随着AlphaGo的出现,掀起了深度强化学习(DRL)的浪潮。包括DeepMind、OpenAI在内的众多科研机构和高校都团队都致力于DRL的研究,DRL在游戏、智能机器人控制等领域也取得了不错的成效,如星际争霸相关游戏研发、机器人Atlas等。随着人工智能逐步走入人们的生活,信息物理系统的概念更加为人们熟知。信息物理系统(CPS, Cyber-Physical Systems)是一个综合计算、网络和物理环境的多维复杂系统,通过3C(Computer、Communication、Control)技术的有机融合与深度协作,实现大型工程系统的实时感知、动态控制和信息服务。主要用于一些智能系统上如设备互联,物联传感,智能家居,机器人,智能导航等。因此,信息物理系统(CPS)的安全检测问题成为了重中之重。
近日,软件工程形式化领域顶会FM2018(International Symposium on Formal Methods)接收了天津大学多智能体与深度强化学习实验室与东京大学、日本 AIST 研究所合作的一篇论文,提出利用深度强化学习方法来检测信息物理系统(CPS)模型中的缺陷。与传统方法(simulated annealing and cross entropy)相比,深度强化学习方法在大多数情况下能够通过更少次的模拟实验找出系统的缺陷。
这篇论文创新点为:首次将深度强化学习与违反CPS模型鲁棒性的问题型结合,并取得的较为显著的实验结果;提出了新型测试框架:
1)利用深度强化学习得到被测试系统的输入
2)把输入传入被测试系统,得到系统输出并计算收益值,作为下一轮学习的输入
3)循环以上步骤,检测缺陷。
CPS漏洞检测的传统方法
信息物理系统(CPS)在关键安全领域被应用得越来越广泛,这使得保证信息物理系统的正确性更加重要。在CPS模型上的测试和验证是保证其准确性的通用方法。同时由于CPS模型的状态空间是无限的,使得测试很难达到高覆盖率,验证技术昂贵并且不可判定。因此以鲁棒性为导向的falsification方法近期被认为是可以有效检测CPS缺陷的方法。
以鲁棒性为导向的falsification方法中,信号时序逻辑(STL)通常被用于表示CPS模型应该满足的(鲁棒性)性质。本文提出用以鲁棒性为导向的falsification技术来探索CPS模型的状态空间,并将使鲁棒性最小化的行为序列确定为测试的候选项。利用这种方式,以鲁棒性为导向生成暴露模型缺陷的输入(也就是反例),这样能更有效的并且自动的进行缺陷检测。尽管falsification过程没有终止不代表没有反例,但是在给定的时间内未找到反例在一定程度上显示了CPS模型的正确性。
现有的以鲁棒性为导向的falsification方法采取随机全局优化的算法,比如模拟退火、交叉熵等,来达到最小化鲁棒性的目的。这些方法都把整条轨迹(行为序列)作为输入,因此在falsification过程中需要大量的模拟运行,进而无法保证在有限的时间内找到实际的CPS系统模型中的反例输入。
基于强化学习的CPS模型性质falsification方法
本文应用DRL解决CPS模型违反鲁棒性性质的问题。强化学习方法可以观察环境反馈,然后及时调整输入行为。通过这种方式,该方法可以更快地收敛到最小的鲁棒性数值。本文采用了两种最先进的DRL技术:Asynchronous Advanced Actor Critic (A3C) 和 Double Deep-Q Network (DDQN)。
具体框架如图1所示:该框架的环境包括Matlab的模拟运行环境模块以及计算回报模块。采用经典的强化学习算法,代理(Agent)以系统的当前状态(state)和当前的回报值(reward)作为输入,然后输出下一个行为(action)作为模拟模块的输入。本框架的Agent采用了A3C和DDQN两种算法。
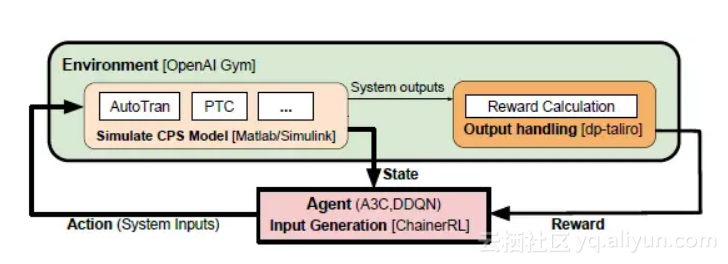
图1:系统的整体框架
本文的主要贡献有:
(1)展示了怎样将找到违反CPS模型鲁棒性性质的行为序列的问题转化为深度强化学习(DRL)问题;
(2)实现提出的方法并进行初步评估,结果证明利用DRL技术可以减少寻找CPS模型致错输入需要的模拟运行次数,进而减少模拟运行的总时间。
(3)提出基于强化学习技术的CPS模型鲁棒性性质falsification问题的测试框架,为进一步探索该问题提供了保障。
本文提出的方法在原型系统中进行了实现,并采用广泛应用的CPS系统模型进行初步评估。实验结果表明,本文提出的方法可以减少发现伪造输入的次数。在自动传输控制系统上运行结果如图2 所示,基于强化学习的方法在成功率上一直优于其他baseline方法。在有限时间内,基于强化学习的方法更容易找到致错输入。
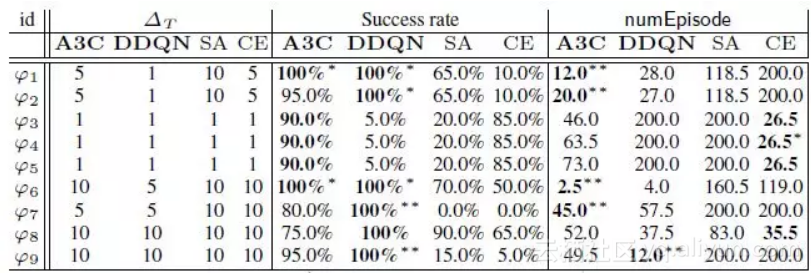
图2:在自动传输控制系统(AT)上运行结果
论文:Falsification of Cyber-Physical Systems Using Deep Reinforcement Learning

原文发布时间为:2018-04-20
本文作者:段义海
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”。


