背景
HiTSDB时序数据库引擎在服务于阿里巴巴集团内的客户时,根据集团业务特性做了很多针对性的优化。 然而在HiTSDB云产品的打磨过程中逐渐发现,很多针对性的优化很难在公有云上针对特定用户去实施。
于此同时, 在公有云客户使用HiTSDB的过程中,发现了越来越多由于聚合查询导致的问题,比如: 返回数据点过多会出现栈溢出等错误,聚合点过多导致OOM, 或者无法完成聚合,实例完全卡死等等问题。这些问题主要由于原始的聚合引擎架构上的缺陷导致。
因此HiTSDB开发团队评估后决定围绕新的聚合引擎架构对HiTSDB引擎进行升级,包含: 存储模型的改造,索引方式的升级,实现全新的流式聚合,数据迁移,性能评测。 本文主要围绕这5个方面进行梳理,重点在“全新的流式聚合部分”。
1. 时序数据存储模型:
1.1 时序的数据存储格式。
一个典型的时序数据由两个维度来表示,一个维度表示时间轴,随着时间的不断流入,数据会不断地追加。 另外一个维度是时间线,由指标和数据源组成,数据源就是由一系列的标签标示的唯一数据采集点。例如指标cpu.usage的数据来自于机房,应用,实例等维度组合成的采集点。 这样大家逻辑上就可以抽象出来一个id+{timestamp, value}的时序数据模型。这种数据模型的存储是如何呢。一般有两种典型的数据存储思路:
1.2 时序模型的热点问题处理
生产环境中业务方采集的指标类型多种多样,对指标的采集周期各不相同。比如cpu.usage这个指标的变化频率比较快,业务方关注度高,采集周期通常很短,1秒,5秒,10秒等等。 然而指标disk.usage这个指标变化趋势相对平滑,采集周期通常为1分钟,5分钟, 10分钟等。这种情况下,数据的存储如果针对同一个指标不做特殊处理,容易形成热点问题。 假设按照指标类型进行存储资源的分片,想象一下如果有20个业务,每个业务10个集群,每个集群500台主机,采集周期是1秒的话,每秒就会有10万个cpu.usage的指标数据点落到同一个存储资源实例中, 而disk.usage采集周期为1分钟,所以大约只有1666个指标数据点落到另外一个存储资源上,这样数据倾斜的现象非常严重。
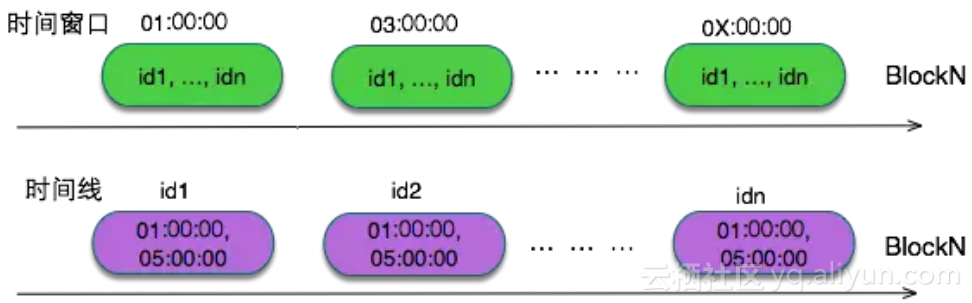
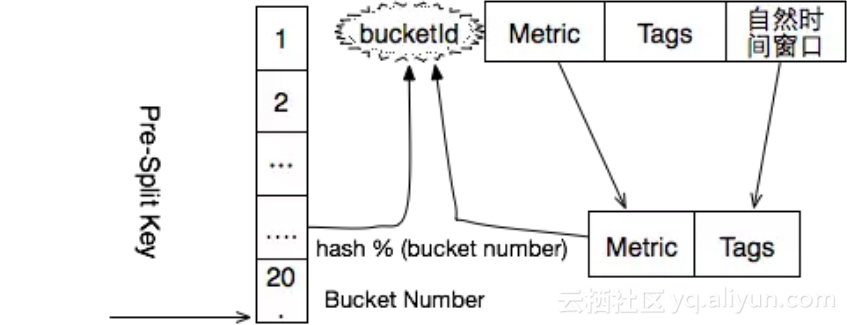
1.2.1 分桶
