摘要:C/C++的指针一直是令人又爱又恨的特性。围绕指针产生了许许多多优雅的数据结构和系统实现,但又滋生了不少“脑细胞杀手”——内存Bug。C/C++指针问题(空指针、野指针、垂悬指针)的根本原因其实是,当你获得一个指针时是无法判断这个指针所指向的地址是否保存着一个有效的对象。如何通过指针管理C++中对象,如何管理对象的生命周期呢?本文中,阿里巴巴高级开发工程师付哲就为大家分享《C++对象的生命周期管理》。
数十款阿里云产品限时折扣中,赶紧点击这里,领劵开始云上实践吧!
视频回顾地址:https://yq.aliyun.com/video/play/1412
PPT下载地址:https://yq.aliyun.com/download/2566
演讲嘉宾简介
付哲(花名:行简),阿里云高级开发工程师,哈尔滨工业大学微电子学硕士,主攻方向为分布式存储与高性能服务器编程,目前就职于阿里云表格存储团队,负责后端开发。
以下内容根据演讲视频以及PPT整理而成。
C++中的对象⽣命期分类
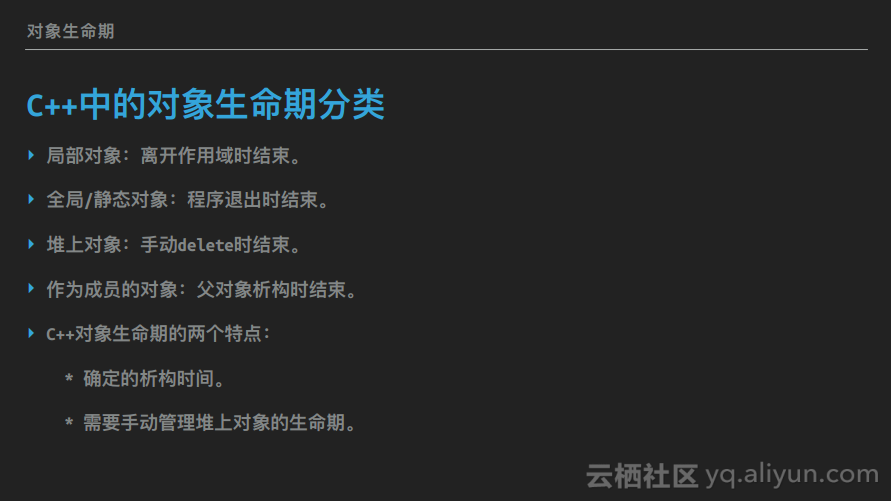
在C++中,对象可以按其生命期分为以下四类:
1. 局部对象,即分配在栈上的函数内对象,它们的生命期是编译器管理的,也就是说它们的析构时间是确定的,当程序执行完某个代码作用域后,这个作用域内定义的所有局部对象会按它们的定义的逆序依次析构。2. 全局或静态对象,这些对象分配在程序的data段,它们的生命期也是由编译器管理的,其构造时间位于main函数之前,并且按照某种不确定的顺序进行构造,析构时间也是确定的,当程序执行完main函数后,在程序退出前,会依次析构每个全局对象。
3. 堆上对象,一般而言就是通过new分配的对象,这些对象的生命期与前两类不同,是完全由编程人员控制的,也就是说需要手动控制堆上对象的生命期,它们的析构时间就是对应的delete被调用的时间。
4. 作为成员的对象,其生命期未定,不一定是固定的,也不一定是由编程人员控制的,这些对象的生命期由它们的父对象决定,当它们的父对象析构时,这些子对象也会一起析构。
这与Java以及C#这样的托管语言不同,这些托管语言都有运行期的垃圾回收器,会定期检查那些已经没有人引用的对象并将其删除掉。在这些语言中,编程人员通常不需要关心自己使用的对象的生命期,这大大减轻了开发上的负担。但同时会带来一些代价,就是编程人员不知道垃圾回收器什么时候会介入,没有办法知道对象的准确的析构时间。
