
以下内容编译自Referring Relationships论文:
图像不仅仅是对象集合,每个图像都代表一个互相关联的关系网络。实体之间的关系具有语义意义,并能帮助观察者区分实体的实例。例如,在一张足球比赛的图像中,可能有多人在场,但每个人都参与着不同的关系:一个是踢球,另一个是守门。
在本文中,我们制定了利用这些“指称关系”来消除同一类别实体之间的歧义的任务。我们引入了一种迭代模型,它将指称关系中的两个实体进行定位,并相互制约。我们通过建模谓语来建立关系中实体之间的循环条件,这些谓语将实体连接起来,将注意力从一个实体转移到另一个实体。
我们证明了我们的模型不仅好于在三种数据集上实现的现有方法--- CLEVR,VRD 和 Visual Genome ---而且它还可以产生视觉上有意义的谓语变换,可以作为可解释神经网络的一个实例。最后,我们展示了将谓语建模为注意力转换,我们甚至可以在没有其类别的情况下进行定位实体,从而使模型找到完全看不见的类别。
指称关系任务
指称表达可以帮助我们在日常交流中识别和定位实体。比如,我们能够指出“踢球人”来区分“守门员”(图 1)。在这些例子中,我们都可以根据他们与其它实体的关系来区分这两人。 当一个人射门时,另一个人守门。 最终的目标是建立计算模型,以识别其他人所指的实体。
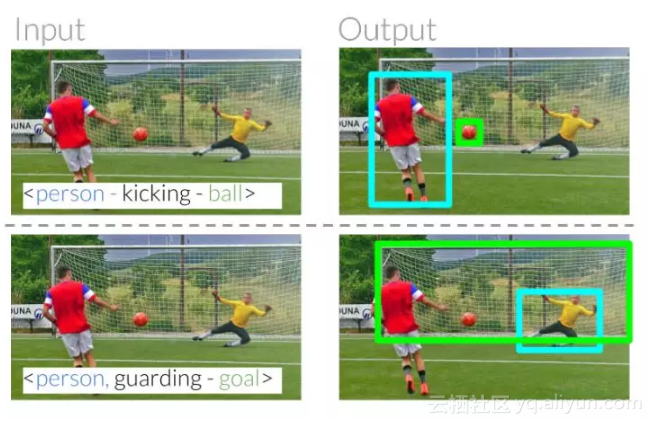
图1:指称关系通过使用实体间的相对关系来消除同一类别实例之间的歧义。给出这种关系之后,这项任务需要我们的模型通过理解谓语来正确识别图像中的踢球人。
指称关系任务的结构化关系输入允许我们评估如何明确地识别图像中同一类别的实体。我们在包含视觉关系的三个视觉数据集上评估我们的模型 2:CLEVR,VRD 和 Visual Genome 。这些数据集中 33%、60.3% 和 61% 的关系是指不明确的实体,也即指具有相同类别的多个实例的实体。我们扩展了模型,使用场景图的关系来执行注意力扫视。最后,我们证明,在没有主体或客体的情况下,我们的模型仍然可以在实体之间消除歧义,同时也可以定位以前从未见过的新类别。
