大家可能熟悉的机器翻译工具有很多,如Google的机器翻译,Bing的翻译甚至Youdao翻译,但是大家对阿里的机器翻译了解多少呢?在《云栖大讲堂第三期|未来人机交互技术沙龙》上阿里巴巴集团机器智能技术实验室的资深算法专家陈博兴介绍了阿里翻译团队在跨境电商领域内遇到的挑战以及相应采取的措施,即数据的搜集选择,机器翻译模型,以及阿里翻译团队相关的创新性工作。
数十款阿里云产品限时折扣中,赶紧点击这里,领劵开始云上实践吧!
演讲嘉宾简介:
陈博兴,阿里巴巴集团机器智能技术实验室的资深算法专家。他的研究方向是机器翻译,自然语言处理和机器学习。在加入阿里之前,他是加拿大国家研究委员会(NRC)的研究员(2009-2017),再之前先后是法国格勒诺布尔大学和意大利FBK-IRST的博士后,新加坡信息与通信研究所的研究员。他1998年本科毕业于北京大学,2003年博士毕业于中科院声学所。他和同事合作先后发表了50来篇会议和期刊论文,并且担任过NLP领域所有顶级会议和期刊的审稿人或程序委员会成员。他领导的团队先后在各种机器翻译评测中取得优异成绩,比如获得了2017年WMT俄语到英语第一名,NIST2012机器翻译中文到英文第一名,2007和2005年IWSLT口语机器翻译比赛第一名等等。
以下内容根据演讲嘉宾视频分享以及PPT整理而成。
本次的分享主要围绕以下五个方面:
一、简介 Who are we?
二、阿里机器翻译场景及业务伙伴
三、电商场景内机器翻译遇到的挑战
四、阿里机器翻译采取的策略
五、总结
一、简介 Who are we?
大家可能了解熟悉的机器翻译工具有很多,如Google的机器翻译,Bing的翻译甚至Youdao翻译,但是对阿里的机器翻译不是很熟悉。每年双十一期间,俄罗斯物流系统就会崩溃!因为俄罗斯人民通过AliExpress从中国买了太多的东西,那么是如何实现的?俄罗斯人民看不懂中文,中国的卖家也不懂俄罗斯语。所以,这显然得益于阿里巴巴翻译系统!
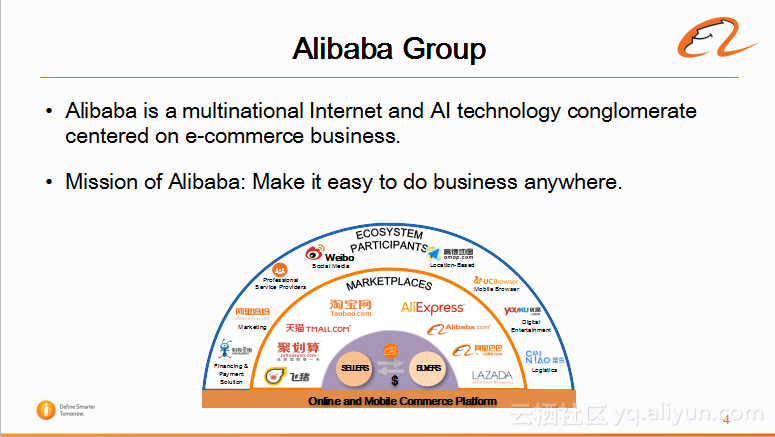
