Apache HBase Backup/Restore 方案
本文开始我们会介绍Apache HBase关于Backup/Restore的方案,虽然HBase2.0的release 版本里面并不会带有该功能,但是我们ApsaraDB for HBase会对应的提供该功能。我们经常会听到“某某某DBA误操作把整张表删了”,“某某磁盘故障,造成数据库的某个库的数据全部损坏了”。这种由于外在和内在的原因造成的数据不可靠,最终会给用户带来毁灭性的灾难。所以基本上所有的数据库都会对应的提供Backup/Restore的方案,以防用户误操物理上删除了一整个表或者别的问题造成的悲剧; 一般通过定时的做备份无论是全量数据做备份还是对增量数据做备份,此外一旦遇到上面提到“悲剧”,通过一键命令就可以恢复数据;
本文开始我们大概的文章架构是:常见的数据库backup/restore方案;Apache HBase的Backup/Restore方案;
1.常见的数据库backup/resotore方案
单机的数据库有Mysql,pg等,一般的话,Mysql的备份的话,可以有备份数据文件的方式到本地磁盘,也有直接进行逻辑备份,操作的sql语句;其他的单机数据库使用的技术也是差不多;
分布数据库的话cassandra的话,也是对数据做快照,然后copy 文件到一个备份的地方,增量备份的话使用备份wal log的方式,但是存在问题是:恢复的话,需要恢复到对等的拓扑结构的集群,再次增量备份wal的话会存在多倍的网卡开销;
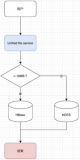
现在来大概介绍HBase的备份和恢复的机制,和单机数据库对比的话意义不大。全量数据备份的话,HBase会对本地文件做一个snapshot,然后通过mr的方式将数据文件copy到一个特定的指定地方,增量备份的话,通过将wal log转换为Hfile,然后copy到远端一个特定备份的地方。这种增量备份是主要备份wal log,且是指定时间的做备份,一天或者一周。
对于恢复模块的话,可以是全量的数据恢复以及增量的数据恢复,基本的逻辑都是将文件copy到HDFS上,然后做一次bulkload即可将数据恢复回来。
2.Apache HBase的Backup/Restore方案
这里分别从4个方面进行介绍,主要是:常见使用方法,全量数据备份和恢复,增量数据备份和恢复,我们即将提供的一些特定功能。做
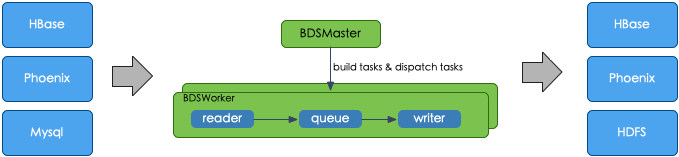
Apache HBase提供的数据备份 可以支持备份到不同地区的HDFS,也支持备份到OSS上面。大概的逻辑可以参考下面的图:
2.1. 使用方法
2.1.1. hbase backup create full/incremental path
full:创建全量备份
incremental:创建增量备份
path:备份到的文件系统以及对应的路径
可以跟的选项:-t table;如果不写就是全部的表都备份
-w 后面跟的数字,表示多少个工作任务
-s 备份的set
-b 控制备份的带宽
2.1.2. hbase restore path backupid
path:备份的路径
backupid:备份的id;
后面可以的选项: -o 覆盖之前的表
-t 备份的表,其他选项类似
2.1.3.hbase backup merge <backup_ids>
把一些backup的id进行merge,可以是每日的backup merge成一个;
2.1.4.hbase backup progress <backup_id>
展示backup进度
AI 代码解读
2.2.全量备份和恢复
这里说的全量备份,主要是从某一个时间点开始做数据备份,这个点之前都没有做过备份,那么这次备份就是全量数据备份,需要使用create full 这个命令;备份的path是我们预先设定好的可以是HDFS的路径也可以是OSS的路径,那么对应的HBase就会存在下面几个流程:
1.backup:system表做snapshot;
2.全局barrier然后让各个rs做log roll,并将各个rs的最新的log的ts记录到backup:system表了;
3.然后各个rs做snapshot,然后mr跑数据,做数据copy到对应path下;完成以后update下system表;并将数据更新到备份的文件系统上面。
AI 代码解读
上面大概就是HBase的全量备份的流程,整个流程下来,我们做一个对比,因为HBase 在Hadoop生态下面,引入MR做批处理数据操作是轻而易举的事情,但是别的分布式数据库做这个操作就是比较困难的。下面的流程是HBase做全量恢复的流程:
0.load 最新的table的原信息(通过备份好的文件),对应的在restore的节点上面进行建表;
1.把对应的full backup下面的data通过mr的形式丢在hdfs上面的一个临时文件下面;
2.bulkload对应的这些文件;
AI 代码解读
同理整个流程下来主要是依赖MR的批处理能力做加速,当然通过bulkload将文件进行恢复也是海量数据下的恢复的最快的一种办法;
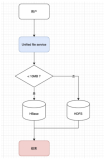
2.3.增量备份和恢复
增量的备份的话,主要是在一个HBase集群做完一次全量备份以后的每一次的增量数据的备份都叫做增量备份,HBase主要是依赖WAL log做数据备份的主体,因为WAL log是增量数据里面最全的,先写wal 才可以存Memstore,大概的备份和恢复的流程如下:
0.发送log roll到各个rs;各个rs也会把自己的当前的log最新信息记录到backup:system里面;
1.wal log转为hfile;(mr任务)
2.mr做数据copy到远端;
3.记录完成的wal log到backup:system表里;
AI 代码解读
0.load 最新的table的原信息,对应的在restore的节点上面进行建表等;
1.先做full restore,完成以后一步步的做增量的恢复,增量恢复到的时间点是你做增量的备份成功给出的那个backup id;
2.每一步都是先把wal的变成的hfile,做bulkload;
AI 代码解读
上述的方式除了可以引用MR做批处理外,保证输出的输出是一份完整的HFile,而不是某些DB那种各个节点输出一份数据,多倍数据输出,消耗了网卡等资源。
当然大家如果有兴趣一起探讨技术可以加我们的钉钉群。
最后的最后播报下!!!
云HBase2.0 在2018年6月6日将正式发布,点击了解更多