因此可以总结C++中对象生命期,主要有两个特点:
1. 析构时间是确定的,这样能保证一个对象相关的清理工作也会在确定时间进行。
2. 堆上对象需要手动管理生命期,这导致编程人员需要非常谨慎地管理堆上对象,这也是使用C++进行开发的明显负担。
确定的析构时间
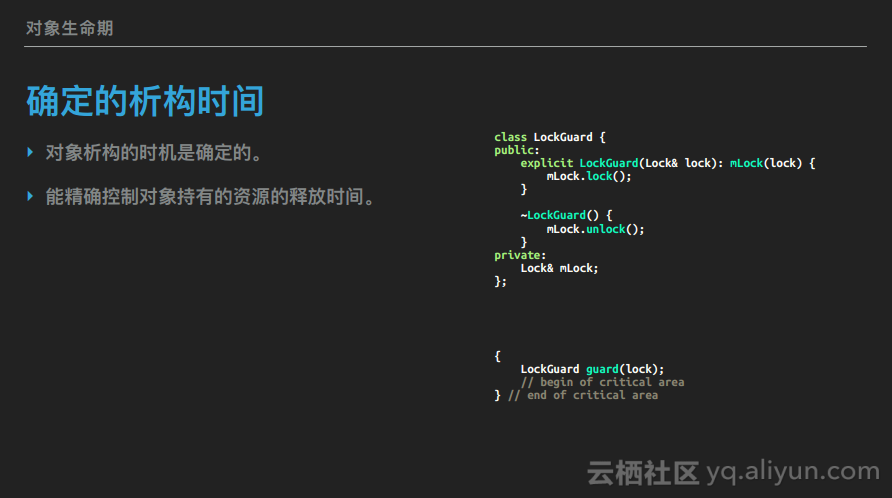
C++对象的析构时间是确定的,这一特性非常重要,这样就能控制一个对象该何时清理掉它持有的各种资源:就在它析构时。这里说的资源不光指内存资源,还包括对象持有的所有资源,比如数据库链接、文件句柄、锁等等。
class LockGuard {
public:
explicit LockGuard(Lock& lock): mLock(lock) {
mLock.lock();
}
~LockGuard() {
mLock.unlock();
}
private:
Lock& mLock;
};LockGuard guard(lock);
// critical area基于栈上对象管理所有对象的生命期
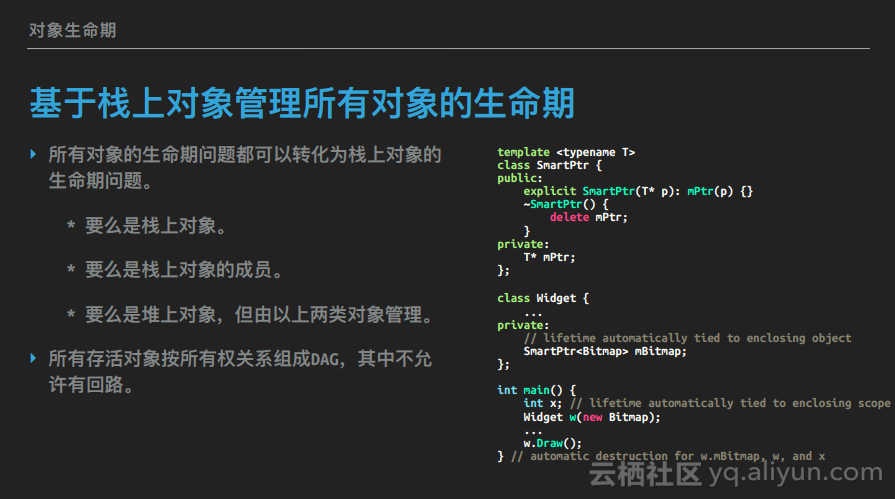
而假如使用这样的栈上对象或者成员来管理堆上对象,就可以把堆上对象的析构时间也确定下来,也就是说可以把所有对象的生命期问题都转化成为栈上对象的生命期问题。当有一个堆上对象时,可以把这个对象的指针放到一个SmartPtr对象中进行管理,这个SmartPtr对象本身可能是栈上对象,也可能是其它对象的成员。这样就把这个堆上对象的生命期管理转化为了对某个栈上对象的生命期管理,而这就简单多了。通过这种方法可以把所有对象的生命期管理问题都转化为栈上对象的生命期管理问题,即所有对象,要么是栈上对象,要么是栈上对象的成员,要么是堆上对象,但被栈上对象或其成员持有。比如下列代码中是一个较为简单的智能矩阵的例子,这个智能矩阵持有一个裸矩阵,这个裸矩阵指向一个堆上对象,智能矩阵控制其生命期,在其析构的时候也会将堆上对象析构掉。
template <typename T>
class SmartPtr {
public:
explicit SmartPtr(T* p): mPtr(p) {}
~SmartPtr() {
delete mPtr;
}
private:
T* mPtr;
};class Widget {
...
