本来一篇文章就该搞定的。结果要分上下篇了。主要是最近颈椎很不舒服。同时还在做秒杀的需求也挺忙的。 现在不能久坐。看代码的时间变少了。然后还买了两本治疗颈椎的书。在学着,不过感觉没啥用。突然心里好害怕。如果颈椎病越来越重。以后的路怎么走。
现在上下班有跑步,然后坐一个小时就起来活动活动。然后在跟着同时们一起去打羽毛球吧。也快30的人了。现在发觉身体才是真的。其他都没什么意思。兄弟们也得注意~~
废话不多说。下面介绍下netio。
netio在系统中主要是一个分包的作用。netio本事没有任何的业务处理。拿到包以后进行简单的处理。再根据请求的命令字发送到对应的业务处理进程去。
一、多进程下的socket epoll以及“惊群现象”
2.1 多进程下
是监听socket的方式
1)比如我们想创建三个进程同时处理一个端口下到来的请求。
2)父进程先创建socket。然后再listen。注意这个时候父进程frok。 2个进程出来。加上父进程就是3个进程
3)每个进程单独创建字节epoll_create和epoll_wait. 并把socket放到epoll_wait里
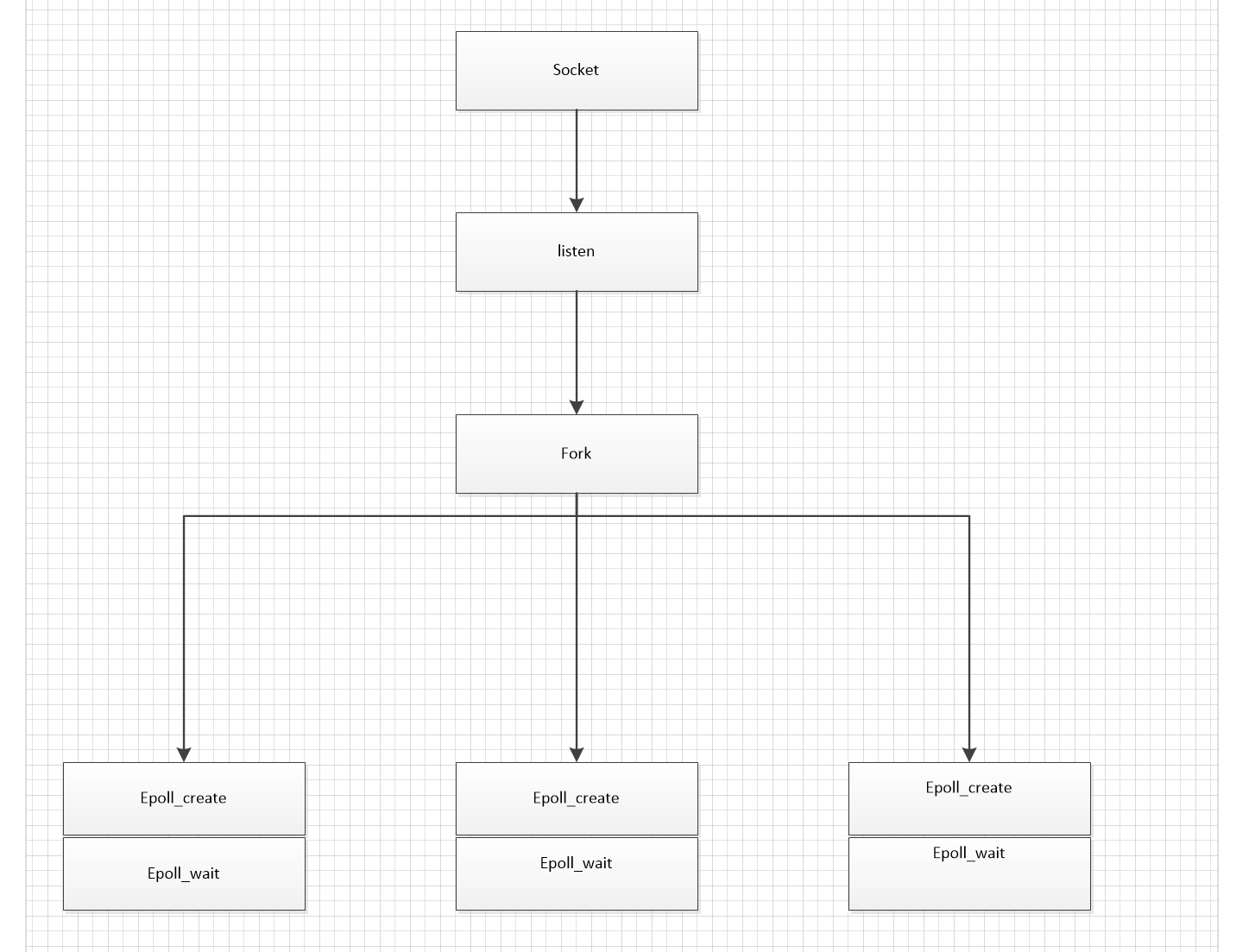
以上是平台多进程下监听同一个端口的方式。我们下面探究下为什么要这么做
2.1.1、为什么要fork出来的子进程来继承父进程的socket。而不是多个进程绑定同一个端口?
2.1.2 、为什么不能使用SO_REUSEADDR来是多个进程监听同一个端口?
首先我们来看下SO_REUSEADDR的用途
服务端重启的时候会进入到TIME_WAIT的状态。这个时候我们在bind的端口会失败的。但是我们不可能等TIME_WAIT状态过去在重启服务 因为TIME_WAIT可能会在一分钟以上。这个时候我们设置为SO_REUSEADDR就是使得
端口处在TIME_WAIT时候,可以复用监听。
注意SO_REUSEADDR只是在TIME_WAIT 重启服务的时候有用。如果你是多个进程要bind同一个端口。且IP相同。那么即使你设置了SO_REUSEADDR也会失败
因为SO_REUSEADDR允许在同一端口上启动同一服务器的多个实例,只要每个实例捆绑一个不同的本地IP地址即可。对于TCP,我们根本不可能启动捆绑相同IP地址和相同端口号的多个服务器。
2.1.3、TIME_WAIT的作用。为什么要TIME_WAIT的?
因为TCP实现必须可靠地终止连接的两个方向(全双工关闭),
一方必须进入 TIME_WAIT 状态,因为可能面临重发最终ACK的情形。
否则的会发送RST
2.1.4、多进行下实现监听同一个端口的原因
因为创建子进程的时候,复制了一份socket资源给子进程。其实可以这么理解。其实只有父进程一个socket绑定了端口。其他子进程只是使用的是复制的socket资源
