1.YARN的基础架构是什么?
2.哪一进程防止Yarn早就web攻击?
3.Zookeeper主进程是哪个?
4.如何下载cdh包?
 本文搭建Hadoop CDH5.0.1 分布式系统,包括NameNode ,ResourceManger HA,忽略了Web Application Proxy 和Job HistoryServer。
一概述
(一)HDFS
本文搭建Hadoop CDH5.0.1 分布式系统,包括NameNode ,ResourceManger HA,忽略了Web Application Proxy 和Job HistoryServer。
一概述
(一)HDFS
1)基础架构
(1)NameNode(Master)
- 命名空间管理:命名空间支持对HDFS中的目录、文件和块做类似文件系统的创建、修改、删除、列表文件和目录等基本操作。
- 块存储管理
(2)DataNode(Slaver)
namenode和client的指令进行存储或者检索block,并且周期性的向namenode节点报告它存了哪些文件的block
2)HA架构
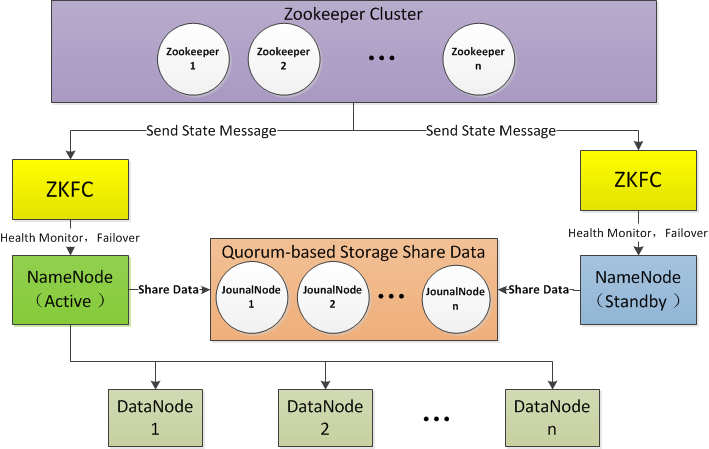
使用Active NameNode,Standby NameNode 两个结点解决单点问题,两个结点通过JounalNode共享状态,通过ZKFC 选举Active ,监控状态,自动备援。
(1)Active NameNode:
接受client的RPC请求并处理,同时写自己的Editlog和共享存储上的Editlog,接收DataNode的Block report, block location updates和heartbeat;
(2)Standby NameNode:
同样会接到来自DataNode的Block report, block location updates和heartbeat,同时会从共享存储的Editlog上读取并执行这些log操作,使得自己的NameNode中的元数据(Namespcae information + Block locations map)都是和Active NameNode中的元数据是同步的。所以说Standby模式的NameNode是一个热备(Hot Standby NameNode),一旦切换成Active模式,马上就可以提供NameNode服务
(3)JounalNode:
用于Active NameNode , Standby NameNode 同步数据,本身由一组JounnalNode结点组成,该组结点基数个,支持Paxos协议,保证高可用,是CDH5唯一支持的共享方式(相对于CDH4 促在NFS共享方式)
(4)ZKFC:
监控NameNode进程,自动备援。
(二)YARN
1)基础架构
(1)ResourceManager(RM)
接收客户端任务请求,接收和监控NodeManager(NM)的资源情况汇报,负责资源的分配与调度,启动和监控ApplicationMaster(AM)。
(2)NodeManager
节点上的资源管理,启动Container运行task计算,上报资源、container情况给RM和任务处理情况给AM。
(3)ApplicationMaster
单个Application(Job)的task管理和调度,向RM进行资源的申请,向NM发出launch Container指令,接收NM的task处理状态信息。NodeManager
(4)Web Application Proxy
用于防止Yarn遭受Web攻击,本身是ResourceManager的一部分,可通过配置独立进程。ResourceManager Web的访问基于守信用户,当Application Master运行于一个非受信用户,其提供给ResourceManager的可能是非受信连接,Web Application Proxy可以阻止这种连接提供给RM。
(5)Job History Server
NodeManager在启动的时候会初始化LogAggregationService服务, 该服务会在把本机执行的container log (在container结束的时候)收集并存放到hdfs指定的目录下. ApplicationMaster会把jobhistory信息写到hdfs的jobhistory临时目录下, 并在结束的时候把jobhisoty移动到最终目录, 这样就同时支持了job的recovery.History会启动web和RPC服务, 用户可以通过网页或RPC方式获取作业的信息
2)HA架构
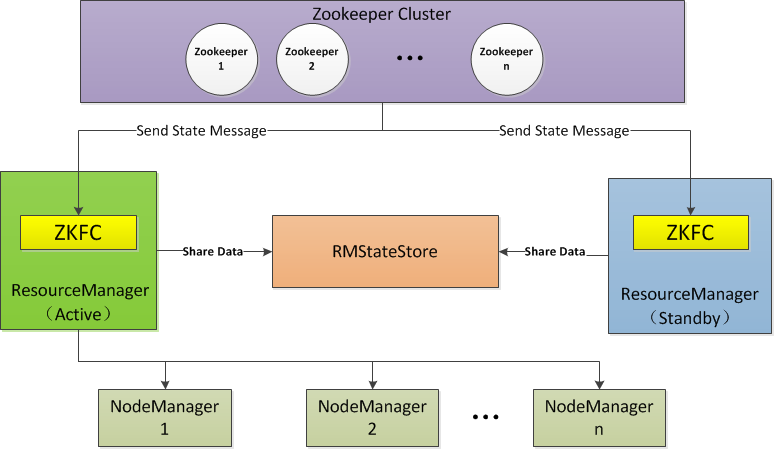 ResourceManager HA 由一对Active,Standby结点构成,通过RMStateStore存储内部数据和主要应用的数据及标记。目前支持的可替代的RMStateStore实现有:基于内存的MemoryRMStateStore,基于文件系统的FileSystemRMStateStore,及基于zookeeper的ZKRMStateStore。
ResourceManager HA的架构模式同NameNode HA的架构模式基本一致,数据共享由RMStateStore,而ZKFC成为 ResourceManager进程的一个服务,非独立存在。
二 规划
ResourceManager HA 由一对Active,Standby结点构成,通过RMStateStore存储内部数据和主要应用的数据及标记。目前支持的可替代的RMStateStore实现有:基于内存的MemoryRMStateStore,基于文件系统的FileSystemRMStateStore,及基于zookeeper的ZKRMStateStore。