这类问题的经典解法就是分桶。比如除了指标类型外,同时将业务名和主机名作为维度标识tags,把指标cpu.usage划分到不同的桶里面。 写入时根据时间线哈希值分散写入到不同的桶里面。 OpenTSDB在处理热点问题也是采用了分桶模式,但是需要广播读取,根本原因在于查询方式需要在某个时间窗口内的全局扫描。 所以设置OpenTSDB的分桶数量需要一个平衡策略,如果数量太少,热点还是有局部性的问题,如果太多,查询时广播读带来的开销会非常大。
与其相比较,HiTSDB避免了广播读,提高了查询效率。由于HiTSDB在查询时,下发到底层存储扫描数据之前,首先会根据查询语句得到精确命中的时间线。 有了具体的时间线就可以确定桶的位置,然后到相应的块区域取数据,不存在广播读。 关于HiTSDB如何在查询数据的时候获取命中的时间线,相信读者这个疑问会在读取完倒排这一节的时候消释。
1.2.2 Region Pre-Split
当一个表刚被创建的时候,HBase默认分配一个Region给新表。所有的读写请求都会访问到同一个regionServer的同一个region中。 此时集群中的其他regionServer会处于比较空闲的状态,这个时候就达不到负载均衡的效果了。 解决这个问题使用pre-split,在创建新表的时候根据分桶个数采用自定义的pre-split的算法,生成多个region。 byte[][] splitKeys =new byte[bucketNumber-1][]; splitKeys[bucketIndex-1] = (bucketIndex&0xFF);
2. 倒排索引:
2.1 时序数据中的多维时间线
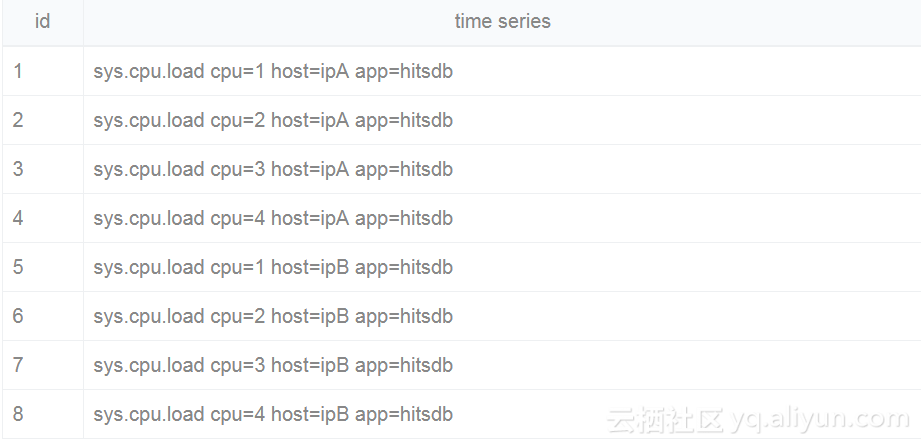
多维支持对于任何新一代时序数据库都是极其重要的。 时序数据的类型多种多样,来源更是非常复杂,不止有单一维度上基于时间的有序数值,还有多维时间线相关的大量组合。 举个简单例子,cpu的load可以有三个维度描述cpu core, host, app应用,每个维度可以有百级别甚至万级别的标签值。 sys.cpu.load cpu=1 host=ipA app=hitsdb,各个维度组合后时间线可以轻松达到百万级别。 如何管理这些时间线,建立索引并且提供高效的查询是时序数据库里面需要解决的重要问题。 目前时序领域比较主流的做法是采用倒排索引的方式。
2.2 倒排索引基本组合
基本的时间线在倒排中的组合思路如下:
时间线的原始输入值:
倒排构建后:
