1.概述
目前,随着大数据的浪潮,Kafka 被越来越多的企业所认可,如今的Kafka已发展到0.10.x,其优秀的特性也带给我们解决实际业务的方案。对于数据分流来说,既可以分流到离线存储平台(HDFS),离线计算平台(Hive仓库),也可以分流实时流水计算(Storm,Spark)等,同样也可以分流到海量数据查询(HBase),或是及时查询(ElasticSearch)。而今天笔者给大家分享的就是Kafka 分流数据到 ElasticSearch。
2.内容
我们知道,ElasticSearch是有其自己的套件的,简称ELK,即ElasticSearch,Logstash以及Kibana。ElasticSearch负责存储,Logstash负责收集数据来源,Kibana负责可视化数据,分工明确。想要分流Kafka中的消息数据,可以使用Logstash的插件直接消费,但是需要我们编写复杂的过滤条件,和特殊的映射处理,比如系统保留的`_uid`字段等需要我们额外的转化。今天我们使用另外一种方式来处理数据,使用Kafka的消费API和ES的存储API来处理分流数据。通过编写Kafka消费者,消费对应的业务数据,将消费的数据通过ES存储API,通过创建对应的索引的,存储到ES中。其流程如下图所示:
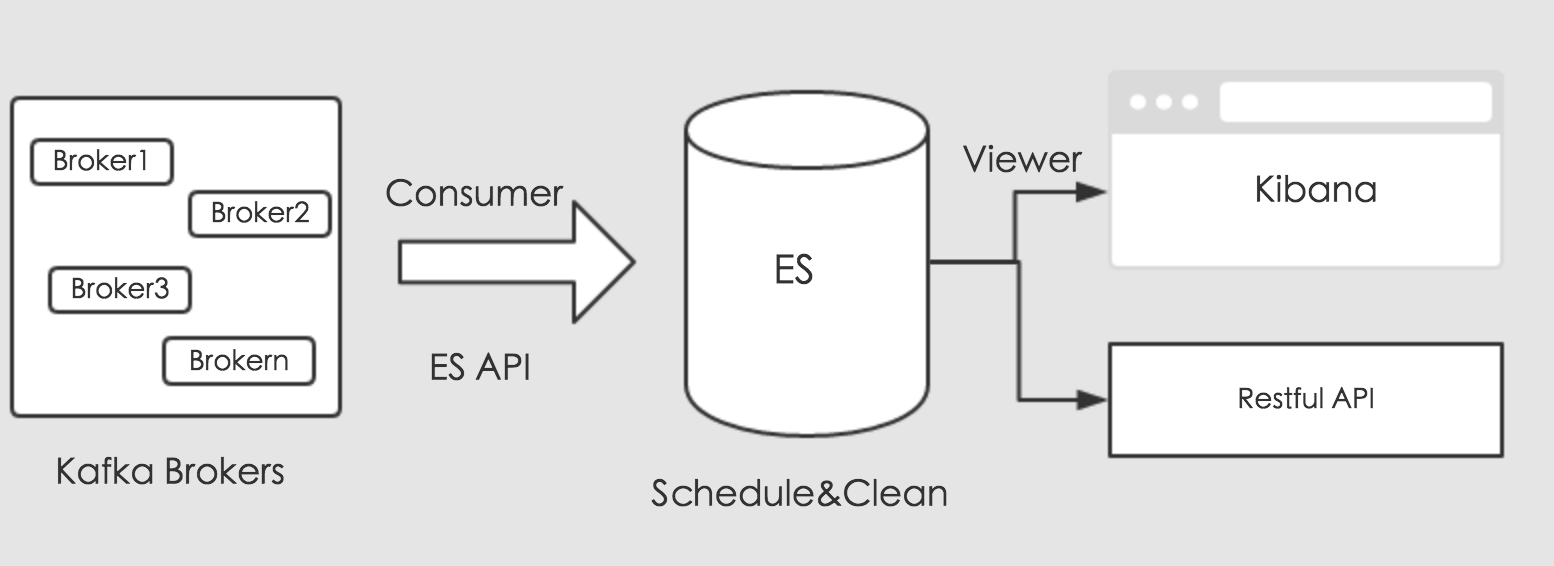
上图可知,消费收集的数据,通过ES提供的存储接口进行存储。存储的数据,这里我们可以规划,做定时调度。最后,我们可以通过Kibana来可视化ES中的数据,对外提供业务调用接口,进行数据共享。
3.实现
下面,我们开始进行实现细节处理,这里给大家提供实现的核心代码部分,实现代码如下所示:
3.1 定义ES格式
我们以插件的形式进行消费,从Kafka到ES的数据流向,只需要定义插件格式,如下所示:
{ "job": { "content": { "reader": { "name": "kafka", "parameter": { "topic": "kafka_es_client_error", "groupid": "es2", "bootstrapServers": "k1:9094,k2:9094,k3:9094" }, "threads": 6 }, "writer": { "name": "es", "parameter": { "host": [ "es1:9300,es2:9300,es3:9300" ], "index": "client_error_%s", "type": "client_error" } } } } }
这里处理消费存储的方式,将读和写的源分开,配置各自属性即可。
3.2 数据存储
这里,我们通过每天建立索引进行存储,便于业务查询,实现细节如下所示:
public class EsProducer { private final static Logger LOG = LoggerFactory.getLogger(EsProducer.class); private final KafkaConsumer<String, String> consumer; private ExecutorService executorService; private Configuration conf = null; private static int counter = 0; public EsProducer() { String root = System.getProperty("user.dir") + "/conf/"; String path = SystemConfigUtils.getProperty("kafka.x.plugins.exec.path"); conf = Configuration.from(new File(root + path)); Properties props = new Properties(); props.put("bootstrap.servers", conf.getString("job.content.reader.parameter.bootstrapServers")); props.put("group.id", conf.getString("job.content.reader.parameter.groupid")); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); consumer = new KafkaConsumer<String, String>(props); consumer.subscribe(Arrays.asList(conf.getString("job.content.reader.parameter.topic"))); } public void execute() { executorService = Executors.newFixedThreadPool(conf.getInt("job.content.reader.threads")); while (true) { ConsumerRecords<String, String> records = consumer.poll(100); if (null != records) { executorService.submit(new KafkaConsumerThread(records, consumer)); } } } public void shutdown() { try { if (consumer != null) { consumer.close(); } if (executorService != null) { executorService.shutdown(); } if (!executorService.awaitTermination(10, TimeUnit.SECONDS)) { LOG.error("Shutdown kafka consumer thread timeout."); } } catch (InterruptedException ignored) { Thread.currentThread().interrupt(); } } class KafkaConsumerThread implements Runnable { private ConsumerRecords<String, String> records; public KafkaConsumerThread(ConsumerRecords<String, String> records, KafkaConsumer<String, String> consumer) { this.records = records; } @Override public void run() { String index = conf.getString("job.content.writer.parameter.index"); String