2.1.5、epoll放到fork之后会怎么样?
netio起5个进程
james 2356 1 0 08:22 pts/0 00:00:00 ./netio netio_config.xml james 2357 2356 0 08:22 pts/0 00:00:00 ./netio netio_config.xml james 2358 2356 0 08:22 pts/0 00:00:00 ./netio netio_config.xml james 2359 2356 0 08:22 pts/0 00:00:00 ./netio netio_config.xml james 2360 2356 0 08:22 pts/0 00:00:00 ./netio netio_config.xml
我们先做几个实验然后再具体分析
a)实验一
正常请求。我们慢慢的按顺序发送十个请求。每个请求都是新的请求。
我们看下netio处理的进程pid 发现每次都是2358
开始我以为会这五个请求来竞争来取socket接收到的请求化。那么每次处理的请求的子进程应该不一样才对。但是每次都是同一个请求

after epoll_wait pid:2358 after epoll_wait pid:2358 after epoll_wait pid:2358 after epoll_wait pid:2358 after epoll_wait pid:2358 after epoll_wait pid:2358 after epoll_wait pid:2358 after epoll_wait pid:2358 after epoll_wait pid:2358 after epoll_wait pid:2358
b)实验二
我们先并发2个请求。看服务处理进程pid还是2358
after epoll_wait pid:2358 after epoll_wait pid:2358
这个时候我们客户端fork8个进程并发请求服务。发现2357和2358开始交替处理
after epoll_wait pid:2358 after epoll_wait pid:2358 after epoll_wait pid:2357 after epoll_wait pid:2358 after epoll_wait pid:2357 after epoll_wait pid:2358 after epoll_wait pid:2357 after epoll_wait pid:2358
c)实验三
我们在epoll_wait后面.recv之前 加上sleep(100000)