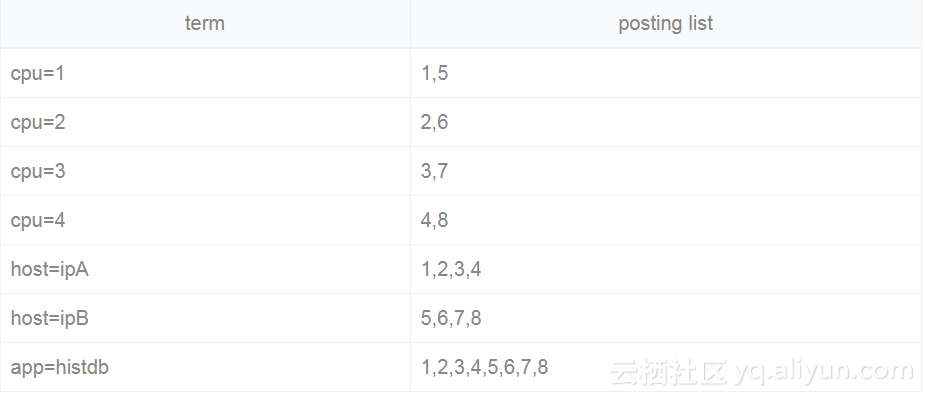
查询时间线 cpu=3 and host=ipB:

取交集后查询结果为7:

2.3 倒排面临的问题以及优化思路
倒排主要面临的是内存膨胀的问题:
3. 流式聚合引擎
3.1 HiTSDB聚合引擎的技术痛点
HiTSDB现有聚合引擎公有云公测以及集体内部业务运行中,暴露发现了以下问题:
3.1.1 Materialization执行模式造成Heap内存易打爆
下图显示了原查询引擎的架构图。HiTSDB以HBase作为存储,原引擎通过Async HBase client 从HBase获取时序数据。由于HBase的数据读取是一个耗时的过程,通常的解法是采用异步HBase client的API,从而有效提高系统的并行性。但原聚合引擎采用了一种典型的materialization的执行方式:1)启动多个异步HBase API启HBase读,2)只有当查询所涉及的全部时序数据读入到内存中后,聚合运算才开始启动。这种把HBase Scan结果先在内存中materialized再聚合的方式使得HiTSDB容易发生Heap内存打爆的现象。尤其当用户进行大时间范围查询,或者查询的时间线的数据非常多的时候,因为涉及的时序数据多,HiTSDB会发生Heap OOM而导致查询失败。
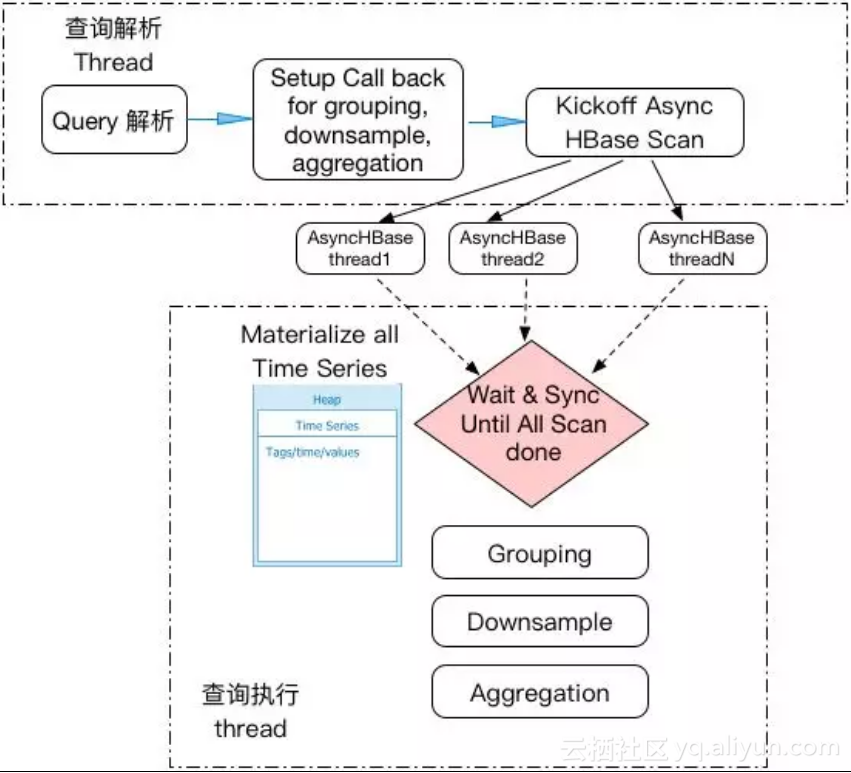
3.1.2 大查询打爆HBase的问题
两个原因造成HiTSDB处理聚合查询的时候,容易发生将底层HBase打爆。
当这种情况发生时,更糟糕的场景是HiTSDB无法处理时序数据的写入请求,造成后续新数据的丢失。
3.1.3 执行架构高度耦合,修改或增加功能困难
聚合引擎主要针对应用场景是性能监控,查询模式固定,所以引擎架构采用单一模式,把查询,过滤,填值/插值,和聚合运算的逻辑高度耦合在一起。这种引擎架构对于监控应用的固定查询没有太多问题,但HiTSDB目标不仅仅是监控场景下的简单查询,而是着眼于更多应用场景下的复杂查询。
我们发现采用原有引擎的架构,很难在原有基础上进行增加功能,或修改原来的实现。本质上的原因在于原有聚合引擎没有采用传统数据库所通常采用的执行架构,执行层由可定制的多个执行算子组成,查询语义可以由不同的执行算子组合而完成。这个问题在产品开发开始阶段并不感受很深,但确是严重影响HiTSDB拓宽应用场景,增加新功能的一个重要因素。