type = conf.getString("job.content.writer.parameter.type"); for (TopicPartition partition : records.partitions()) { List<ConsumerRecord<String, String>> partitionRecords = records.records(partition); for (ConsumerRecord<String, String> record : partitionRecords) { JSONObject json = JSON.parseObject(record.value()); List<Map<String, Object>> list = new ArrayList<>(); Map<String, Object> map = new HashMap<>(); index = String.format(index, CalendarUtils.timeSpan2EsDay(json.getLongValue("_tm") * 1000L)); if (counter < 10) { LOG.info("Index : " + index); counter++; } for (String key : json.keySet()) { if ("_uid".equals(key)) { map.put("uid", json.get(key)); } else { map.put(key, json.get(key)); } list.add(map); } EsUtils.write2Es(index, type, list); } } } } }
这里消费的数据源就处理好了,接下来,开始ES的存储,实现代码如下所示:
public class EsUtils {
private static TransportClient client = null;
static {
if (client == null) {
client = new PreBuiltTransportClient(Settings.EMPTY);
}
String root = System.getProperty("user.dir") + "/conf/";
String path = SystemConfigUtils.getProperty("kafka.x.plugins.exec.path");
Configuration conf = Configuration.from(new File(root + path));
List<Object> hosts = conf.getList("job.content.writer.parameter.host");
for (Object object : hosts) {
try {
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(object.toString().split(":")[0]), Integer.parseInt(object.toString().split(":")[1])));
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void write2Es(String index, String type, List<Map<String, Object>> dataSets) {
BulkRequestBuilder bulkRequest = client.prepareBulk();
for (Map<String, Object> dataSet : dataSets) {
bulkRequest.add(client.prepareIndex(index, type).setSource(dataSet));
}
bulkRequest.execute().actionGet();
// if (client != null) {
// client.close();
// }
}
public static void close() {
if (client != null) {
client.close();
}
}
}
这里,我们利用BulkRequestBuilder进行批量写入,减少频繁写入率。
4.调度
存储在ES中的数据,如果不需要长期存储,比如:我们只需要存储及时查询数据一个月,对于一个月以前的数据需要清除掉。这里,我们可以编写脚本直接使用Crontab来进行简单调用即可,脚本如下所示:
#!/bin/sh # <Usage>: ./delete_es_by_day.sh kafka_error_client logsdate 30 </Usage>
echo "<Usage>: ./delete_es_by_day.sh kafka_error_client logsdate 30 </Usage>"
index_name=$1 daycolumn=$2 savedays=$3 format_day=$4 if [ ! -n "$savedays" ]; then echo "Oops. The args is not right,please input again...." exit 1 fi if [ ! -n "$format_day" ]; then format_day='%Y%m%d' fi sevendayago=`date -d "-${savedays} day " +${format_day}` curl -XDELETE "es1:9200/${index_name}/_query?pretty" -d " { "query": { "filtered": { "filter": { "bool": { "must": { "range": { "${daycolumn}": { "from": null, "to": ${sevendayago}, "include_lower": true, "include_upper": true } } } } } } } }" echo "Finished."
然后,在Crontab中进行定时调度即可。
5.总结
这里,我们在进行数据写入ES的时候,需要注意,有些字段是ES保留字段,比如`_uid`,这里我们需要转化,不然写到ES的时候,会引发冲突导致异常,最终写入失败。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉
邮箱:smartloli.org@gmail.com
Twitter: https://twitter.com/smartloli
QQ群(Hadoop - 交流社区1): 424769183
温馨提示:请大家加群的时候写上加群理由(姓名+公司/学校),方便管理员审核,谢谢!