相信大家对阿里的业务已经非常熟悉。总体来说,阿里是一个跨国的,互联网跟人工智能技术公司,阿里的使命是让天下没有难度的生意,其业务核心是买家与卖家建立联系,所以阿里有一系列的电商平台,包括飞猪,天猫,淘宝,AliExpress,Alibaba.com,聚划算,东南亚的LAZADA;以及为这些电商服务的扩展平台,比如金融,物流,广告等等。那么在买家与卖家说同一种语言,则没有问题,但是买家与卖家说不同的语言,则需要机器翻译来介入。
阿里在2016年的11月份成立了达摩院。首先,达摩院有个顾问委员会,分别会在亚洲,美洲和欧洲成立分院。然后,阿里集团内部会有四大实验室,其中第一个实验室是机器智能技术实验室(MIT Lab),后续还有成立三个实验室。除此之外,在外面,达摩院还会与各个大学和科研院所合作成立联合实验室。比如,与浙江大学联合成立的前沿科学联合实验室,与每个伯克利大学成立的RISE实验室,与中科院成立的量子计量实验室,与清华大学成立的金融科技实验室,以及跟新加坡南洋理工大学成立的人工智能实验室。
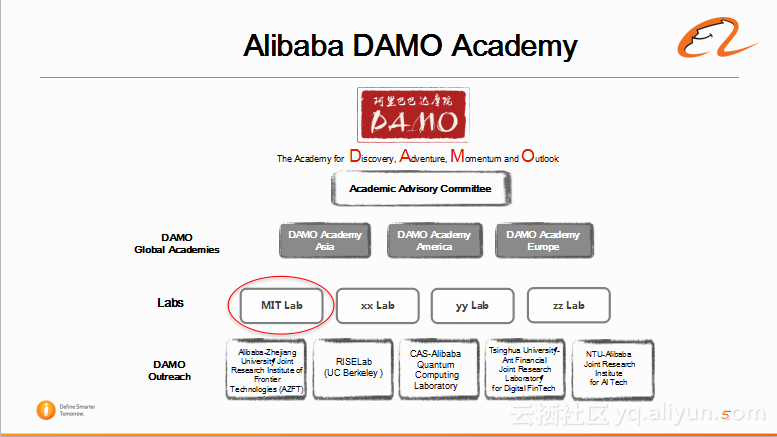
我们是在其中的机器智能技术实验室(MIT Lab),MIT实验室的前身是iDST, 成立于2014年,目前已经有400多个科学家和工程师。实验室人员分布在杭州,北京,西雅图,硅谷,新加坡和莫斯科等地。MIT实验室主要是做人工智能领域内的基础方面的研究。MIT实验室主要有四个团队,第一个是语音技术团队(Speech Technologies);机器翻译是来自自然语言处理团队(Natural Language Processing),其中还包括问答,情感分析等小团队;另外两个团队分别是图像与视频技术以及深度学习与优化技术。

我们是阿里巴巴的机器翻译团队,如之前所说,在杭州,北京和西雅图都有成员,大概有40名工程师和研究员。同时技术团队与业务团队紧密合作,业务团队是主要负责分解并转交阿里内部的机器翻译需求。比如AliExpress, AliExpress的人员不会直接与技术团队沟通,而是找到做业务的同学,提出要求,那么做业务的同学会根据要求将需求进行技术层度的分解,然后交给不同的技术团队,比如图像识别,机器翻译等团队。如此,有利于技术团队可以更加专注于技术。整个机器翻译团队还会分为不同的小组,比如像创新技术小组,翻译系统构建小组,数据小组,还有工程架构小组以及人工翻译平台小组等等。

如阿里巴巴的使命是让天下没有难做的生意,那么阿里翻译平台的使命便是让天下的生意没有语言障碍。