ResourceManager HA的架构模式同NameNode HA的架构模式基本一致,数据共享由RMStateStore,而ZKFC成为 ResourceManager进程的一个服务,非独立存在。
二 规划
(一)版本
|
组件名
|
|
|
|
JRE
|
java version "1.7.0_60"
Java(TM) SE Runtime Environment (build 1.7.0_60-b19)
Java HotSpot(TM) Client VM (build 24.60-b09, mixed mode)
|
|
|
Hadoop
|
hadoop-2.3.0-cdh5.0.1.tar.gz
|
|
|
Zookeeper
|
zookeeper-3.4.5-cdh5.0.1.tar.gz
|
|
(二)主机规划
|
IP
|
|
|
|
|
8.8.8.11
|
|
|
NameNode
DFSZKFailoverController
ResourceManager
|
|
8.8.8.12
|
|
|
NameNode
DFSZKFailoverController
ResourceManager
|
|
8.8.8.13
|
Hadoop-DN-01
Zookeeper-01
|
DataNode
NodeManager
Zookeeper
|
DataNode
NodeManager
JournalNode
QuorumPeerMain
|
|
8.8.8.14
|
Hadoop-DN-02
Zookeeper-02
|
DataNode
NodeManager
Zookeeper
|
DataNode
NodeManager
JournalNode
QuorumPeerMain
|
|
8.8.8.15
|
Hadoop-DN-03
Zookeeper-03
|
DataNode
NodeManager
Zookeeper
|
DataNode
NodeManager
JournalNode
QuorumPeerMain
|
各个进程解释:
- NameNode
- ResourceManager
- DFSZKFC:DFS Zookeeper Failover Controller 激活Standby NameNode
- DataNode
- NodeManager
- JournalNode:NameNode共享editlog结点服务(如果使用NFS共享,则该进程和所有启动相关配置接可省略)。
- QuorumPeerMain:Zookeeper主进程
(三)目录规划
|
名称
|
|
|
$HADOOP_HOME
|
/home/zero/hadoop/hadoop-2.3.0-cdh5.0.1
|
|
Data
|
|
|
Log
|
|
三 环境准备
1)关闭防火墙
root 用户:
-
- [root@CentOS-Cluster-01 hadoop-2.3.0-cdh5.0.1]# service iptables stop
- iptables: Flushing firewall rules: [ OK ]
- iptables: Setting chains to policy ACCEPT: filter [ OK ]
- iptables: Unloading modules: [ OK ]
复制代码
验证:
-
- [root@CentOS-Cluster-01 hadoop-2.3.0-cdh5.0.1]# service iptables status
- iptables: Firewall is not running.
复制代码
2)安装JRE:略
3)安装Zookeeper :参见Zookeeper-3.4.5-cdh5.0.1 单机模式、副本模式安装指导
4)配置SSH互信:
(1)Hadoop-NN-01创建密钥:
- [zero@CentOS-Cluster-01 ~]$ ssh-keygen
- Generating public/private rsa key pair.
- Enter file in which to save the key (/home/zero/.ssh/id_rsa):
- Created directory '/home/zero/.ssh'.
- Enter passphrase (empty for no passphrase):
- Enter same passphrase again:
- Your identification has been saved in /home/zero/.ssh/id_rsa.
- Your public key has been saved in /home/zero/.ssh/id_rsa.pub.
- The key fingerprint is:
- 28:0a:29:1d:98:56:55:db:ec:83:93:56:8a:0f:6c:ea zero@CentOS-Cluster-01
- The key's randomart image is:
- +--[ RSA 2048]----+
- | ..... |
- | o. + |
- |o.. . + |
- |.o .. ..* |
- |+ . .=.*So |
- |.. .o.+ . . |
- | .. . |
- | . |
- | E |
- +-----------------+
复制代码
(2)分发密钥:
- [zero@CentOS-Cluster-01 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub zero@Hadoop-NN-01
- The authenticity of host 'hadoop-nn-01 (8.8.8.11)' can't be established.