private:
SmartPtr<Bitmap> mBitmap; // lifetime automatically tied to enclosing object
};
int main() {
int x; // lifetime automatically tied to enclosing scope
Widget w(new Bitmap);
...
w.Draw();
} // automatic destruction and deallocation for w.mBitmap, w, and x资源获取即初始化 (RAII)

资源获取即初始化,缩写是RAII,实际上前面例子中的LockGuard和SmartPtr两个类型都体现了RAII。简单来说,资源获取即初始化就是把每项资源都封装为一个对象,通过对象的生命期来管理资源,一个RAII对象的构造就意味着对应资源的获取,而RAII对象的析构就意味着对应资源的释放,这样就将资源的有效期转化成为资源的有效期问题。它的最主要的好处就是可以保证资源管理是异常安全的,不会导致下面的情况发生:
{
Bitmap* pb = new BitMap;
...
Draw(*pb); // here throw an exception!
delete pb; // can't reach here!
} 如上示例代码所示,首先new一个对象并将其传入一个函数,之后将对象删除掉,但是C++是有异常的,加入代码中间的Draw函数抛出了异常,那就永远无法执行到delete操作了,那么pb对象也就无法删除掉了,这就造成了内存泄漏,也就说明代码不是异常安全的。
使用RAII后的代码:
{
auto pb = std::make_unique<BitMap>(); // pb is a std::unique_ptr
Draw(*pb);
} // automatic destruction for pb even if Draw(*pb) throws exception使用容器管理资源

当需要管理若干个不同的对象时候,往往会考虑使用某种容器类。C++标准库中包含了很多种容器类,这些容器都会负责管理其中所有元素的生命期,比如std::array、std::vector、std::deque、std::list等。C++11之前没有移动,那么只能通过复制的方式将元素加到容器中,复制结束后容器中的元素与源对象是完全独立的,它们两个各自有不同的生命期。而在C++11之后则可以通过移动的方式构造容器中的元素,移动结束后源对象的生命期还没有结束,但一般来说它应该是一个等待析构的空对象了,逻辑上它的生命期已经结束了。
标准库的这些容器都能保证异常安全,也就是当向容器中增加一个元素、删除一个元素、或者调用一个元素的方法时抛了异常,这些标准库容器能保证其它元素不受影响,过程中已经分配的临时资源也能被正确销毁。另外这些标准库容器往往都有着非常高效的实现,因此当需要用一个容器来管理对象时,优先考虑使用标准库已有的容器类,而不应该自己去写一个没有异常安全保证的容器类。
std::vector<std::string> vs;
string tmp("xyzzy");
// before C++11
vs.push_back(tmp);
// after C++11
vs.emplace_back(std::move(tmp));智能指针

之所以要用智能指针是因为C和传统C++里面的裸指针存在很多缺点:
1. 裸指针的声明没办法告诉我们它指向的是单个对象还是数组;因为C里面规定了数组是无法传递的,在传递的过程中会退化为指针,所以在一个函数中如果看到了指针作为参数,那么就无法知道其所指向的是单个对象还是数组。2. 没办法知道用完这个裸指针后要不要销毁它指向的对象;裸指针也没有表达所有权信息,也就是说无法知道有多少人持有该指针,也不知道是否需要管理其生命期,更不知道使用完该裸指针之后是否需要将其销毁掉。