二、阿里机器翻译场景及业务伙伴
翻译在电商领域都有哪些应用的场景或者都有哪些可以带来价值的地方?首先是流量的引导,站内的搜索,预订和购买,以及买卖双方的沟通等场景需要带来价值。做过机器翻译的可能知道在评价翻译质量好坏时,可能会用到BLEU Score这样一个衡量标准,做人工翻译时可能会评价忠实度,流利度。但在业务上,有一些指标评价,比如,使用翻译之后是否提高了用户的访问量,是否提高了商品的转换率等等业务指标来评价机器翻译是否真正给商品带来价值。
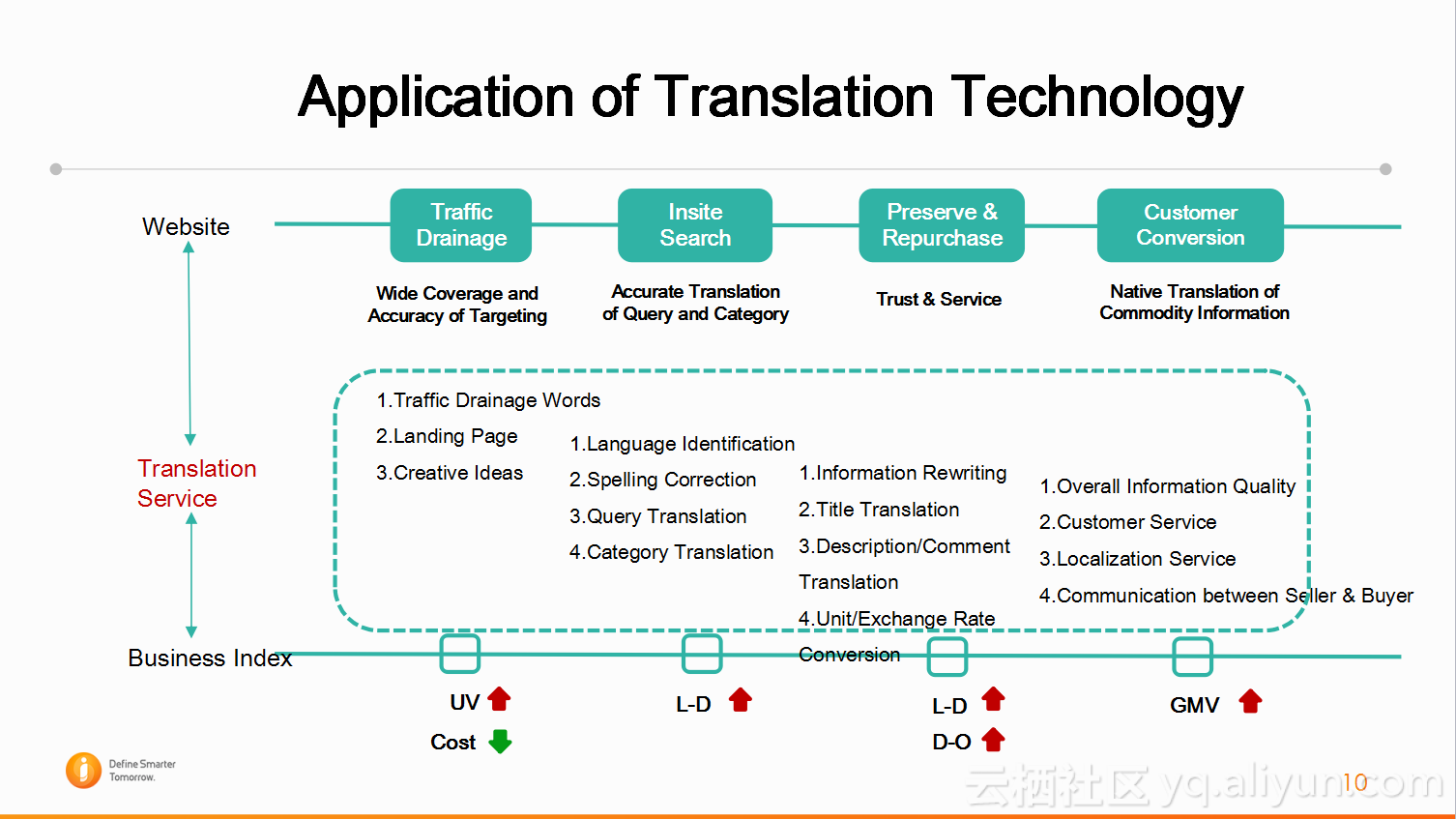
下图为阿里的生态圈,目前机器翻译平台支持很多阿里内部的合作伙伴,包括支付宝,天猫,淘宝网,LAZADA,AliExpress,Alibaba.com等等业务方。所以说,机器翻译平台已经支持了阿里相当多的业务。
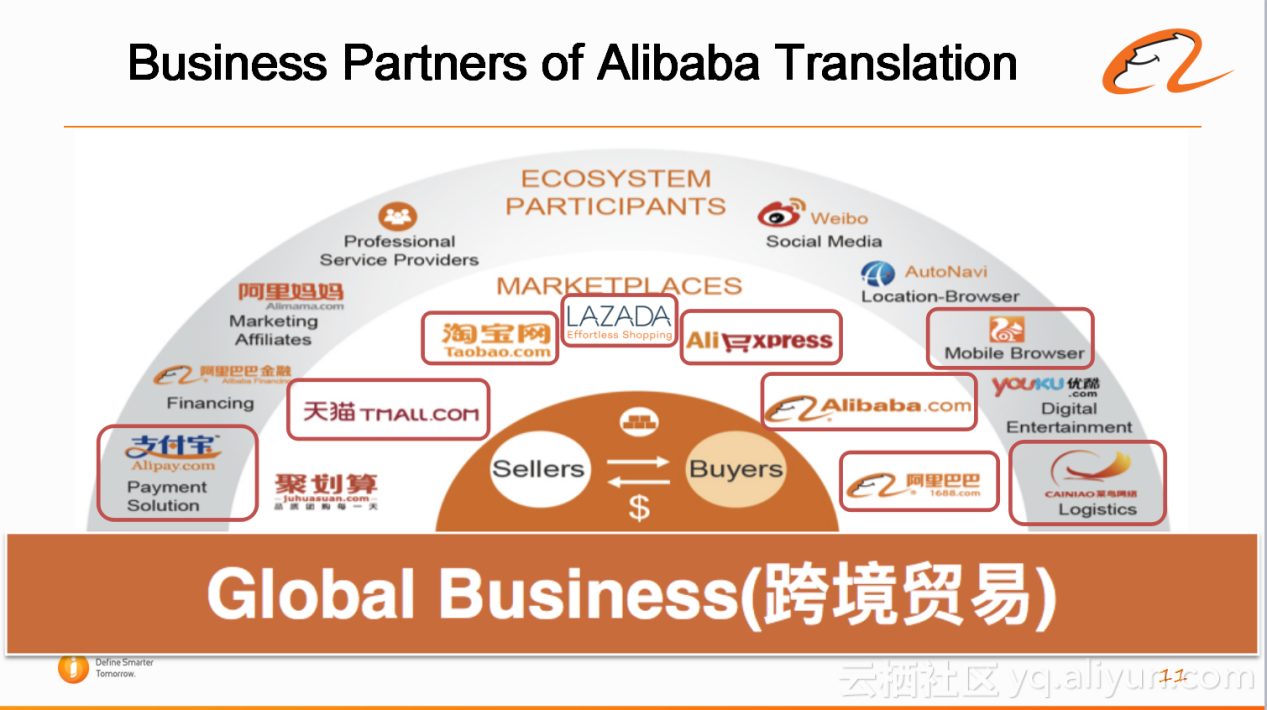
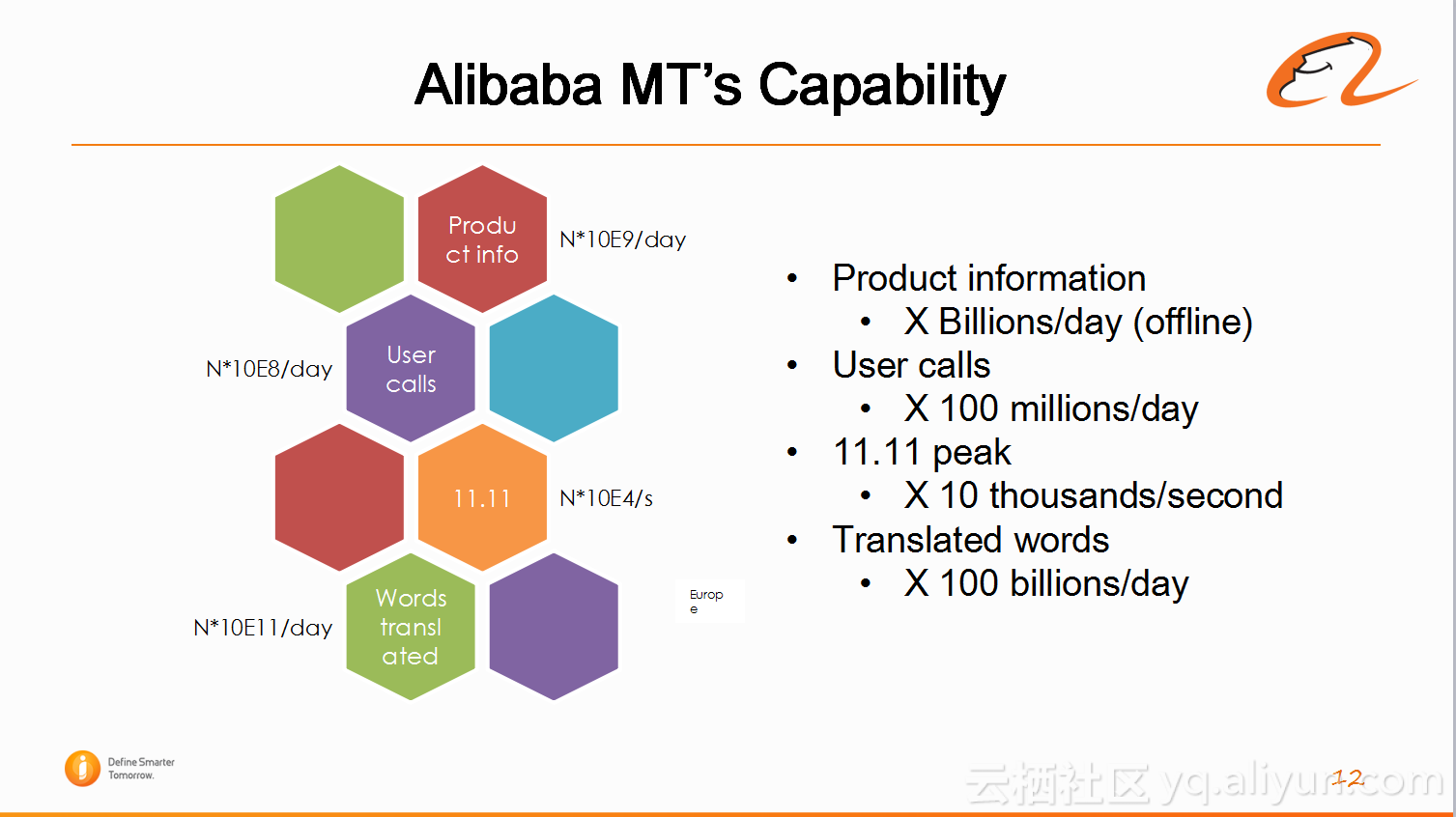
下图为阿里机器翻译平台的能力数据展示。假设翻译线下的中文网站,比如淘宝网,机器翻译可以达到每天翻译出几十亿量级的产品信息,每天的线上翻译请求到达数亿次,在双11时每秒钟的翻译请求大概有几万次,然后每天翻译的词语个数超过2000亿。2000多亿的是什么概念?比如Google的翻译是有好几百个语言对向全球所有人开放,2016年披露的数据表明它每天翻译的词语个数大概是1400多亿,而阿里单个公司,而且绝大部分普通用户没用过阿里翻译的情况下,翻译的词语已经达到上千亿级别,其他平台是很难到达这个级别的。所以说在阿里是有机器翻译的,且用到的地方非常之多,业务量也非常大。
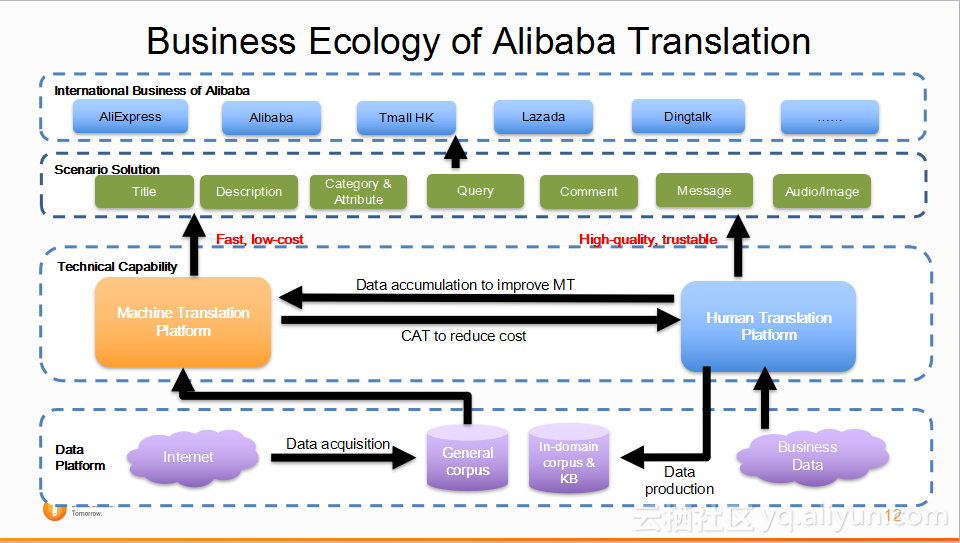
下面进一步了解一下阿里翻译的业务生态。首先数据部分,从网上获得了很多平行语料数据。然后阿里有自己的机器翻译平台和人工翻译平台。人工翻译平台实际上是阿里通过众包翻译平台将需求放上去,外面的译员通过平台进行翻译,并获得一定的报酬。通过这种方法,一方面阿里可以收集通用领域内的数据,同时阿里也通过在众包平台上放一些领域内的数据或者电商领域的数据。通过领域内的数据来提高机器翻译的性能,同时改善的机器翻译也能够提高人工翻译的效率。阿里通过机器翻译以下类型数据,比如产品标题,产品的描述,产品类别信息,产品评论,消息等等,然后支持不同的业务平台。
