一致性Hash原理及应用
一、背景
在业务开发中,我们常把数据持久化到数据库中。如果需要读取这些数据,除了直接从数据库中读取外,为了减轻数据库的访问压力以及提高访问速度,我们更多地引入缓存来对数据进行存取。对于只有单个缓存服务器来说我们可以直接定位,那么对于分布式情境下,我们又该如何处理呢?
二、引入
我们在使用Redis的时候,为了保证Redis的高可用,提高Redis的读写性能,最简单的方式我们会做主从复制,组成Master-Master或者Master-Slave的形式,或者搭建Redis集群,进行数据的读写分离,类似于数据库的主从复制和读写分离。当我们的系统更加庞大,业务更加繁杂时,类似数据库一样,只通过读写分离也无法满足需求,这时我们可能需要分布式缓存:

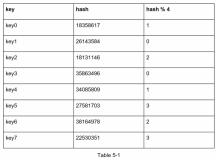
假如当前没有任何规则,那么所有数据的存放都是随机的,读取数据时并不确定在哪一台redis上,所以我们只有通过遍历的方式才能找到,很显然,这个过程是没有必要的。这个时候我们可以回想Jdk1.7中Hashmap的源代码中indexfor实现:
IndexFor方法 (此处是位运算,跟取模的结果一样) 是为了确定当前元素在数组上的位置,再去定位在链表上的位置,跟当前场景一样为了定位,而我们要找的数据的key可能是字符串类型,我们可以通过取hash值再取模的方式来存取。那么新的问题来了,如果我们其中的一台服务器宕掉了或要添加新的服务器,这个时候会发生什么呢
三、原理
我们发现,使用取模的方式如1 mod 4 = 3, 2 mod 4 = 2...,如果我们加入一台服务器,之前存储在第3台服务器上的数据现在取数都被分发到 1 mod 5 = 4 第4台服务器上,结果就是找不到数据,如果这时候有大量的请求过来会全部去读取数据库,造成的结果就是缓存雪崩,对数据库会带来灾难行的后果。为了解决这些问题,一致性Hash算法出现了。
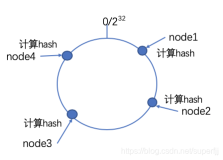
一致性Hash算法也是通过取模来完成,不过它不再是对例如服务器的数量来取模,而是对2^32 取模。算法原理即先构造一个2^32的整数环,根据服务器节点名称(或IP)的Hash值将服务器节点放在这个环上,然后根据数据的key值计算得到起哈希值,接着在环上顺时针查找距离这个key的Hash值最近的服务器节点,完成key到服务器的映射:
按照以上的假设,如果我们B节点宕掉了,按照规则B到A之间的数据会按照顺时针去寻找下一个离它最近的节点,受影响的也只有也只会是此环空间中的一台服务器的数据,增加一台服务器同理。
四、问题
一致性基本解决了以上问题,但是又暴露出另外一个问题---数据倾斜,即当服务节点过少而分部不均导致大量的数据集中到其中一个节点,为了解决这种问题,一致性Hash算法引入了虚拟节点机制,即将一个物理节点拆分为多个虚拟节点,并且同一个物理节点尽量均匀分布在Hash环上。
五、无虚拟节点代码实现
public class ConsistentHashTest {
static List<ServerNode> serverNodes= new ArrayList<ServerNode>(); // 真实机器节点
static class ServerNode{
private String nodeName;
private long nodeHash;
public ServerNode(String nodeName, long nodeHash) {
super();
this.nodeName = nodeName;
this.nodeHash = nodeHash;
}
public String getNodeName() {
return nodeName;
}
public void setNodeName(String serverNodeName) {
this.nodeName = serverNodeName;
}
public long getNodeHash() {
return nodeHash;
}
public void setNodeHash(long serverNodeHash) {
this.nodeHash = serverNodeHash;
}
}
public long hash(String key){
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//得到应当路由到的服务器结点
public ServerNode getServerNode(String key){
long hash = hash(key);
for(ServerNode node: serverNodes){
//已排序,第一次找到大于这个节点即可
if(node.getNodeHash() > hash){
return node;
}
}
//没找到则在最后,依赖的即第一个
return serverNodes.get(0);
}
//添加服务器节点
public void addServerNode(String serverNodeName){
long serverNodeHash = hash(serverNodeName);
ServerNode serverNode = new ServerNode(serverNodeName,serverNodeHash);
serverNodes.add(serverNode);
//将serverNodes进行排序
Collections.sort(serverNodes, new Comparator<ServerNode>() {
@Override
public int compare(ServerNode node1, ServerNode node2) {
if(node1.getNodeHash() < node2.getNodeHash()){
return -1;
}
return 1;
}
});
}
//删除服务器节点
public void deleteServerNode(String serverName){
for(ServerNode node: serverNodes){
if(serverName.equals(node.getNodeName())){
serverNodes.remove(node);
return;
}
}
}
public static void main(String[] args){
ConsistentHashTest cht = new ConsistentHashTest();
//添加一系列的服务器节点
String[] servers = {"10.0.0.20", "10.0.0.21","10.0.0.22", "10.0.0.23"};
for(String server: servers){
cht.addServerNode(server);
}
//打印输出一下服务器节点
System.out.println("所有的服务器节点信息如下:");
for(ServerNode node: serverNodes){
System.out.println(node.getNodeName()+":"+node.getNodeHash());
}
//看看下面的客户端节点会被路由到哪个服务器节点
String[] nodes = {"a.png", "b.png", "c.png"};
System.out.println("此时,各个客户端的路由情况如下:");
for(String node:nodes){
ServerNode serverNode = cht.getServerNode(node);
System.out.println(node + "路由到" + serverNode.getNodeName()+","+serverNode.getNodeHash());
}
//删除节点,发现所有客户端都在23上,然后就删除23节点
cht.deleteServerNode("10.0.0.20");
System.out.println("删除20节点后,再看看同样的客户端的路由情况,如下:");
for(String node:nodes){
ServerNode serverNode = cht.getServerNode(node);
System.out.println(node + "路由到" + serverNode.getNodeName()+","+serverNode.getNodeHash());
}
//删除20节点没有影响,然后就删除23节点
cht.deleteServerNode("10.0.0.23");
System.out.println("删除23节点后,再看看同样的客户端的路由情况,如下:");
for(String node:nodes){
ServerNode serverNode = cht.getServerNode(node);
System.out.println(node + "路由到" + serverNode.getNodeName()+","+serverNode.getNodeHash());
}
}
参考资料:
https://blog.csdn.net/u010412719/article/details/53863219