3. 没办法知道怎么销毁这个裸指针,是用operator delete还是什么其它自定义的途径;因为不知道裸指针所指向的是单个对象还是数组,那么就无法知道应该如何销毁其所指向的东西。
4. 参照原因1,没办法知道该用delete还是delete[],如果用错了,结果未定义;比如当存在对象池时,使用完毕并不应该做delete操作而应该归还到对象池中,但是这样的信息是无法通过裸指针获得的。
5. 很难保证调用路径上恰好销毁这个指针一次;很难保证在调用路径上只恰好销毁了这个调用指针有且仅有一次,如果多以一次就会造成double free,而如果在调用路径上没有人销毁该指针那么就造成了内存泄漏。
6. 通常没办法知道裸指针是否是空悬指针,即是否指向已销毁的对象;所谓空悬指针也就是如果指针在调用路径中被销毁了多次,在第一次销毁之后,这个指针指向的就已经不是一个合法的对象了,其可能指向任何东西,这时候指针就称为空悬指针。指针本身还指向着某一块内存,而这一块内存不一定能够被使用。
智能指针就是来解这些问题的,它们用起来像裸指针,但能避免以上的很多陷阱。C++11中有4种智能指针:std::auto_ptr、std::unique_ptr、std::shared_ptr、std::weak_ptr。其中std::auto_ptr已经过时了,存在很多问题,比如复制逻辑反人类,因此不建议使用,C++11中可以被std::unique_ptr取代了。
深入智能指针的适用场景
使用unique_ptr管理所有权明确的资源
首先要知道:默认情况下,std::unique_ptr与裸指针一样大,且对于绝大多数操作来说(包括解引用),它们编译后的指令都是完全一样的,所有裸指针的空间和性能开销能满足要求的场景,std::unique_ptr一样能满足。
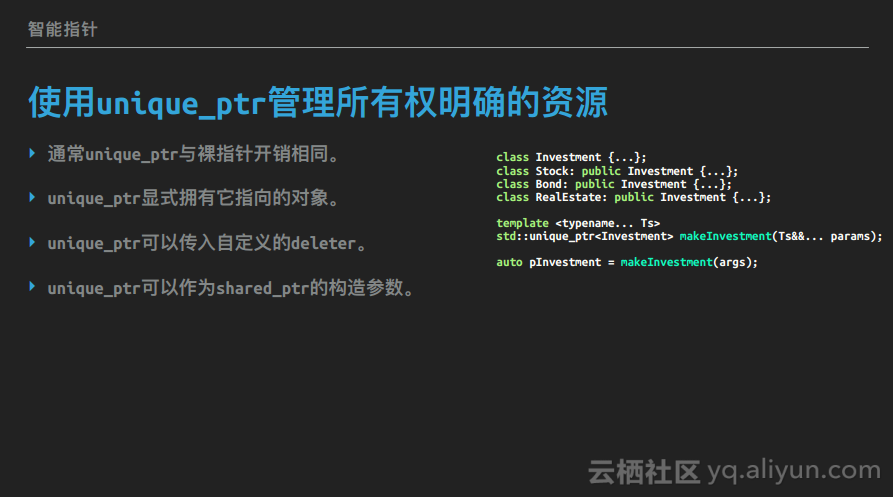
std::unique_ptr体现了显式所有权的语义:非空的std::unique_ptr总是拥有它指向的对象,其在析构的时候就会将指向的对象销毁;移动一个std::unique_ptr会将源指针持有的所有权移交给目标指针;不允许复制std::unique_ptr,也就是说无法让两个std::unique_ptr同时拥有一个对象;非空的std::unique_ptr总是销毁它持有的资源,默认是通过delete。如下的工厂函数就是std::unique_ptr的使用示例。假设有一个基类和三个派生类,通过一个工厂函数来返回某个派生类的std::unique_ptr,这样调用方就不需要费心什么时候销毁返回的对象了,当std::unique_ptr析构的时候就会将对象销毁掉,这样就能够保证返回的对象能够被安全地销毁。
class Investment {...};
class Stock: public Investment {...};
class Bond: public Investment {...};
class RealEstate: public Investment {...};
template <typename... Ts>
std::unique_ptr<Investment> makeInvestment(Ts&&... params);
auto pInvestment = makeInvestment(args);注意这里实际上有个所有权的转移:工厂函数通过std::unique_ptr将Investment对象的所有权转移给了调用者。在构造std::unique_ptr时还可以传入一个自定义的销毁器,也就是所谓的deleter,它会在std::unique_ptr析构时被调用,来销毁对应的资源。值得强调的一点是在标准库的实现里面用到了空基类优化,也就是如果不传入自定义的deleter或者传入的deleter只是一个不捕获任何外界信息的lambda,这种deleter都是空对象,std::unique_ptr继承自此空对象就会使用到空基类优化,也就是说此时的基类不会占派生类空间。这样的做法比把deleter作为成员要好,因为空对象作为成员也会需要占据一个字节,所以这样的优化是很重要的,在大多数情况使得deleter的大小与裸指针相同。