3.1.4 聚合运算效率有待提高
原有引擎在执行聚合运算的时候,也和传统数据库所通常采用的iterative执行模式一样,迭代执行聚合运算。问题在于每次iteration执行,返回的是一个时间点。Iterative 执行每次返回一条时间点,或者一条记录,常见于OLTP这样的场景,因为OLTP的查询所需要访问的记录数很小。但对HiTSDB查询有可能需要访问大量时间线数据,这样的执行方式效率上并不可取。
原因1)每次处理一个时间点,都需要一系列的函数调用,性能上有影响,2)iterative循环迭代所涉及到的函数调用,无法利用新硬件所支持的SIMD并行执行优化,也无法将函数代码通过inline等JVM常用的hotspot的优化方式。在大数据量的场景下,目前流行的通用做法是引入Vectorization processing, 也就是每次iteration返回的不再是一条记录,而是一个记录集(batch of rows),比如Google Spanner 用batch-at-a-time 代替了row-at-a-time, Spark SQL同样也在其执行层采用了Vectorization的执行模式。
3.2 流式聚合引擎设计思路
针对HiTSDB原有聚合运算引擎上的问题,为了优化HiTSDB,支持HiTSDB商业化运营,我们决定改造HiTSDB聚合运算引擎。下图给出了新聚合查询引擎的基本架构。
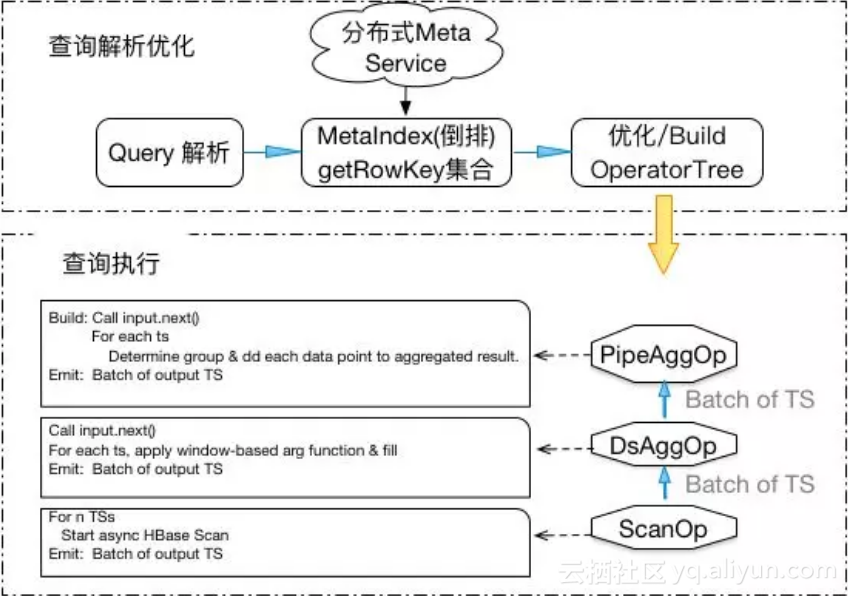
3.2.1 pipeline执行模式
借鉴传统数据库执行模式,引入pipeline的执行模式(aka Volcano / Iterator 执行模式)。Pipeline包含不同的执行计算算子(operator), 一个查询被物理计划生成器解析分解成一个DAG或者operator tree, 由不同的执行算子组成,DAG上的root operator负责驱动查询的执行,并将查询结果返回调用者。在执行层面,采用的是top-down需求驱动 (demand-driven)的方式,从root operator驱动下面operator的执行。这样的执行引擎架构具有优点:
每个operator,实现如下接口:
我们在HiTSDB中实现了以下算子:
3.2.2 执行计算算子一个batch的时间线数据为运算单位