阿里从2012年初和学术界有一些合作,刚开始有一些机器翻译的同学在做,到2014年阿里机器翻译团队正式成立。通过这几年经验的积累,阿里也提出了改善机器翻译性能的闭环。首先部署一版机器翻译系统,上线,大量用户使用机器翻译,阿里通过收集用户偏好的数据准备语料(不管是网上的语料还是众包平台),之后优化引擎,做一些自动的和人工的评测判断出哪些改进的地方。但是目前只是从翻译角度判断完成了改进,那么从用户角度,则需要进行将两个版本系统(A/B test)进行对比,证实了改进之后,再上线。

三、电商场景内机器翻译遇到的挑战
在电商领域,做机器翻译其实存在很多挑战的,可能跟通用领域有些不一样。首先,翻译到的目标语言对文本的可读性要求很高或者流畅度很高,如果翻译的磕磕绊绊,用户会对没有耐心看完该产品的相关信息,便查看另外的商品。如今得益于神经网络机器翻译的出现,使得翻译的流畅度得到飞跃式的提升,所以目标语言可读性高这项要求基本达到了满足。第二项,关键信息翻译必须准确。如产品名,购买数量及数字等信息都非常重要。如果品牌名翻译错误,便会得到商家投诉,如果商品数量错误,也会造成买家与卖家的纠纷。前段时间有一则相关新闻,挪威体育代表团想买15个鸡蛋,但是商家送来了15000个鸡蛋,造成了全球性的娱乐事件。阿里翻译需要对数字,品牌进行极其精确的翻译。另外阿里翻译需要有及时的干预机制,对于暴力,色情的信息做处理。以上是对翻译质量上的挑战。
另外,阿里翻译也存在速度上的挑战。首先,由于商品数量很多,阿里翻译也必须在训练速度上加快。比如在高峰期,双11时期流量非常庞大,阿里翻译要求20-30词语的句子的翻译时间不能超过100毫秒的级别。假设,翻译速度达不到要求,2秒钟才出来翻译结果,买家会没有耐心等到结果出来,可能看一条同样类型的商品。导致的结果就是即使翻译准确,但是翻译还是无法给商家带来价值。
除了翻译质量和翻译速度上的要求,还有服务质量上的要求。可用性要高,灵活,可用性的界面(手机,ipad,PC端等凡是可以购物的地方都需要提供界面),还有能够翻译多种语言,以及可以快速部署和更新。

四、阿里机器翻译采取的策略
