy。其可以有一些扩展,比如内部状态不一定是double,在设计模式中有一个叫做memento pattern,当然对于C++而言可以使用模板。如果状态转移和表观这两件事情紧耦合,可以使用抽象工厂模式,如果状态转移和表观是松耦合的,则可以使用原型模式。那么是不是这样就足够好了呢?其实并不是的,可以看到无论哪些模式用上去都是比较复杂的,没有within1函数这么简洁。而within1函数简洁的核心之处就在于其使用了高阶函数。那么是不是within1就是最好的方法呢?也不是的,函数式编程又提供了另外一种思考的角度。
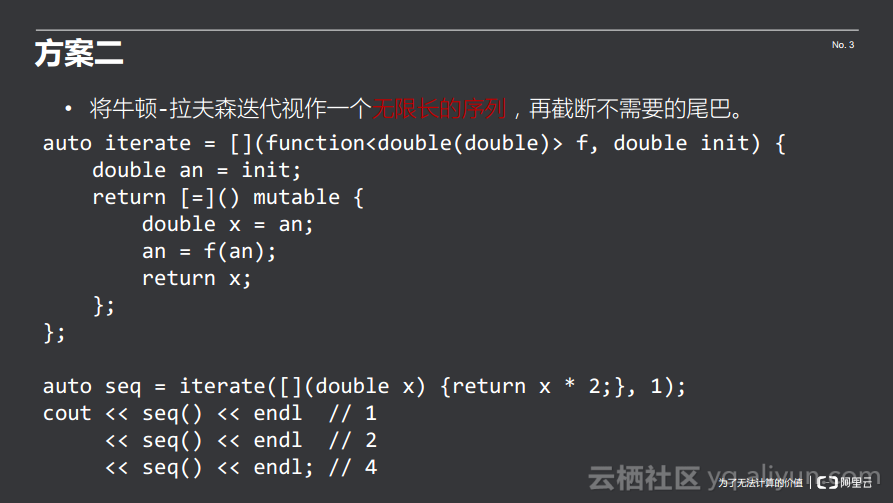
此外还需要进行截断,需要遍历Lazy sequence,并在遍历过程中截断,这也是下列代码中within2所做的事情,每次迭代都会取一个值,当前一个值和后一个值的误差足够小之后就结束。

牛顿-拉夫森迭代算法就可以变成如下代码的形式,函数传递一个x并传递一个误差值,每次向下走的时候就是牛顿-拉夫森迭代,这里捕获的就是x,然后产生一个无限长的序列,把序列和误差精度传入到within2函数中去。

在这样的方案中应该如何计算导数呢?大家可以重新看一下求导数的公式,这里的limit记号所代表的是有一个h接近0无限序列,对这个序列求出了一个斜率的序列,当h逼近0的时候,斜率也会逼近一个值,也就是所需要的导函数。从实现的角度而言,将极限逼近的过程视作一个无限长的序列。将一个无限长序列变换到另一个无限长的序列,也就是从h的序列变成斜率的序列,然后截断。其核心就是将一个无限长序列变换到另一个无限长的序列,也就是map所实现的。在函数式编程的语境下面,map就是把一个序列变换成另外一个序列,这与过程式编程中的数据结构map是不同的。对于map而言,其结果仍然是一个无限长的序列,所以其也是一个无参数但是有内部状态的函数,其接受一个变换的函数和无限长序列,并返回一个函数。该函数无参数,其所作的事情就是将输入的序列取一个值,把函数作用上去之后返回。
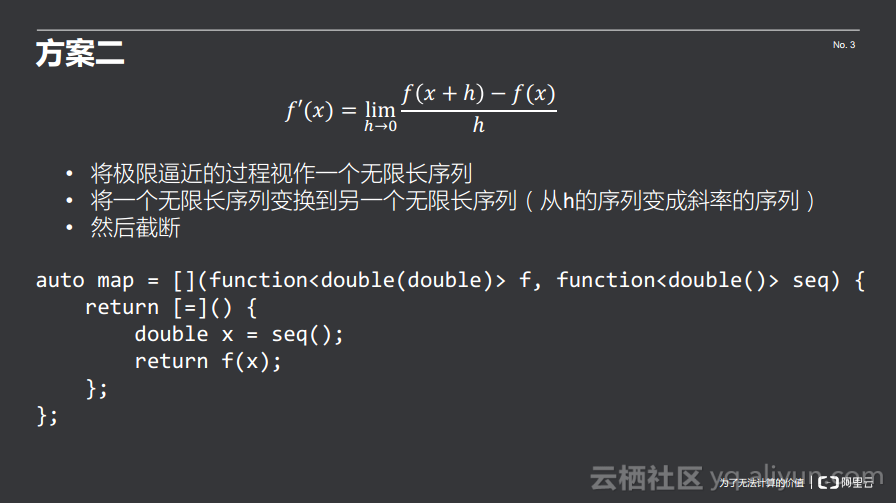
在方案二里面的实现求导数如下所示,首先每次将h取半,通过迭代得到一个无限长的序列seq,然后切斜率函数将其作用在原来的无限长序列上面得到另一个无限长序列,然后使用eps误差进行截断。代码的实现是相当直白的,基本上就是按照limit记号来写的。