std::unique_ptr另一个吸引人的地方在于,它可以作为std::shared_ptr的构造参数,因此上面的工厂函数返回std::unique_ptr就再正确不过了。调用者可以根据自己对所有权的需求来决定用std::unique_ptr还是std::shared_ptr来接收,反正都支持。
使用shared_ptr管理需要共享所有权的资源
垃圾回收的好处是不用手动管理资源的生命期,这样极大地降低开发时成本;其缺点是资源回收的时间无法确定,所以不能依赖对象被删除时执行资源清理,理论上在内存足够大的时候,资源永远都不会回收。而手动管理资源的好处是确定的资源回收时间,何时回收是由自己控制的,不只可以回收内存,还能回收任何其它资源。其缺点是比较复杂,容易写出bug,导致开发成本非常高。
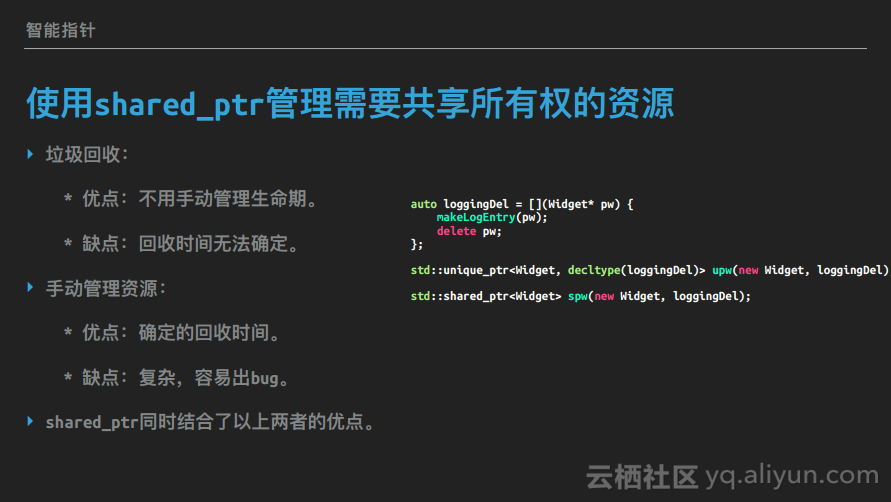
C++11中结合以上两者的方式是使用std::shared_ptr。使用std::shared_ptr管理的对象的所有权是共享的,没有哪个std::shared_ptr是独占这个对象的,std::shared_ptr在不同函数之间可以传递,传递本身是线程安全的,因此可以在多线程之间安全地传递std::shared_ptr。而当std::shared_ptr析构时,其内部有引用计数,被复制时,引用计数+1,有std::shared_ptr析构时,引用计数-1,当引用计数为0时,析构持有的对象。与垃圾回收类似,调用者不需要手动管理std::shared_ptr管理的对象;与析构函数类似,对象的析构时间是确定的,也就是最后一个std::shared_ptr析构的时间。
而引用计数的存在有以下性能影响:
1. 引用计数使用的内存必须动态分配,原因是std::shared_ptr的引用计数是非侵入式的,必须要独立在对象外面。用std::make_shared能避免这次单独的内存分配。2. std::shared_ptr的大小是裸指针的两倍:一个指针指向持有的对象,一个指针指向引用计数。
3. 每当复制或者析构std::shared_ptr时,都会导致引用计数的加减,而为了线程安全,引用计数的加减必须是原子的,因此这样的加减成本高出很多,因此必须假设读写引用计数是有成本的。
与std::unique_ptr类似,std::shared_ptr的默认销毁动作也是delete,且也可以接受自定义的销毁器。但与std::unique_ptr不同的是,std::shared_ptr的销毁器类型不必作为它的模板参数之一。
auto loggingDel = [](Widget* pw) {
makeLogEntry(pw);
delete pw;
};
std::unique_ptr<Widget, decltype(loggingDel)> upw(new Widget, loggingDel);
std::shared_ptr<Widget> spw(new Widget, loggingDel);使用weak_ptr避免所有权回路与空悬指针
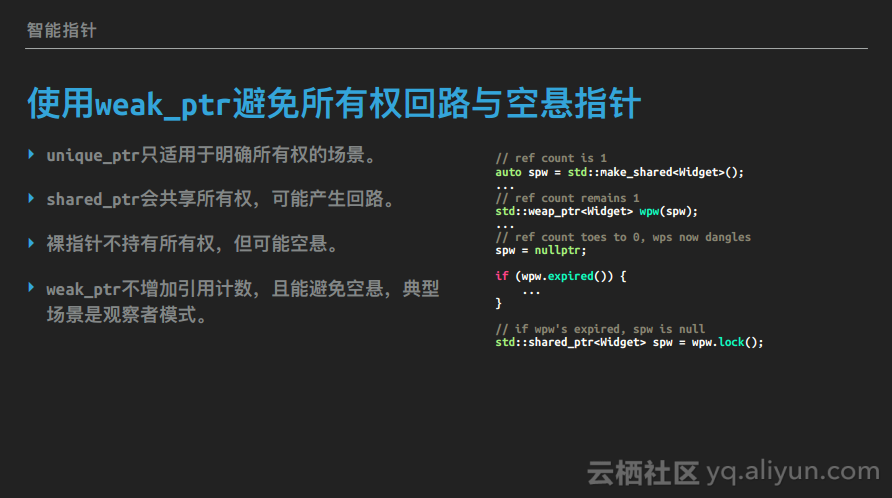
有时候需要一种类似std::shared_ptr但又不参与这个共享对象的所有权的智能指针,它需要能知道共享对象是否已经销毁了,这就是std::weak_ptr。std::weak_ptr不是单独存在的,它不能解引用,也不能检测是否为空,它就是配合std::shared_ptr使用的。通常std::weak_ptr都是通过std::shared_ptr构造的,但它不会影响std::shared_ptr的引用计数。
auto spw = std::make_shared<Widget>(); // ref count is 1
...