针对以上这些挑战,阿里翻译采取了相应的策略。分别从数据,模型以及特征等方面采取了不同的策略。
1.阿里机器翻译的数据
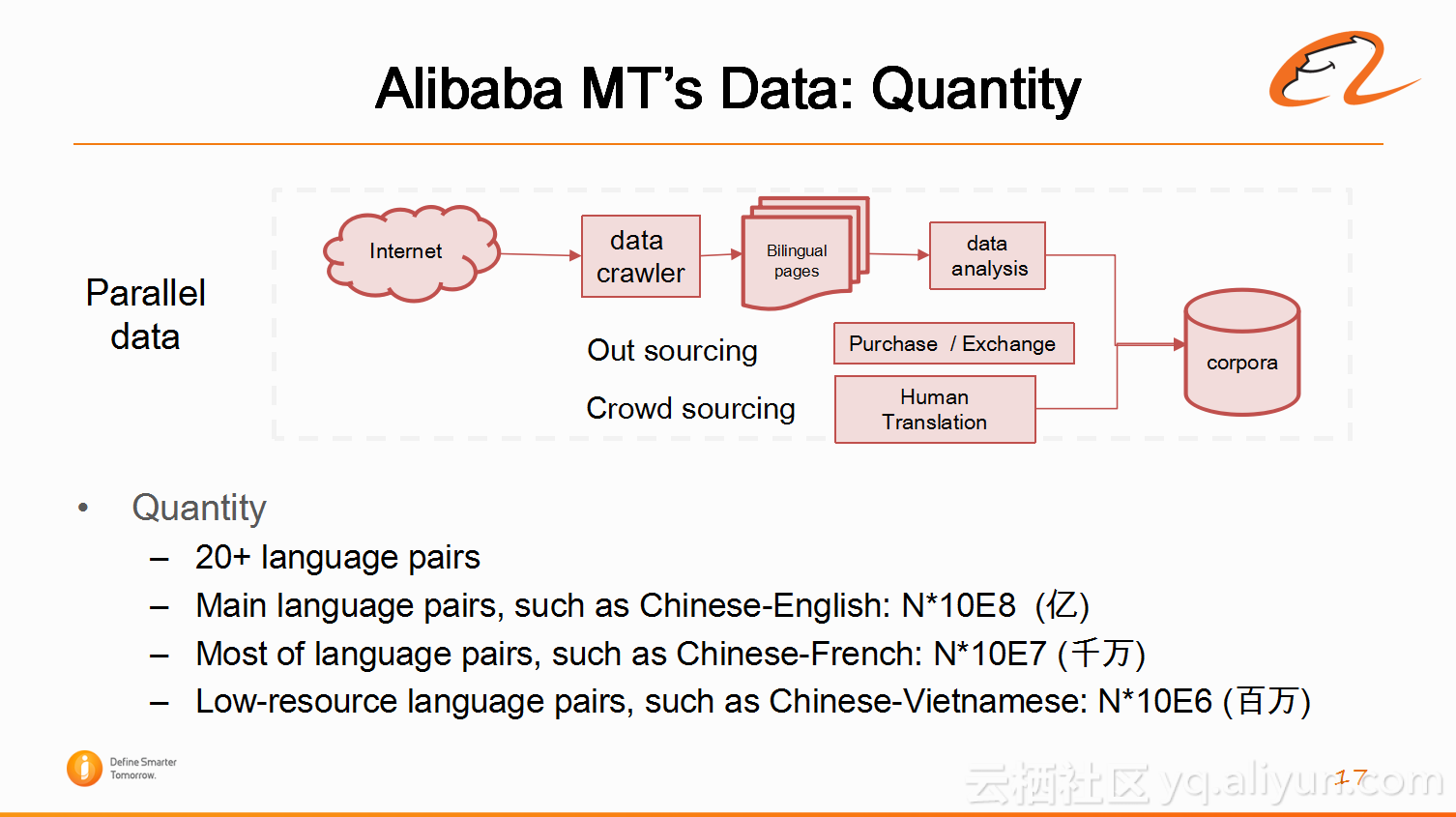
首先,阿里翻译会通过互联网爬取数据,这是通用的数据主要来源。另外,阿里翻译也会从一些学术机构单位,做翻译的单位购买和交换一些数据。还有就是从众包平台搜集数据。可以说,阿里翻译在搜集数据这一块花了大量的时间和金钱。而且阿里搜集到了大量的电商领域的数据,在机器翻译圈中,在数据上面建立了强大的壁垒。目前,阿里翻译已经搜集了20多项语言对,在主要的语言对上,中英文已经达到了几个亿的级别。其他很多语言对已经到了几千万的级别,比如中法文。另外,一些小语种语言对大概到了几百万的级别。因为LANADA是目前阿里收购的很重要的东南亚电商平台,主要对印度尼西亚,泰国等国家提供大量的服务。所以阿里翻译正在对于东南亚语言对这方面花很大的精力提供支持。
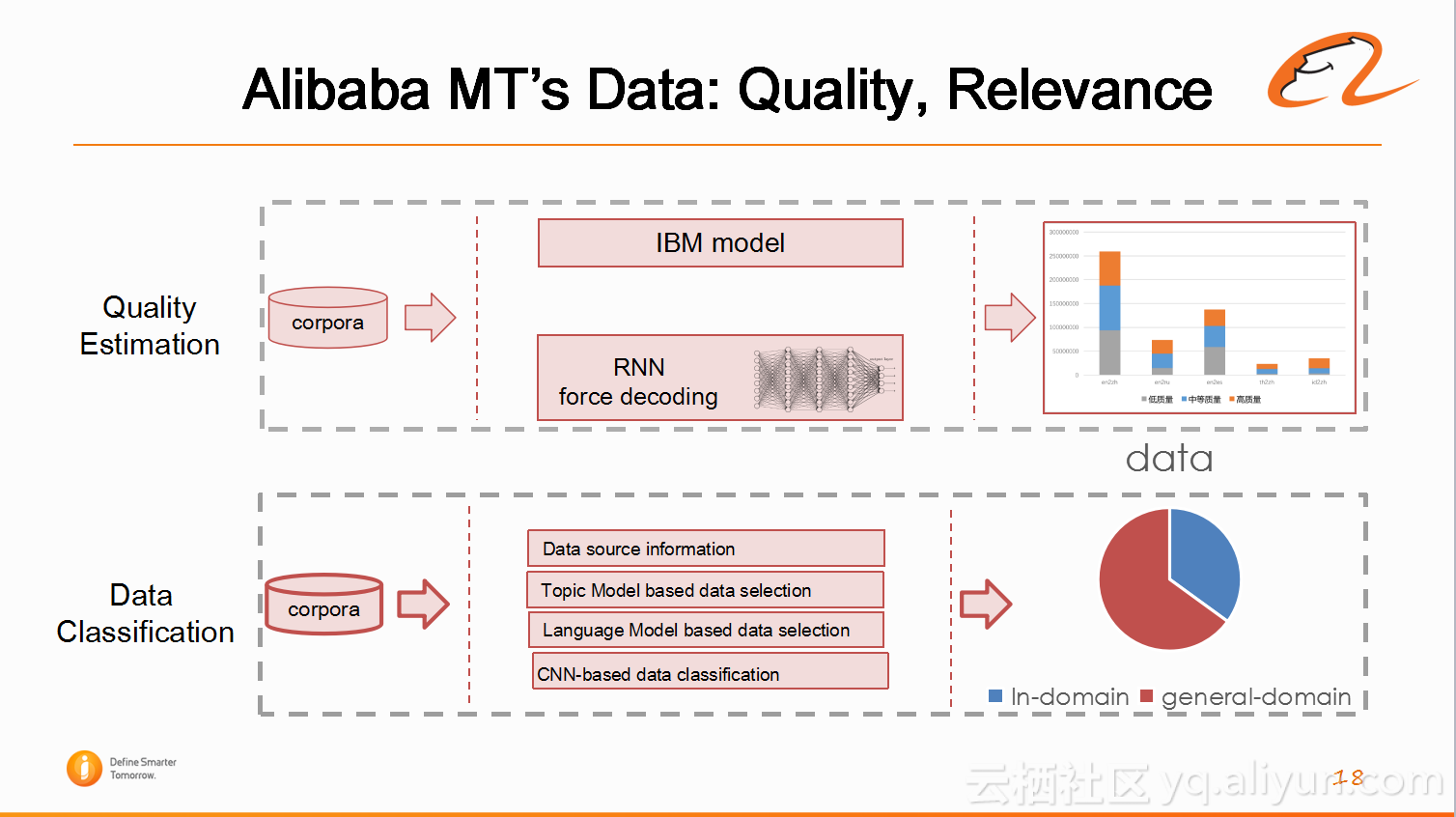
数据搜集光有数量是不够的,还需要有质量,尤其是神经网络系统需要训练数据的质量要求还是很高的。阿里翻译采取学术界通用的方法,如IBM model,以及基于神经网络的循环神经网络的force decoding等方法对数据进行打分。然后在不同的运用场景下,使用不同的质量数据。另外还需要保证数据领域相关性,如果是通用领域的数据,在电商领域的翻译效果不会很高,甚至同样在电商领域,不同产品之间也是需要进行区分。比如apple指的是苹果的手机还是说苹果这个水果。所以,必须选择跟领域相关的数据进行翻译,因为所有翻译是从数据中学习出来的。阿里翻译同样也在使用学术界目前使用的数据挑选方法,包括来自数据源的信息,基于主题模型挑选方法,基于语音模型的数据挑选方法以及基于卷积神经网络的数据挑选方法。
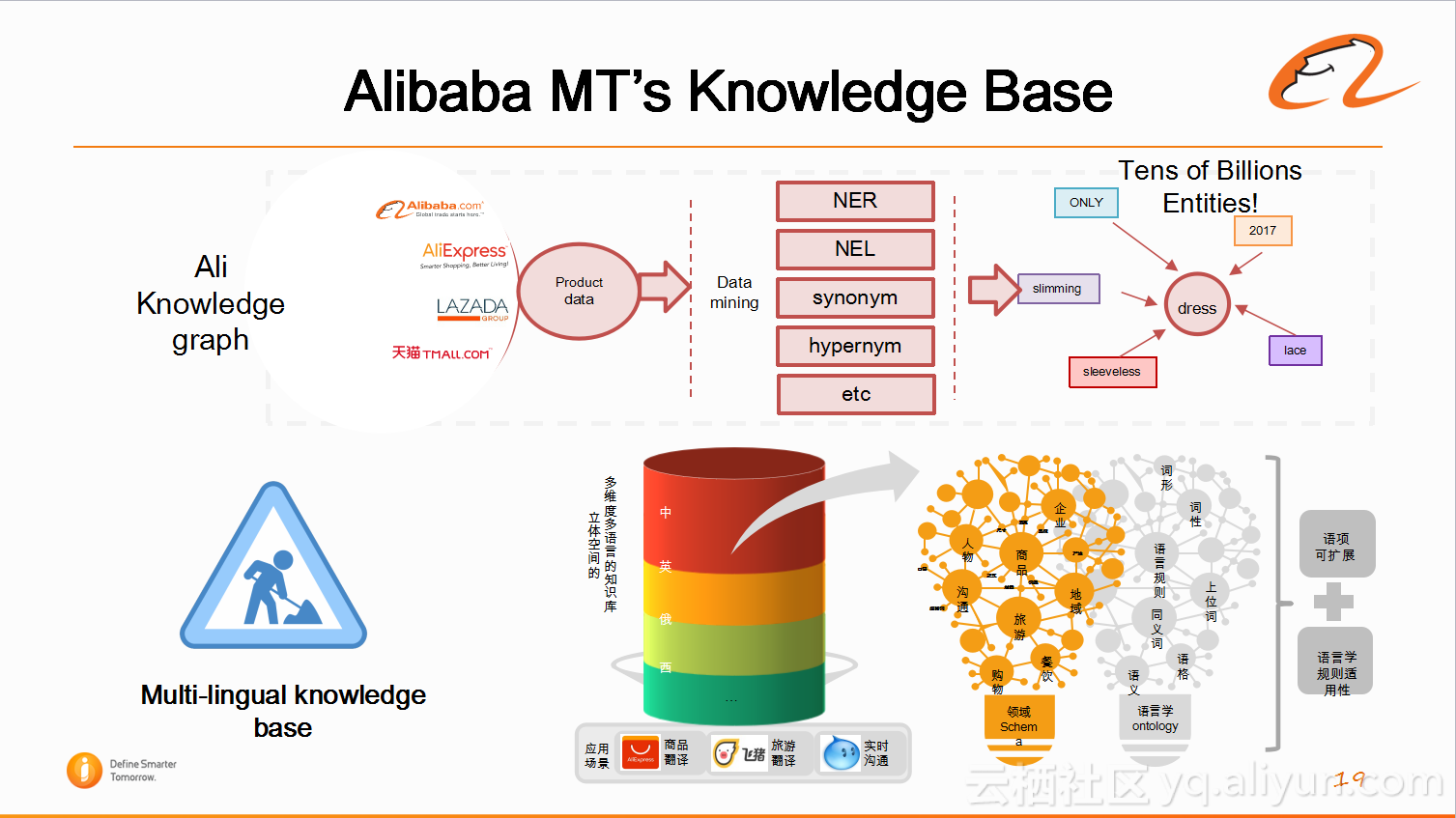
因为阿里翻译需要精确翻译商品品牌名,数量等信息,所以需要建立多语言的知识图谱。阿里翻译基于阿里的知识图谱(目前大概有100亿的词条),正在进行多语言化,主要是电商领域的信息翻译成中文,英语,俄语等。这项工作正在进行过程中,还没有完全运用到系统当中。
2.阿里机器翻译模型
1)基于规则的机器翻译模型(RBMT)