然后发送一个请求。发现每个进程被唤醒以后 但是因为sleep阻塞了。 然后会接着唤醒别的进程来处理。每次唤醒都会被阻塞。一直到5个进程全部被阻塞
after epoll_wait pid:2358 after epoll_wait pid:2357 after epoll_wait pid:2359 after epoll_wait pid:2356 after epoll_wait pid:2360
d)实验四
我们在epoll_wait后面recv 后面 加上是sleep(100000)
然后发送一个请求。发现有一个进程recv处理完以后。sleep住。其他进程并没有被唤醒。
|
1
|
after epoll_wait pid:2358
|
当我们并发两个请求的时候。发现唤醒了两个进程
after epoll_wait pid:2357 after epoll_wait pid:2359
四个实验已经做完现在我们来具体分析下原因
1)实验一中为什么 每次只有一个进程来处理。
首先我们三个进程都epoll_wait同一个fd。按理来说这个时候其实应该唤醒三个进程都来处理的。但是每次都只有一个进程来处理。如果是进程竞争处理的话。别的子进程应该也有机会来处理的。但是没有。这就是我们所谓的“惊群”现象。但是并没有发生。
查了下资料发现。内核采用的不是竞争。而是分配策略。在有多个子进程epoll_wait 同一个fd的时候。会选择一个子进程来处理这个消息。 并不会唤醒其他子进程。
2)实验二中 并发增大的时候 为什么会开始有多个子进程来处理。
其实这里做的很有意思。内核轮流唤醒监听fd的子进程。如果子进程很快处理完。那么就一直让这个子进程来处理fd.但是如果子进程处理不完。速度没那么快。会接着唤醒别的子进程来处理这个fd.
即fd事件到达的时候。内核会先去看下A进程是否繁忙。如果不繁忙 。则让这个A进程一直处理。如果发现A进程繁忙中。会去查看进程B是否繁忙。如果不繁忙则B处理 后面的子进程以此类推
所以我们看到 并发请求增大的时候 开始有多个子进程来处理了
3)实验三、5个进程为什么都被唤醒了?
其实就是上面说的。被sleep住了。我们认为进程就是繁忙状态中。会依次通知其他进程来处理。
4)实验四 为什么只有一个进程被唤醒处理
我们在sleep放在recv之后。发现只有一个进程被唤醒。 我们可以任务进程已经接受并处理了任务。所有不需要再通知其他进程了
这里我们小结下:
epoll放在fork之后这种方式不会引起惊群现象。 会轮询选择其中一个子进程来处理。如果子进程来不及处理。则会通知另外一个子进程来处理。
但是以上结论是做实验和查资料得来的。并没有看内核源码。所有如果有看过内核源码的同学。希望能指点下。
2.1.6、epoll放到fork之前会怎么样?