- RSA key fingerprint is a6:11:09:49:8c:fe:b2:fb:49:d5:01:fa:13:1b:32:24.
- Are you sure you want to continue connecting (yes/no)? yes
- Warning: Permanently added 'hadoop-nn-01,8.8.8.11' (RSA) to the list of known hosts.
- puppet@hadoop-nn-01's password:
- Permission denied, please try again.
- puppet@hadoop-nn-01's password:
- [zero@CentOS-Cluster-01 ~][ DISCUZ_CODE_105 ]nbsp; ssh-copy-id -i ~/.ssh/id_rsa.pub zero@Hadoop-NN-01
- zero@hadoop-nn-01's password:
- Now try logging into the machine, with "ssh 'zero@Hadoop-NN-01'", and check in:
-
- .ssh/authorized_keys
-
- to make sure we haven't added extra keys that you weren't expecting.
- [zero@CentOS-Cluster-01 ~][ DISCUZ_CODE_105 ]nbsp; ssh-copy-id -i ~/.ssh/id_rsa.pub zero@Hadoop-NN-02
- (…略…)
- [zero@CentOS-Cluster-01 ~][ DISCUZ_CODE_105 ]nbsp; ssh-copy-id -i ~/.ssh/id_rsa.pub zero@Hadoop-DN-01
- (…略…)
- [zero@CentOS-Cluster-01 ~][ DISCUZ_CODE_105 ]nbsp; ssh-copy-id -i ~/.ssh/id_rsa.pub zero@Hadoop-DN-02
- (…略…)
- [zero@CentOS-Cluster-01 ~][ DISCUZ_CODE_105 ]nbsp; ssh-copy-id -i ~/.ssh/id_rsa.pub zero@Hadoop-DN-03
- (…略…)
复制代码
分发密钥这里如出现问题,可以参考:
linux(ubuntu)ssh无密码互通、相互登录高可靠文档
CentOS6.4之图解SSH无验证双向登陆配置
(3)验证:
- [zero@CentOS-Cluster-01 ~]$ ssh Hadoop-NN-01
- Last login: Sun Jun 22 19:56:23 2014 from 8.8.8.1
- [zero@CentOS-Cluster-01 ~]$ exit
- logout
- Connection to Hadoop-NN-01 closed.
- [zero@CentOS-Cluster-01 ~]$ ssh Hadoop-NN-02
- Last login: Sun Jun 22 20:03:31 2014 from 8.8.8.1
- [zero@CentOS-Cluster-03 ~]$ exit
- logout
- Connection to Hadoop-NN-02 closed.
- [zero@CentOS-Cluster-01 ~]$ ssh Hadoop-DN-01
- Last login: Mon Jun 23 02:00:07 2014 from centos_cluster_01
- [zero@CentOS-Cluster-03 ~]$ exit
- logout
- Connection to Hadoop-DN-01 closed.
- [zero@CentOS-Cluster-01 ~]$ ssh Hadoop-DN-02
- Last login: Sun Jun 22 20:07:03 2014 from 8.8.8.1
- [zero@CentOS-Cluster-04 ~]$ exit
- logout
- Connection to Hadoop-DN-02 closed.
- [zero@CentOS-Cluster-01 ~]$ ssh Hadoop-DN-03
- Last login: Sun Jun 22 20:07:05 2014 from 8.8.8.1
- [zero@CentOS-Cluster-05 ~]$ exit
- logout
- Connection to Hadoop-DN-03 closed.