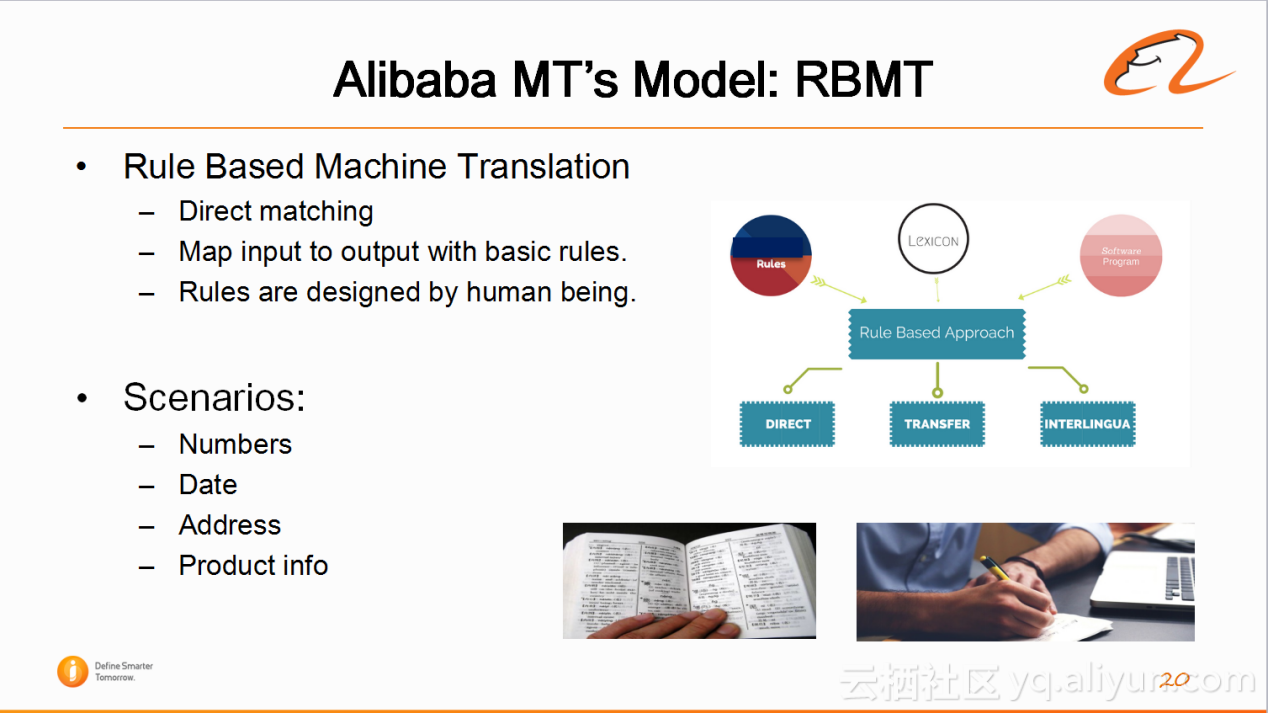
从整个机器翻译的发展历史来看,有基于规则的机器翻译时代(大概有20-30年的历史),接着是统计机器翻译的年代(90年代-2014),然后2014开始有了神经网络机器翻译。如果参加学术界会议,现在很难看到基于规则或统计机器翻译的文章,那是否这两种模型真的已经过时了?阿里翻译认为,在不同场景下,这些模型还是有自己的优势的。比如基于规则的模型虽然很多年不再被使用,但是在翻译数字,翻译日期,翻译地址以及翻译商品相关信息时,使用简单的规则加上cover的词典,翻译的结果非常好且准确度很高。所以,阿里的翻译系统有一块是基于规则的翻译模块。
2)统计机器翻译模型(SMT)
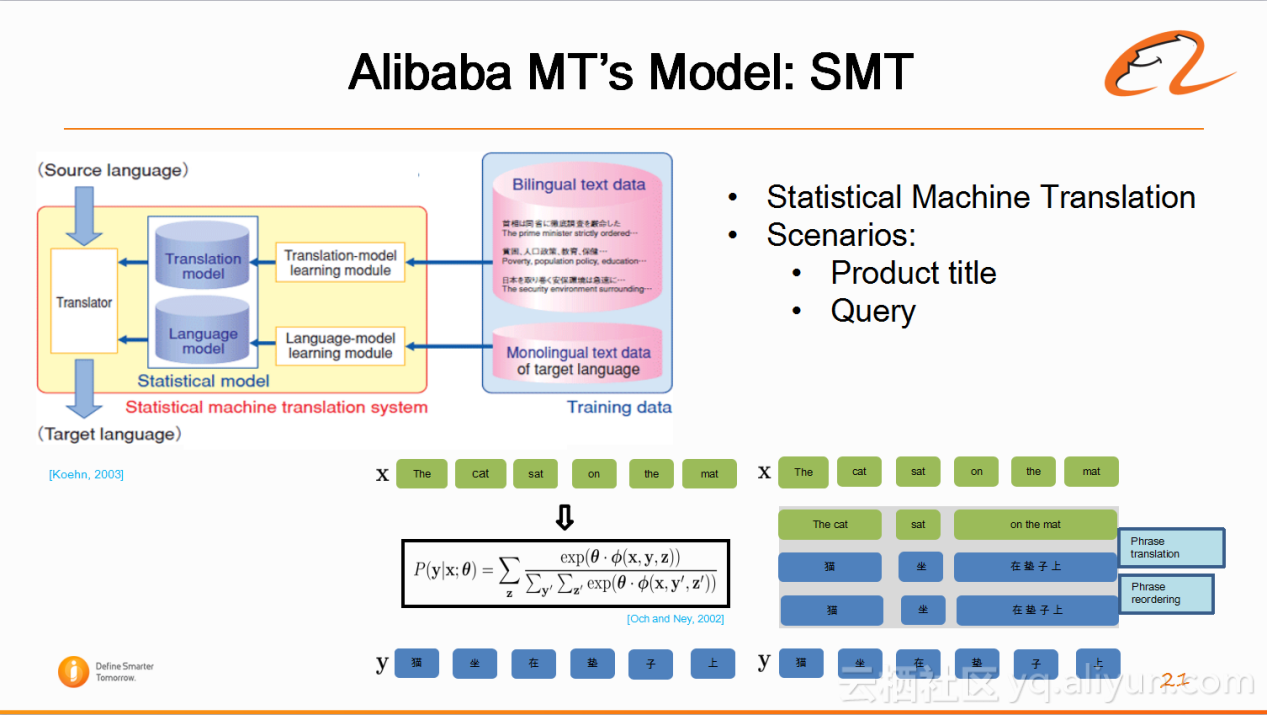
阿里机器翻译也有统计机器翻译系统。虽然神经网络机器翻译的流畅度很高,但是在不同场景,统计机器翻译也非常有优势。比如产品的标题都是一个一个字段拼在一起的短语,各个短语之间没有语序,也不存在逻辑性。这时使用统计机器翻译系统,就可以翻译的非常好。另外,用户在搜索产品时,也是输入一两个词语,这个时候基于短语的统计机器翻译系统(学术界常用的统计机器翻译系统)翻译的效果也很好。
3)神经网络机器翻译模型(NMT)
当然,阿里翻译也有神经网络机器翻译系统,并且实现了基于循环神经网络的seq-seq模型(RNN-based seq-seq model),以及2017年刚刚推出的Transformer模型。NMT model优势在于流畅高,翻译语序很好,逻辑性强。比如英文翻译为中文,不会存在英文语序结构,可以使用在20-30词语的句子的场景翻译,像产品描述,消息(买家与卖家的交流),买家的评论。那具体使用哪一NMT系统,阿里翻译会同时使用两套系统进行PK,虽然Transformer性能通常更优,但是不同场景下RNN-based seq-seq model也可以同样优秀,最终选择都以实验结果和人工评测为准。
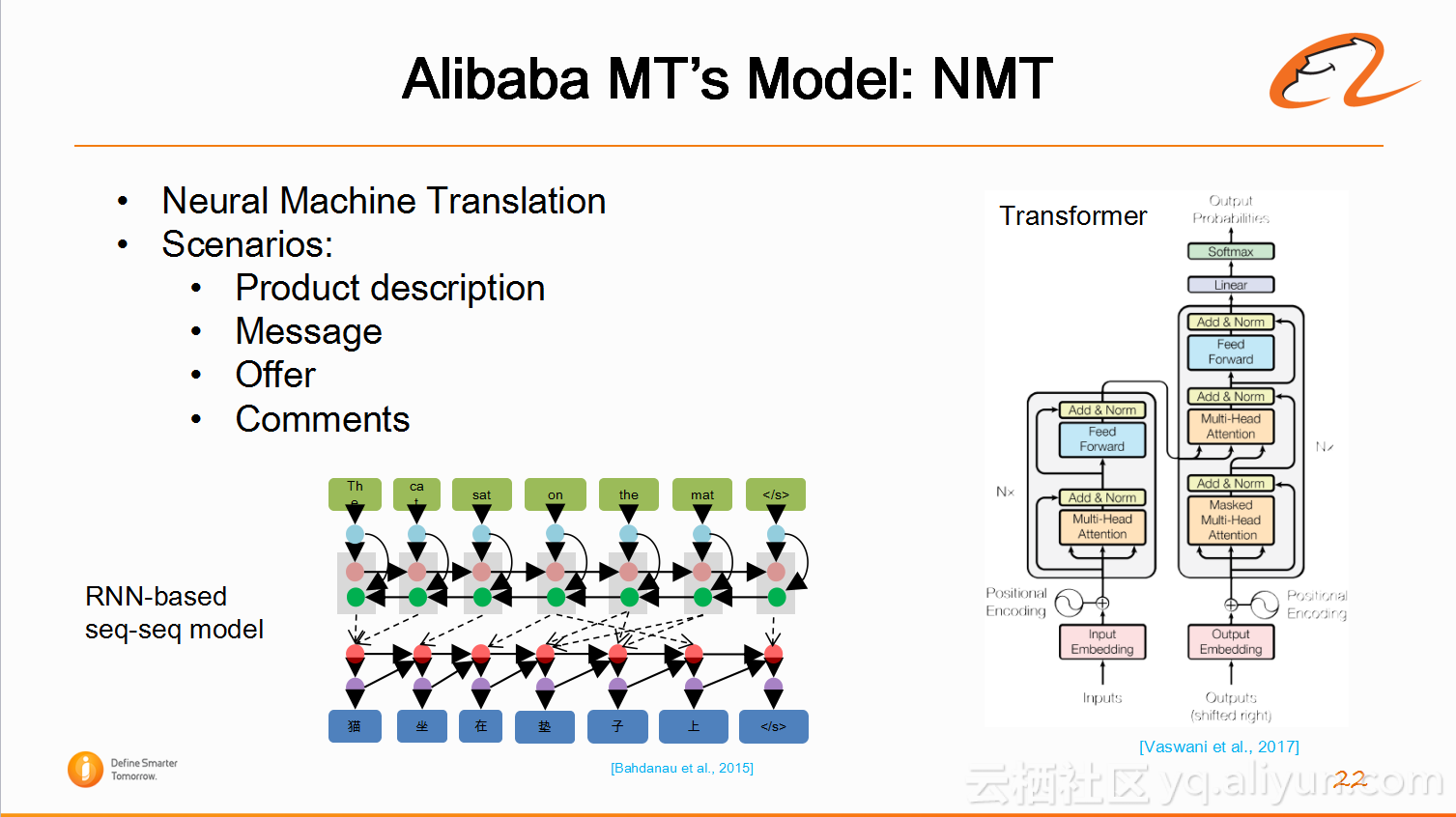
3.阿里机器翻译创新性工作
除了上面的现有的机器翻译系统,因为我们是达摩院下的机器翻译实验室,包括很多硕士,博士,研究员等,所以也做了很多机器学习方面的创新性工作,下面进行简单介绍。