在计算算子之间以一个batch的时间线数据为单位,提高计算引擎的执行性能。其思想借鉴于OLAP系统所采用的Vectorization的处理模式。这样Operator在处理一个batch的多条时间线,以及每条时间线的多个时间点,能够减少函数调用的代价,提高loop的执行效率。
每个Operator以流式线的方式,从输入获得时间线batch, 经过处理再输出时间线batch, 不用存储输入的时间线batch,从而降低对内存的要求。只有当Operator的语义要求必须将输入materialize,才进行这样的操作(参见下面提到的聚合算子的不同实现)。
3.2.3. 区分不同查询场景,采用不同聚合算子分别优化
HiTSDB原来的聚合引擎采用materialization的执行模式,很重要的一个原因在于处理时序数据的插值运算,这主要是因为时序数据的一个典型特点是时间线上不对齐:不同的时间线在不同的时间戳上有数据。HiTSDB兼容OpenTSDB的协议,引入了插值(interpolation)的概念,目的在于聚合运算时通过指定的插值方式,在不对齐的时间戳上插入计算出来的值,从而将不对齐的时间线数据转换成对齐的时间线。插值是在同一个group的所有时间线之间比较,来决定在哪个时间戳上需要进行插值 (参见OpenTSDB 文档)。
为了优化聚合查询的性能,我们引入了不同的聚合运算算子。目的在于针对不同的查询的语义,进行不同的优化。有些聚合查询需要插值,而有些查询并不要求插值;即使需要插值,只需要把同一聚合组的时间线数据读入内存,就可以进行插值运算。
1)不需要插值: 查询使用了降采样(downsample),并且降采样的填值采用了非null/NaN的策略。这样的查询,经过降采样后,时间线的数据都是对齐补齐的,也就是聚合函数所用到的插值不再需要。
2)聚合函数可以支持渐进式迭代计算模式 (Incremental iterative aggregation), 比如sum, count ,avg, min, max, zerosum, mimmim, mimmax,我们可以采用incremental聚合的方式,而不需要把全部输入数据读入内存。这个执行算子采用了流水线的方式,每次从输入的operator获得一系列时间线,计算分组并更新聚合函数的部分值,完成后可以清理输入的时间线,其自身只用保留每个分组的聚合函数的值。
对于MTAggOp, 我们可以引入分组聚合的方法进行优化:
3.2.4 查询优化器和执行器