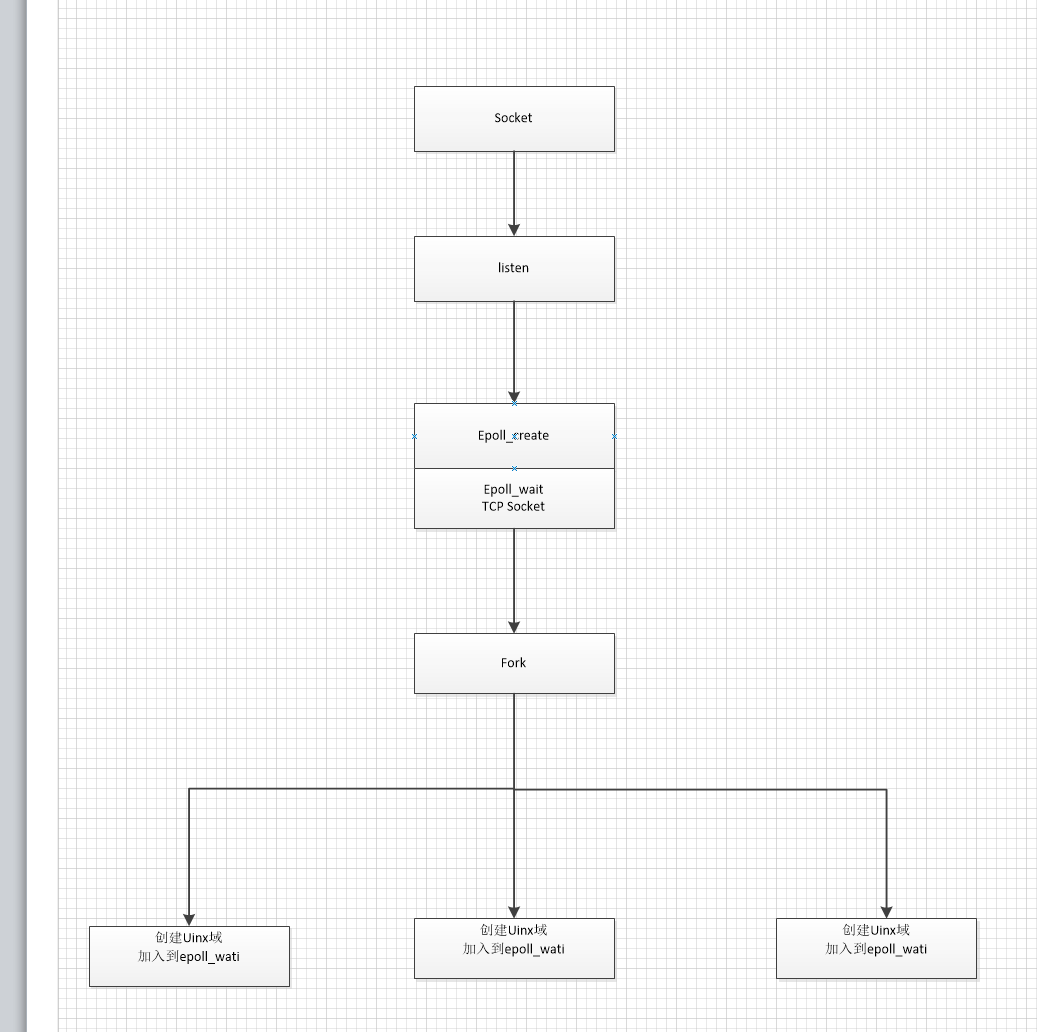
把epoll放到fork 之前。当发送一个请求的时候 发现也是只唤醒了一个进程来处理。
这里其实跟epoll放到fork之后是一样的。
但这里有个很蛋痛的地方 。
我们系统用到了unix域来做消息通知。当container处理完消息。会发送uinx域来通知neito来处理回包。
但是回包的时候。不知道为什么 5个进程都被唤醒了来被处理。最后有三个进程被主动结束了。
下面是我自己的理解
a)
首先
是进程id为
6000
的netio处理的数据。
当container回包实际数据只会通知
f000_6000的uinx域中
如下图。有5个进程。就有5个uinx域

b)
但是由于多进程公用一个epoll。其他进程也被唤醒了。然后判断发现这个fd是uxin域的类型。
然后就会去不停的读取自己对应的unix域文件。
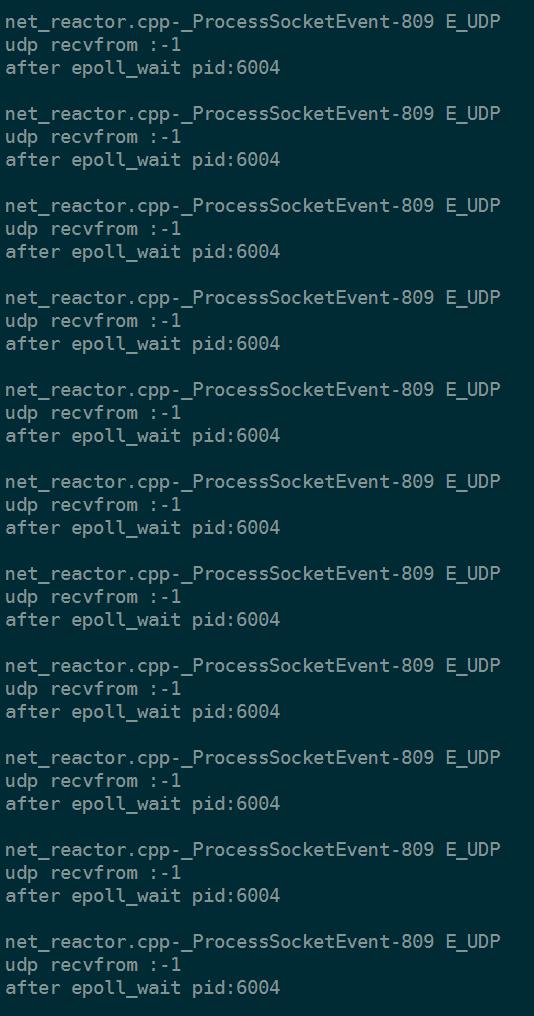
但是其实没有消息的。container只回到了
中所以其他进程一直recvfrom =-1
f000_6000
而且由于正在处理
的进程不够及时。这个消息没处理。epoll的特性是会一直通知进程来处理。所以其他进程会一直读自己的unix域。然后就一直recvfrom =-1
f000_6000
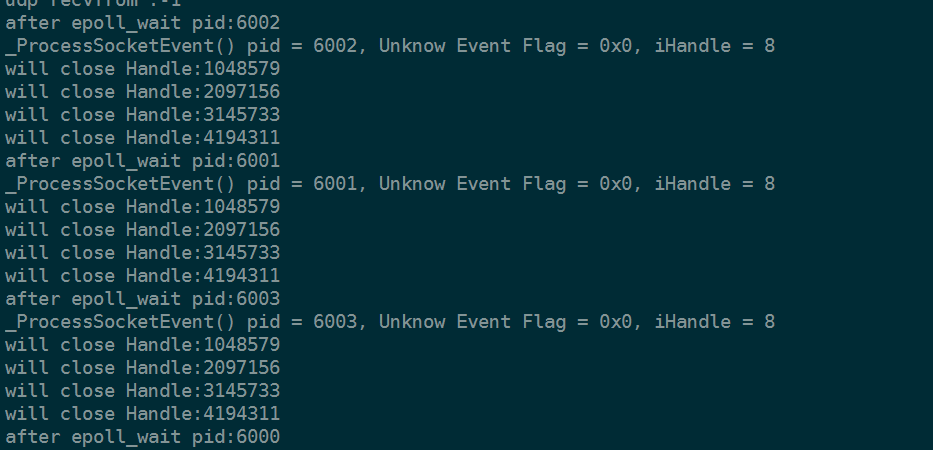
如下图。没贴全。除了进程6000其他进程打印了一堆这样的信息
c)
最后我们读进程6000从的uinx域中读到数据后。
其他进程刚好这个时候拿到fd是被处理过的。这个时候再来处理这个fd就是未定义的。
而我们对未定义的fd会直接stop进程。所以最后三个进程被主动关闭了
这里我们小结一下
因为没有看内核代码 所有对这种情况只有靠实验和猜了。。。。。跪求大神指导
1、首先针对TCP端口内核应该是做了特殊处理。所以epoll在fork前还是后。如果处理及时。应该都是只有一个进程被唤醒。来处理。处理不及时会依次唤醒别的进程。并不会造成惊群现象(就是那种临界资源多个进程来抢这个包。最后只有一个进程能抢到包。但是做实验发现好像并不是竞争的关系)
2、但是针对unix域的fd。公用一个epoll没有特殊处理。