std::weap_ptr<Widget> wpw(spw); // ref count remains 1
...
spw = nullptr; // ref count toes to 0, wps now dangles
if (wpw.expired()) {
...
}
std::shared_ptr<Widget> spw = wpw.lock(); // if wpw's expired, spw is null如上示例代码,首先构造一个std::shared_ptr,此时其引用计数为1,然后通过其构造一个std::weak_ptr,接下来将之前的std::shared_ptr进行重置,这时候引用计数为0,引用对象就被析构了。此时可以使用expired()方法检查std::weak_ptr是否空悬,或者调用其lock,如果返回值为空,那么就说明引用对象被析构掉了,而如果返回的std::shared_ptr非空就可以放心地使用该对象。
std::weak_ptr本身的实现机制就是std::shared_ptr中不仅有引用计数,还有std::shared_ptr使用到的弱引用计数以及销毁器,都在这个被称为控制块的内存中。这样就能够在对象引用被析构掉的情况下仍然通过弱引用计数来判断该对象是否被析构了,就不会出现指针空悬状况。
为什么要用weak_ptr?想像一种场景,A和B都需要持有对方的指针,肯定不想用裸指针,那么就用智能指针。但用什么智能指针呢?unique_ptr吗?但A和B之间没有所有权的关系。shared_ptr吗?注意了,这里就会导致一个生命期的回路,A的析构依赖于B,因为B持有A的shared_ptr,但B的析构也同样依赖于A,因为A也持有B的shared_ptr,这就导致A和B谁也没办法析构,从而造成内存泄漏。这个时候我们就需要用到weak_ptr了,它不会持有对象的所有权,也不影响对象的生命期,但又有办法知道weak_ptr指向的对象是否已经析构了,这样就避免了裸指针的空悬问题。最典型的适用weak_ptr的场景就是观察者模式,每个topic会持有一组观察者的指针,每当topic本身有变化时它就需要通知所有观察者,这里topic不需要控制观察者的生命期,但需要知道观察者是否还存在。
优先用make_unique和make_shared
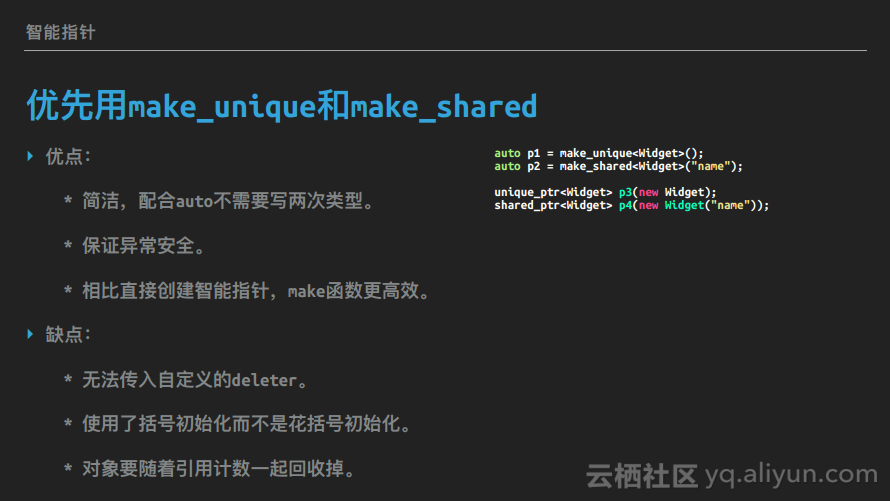
C++11增加了make_shared,C++14增加了make_unique,它们是用来简化创建智能指针的代码的。
auto p1 = make_unique<Widget>();
auto p2 = make_shared<Widget>("name");
unique_ptr<Widget> p3(new Widget);
shared_ptr<Widget> p4(new Widget("name"));这个例子就说明了用make_unique和make_shared的第一个好处:简洁,不需要重复写一遍模板类型。所有程序员都知道:不要重复代码。代码越少,bug越少。
第二个好处是保证异常安全性,如下代码示例:
void processWidget(shared_ptr<Widget> spw, int priority);