引入执行算子和pipeline执行模式后,我们可以在HiTSDB分成两大模块,查询优化器和执行器。优化器根据查询语义和执行算子的不同特点,产生不同的执行计划,优化查询处理。例如HiTSDB可以利用上面讨论的三个聚合运算算子,在不同的场景下,使用不同的执行算子,以降低查询执行时的内存开销和提高执行效率为目的。这样的处理方式相比于原来聚合引擎单一的执行模式,更加优化。
4. 数据迁移
HiTSDB新的聚合引擎采用的底层存储格式与以前的版本并不兼容。 公有云公测期间运行在旧版本实例的数据,需要迁移至新的聚合引擎。 同时热升级出现了问题,数据迁移还应回滚功能,将新版本的数据点转换成旧的数据结构,实现版本回滚。 整体方案对于用户的影响做到:写入无感知,升级过程中,历史数据不可读。
4.1 数据迁移架构
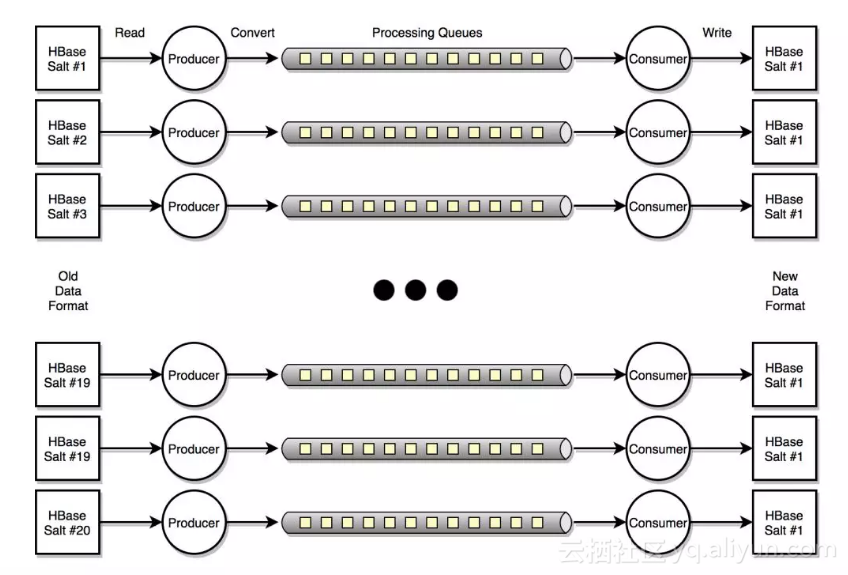
![]() 并发转换和迁移数据: 原有的HiTSDB数据点已经在写入的时候进行了分片。默认有20个Salts。数据迁移工具会对每个Salt的数据点进行并发处理。 每个“Salt”都有一个Producer和一个Consumer。Producer负责开启HBase Scanner获取数据点。 每个Scanner异步对HBase进行扫描,每次获取HBASE_MAX_SCAN_SIZE行数的数据点。然后将HBase的Row Key转换成新的结构。
并发转换和迁移数据: 原有的HiTSDB数据点已经在写入的时候进行了分片。默认有20个Salts。数据迁移工具会对每个Salt的数据点进行并发处理。 每个“Salt”都有一个Producer和一个Consumer。Producer负责开启HBase Scanner获取数据点。 每个Scanner异步对HBase进行扫描,每次获取HBASE_MAX_SCAN_SIZE行数的数据点。然后将HBase的Row Key转换成新的结构。
4.2 数据迁移的一致性
由于目前云上版本HiTSDB为双节点,在结点升级结束后会自动重启HiTSDB。自动启动脚本会自动运行数据迁移工具。 如果没有任何预防措施,此时两个HiTSDB节点会同时进行数据迁移。虽然数据上不会造成任何丢失或者损坏, 但是会对HBase造成大量的写入和读取压力从而严重影响用户的正常的写入和查询性能。