复制代码
5)配置/etc/hosts并分发:
- [root@CentOS-Cluster-01 zero]# vi /etc/hosts
- 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
- ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
- 8.8.8.10 CentOS-StandAlone
- 8.8.8.11 CentOS-Cluster-01 Hadoop-NN-01
- 8.8.8.12 CentOS-Cluster-02 Hadoop-NN-02
- 8.8.8.13 CentOS-Cluster-03 Hadoop-DN-01 Zookeeper-01
- 8.8.8.14 CentOS-Cluster-04 Hadoop-DN-02 Zookeeper-02
- 8.8.8.15 CentOS-Cluster-05 Hadoop-DN-03 Zookeeper-03
复制代码
6)配置环境变量:vi ~/.bashrc 然后 source ~/.bashrc
-
- [zero@CentOS-Cluster-01 ~]$ vi ~/.bashrc
- ……
-
- # hadoop cdh5
- export HADOOP_HOME=/home/zero/hadoop/hadoop-2.3.0-cdh5.0.1
- export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
- [zero@CentOS-Cluster-01 ~]$ source ~/.bashrc
复制代码
四 安装
1)解压
- [puppet@BigData-01 cdh4.4]$ tar -xvf hadoop-2.0.0-cdh4.4.0.tar.gz
复制代码
下载地址:
CDH4包汇总
http://archive.cloudera.com/cdh4/
CDH5包汇总
http://archive.cloudera.com/cdh5/
2)修改配置文件
说明:
|
配置名称
|
|
|
|
hadoop-env.sh
|
|
|
|
core-site.xml
|
|
|
|
hdfs-site.xml
|
|
|
|
yarn-env.sh
|
|
|
|
yarn-site.xml
|
|
|
|
mapred-site.xml
|
|
|
|
capacity-scheduler.xml
|
|
|
|
container-executor.cfg
|
|
|
|
mapred-queues.xml
|
|
|
|
hadoop-metrics.properties
|
|
|
|
hadoop-metrics2.properties
|
|
|
|
slaves
|
|
|
|
exclude
|
|
|
|
log4j.properties
|
|
|
|
configuration.xsl
|
|
|
(1)修改$HADOOP_HOME/etc/hadoop-env.sh:
- #--------------------Java Env------------------------------
- export JAVA_HOME="/usr/runtime/java/jdk1.7.0_60"
-
- #--------------------Hadoop Env------------------------------
- #export HADOOP_PID_DIR=
- export HADOOP_PREFIX="/home/zero/hadoop/hadoop-2.3.0-cdh5.0.1"
-
- #--------------------Hadoop Daemon Options-----------------
- #export HADOOP_NAMENODE_OPTS="-XX:+UseParallelGC ${HADOOP_NAMENODE_OPTS}"
- #export HADOOP_DATANODE_OPTS=
-
- #--------------------Hadoop Logs---------------------------
- #export HADOOP_LOG_DIR=
-
复制代码
(2)修改$HADOOP_HOME/etc/hadoop-site.xml
-
-
-
-
-
- fs.defaultFS
- hdfs://mycluster
-
-
-
- dfs.permissions.superusergroup
- zero
-
-
-
-
- fs.trash.checkpoint.interval
- 0
-
-
-
- fs.trash.interval
- 1440
-
-
-
复制代码
(3)修改$HADOOP_HOME/etc/hdfs-site.xml
(4)修改$HADOOP_HOME/etc/yarn-env.sh
- #Yarn Daemon Options
- #export YARN_RESOURCEMANAGER_OPTS
- #export YARN_NODEMANAGER_OPTS
- #export YARN_PROXYSERVER_OPTS
- #export HADOOP_JOB_HISTORYSERVER_OPTS
-
- #Yarn Logs
- export YARN_LOG_DIR=” /home/zero/hadoop/hadoop-2.3.0-cdh5.0.1/logs”
-
复制代码
(5)$HADOOP_HOEM/etc/mapred-site.xml
-
-
-
- mapreduce.framework.name
- yarn
-
-
-
-
- mapreduce.jobhistory.address
- 0.0.0.0:10020
-
-
-
- mapreduce.jobhistory.webapp.address
- 0.0.0.0:19888
-
-
-
复制代码
(6)修改$HADOOP_HOME/etc/yarn-site.xml
(7)修改slaves
-
- [zero@CentOS-Cluster-01 hadoop]$ vi slaves
- Hadoop-DN-01
- Hadoop-DN-02
- Hadoop-DN-03
复制代码
3)分发程序
- [zero@CentOS-Cluster-01 ~]$ scp -r /home/zero/hadoop/hadoop-2.3.0-cdh5.0.1 zero@Hadoop-NN-02: /home/zero/hadoop/
- …….
- [zero@CentOS-Cluster-01 ~]$ scp -r /home/zero/hadoop/hadoop-2.3.0-cdh5.0.1 zero@Hadoop-DN-01: /home/zero/hadoop/
- …….
- [zero@CentOS-Cluster-01 ~]$ scp -r /home/zero/hadoop/hadoop-2.3.0-cdh5.0.1 zero@Hadoop-DN-02: /home/zero/hadoop/
- …….