int computePriority();
processWidget(shared_ptr<Widget>(new Widget), computePriority());1. new Widget一定会执行,即一定会有一个Widget对象在堆上被创建。
2. std::shared_ptr<Widget>的构造函数一定会执行。
3. computePriority一定会执行。
new Widget的结果是std::shared_ptr<Widget>构造函数的参数,因此前者一定早于后者执行。除此之外,编译器不保证其它操作的顺序,即有可能执行顺序为:
Step1:new Widget;创建一个堆上对象,还没有被智能指针保护起来。Step2: 执行computePriority
Step3: 构造智能指针std::shared_ptr<Widget>
如果第2步抛异常,第1步创建的对象还没有被智能指针std::shared_ptr<Widget>管理,就会发生内存泄漏。如果这里我们用std::make_shared,就能保证new Widget和shared_ptr<Widget>是一起完成的,中间不会有其它操作插进来,即不会有不受智能指针保护的裸指针出现:
processWidget(make_shared<Widget>(), computePriority());第三个好处是make函数更高效。在创建一个shared_ptr时,实际发生了两次内存分配,一次是分配这个对象本身,一次是分配shared_ptr维护引用计数的控制块。而如果使用make_shared,就只会有一次内存分配,对象和控制块会被一次分配出来。
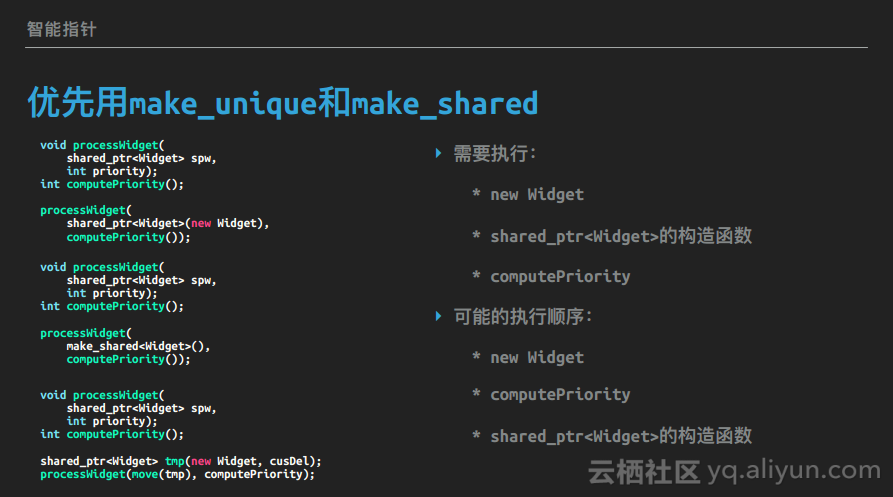
当然make函数也有一些缺点:
1. 无法传入自定义的销毁器。2. make函数初始化时使用了括号初始化,而不是花括号初始化,这是C++11新增的一个特性,这里不展开讨论了,但两种初始化方式在某些场景下有微妙的语义差异值得注意。
3. 对象和控制块分配在一块内存上,减少了内存分配的次数,但也导致对象和控制块占用的内存也要一次回收掉。而控制块是要等所有shared_ptr和weak_ptr都析构后才能释放的,这就导致如果有weak_ptr未析构,对象本身占的内存也没办法释放。
如果因为这三个缺点没办法使用make函数,那么为了保证异常安全,要保证智能指针的构造一定要是一个单独的语句,如下代码所示:
shared_ptr<Widget> spw(new Widget, cusDel);
processWidget(move(spw), computePriority());使用unique_ptr时避免析构不完整类型
当在使用某个类时,如果只能看到它的名字,但看不到它的定义,这样的类被称为不完整类型,编译器没办法知道不完整类型的内存布局,有哪些成员、方法等信息。大多数场景下,编译器都不允许使用一个不完整的类型,但如果只是使用它的指针和引用,而不通过指针和引用访问它的任何成员的话,则是没有问题的。unique_ptr本身允许在声明时允许用不完整类型作为模板参数。前向声明就会产生不完整类型,很多人喜欢用前向声明来减少不同编译单元间的依赖,从而降低编译时间,如下代码:class A;
class B {
public:
...