指称关系模型
我们的目标是通过对指称关系的实体进行定位,从而使用输入的指称关系来消除图像中的实体歧义。 形式上而言,输入是具有指称关系的图像 I,R = <S - P - O>,它们分别是主体,谓语和对象类别。 预计这个模型可以定位主体和客体。
模型设计
我们设计了一个迭代模型,学习如何在视觉关系中使用谓语来操作注意力转移,这受到了心理学中移动聚光理论的启发。给出足球的初始估值后,它会学习踢球的人必须在哪里。同样,如果对人进行估值,它将会学习确定球的位置。通过在这些估值之间进行迭代,我们的模型能够专注于正确实例,并排除其它实例。
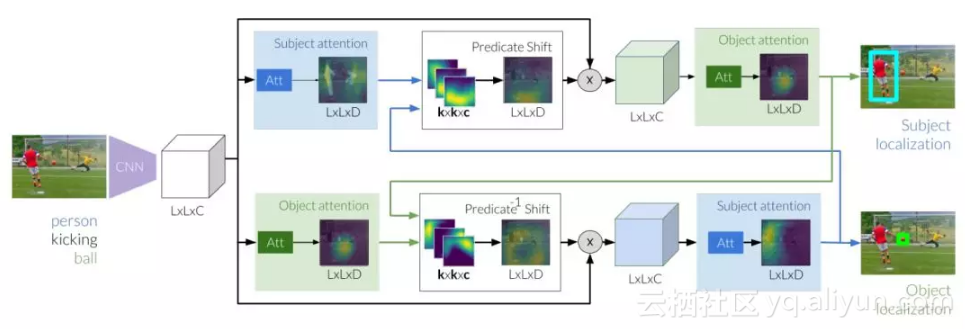
图 2:指称关系的推理首先要提取图像特征,这是用于生成主体和客体的基础。接下来,这些估值可以用来执行转换注意力,注意力使用了从主体到我们所期望客体位置的谓语。在对客体的新估值进行细化的同时,我们通过关注转换区域来修改图像特征。同时,我们研究了从初始客体到主体的反向移位。通过两个预测移位模块迭代地在主体和对象之间传递消息,可以最终定位这两个实体。
实验
我们在跨三个数据集的指称关系中评估模型性能来进行实验操作,其中每个数据集提供了一组独特的特征来补充我们的实验。 接下来,我们评估在输入指称关系中缺少其中一个实体的情况下如何改进模型。 最后,通过展示模型如何模块化并用于场景图注意力扫视来结束实验。
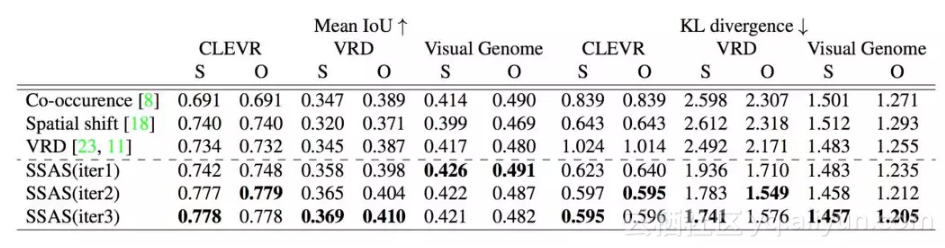
以下是我们在 CLEVR、VRD 和 Visual Genome 上的评估结果。 我们分别标出了对主题和对象定位的 Mean IoU 和 KL 分歧:
在三种测试条件下缺少实体的指称关系结果:
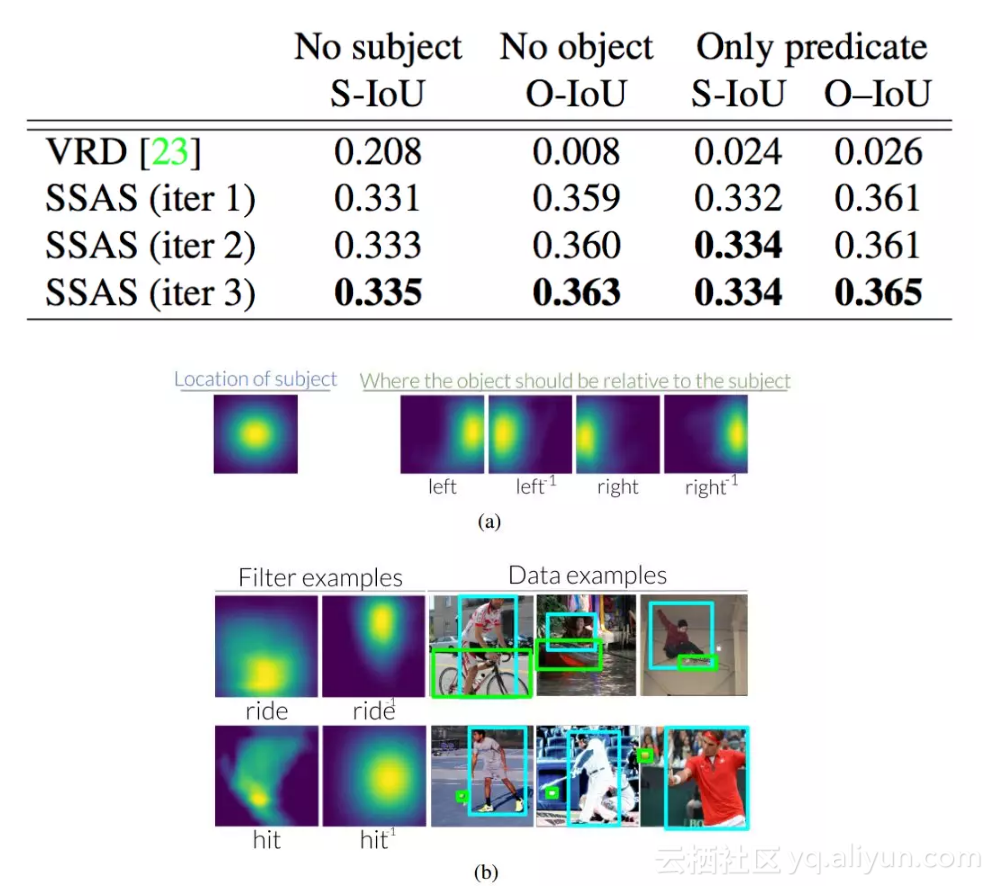