- [zero@CentOS-Cluster-01 ~]$ scp -r /home/zero/hadoop/hadoop-2.3.0-cdh5.0.1 zero@Hadoop-DN-03: /home/zero/hadoop/
复制代码
4)启动HDFS
(1)启动JournalNode
格式化前需要在JournalNode结点上启动JournalNode:
- [zero@CentOS-Cluster-03 hadoop-2.3.0-cdh5.0.1]$ hadoop-daemon.sh start journalnode
- starting journalnode, logging to /home/puppet/hadoop/cdh4.4/hadoop-2.0.0-cdh4.4.0/logs/hadoop-puppet-journalnode-BigData-03.out
复制代码
验证JournalNode:
- [zero@CentOS-Cluster-03 hadoop-2.3.0-cdh5.0.1]$ jps
- 25918 QuorumPeerMain
- 16728 JournalNode
- 16772 Jps
复制代码
(2)NameNode 格式化:
结点Hadoop-NN-01:hdfs namenode -format
- [zero@CentOS-Cluster-01 hadoop-2.3.0-cdh5.0.1]$ hdfs namenode -format
- 14/06/23 21:02:49 INFO namenode.NameNode: STARTUP_MSG:
- /************************************************************
- STARTUP_MSG: Starting NameNode
- STARTUP_MSG: host = CentOS-Cluster-01/8.8.8.11
- STARTUP_MSG: args = [-format]
- STARTUP_MSG: version = 2.3.0-cdh5.0.1
- STARTUP_MSG: classpath =…
- STARTUP_MSG: build =…
- STARTUP_MSG: java = 1.7.0_60
- ************************************************************/
- (…略…)
- 14/06/23 21:02:57 INFO common.Storage: Storage directory /home/zero/hadoop/hadoop-2.3.0-cdh5.0.1/data/dfs/name has been successfully formatted. (…略…)
- 14/06/23 21:02:59 INFO namenode.NameNode: SHUTDOWN_MSG:
- /************************************************************
- SHUTDOWN_MSG: Shutting down NameNode at CentOS-Cluster-01/8.8.8.11
- ************************************************************/
复制代码
(3)同步NameNode元数据:
同步Hadoop-NN-01元数据到Hadoop-NN-02
主要是:dfs.namenode.name.dir,dfs.namenode.edits.dir还应该确保共享存储目录下(dfs.namenode.shared.edits.dir ) 包含NameNode 所有的元数据。
-
- [puppet@BigData-01 hadoop-2.0.0-cdh4.4.0]$ scp -r data/ zero@Hadoop-NN-02:/home/zero/hadoop/hadoop-2.3.0-cdh5.0.1
- seen_txid 100% 2 0.0KB/s 00:00
- VERSION 100% 201 0.2KB/s 00:00
- seen_txid 100% 2 0.0KB/s 00:00
- fsimage_0000000000000000000.md5 100% 62 0.1KB/s 00:00
- fsimage_0000000000000000000 100% 121 0.1KB/s 00:00
- VERSION 100% 201 0.2KB/s 00:00
复制代码
(4)初始化ZFCK:
创建ZNode,记录状态信息。
结点Hadoop-NN-01:hdfs zkfc -formatZK
- [zero@CentOS-Cluster-01 hadoop-2.3.0-cdh5.0.1]$ hdfs zkfc -formatZK
- 14/06/23 23:22:28 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
- 14/06/23 23:22:28 INFO tools.DFSZKFailoverController: Failover controller configured for NameNode NameNode at Hadoop-NN-01/8.8.8.11:8020
- 14/06/23 23:22:28 INFO zookeeper.ZooKeeper: Client environment:zookeeper.version=3.4.5-cdh5.0.1--1, built on 05/06/2014 18:50 GMT
- 14/06/23 23:22:28 INFO zookeeper.ZooKeeper: Client environment:host.name=CentOS-Cluster-01
- 14/06/23 23:22:28 INFO zookeeper.ZooKeeper: Client environment:java.version=1.7.0_60
- 14/06/23 23:22:28 INFO zookeeper.ZooKeeper: Client environment:java.vendor=Oracle Corporation
- 14/06/23 23:22:28 INFO zookeeper.ZooKeeper: Client environment:java.home=/usr/runtime/java/jdk1.7.0_60/jre
- 14/06/23 23:22:28 INFO zookeeper.ZooKeeper: Client environment:java.class.path=...
- 14/06/23 23:22:29 INFO zookeeper.ZooKeeper: Client environment:java.library.path=/home/zero/hadoop/hadoop-2.3.0-cdh5.0.1/lib/native
- 14/06/23 23:22:29 INFO zookeeper.ZooKeeper: Client environment:java.io.tmpdir=/tmp
- 14/06/23 23:22:29 INFO zookeeper.ZooKeeper: Client environment:java.compiler=
- 14/06/23 23:22:29 INFO zookeeper.ZooKeeper: Client environment:os.name=Linux
- 14/06/23 23:22:29 INFO zookeeper.ZooKeeper: Client environment:os.arch=i386
- 14/06/23 23:22:29 INFO zookeeper.ZooKeeper: Client environment:os.version=2.6.32-431.el6.i686
- 14/06/23 23:22:29 INFO zookeeper.ZooKeeper: Client environment:user.name=zero
- 14/06/23 23:22:29 INFO zookeeper.ZooKeeper: Client environment:user.home=/home/zero
- 14/06/23 23:22:29 INFO zookeeper.ZooKeeper: Client environment:user.dir=/home/zero/hadoop/hadoop-2.3.0-cdh5.0.1
- 14/06/23 23:22:29 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=Zookeeper-01:2181,Zookeeper-02:2181,Zookeeper-03:2181 sessionTimeout=2000 watcher=org.apache.hadoop.ha.ActiveStandbyElector$WatcherWithClientRef@150c2b0
- 14/06/23 23:22:29 INFO zookeeper.ClientCnxn: Opening socket connection to server CentOS-Cluster-03/8.8.8.13:2181. Will not attempt to authenticate using SASL (unknown error)
- 14/06/23 23:22:29 INFO zookeeper.ClientCnxn: Socket connection established to CentOS-Cluster-03/8.8.8.13:2181, initiating session
- 14/06/23 23:22:29 INFO zookeeper.ClientCnxn: Session establishment complete on server CentOS-Cluster-03/8.8.8.13:2181, sessionid = 0x146cc0517b30002, negotiated timeout = 4000
- 14/06/23 23:22:29 INFO ha.ActiveStandbyElector: Session connected.