就会造成惊群现象。并且多个进程都能拿到这个fd来处理。
二、netio之定时器
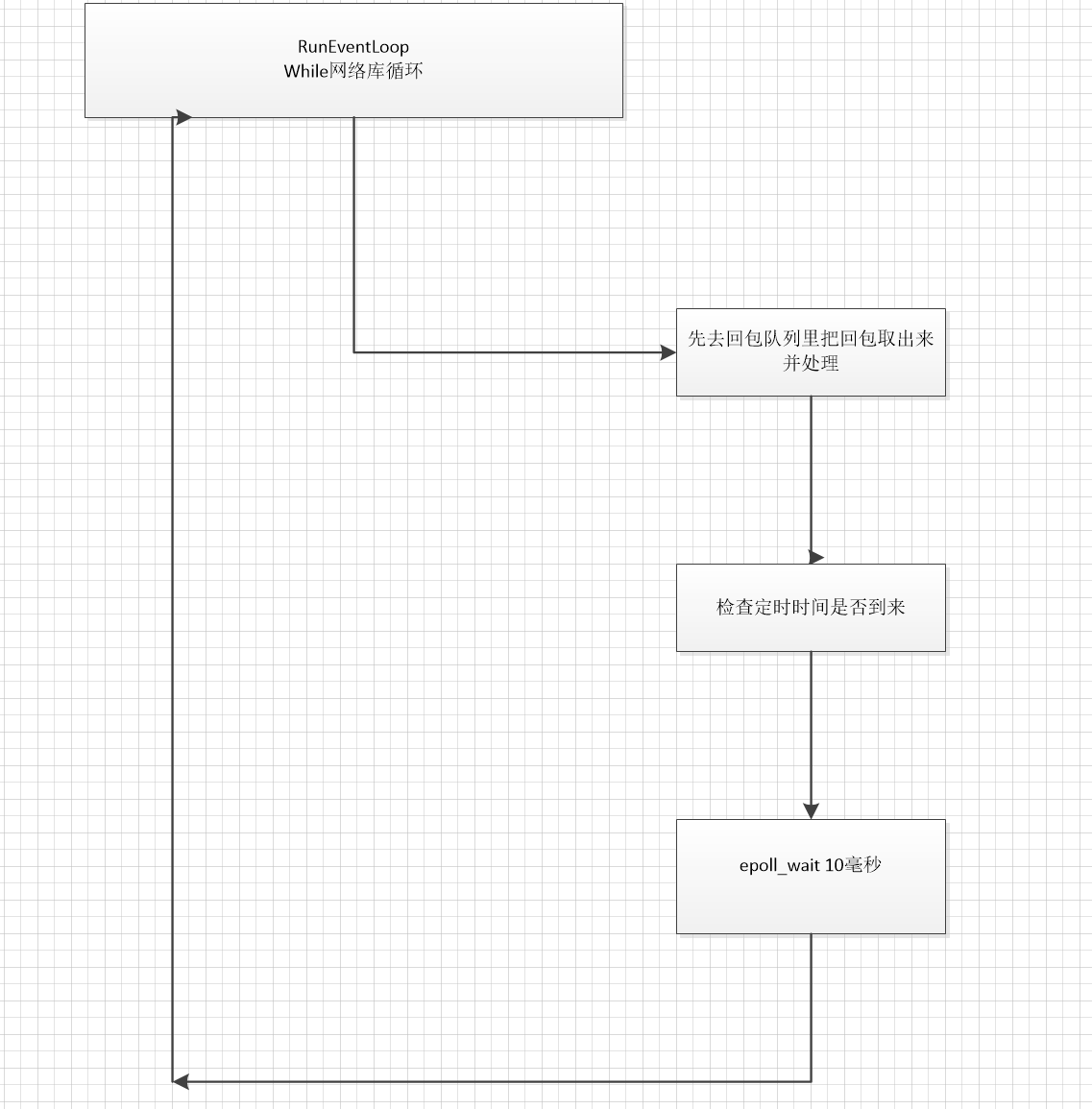
先看下图。netio定时器所处在的位置。
由于epoll_wait了10毫秒。无论是否有请求触发。
每隔10毫秒都会轮询一次。这样可以防止当container通知netio的时候。消息丢失而导致netio不能处理的情况
定时器是一个比较重要的概念。每个服务进程都会有个定时器来处理定时任务。这里介绍下netio的定时器. 这里检查定时时间事件做两件事。一个是找出已经到达的时间事件。并执行子类的具体处理函数。第二个是给自动时间事件续期。
netio初始化的时候。会注册一个60秒的循环时间事件。即每60秒会执行一次时间事件。这个时间事件有以下几个动作。1)清除超时的socket 2)查询本地命令字列表 3)定时输出netio的统计信息
3.1 定时器的数据结构
netio的定时器数据结构是最小堆。即最近的定时任务是在最小堆上
a)申请了65个大小的二维数组
const uint32_t DEFAULT_QUEUE_LEN = 1 + 64; m_pNodeHeap = new CNode*[DEFAULT_QUEUE_LEN];
这里为什么申请1+64.其实只有64个可用。
其中的一个指针是用来辅助最小堆算法的。
即m_pNodeHeap[0] = NULL; 是一直指向空的。
最小堆的最小值 是m_pNodeHeap【1】.
b) CNode成员变量的意义
struct CNode
{
CNode(ITimerHandler *pTimerHandler = NULL, int iTimerID = 0)
: m_pTimerHandler(pTimerHandler)
, m_iTimerID(iTimerID)
, m_dwCount(0)
, bEnable(true)
{ }
ITimerHandler *m_pTimerHandler;
int m_iTimerID;
CTimeValue m_tvExpired; // TimeValue for first check
CTimeValue m_tvInterval; // Time check interval