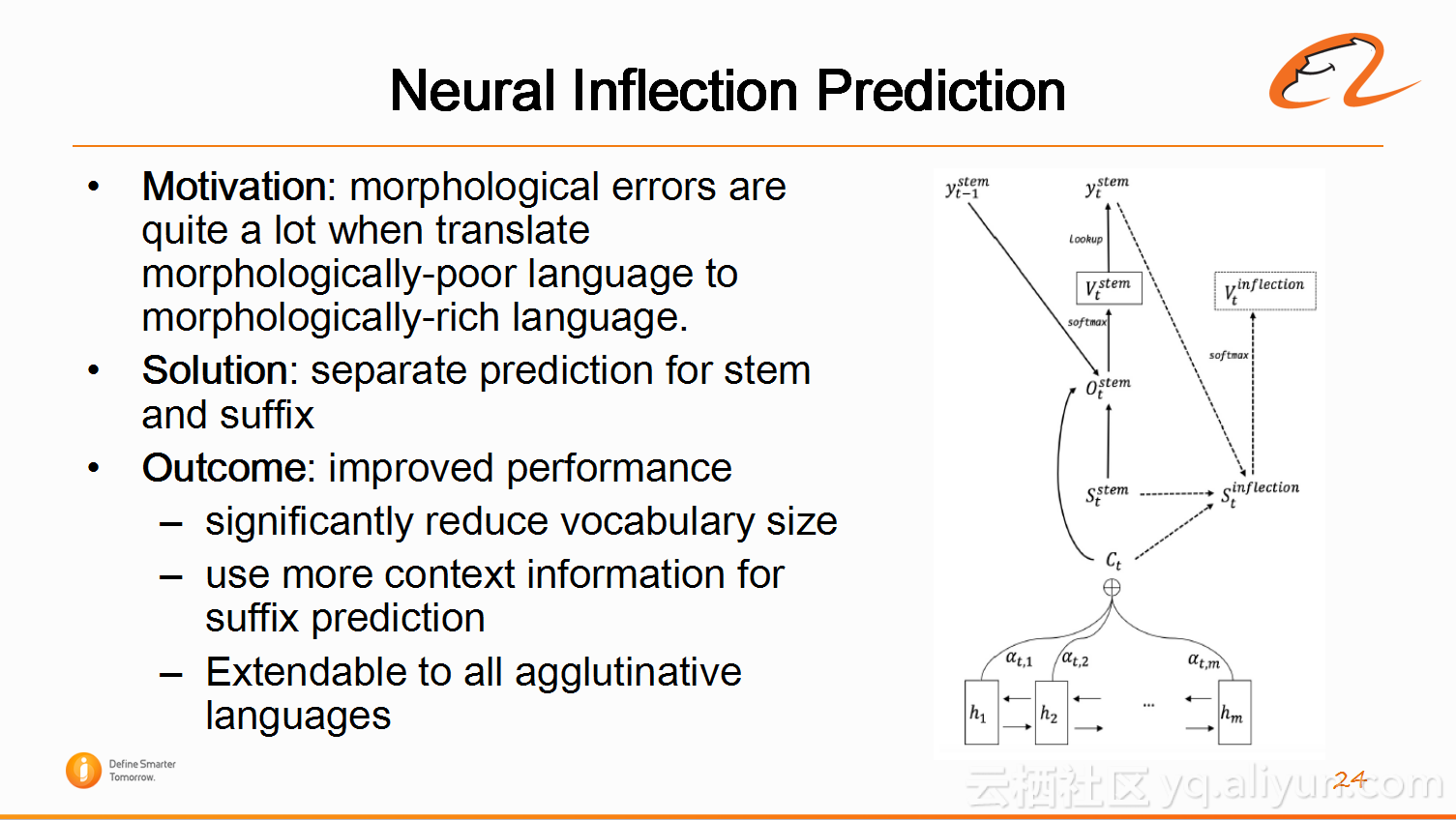
1)词尾预测(Neural Inflection Prediction)
第一个,词尾预测。中文当中没有单复数变化,没有时态变化,但是英文里有。英语的词法还相对简单,俄罗斯语则不然,语法相当相当复杂,同一个名词,开头的词干不变,后面的词缀可以有几十种变化。这时,从中文或英文翻译成俄语,因为源语言词语没有这些词缀变化,翻译的结果同样没办法生成这些词缀变化。那俄罗斯人经常从阿里平台买东西,中文-俄语,英文-俄语的翻译需求非常大。为了解决这个问题,阿里翻译做了词尾预测这个工作,就是将俄语做词法分析,切分成词干和词尾。源语言有一个Seq,目标语言有两个Seq,预测完词干(下图模型左边),再预测词尾,这时会利用三个信息,首先是源语言的信息,然后是当前词语的词干信息,以及前面词语的词尾信息,这样就可以提高词尾预测的信息率。该项工作已经在2018年的AAAI上面发表了文章。
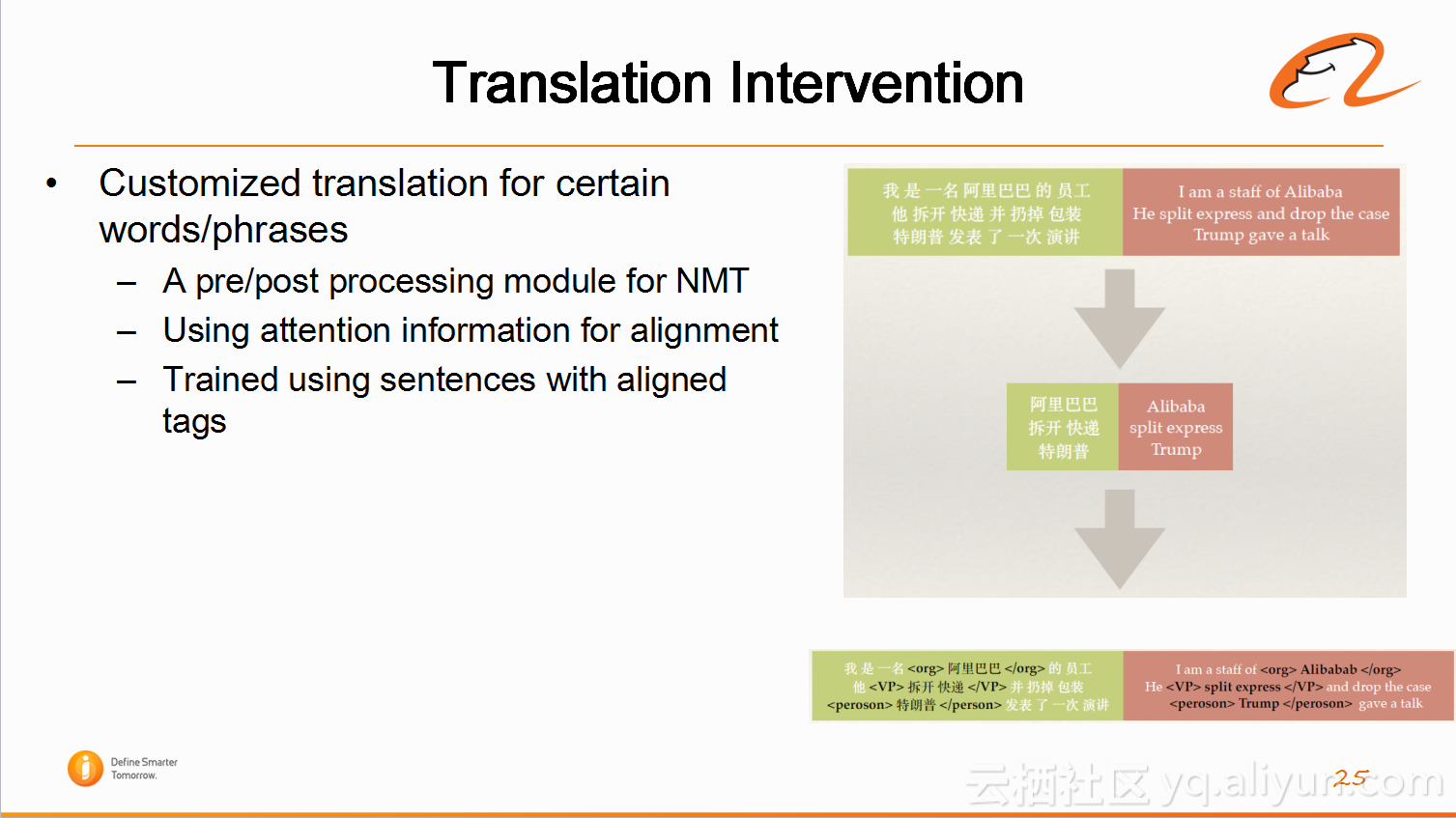
2)机器翻译的干预(Translation Intervention)
另一个工作是机器翻译的干预,前面提到机器翻译对于关键信息翻译准确。但是在神经网络做干预非常难,因为它不是按每个词翻译,而是将这句读下来,理解之后在用目标语言复述一遍,这时有些信息会翻译不到,因为这项技术还是有些弊端。阿里翻译将一句话的关键信息提取出来翻译,之后在目标语言中copy。Copy这项操作很简单有效,但只能解决80%的问题,而在电商领域需要解决99%的问题,甚至更高。目前阿里翻译通过与外面的大学的科研机构合作,大概解决了95%的问题,希望继续做研究,干预成功率达到99%以上。
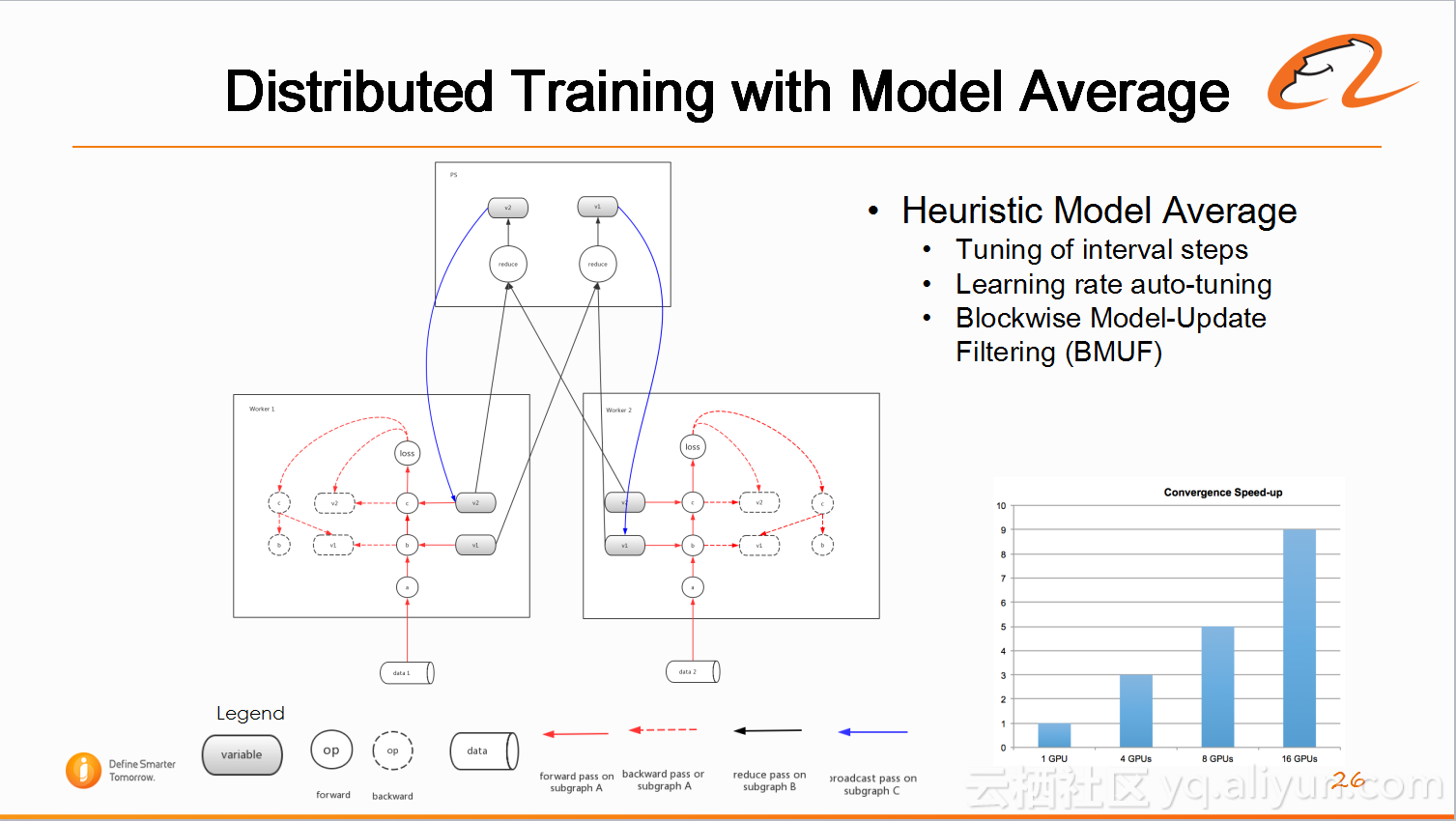
3)分布式模型平均训练(Distributed Training with Model Average)
在上面提到过,训练语料已经达到十亿的级别,如果单用一个GPU训练无法高效地完成。这时需要使用多机多卡,将数据切分为多个块,每个GPU单独训练完得到一个模型,然后给模型做平均,再继续训练。如此,利用多机多卡就可以将训练速度得到提高。
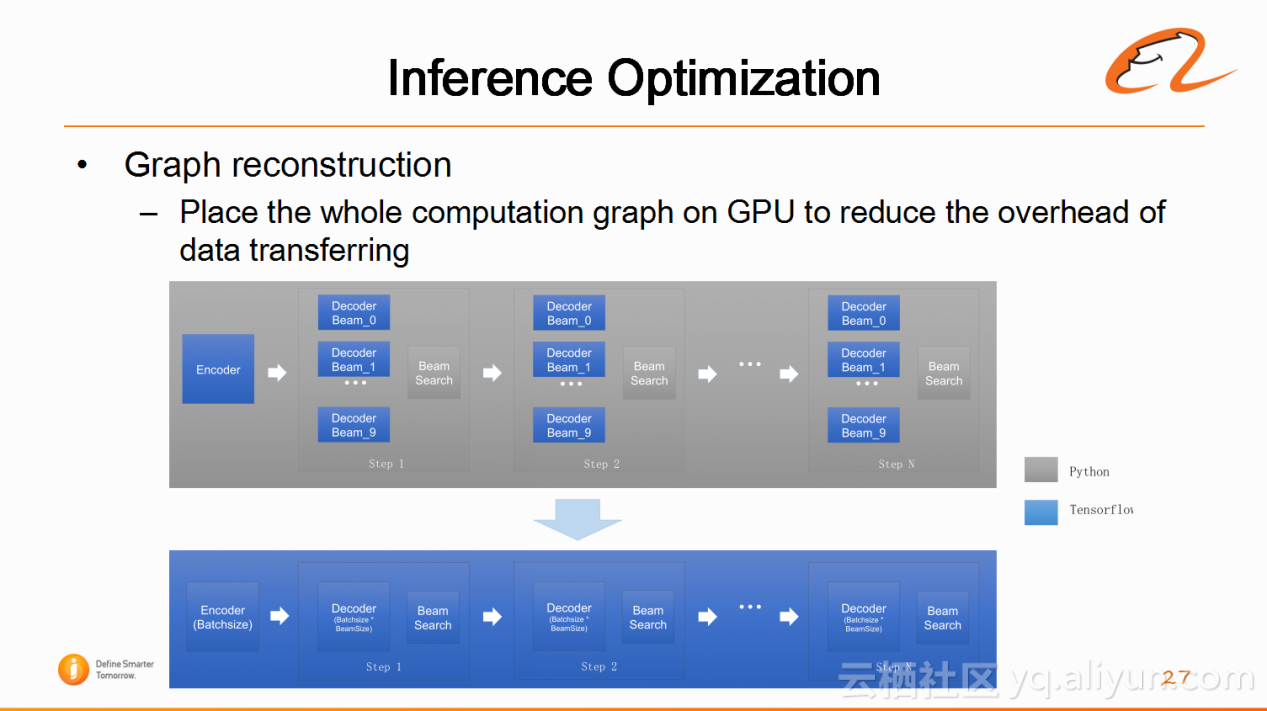