- 14/06/23 23:22:30 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/mycluster in ZK.
- 14/06/23 23:22:30 INFO zookeeper.ZooKeeper: Session: 0x146cc0517b30002 closed
复制代码
(5)启动
集群启动法:Hadoop-NN-01:
- [zero@CentOS-Cluster-01 hadoop-2.3.0-cdh5.0.1]$ start-dfs.sh
- 14/04/23 01:54:58 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
- Starting namenodes on [Hadoop-NN-01 Hadoop-NN-02]
- Hadoop-NN-01: starting namenode, logging to /home/puppet/hadoop/cdh4.4/hadoop-2.0.0-cdh4.4.0/logs/hadoop-puppet-namenode-BigData-01.out
- Hadoop-NN-02: starting namenode, logging to /home/puppet/hadoop/cdh4.4/hadoop-2.0.0-cdh4.4.0/logs/hadoop-puppet-namenode-BigData-02.out
- Hadoop-DN-01: starting datanode, logging to /home/puppet/hadoop/cdh4.4/hadoop-2.0.0-cdh4.4.0/logs/hadoop-puppet-datanode-BigData-03.out
- Hadoop-DN-02: starting datanode, logging to /home/puppet/hadoop/cdh4.4/hadoop-2.0.0-cdh4.4.0/logs/hadoop-puppet-datanode-BigData-04.out
- Hadoop-DN-03: starting datanode, logging to /home/puppet/hadoop/cdh4.4/hadoop-2.0.0-cdh4.4.0/logs/hadoop-puppet-datanode-BigData-05.out
- Starting journal nodes [Hadoop-DN-01 Hadoop-DN-02 Hadoop-DN-03]
- Hadoop-DN-01: starting journalnode, logging to /home/puppet/hadoop/cdh4.4/hadoop-2.0.0-cdh4.4.0/logs/hadoop-puppet-journalnode-BigData-03.out
- Hadoop-DN-03: starting journalnode, logging to /home/puppet/hadoop/cdh4.4/hadoop-2.0.0-cdh4.4.0/logs/hadoop-puppet-journalnode-BigData-05.out
- Hadoop-DN-02: starting journalnode, logging to /home/puppet/hadoop/cdh4.4/hadoop-2.0.0-cdh4.4.0/logs/hadoop-puppet-journalnode-BigData-04.out