unsigned int m_dwCount; // Counter for auto re-schedule
bool bEnable;
};
m_pTimerHandler 主要是用来保存父类指针。当时间事件触发的时候。通过父类指针找到继承类。来处理具体的 时间事件
m_tvExpired 记录过期时间。比如一个事件过期时间是10秒。那么m_tvExpired就是存的当前时间+10秒这个值。每次比较的时候。拿最小堆的的这个值跟当前时间比对。如果当前时间小于m_tvExpired说明 没有任何时间时间被触发。如果当前时间大于这个值。则认为需要处理时间事件
m_dwCount 这个是用来设置自动过期时间的次数。比如我们有一个时间事件。我们希望它执行三次。每次的间隔以为1分钟。那么这个值设置为3. 当第一次到达时间时间的时候。我们发现这个值大于0.则对m_tvExpired赋值当前时间+1分钟 重新进入最小堆。然后m_dwCount减一。
下次依然是这样处理。直到m_dwCount这个值到0.我们就认为不需要再自动给这个时间设置定时任务。
bEnable 这个值是用来判断这个事件事件是否还有效。这里的做法很有意思。当一个时间事件执行完。或者不需要的时候。我们先是帮它设置为false.等下次check时间最堆的时候。如果发现这个时间事件是无效的。这个时候在delete
m_tvInterval 这个是时间事件的间隔时间。比如我的时间事件是每10秒执行一次。则这个值就设置为10秒
m_iTimerID 这个是时间事件的唯一ID
这个值是自增的。每来一个新时间事件。m_iTimerID都会+1. 因为初始化的时候。这个值为1了。所以最开始的时间事件m_iTimerID的值为2
3.2 定时清理无效连接
a)首先如果有客户端connet进来。
netio会把这个connet的fd保存下来 还有到来的时间。
m_mapTcpHandle[iTcpHandle] = (int)time(NULL);
b ) 每次接受到数据 都会更新这个时间
c ) netio有个配置文件。 我们一般是设置为10秒。每次检查定时事件的时候。都会去检查m_mapTcpHandle。
用当前时间 跟 m_mapTcpHandle里面保存的时间比较。当发现超过10秒的时候
