1.概述
Apache Arrow 是 Apache 基金会全新孵化的一个顶级项目。它设计的目的在于作为一个跨平台的数据层,来加快大数据分析项目的运行速度。
2.内容
现在大数据处理模型很多,用户在应用大数据分析时,除了将 Hadoop 等大数据平台作为一个存储和批处理平台之外,同样也得关注系统的扩展性和性能。过去开源社区已经发布了很多工具来完善大数据分析的生态系统,这些工具包含了数据分析的各个层面,例如列式存储格式(Parquet,ORC),内存计算模型(Drill,Spark,Impala 和 Storm)以及其强大的 API 接口。而 Arrow 则是最新加入的一员,它提供了一种跨平台应用的内存数据交换格式。
在数据快速增长和复杂化的情况下,提高大数据分析性能一个重要的途径是对列式数据的设计和处理。列式数据处理借助了向量计算和 SIMD 使我们可以充分挖掘硬件的潜力。而 Apache Drill 其大数据查询引擎无论是在硬盘还是内存中数据都是以列的方式存在的,而 Arrow 就是由 Drill 中的 Value Vector 这一数据格式发展而来。此外,Arrow 也支持关系型和动态数据集。
Arrow 的诞生为大数据生态带来了很多可能性,有了 Arrow 作为今后标准数据交换格式,各个数据分析的系统和应用之间的交互性可以说是揭开了新的篇章。过去大部分的 CPU 周期都花在了数据的序列化与反序列化上,现在我们则能够实现不同系统之间数据的无缝链接。这意味着使用者在不同系统结合时,不用在数据格式上话费过多的时间。
3.Arrow Group
Arrow 的内存数据结构如下所示:

从上图中,我们可以很清晰的看出,传统的内存数据格式,各个字段的分布是以没一行呈现,相同字段并未集中排列在一起。而通过 Arrow 格式化后的内存数据,可以将相同字段集中排列在一起。我们可以很方便的使用 SQL 来操作数据。
传统的访问各个数据模型中的数据以及使用 Arrow 后的图,如下所示:
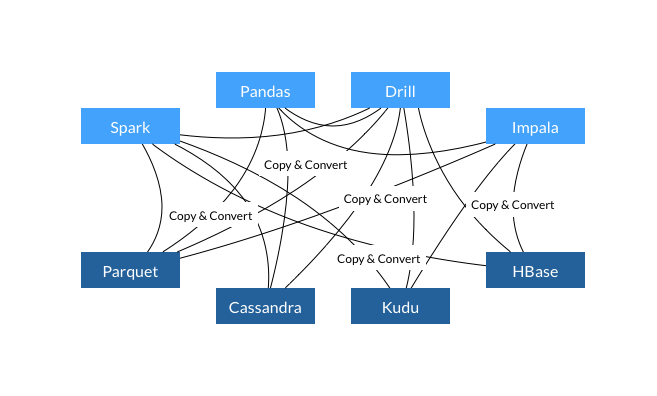
通过上图可以总结出以下观点:
- 每个系统都有属于自己的内存格式。
- 70~80% 的 CPU 浪费在序列化和反序列化上。
- 在多个项目都实现的类似的功能(Copy & Convert)。
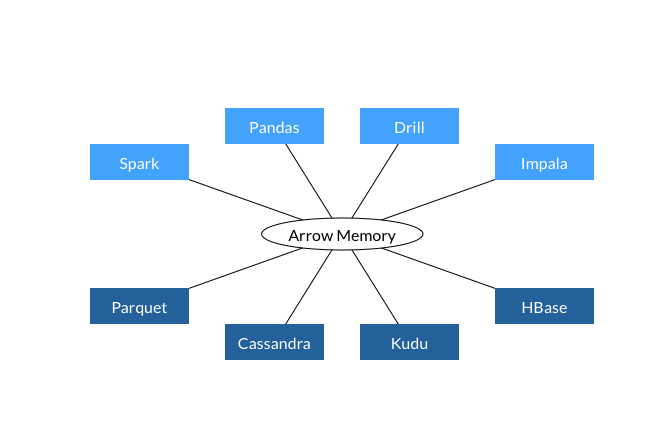
而在看上述使用 Arrow 后,得出以下结论:
- 所有的系统都使用相同的内存格式。
- 没有跨系统通信开销。
- 项目可以贡献功能(比如,Parquet 到 Arrow 的读取)。
4.Arrow 数据格式
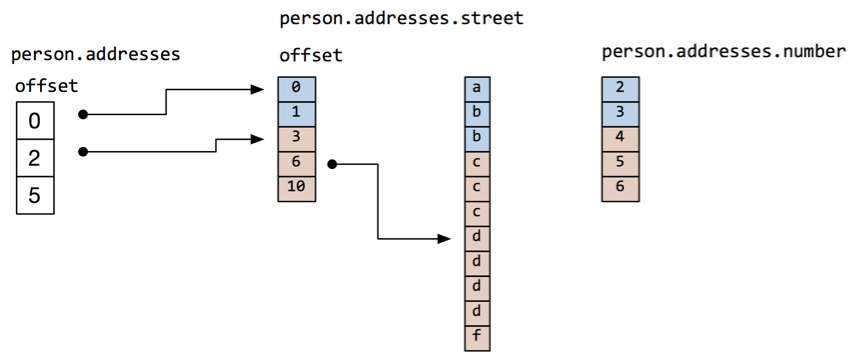
Arrow 列式数据格式如下所示:
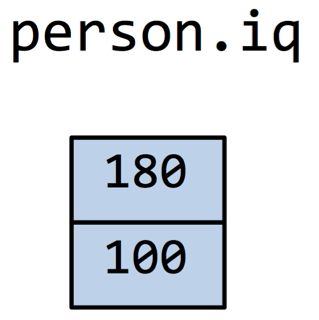