- 14/04/23 01:55:29 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
- Starting ZK Failover Controllers on NN hosts [Hadoop-NN-01 Hadoop-NN-02]
- Hadoop-NN-01: starting zkfc, logging to /home/puppet/hadoop/cdh4.4/hadoop-2.0.0-cdh4.4.0/logs/hadoop-puppet-zkfc-BigData-01.out
- Hadoop-NN-02: starting zkfc, logging to /home/puppet/hadoop/cdh4.4/hadoop-2.0.0-cdh4.4.0/logs/hadoop-puppet-zkfc-BigData-02.out
复制代码
单进程启动法:
<1>NameNode(Hadoop-NN-01,Hadoop-NN-02):
- [zero@CentOS-Cluster-01 hadoop-2.3.0-cdh5.0.1]$ hadoop-daemon.sh start namenode
复制代码
<2>DataNode(Hadoop-DN-01,Hadoop-DN-02,Hadoop-DN-03):
- [zero@CentOS-Cluster-01 hadoop-2.3.0-cdh5.0.1]$ hadoop-daemon.sh start datanode
复制代码
<3>JournalNode(Hadoop-DN-01,Hadoop-DN-02,Hadoop-DN-03):
- [zero@CentOS-Cluster-01 hadoop-2.3.0-cdh5.0.1]$ hadoop-daemon.sh start journalnode
复制代码
<4>ZKFC(Hadoop-NN-01,Hadoop-NN-02):
- [zero@CentOS-Cluster-01 hadoop-2.3.0-cdh5.0.1]$ hadoop-daemon.sh start zkfc
复制代码
(6)验证
<1>进程
NameNode:
- [zero@CentOS-Cluster-01 hadoop-2.3.0-cdh5.0.1]$ jps
- 4001 NameNode
- 4290 DFSZKFailoverController
- 4415 Jps
复制代码
DataNode:
- [zero@CentOS-Cluster-03 hadoop-2.3.0-cdh5.0.1]$ jps
- 25918 QuorumPeerMain
- 19217 JournalNode
- 19143 DataNode
- 19351 Jps
复制代码
<2>页面:
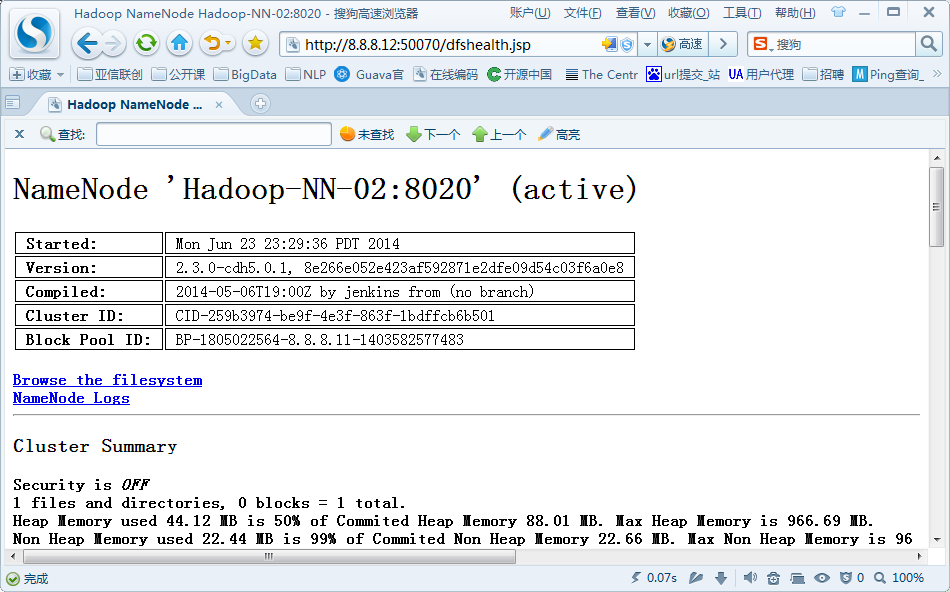
Active结点:
http://8.8.8.10:50070
 JSP:
JSP:
 StandBy结点:
StandBy结点:
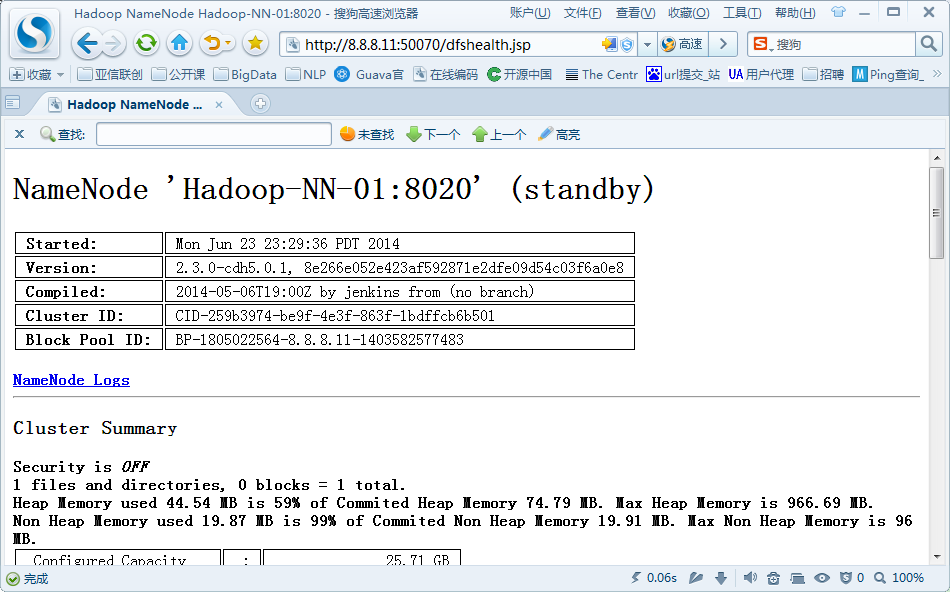
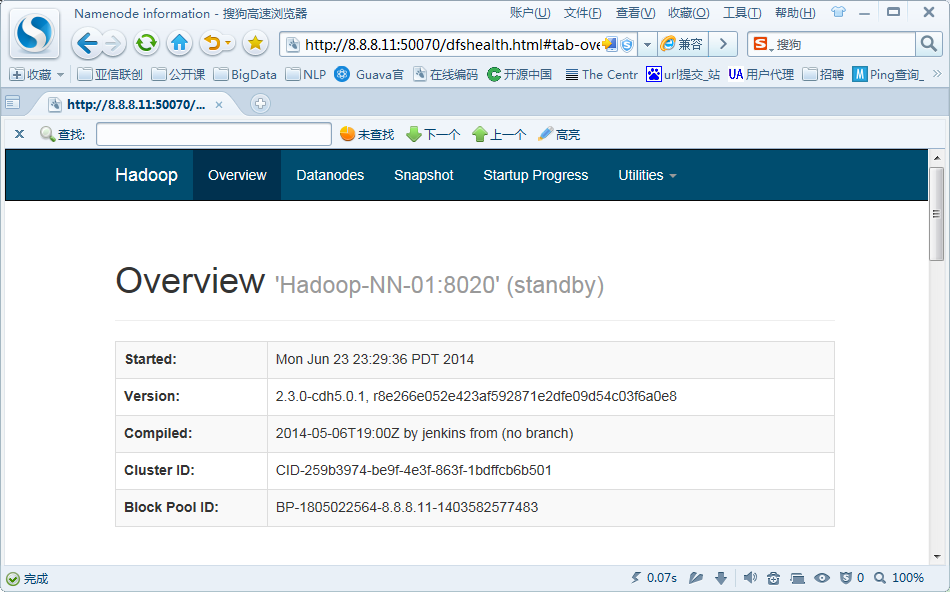 JSP:
JSP:
 (7)停止:stop-dfs.sh
(7)停止:stop-dfs.sh
5)启动Yarn
(1)启动
<1>集群启动
Hadoop-NN-01启动Yarn,命令所在目录:$HADOOP_HOME/sbin
- [zero@CentOS-Cluster-01 hadoop]$ start-yarn.sh
- starting yarn daemons