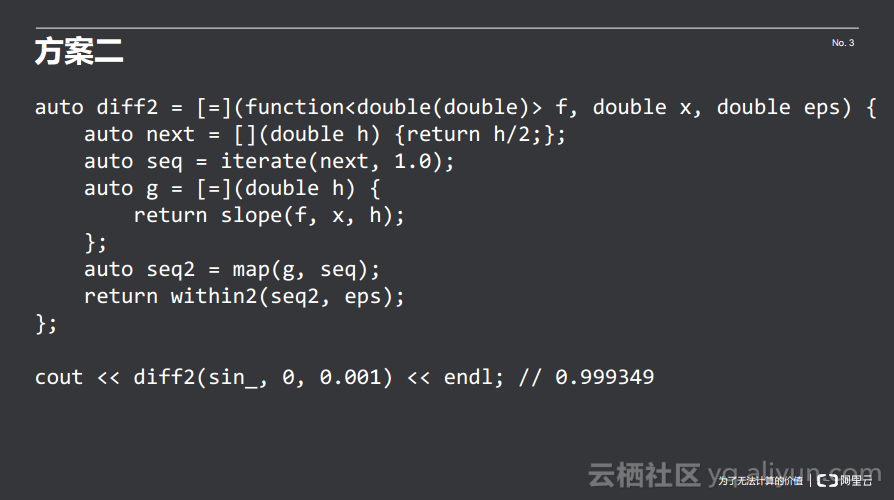
在这个方案中引入了一个无限长序列的概念,而无限长序列在计算机中是无法实现的,所以将其转换成了一个Lazy sequence,除了与业务相关within2函数中的误差属于业务概念外,iterate和map都不是业务的概念。方案二中引入的新增概念就是Lazy sequence和within2,所以方案二比方案一更为直观,需要引入更少的概念,不需要表观和转移,尤其是对于牛顿-拉夫森迭代算法这样的情况,在方案一牛顿-拉夫森迭代算法的表观函数就是一个恒等函数,算法本身不需要表观概念,但是为了套在within1框架中,所以强制搞出来一个表观函数,而在方案二中却是不需要的。总而言之就是方案二比方案一代码实现更简洁,更贴近业务。
总结
总结而言,在本次分享中主要介绍了以下四点:
1. 高阶函数。函数可以作为参数,也可以作为返回值。
2. Lazy sequence。逻辑上的无限长序列,实现中是一个有状态无参数的函数。
3. 新的“胶水”。函数式编程提供了新的建模思路,新的胶合代码组件的方法。“胶水”不同,分解问题的方式也不同。
4. “没有银弹”。如果你手里只有锤子,看什么都像钉子。学习函数式编程是为了丰富你的武器库。
视频回顾地址: https://yq.aliyun.com/video/play/1415
PPT下载地址: https://yq.aliyun.com/download/2571
演讲嘉宾简介
陶云峰,阿里云高级技术专家,上海交通大学理论计算机科学博士,专注数据存储、分布式系统与计算等领域,写了20多年程序。2000年参加ACM/ICPC大赛,实现亚洲队伍进World Final前十的突破。
以下内容根据演讲视频以及PPT整理而成。
首先实现一个sum函数,在sum函数中传入一个vector<int>,sum所做的工作就是将vector<int>里面的int通过累加器加到一起并返回。
在下列示例代码中定义了一个树形结构,每个树节点上面都有整数值mPayload,并且还有零到若干个子树可以放到vector里面。现在想要将这颗树上所有节点的值全部加到一起,根据上述的做法可以知道,在实现时可以使用一个reduceTree。reduceTree同样接受三个参数,reduce用的函数、初始值和树的根节点。整个过程大致就是将累积变量定义好,将根节点的mPayload作用上去,然后将每个子树reduce好的结果作用到累积器上。此时想要实现树上节点的值全部加在一起的sum可以通过在累积函数参数上传递一个加法,初始值传递一个0即可。