4)解码速度优化(Inference Optimization)
阿里翻译的要求是达到(20-30词语的句子)百毫秒级别,则目前很多开源平台可能需要1到2秒的时间。与Google类似,因为阿里翻译使用的是TensorFlow,有Python代码和TensorFlow代码,前者计算在CPU中,后者在GPU中计算,阿里的策略比较简单粗暴,是将代码全部在GPU中进行计算,虽然降低了GPU使用效率,但是提高了解码速度。
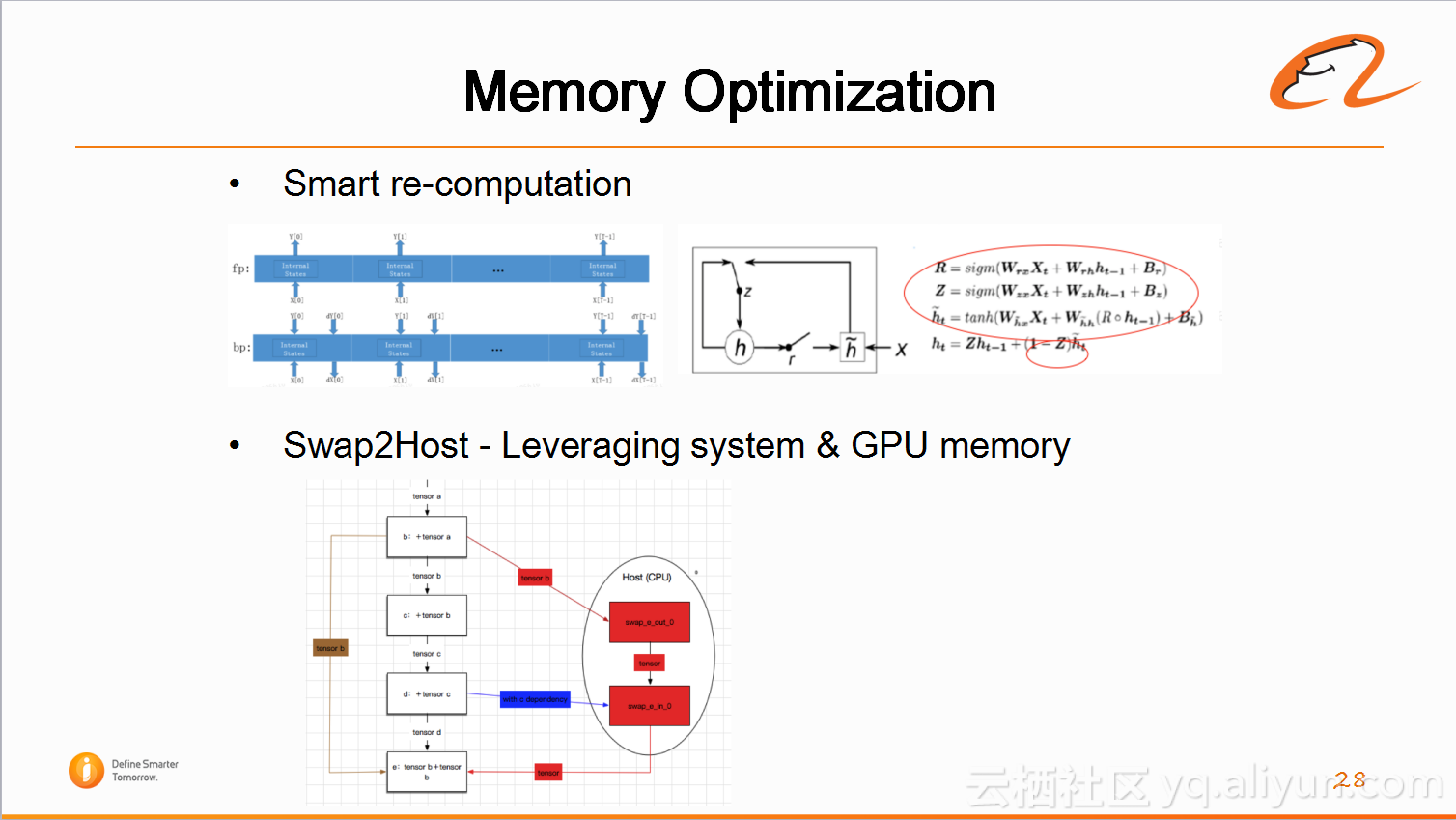
5)内存优化(Memory Optimization)
还有一些内存优化工作,主要是工程方面的策略。
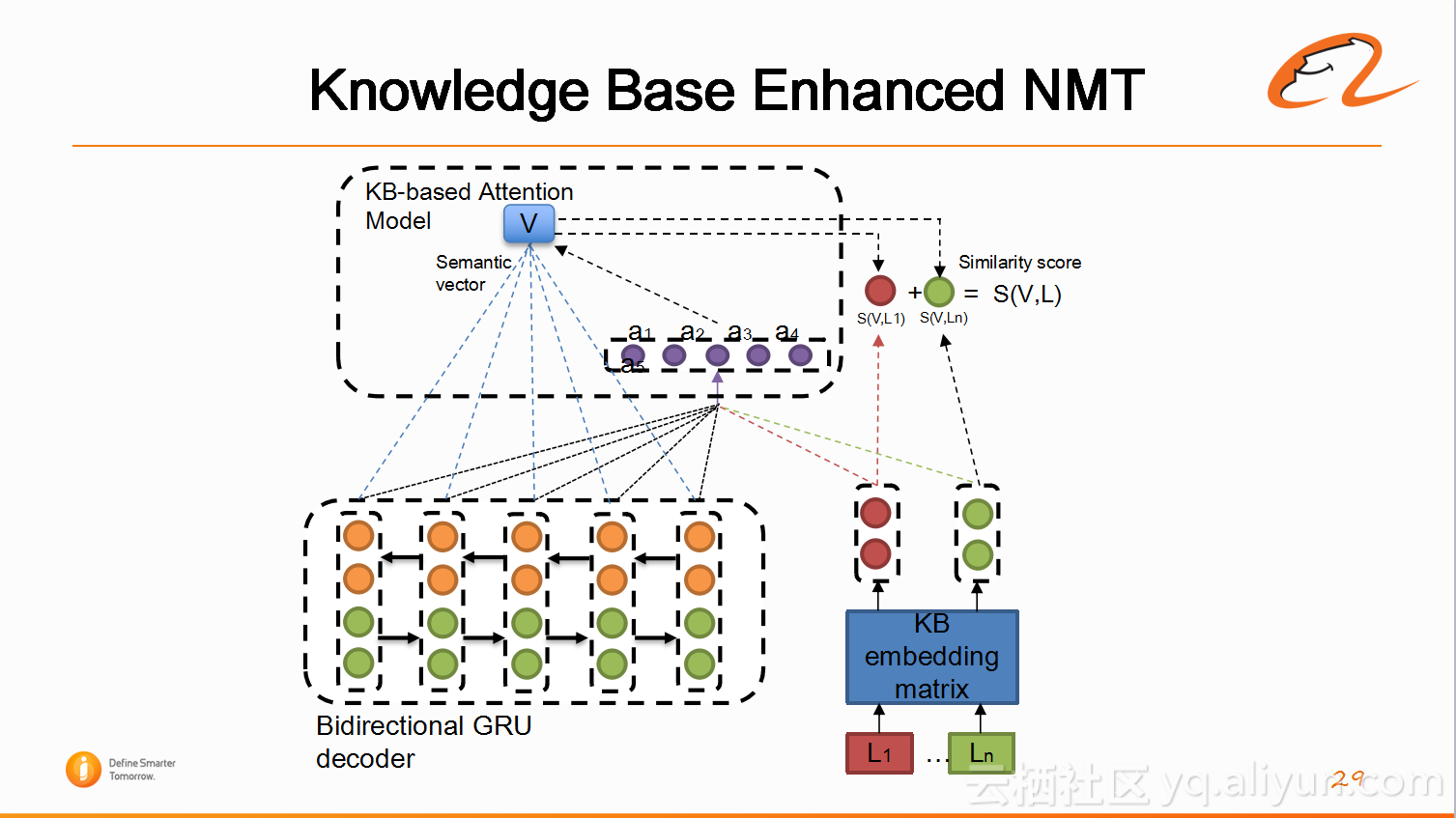
6)知识库接口(Knowledge Base Enhanced NMT)
另外,前面提高利用知识库进行翻译,所以在系统中给知识库留了一个接口。因为知识库还在建设当中,目前主要用到的是术语表和双语词典等信息。这项工作是跟中科院的自动化研究团队合作的项目,如果后续有进一步的改进,会通过下面的结果加入到系统中。
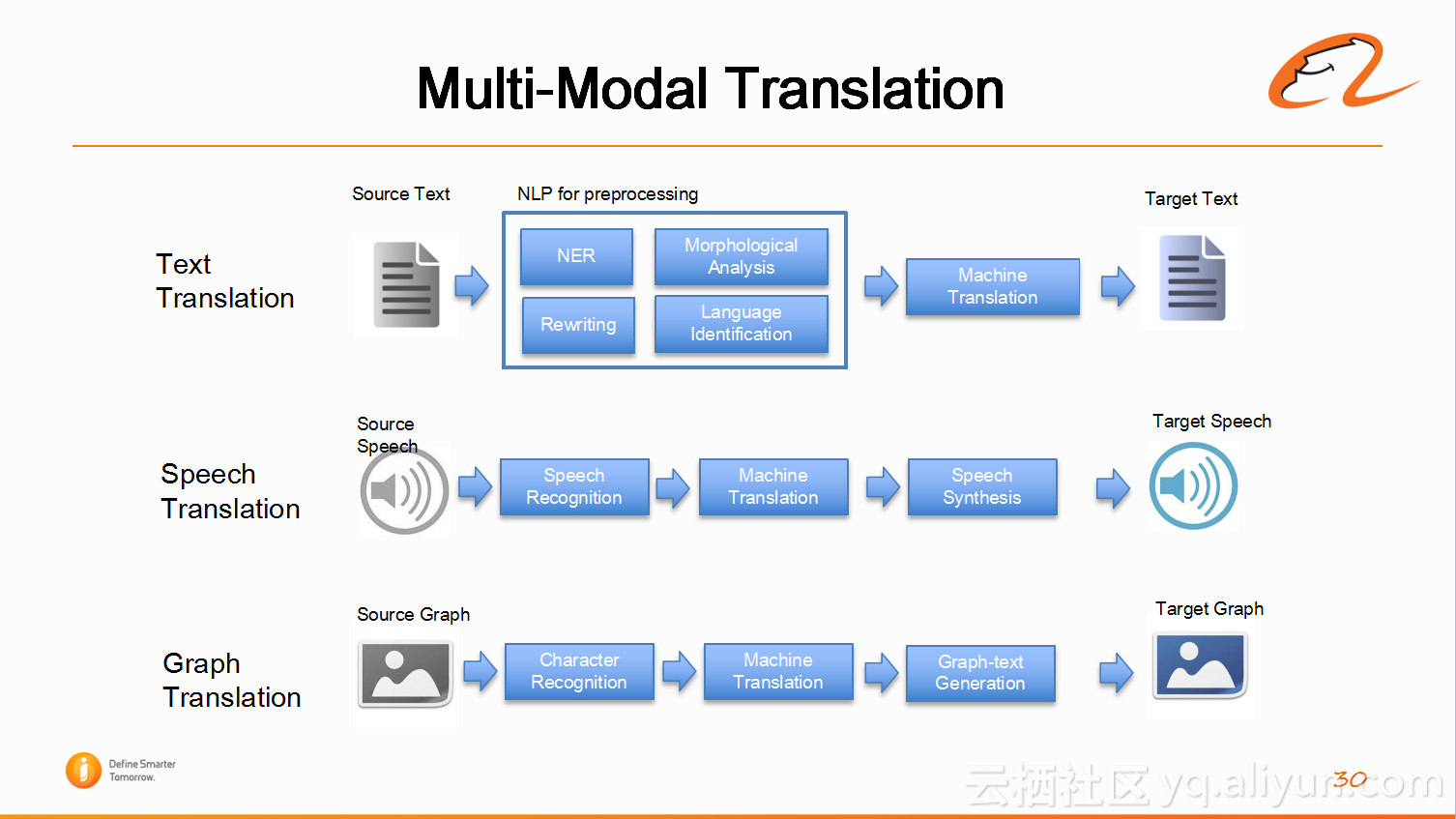
7)多模态的机器翻译(Multi-Modal Translation)
然后,阿里翻译也做了多模态的机器翻译,当然现在主要的需求还是文本的翻译。在2018年的CES会议上阿里翻译展示了语音翻译的demo,在不久的将来,会推出阿里语音翻译系统。目前正在做基于图片的翻译,需要与内部的其他团队进行合作。
五、总结
当然,机器翻译还远远不够完美,还无法达到人类专业译员的水平。一个技术不够完美是否可以使用?需要视场景而定,可能还不可以应用到正式的法律文书的翻译。但是跨境电商领域是一个非常好的场景,可能人们在浏览商品信息时,对某些信息不是那么在意,用户可以容忍。使用机器翻译为跨境电商提供有效服务,可以帮助阿里带来不少的价值。第二点,跨境电商场景下,机器翻译依然存在特定的困难,需要进一步的研究探索。第三点,基于规则的机器翻译,统计机器翻译和神经网络机器翻译在不同场景下各有各的优势。最后,质量,灵活性和稳定性等关键因素都是需要考虑的因素。
本文由云栖志愿小组董黎明整理,编辑程弢