我们认为这个连接时无效的。然后会把这个fd关闭。并删除
d
) 所以如果 要保持长连接的话。 需要客户端不停的发送心跳包。来更新这个时间
3.3 定时统计netio的统计信息
这有个很有意思的地方。
在初始化的时候。我们已经注册了一个每60秒执行一次输出的netio状态的时间事件
前面我们说了m_dwCount这个值用来控制自动时间事件的次数。我们每一分钟会输出netio的状态信息。
这就是固定的时间事件。我们入参dwCount设置0.那么系统就认为你这个时间事件是需要无限循环的。
就设置了一个最大值 (unsigned int )-1。
这个值算出来是4294967295。
我们以每分钟一次来计算。差不多要8000多年才能把这个m_dwCount减为0~~~~~
if (dwCount > 0)
m_l_pNode->m_dwCount = dwCount;
else
m_l_pNode->m_dwCount = (unsigned int)-1;
当输出完状态信息后。会把netio的一些状态初始化为0.因为我们的状态输出是统计一分钟的状态。比如这一分钟的请求包个数。比率。丢包个数等。
3.4 定时请求命令字
这里还是比较重要的是。比如我们新加了一个服务。如果不重启netio是不知道的。但是我们会没隔一分钟去请求所有的命令字。 可以发现有心的服务加了进来。
三、netio 之日志分析
4.1、 netio_debug.log日志分析
下面分析下简单netio的日志。这里就大概介绍了 。不具体在介绍netio的值了 。 多看看就知道是什么意思的。
还是请求道container. container发现参数校验不对直接把包丢回给netio的回包队列
如下图
a)192.168.254.128:58638 当请求到来的时候会打印请求的IP和端口
b)Handle = 00700008 但是这个socket不是原生的。是经过处理的。
c)ConnNum = 1 当前有多个连接数
d) Timestamp = 1460881087 请求到了的时间戳

如下图
a) SendMsgq REQUEST START 这里是把内容丢到消息队列里