牛顿-拉夫森迭代
平方根有很多种算法,其中一种就是牛顿-拉夫森迭代,这种方法是一种非常高效的迭代方法。其大致就是如果想要对于x求平方根,那么可以根据迭代的前一项使用这个公式算法来得到后一项。如下代码所实现的就是牛顿-拉夫森迭代,所传入的两个参数分别是所要求平方根的数值和所要误差。在代码中首先定义一个初始值,每次使用牛顿-拉夫森公式计算下一个值,如果前后两个值的偏差小于传入的要求误差就可以返回当前值,否则当前值就变成下一个值继续进行下一次迭代。
求导数
求导数其实就是不停地求斜率,当h逼近0的时候,斜率也就逼近f(x)的导数了。在代码实现中,参数分别是需要求导的函数、函数求导的位置以及误差。h从1.0开始,每一次都会折半,比较当前的斜率和下一次的斜率,如果前后两个斜率误差足够小,结果就可以返回了,否则就继续执行。
方案一
下面定义了within1函数,其参数分别是误差和所要传递的表观函数和状态转移函数。每一次迭代中,状态转移函数负责将当前这个状态变成下一个状态,而表观函数则负责将状态转化成用户需要看到的值,最后利用用户需要看到的前后两个值的差来判断其误差,如果误差足够小就返回,否则就继续迭代。
方案二
在函数式编程中,可以将牛顿-拉夫森迭代视作一个无限长的序列,再截断不需要的尾巴。而问题是计算机资源是有限的,不可能计算出一个无限长的序列,所以需要Lazy sequence。Lazy sequence逻辑上是一个无限长的序列,但是其元素只有需要的时候才会实际产生出来。在函数式编程中,Lazy sequence就是一个有状态但是无参数的函数,每一次调用都会返回当前的状态并将自己的状态迁移到下一个。下列代码中使用了值捕获,产生一个内部状态,并且加上mutable使得内部状态可以被改变。
总结
总结而言,在本次分享中主要介绍了以下四点:
1. 高阶函数。函数可以作为参数,也可以作为返回值。
2. Lazy sequence。逻辑上的无限长序列,实现中是一个有状态无参数的函数。
3. 新的“胶水”。函数式编程提供了新的建模思路,新的胶合代码组件的方法。“胶水”不同,分解问题的方式也不同。
4. “没有银弹”。如果你手里只有锤子,看什么都像钉子。学习函数式编程是为了丰富你的武器库。