~B();
private:
A* mPtr;
};class A;
class B {
...
private:
std::unique_ptr<A> mPtr;
}假如B的析构函数中只做了delete mPtr的话,现在用了unique_ptr之后,它自己就会析构指向的对象,看起来似乎就不需要自定义B的析构函数了。但此时我们已经掉入了一个陷阱。如果没有给B定义析构函数的话,编译器会为B生成一个析构函数,在前面提到这样的析构函数是public且内联的,因此这个析构函数会直接展开在调用处。
这个析构函数里面实际只调用了unique_ptr的析构函数,而unique_ptr的析构函数则是直接delete对象的指针。这是因为unique_ptr是一个模板类,其所有的方法都是在头文件中定义的,默认会在调用处展开,假如在展开时A对象还是不完整类型,显然不知道其有什么析构器的,那么默认行为就是delete这个对象的指针。那么问题来了,如果这个对象的类型还不完整,编译器看不到它的析构函数,delete这个指针该发生什么?答案是不调用任何析构函数,直接释放内存。这显然是不对的,但编译器也没有办法,它看不到完整的类型,因此也不知道该调用什么析构函数。但是编译器却没有办法,他看不到完整类型,因此也不知道该调用什么析构函数,此时编译器会有一个警告。在C++11之前,unique_ptr的前任auto_ptr没有做这方面的检查,而unique_ptr在析构时会有static_assert,不允许析构不完整类型。
那么该怎么修改呢?
方法一,在cpp文件中定义B的析构函数:
// b.h
class A;
class B {
public:
~B();
private:
std::unique_ptr<A> mPtr;
};
// b.cpp
#include "a.h" // make A complete
B::~B() {}这个析构函数可以是空的,编译器会帮我们把unique_ptr的析构函数补充进去,此时A不再是不完整类型了,析构也就不会报错了。
方法二,抛弃前向声明。实际上前向声明还会带来其它问题,因此可以直接显式地include。
// b.h
#include "a.h"
class B {
public:
~B() = default;
private:
std::unique_ptr<A> mPtr;
};修改shared_ptr本身不是线程安全的

大家都知道在不同函数间传递shared_ptr是线程安全的,因为它在修改引用计数时使用了原子操作,能保证引用计数被正确修改。但一个陷阱是,如果修改shared_ptr本身,这个操作不是线程安全的,因为它要同时操作多个变量,显然不是原子操作!前面提到,shared_ptr中会有两个成员——对象指针和引用计数,那么如果要做这样如下的操作:
shared_ptr<Widget> a;
shared_ptr<Widget> b = a;1. b复制a的对象指针。
2. 增加a的引用计数。
3. b持有之前复制的a的对象指针。
这几步分别都可以是原子操作,但合起来就不是了。如果在其中另一个线程修改了a:
auto c = make_shared<Widget>("c");
a = c;1. a复制c的对象指针。
2. 增加c的引用计数。
3. 减少a的引用计数,可能引起a的对象析构。
4. a持有之前复制的c的对象指针。
1. b复制a的对象指针。
2. a复制c的对象指针。
3. 增加c的引用计数。
4. 减少a的引用计数,a的对象析构。
5. b持有之前复制的a的对象指针。
1. 增加a的引用计数
2. 增加c的引用计数。
3. 减少a的引用计数,没有引起a的对象析构。
4. a持有c的对象指针。
5. b持有a的对象指针。
// thread 1
shared_ptr<Widget> b;
mutex.lock();
b = a;
mutex.unlock();
// do something ... on b
// thread 2
mutex.lock();
a = c;
mutex.unlock();第一个线程如果想要读取a,那么应该在前面先加锁,也就是在临界区中将其拷贝出来,之后在b上面做事情,而第二个线程赋值时也需要在加锁条件下进行。
本文由云栖志愿小组贾子甲整理,编辑百见