b) _NotifyNext REQUEST START 这里是通知container的uinx域。有消息丢到了你的消息队列里
c) OnRecvFrom REQUEST START 这里是接收到了container发来的uinx域 。告诉netio我已经处理完。丢到你的回包消息队列里去了。你赶紧去处理吧
d) OnEventFire request:0 从消息队列里拿到数据并开始处理。 回给客户端包
e)OnClose REQUEST START 客户端发送close socket信号。 服务端接收后。关闭socket

4.2 netio_perform.log 日志分析
以下都是一份钟的统计数据

PkgRecv 收到的包
PkgSent 发送出去的包
ErrPkgSent 错误的包。
PkgPushFail 这个暂时没用到
PkgSendFail 这个是netio 包发送的时候 。发不出去的个数
BytesRecv 收到的字节数
BytesSent 发送出去的字节数
MaxConn 最大连接数。这个值不是一份内的最大值。是从开始到输出统计是。最高的同时连接数据
TcpConnTimeout 因为超时。netio自动关闭的TCP连接。
Cmd[0x20630001] 是netio从回包队列中拿到。命令字
Count[15] 该命令字一分钟内总共拿到的回包总数
AverageTime[0] 每个包的平均处理时间。 这里是拿这15个包从netio-container-netio这期间的总时间 除以 15得到的平均时间 单位是毫秒
MaxTime[1] 这15个包中耗时最长的一个包。所耗时间
AverageRspLen[89] 平均每个包回给客户端的字节数
MaxRspLen[89] 最大的一个回包字节数
Ratio[100] 这里先会拿到一个一分钟内netio接受包的总个数 (这里指客户端来的请求包) 。然后用用0x20630001命令字的个数来除以总包数再乘以100。得到0x20630001在这一分钟内。所占处理包的比重。
后面接着的一串是 命令字0x20630001的分布在不同相应时间的个数
最后一天是正对一分钟所有命令字包的统计
最后:
1)对大型系统。统计日志很重要。可以时事了解系统的状态
2)一定要处理好多进程的关系
3)最后 一定要保护好身体。 身体才是根本啊~~~