为了防止这样的事情发生,我们通过HBase的Zoo Keeper实现了类似FileLock锁,我们称为DataLock,的机制保证只有一个结点启动数据迁移进程。 在数据迁移进程启动时,他会通过类似非阻塞的tryLock()的形式在Zoo Keeper的特定路径创建一个暂时的节点。 如果成功创建节点则代表成果获得DataLock。如果该节点已经存在,即被另一个HiTSDB创建,我们会收到KeeperException。这样代表未获得锁,马上返回失败。 如果未成功获得DataLock,该节点上的数据迁移进程就会自动退出。成果获得DataLock的节点则开始进行数据迁移。
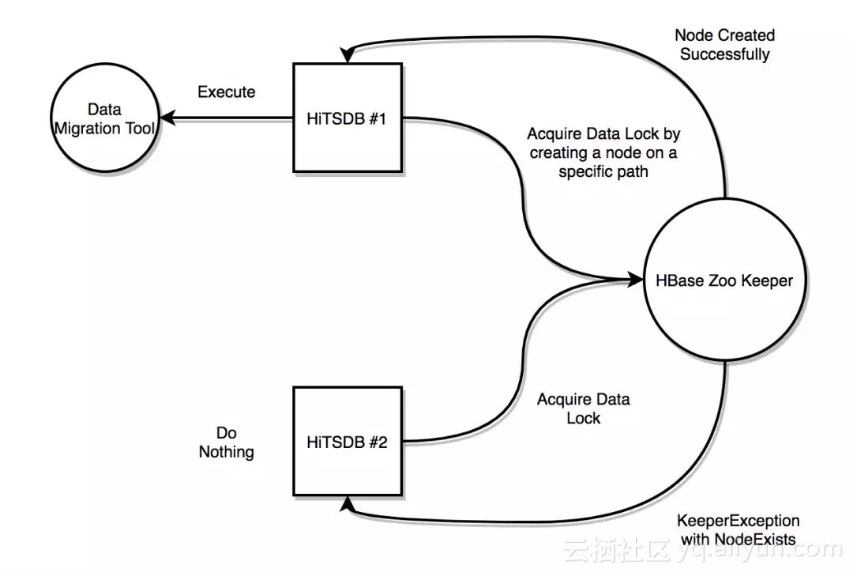
4.3 数据迁移中的"执行一次"
当所有“Salt”的数据点全部顺利完成迁移之后,我们会在HBase的旧表中插入一行新数据,data_conversion_completed。 此行代表了数据迁移工程全部顺利完成。同时自动脚本会每隔12个小时启动数据迁移工具,这样是为了防止上次数据迁移没有全部完成。 每次启动时,我们都会先检查“data_conversion_completed”标志。如果标志存在,工具就会马上退出。 此项操作只会进行一次HBase的查询,比正常的健康检查成本还要低。所以周期性的启动数据迁移工具并不会对HiTSDB或者HBase产生影响。
4.4. 数据迁移的评测
测试机型: 4core,8G,SSD
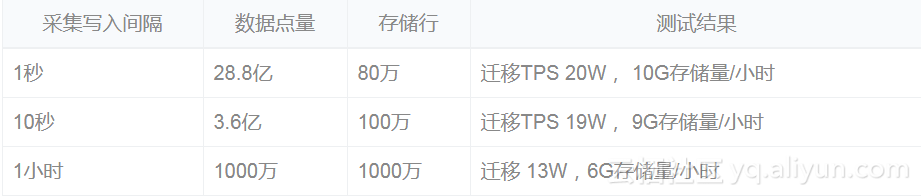
效果:上线后无故障完成100+实例数据的迁移,热升级。
5. 查询性能评测
测试环境配置
192.168.12.3 2.1.5版本
192.168.12.4 2.2.0版本(Pipelined Engine)
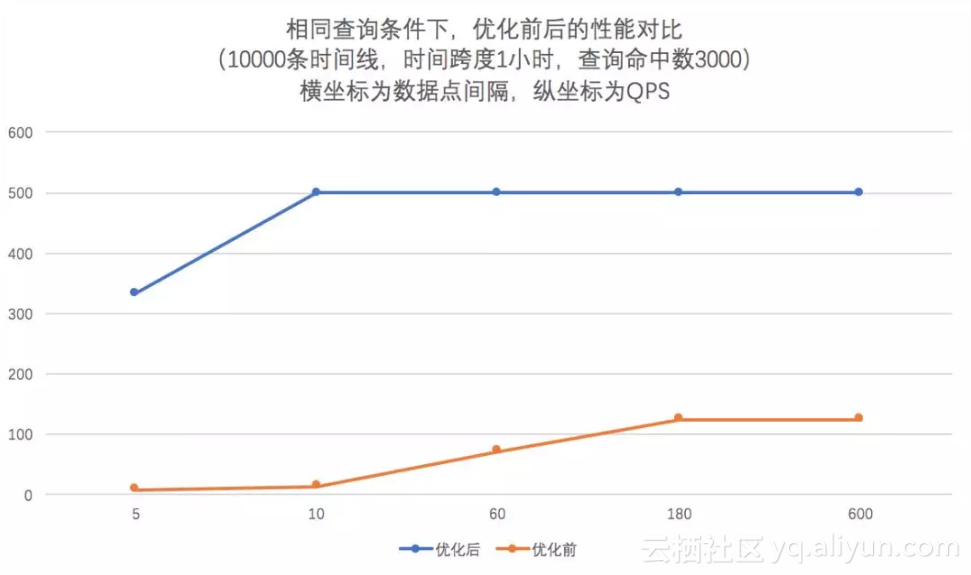
测试数据 - 1万条时间,不同的采集频率和时间窗口,还有查询命中的时间线数量。
Case 1: 数据采集频率5s, 查询命中1000条,时间窗口3600s

Case 2: 数据采集频率1s,查询命中1条,时间窗口36000s

总结: 新的查询聚合引擎将查询速度提高了10倍以上。
其他
本文介绍了高性能时间序列数据库HiTSDB引擎在商业化运营之前进行的优化升级,目的是提高HiTSDB引擎的稳定性,数据写入和查询性能以及新功能的扩展性。HiTSDB已经在阿里云正式商业化运营,我们将根据用户反馈,进一步提高HiTSDB引擎,更好服务于HiTSDB的客户。
原文发布时间为:2018-04-18
本文作者:阿里HiTSDB团队