persons = [{ name: 'wes', iq: 180, addresses: [ {number: 2, street 'a'}, {number: 3, street 'bb'} ] }, { name: 'joe', iq: 100, addresses: [ {number: 4, street 'ccc'}, {number: 5, street 'dddd'}, {number: 2, street 'f'} ] }]
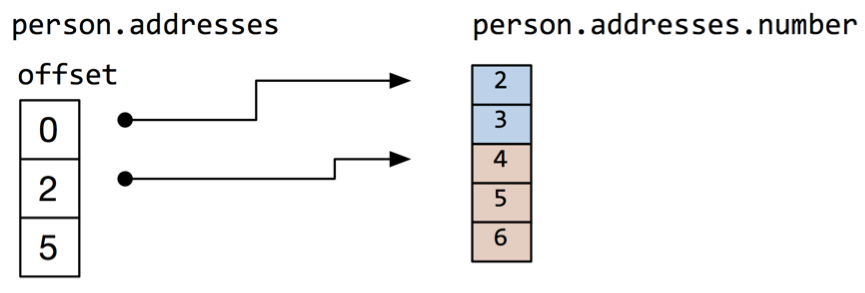
从上述 JSON 数据格式来看,person.iq 分别是 180 和 100,以如下方式排列:
而 persons.addresses.number 的排列格式如下所示:
5.特性
5.1 Fast
Apache Arrow 执行引擎,利用最新的SIMD(单输入多个数据)操作包括在模型处理器,用于分析数据处理本地向量优化。数据的列式布局也允许更好地利用 CPU 缓存,将所有与列操作相关的数据以尽可能紧凑的格式放置。
5.2 Flexible
Arrow 扮演着高性能的接口在各个复杂的系统中,它也支持工业化的编程语言。Java,C,C++,Python 以及今后更多的语言。
5.3 Standard
Apache Arrow 由 13 个开源项目开发者支持,包含 Calcite, Cassandra, Drill, Hadoop, HBase, Ibis, Impala, Kudu, Pandas, Parquet, Phoenix, Spark, 和 Storm。
6.Example
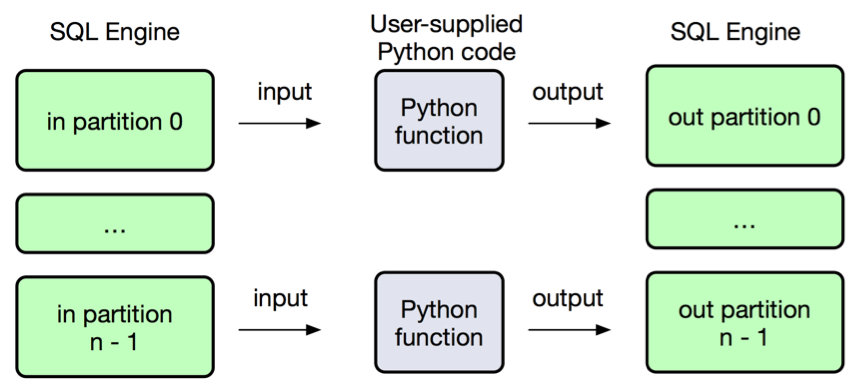
使用 Python 来处理 Spark 或是 Drill 中的数据,如下图所示:
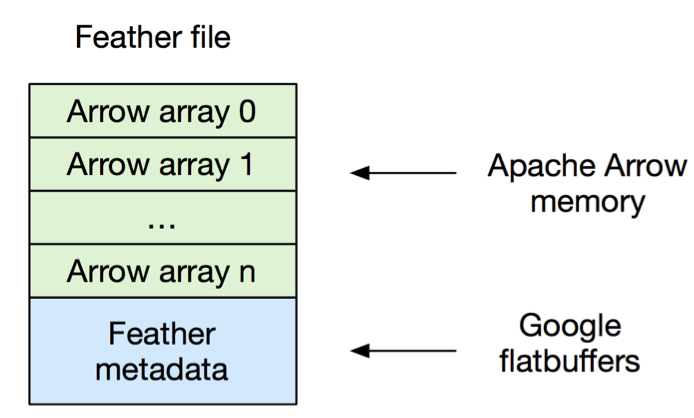
- 快速的、语言无关的二进制数据帧格式的文件。
- 使用 Python 去写。
- 读取速度接近磁盘 IO 性能。
部分实现示例代码,如下所示:
import feather path = 'my_data.feather' feather.write_dataframe(df, path) df = feather.read_dataframe(path)
7.总结
Apache Arrow 当前发布了 0.1.0 第一个版本,官方目前获取的资料的信息较少,大家可以到官方的 JIRA 上获取更多咨询信息,以及 Arrow 提供的开发者聊天室去获取更多的帮助。
8.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
邮箱:smartloli.org@gmail.com
Twitter: https://twitter.com/smartloli
QQ群(Hadoop - 交流社区1): 424769183
温馨提示:请大家加群的时候写上加群理由(姓名+公司/学校),方便管理员审核,谢谢!