图 3:(a)相对于图像中的主体,当使用<subject - left - of object>关系来查找客体时,左边的谓语会把注意力转移到右边。相反,当使用物体找到主体时,左侧的逆谓语会将注意力转移到左侧。在辅助材料中,我们可视化了 70 个 VRD、6 个 CLEVR 和 70 个 Visual Genome 的谓语和逆谓语转化(b)我们还看到,在查看用于了解它们的数据集时,这些转换是直观的。
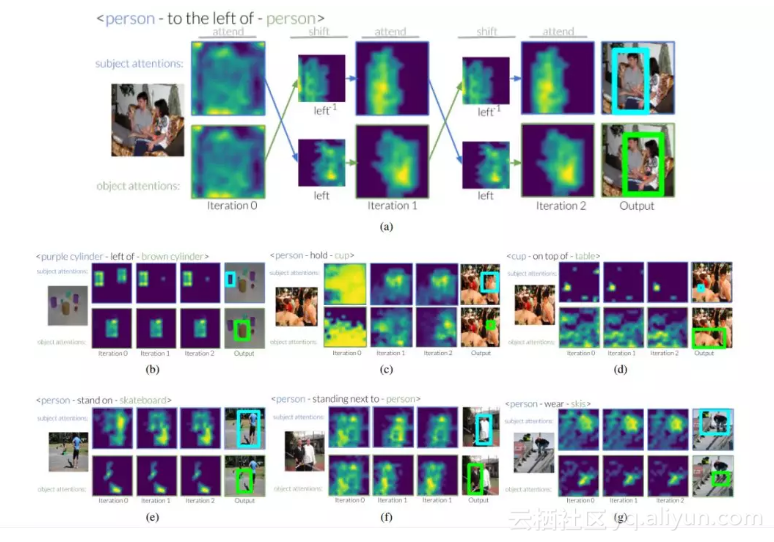
图 4:这是 CLEVR 和 Visual Genome 数据集的注意力转移如何跨越多次迭代的示例。在第一次迭代时,模型仅接收试图找到以及尝试定位这些类别中所有实例的实体信息。在后面的迭代中,我们看到谓语转换注意力,这可以让我们的模型消除相同类别的不同实例之间的歧义。
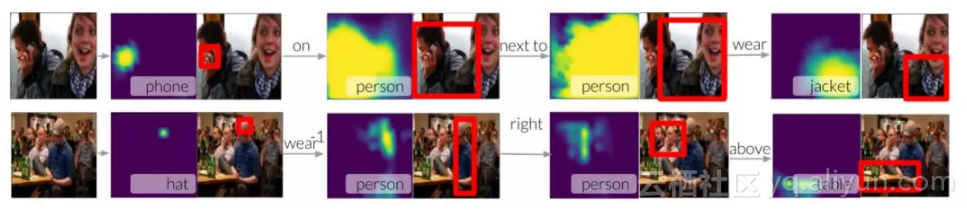
图 5:我们可以将我们的模型分解成其注意力和转换模块,并将它们堆叠起来作为场景图的节点。 在这里,我们演示了如何使用模型从一个节点(手机)开始,并使用指称关系来通过场景图连接节点,并在短语<拿电话的人旁边有人身穿夹克>中定位实体。 第二个例子是关于<在戴帽子的人的右边有个人一张桌子前>中的实体。
结论
我们介绍了指称关系的目的,其中我们的模型利用视觉关系来消除了同一类别实例之间的歧义。我们的模型学习去迭代地使用谓语作为一种关系里,两个实体之间的注意力转换。它通过分别对主体和客体的先前位置进行预测,来更新其关于主体和客体的位置信息。我们展示了 CLEVR,VRD 和 Visual Genome 数据集的改进,证明了我们的模型产生了可解释的谓语转换,使我们能够验证模型实际上是在学习转移注意力。通过依赖部分指称关系以及如何将其扩展到场景图上执行注意力扫视,我们甚至展示了如何使用我们的模型来定位完全看不见的类别。指称关系的改进可能为视觉算法探测未见的实体铺路,并学习如何增强对视觉世界的理解。
原文发布时间为:2018-04-9
本文作者:费棋