- starting resourcemanager, logging to /home/zero/hadoop/hadoop-2.3.0-cdh5.0.1/logs/yarn-zero-resourcemanager-CentOS-Cluster-01.out
- Hadoop-DN-02: starting nodemanager, logging to /home/zero/hadoop/hadoop-2.3.0-cdh5.0.1/logs/yarn-zero-nodemanager-CentOS-Cluster-04.out
- Hadoop-DN-03: starting nodemanager, logging to /home/zero/hadoop/hadoop-2.3.0-cdh5.0.1/logs/yarn-zero-nodemanager-CentOS-Cluster-05.out
- Hadoop-DN-01: starting nodemanager, logging to /home/zero/hadoop/hadoop-2.3.0-cdh5.0.1/logs/yarn-zero-nodemanager-CentOS-Cluster-03.out
复制代码
Hadoop-NN-02备机启动RM:
- [zero@CentOS-Cluster-02 hadoop]$ yarn-daemon.sh start resourcemanager
- starting resourcemanager, logging to /home/zero/hadoop/hadoop-2.3.0-cdh5.0.1/logs/yarn-zero-resourcemanager-CentOS-Cluster-02.o
复制代码
<2>单进程启动
ResourceManager(Hadoop-NN-01,Hadoop-NN-02):
- [zero@CentOS-Cluster-01 hadoop-2.3.0-cdh5.0.1]$ yarn-daemon.sh start resourcemanager
复制代码
DataNode(Hadoop-DN-01,Hadoop-DN-02,Hadoop-DN-03):
- [zero@CentOS-Cluster-03 hadoop-2.3.0-cdh5.0.1]$ yarn-daemon.sh start nodemanager
-
复制代码
(2)验证
<1>进程:
JobTracker:Hadoop-NN-01,Hadoop-NN-02
- [zero@CentOS-Cluster-01 hadoop]$ jps
- 7454 NameNode
- 14684 Jps
- 14617 ResourceManager
- 7729 DFSZKFailoverController
复制代码
TaskTracker:Hadoop-DN-01,Hadoop-DN-02,Hadoop-DN-03
- [zero@CentOS-Cluster-03 ~]$ jps
- 8965 Jps
- 5228 JournalNode
- 5137 DataNode
- 2514 QuorumPeerMain
- 8935 NodeManager
复制代码
<2>页面
ResourceManger(Active):8.8.8.11:23188
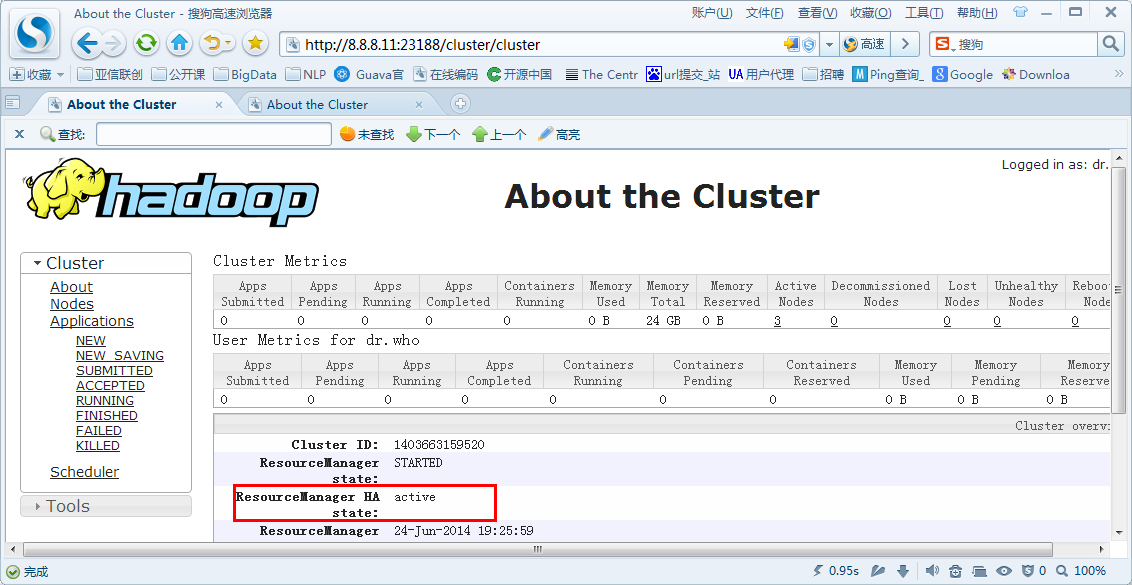 ResourceManager(Standby):8.8.8.12:23188
ResourceManager(Standby):8.8.8.12:23188
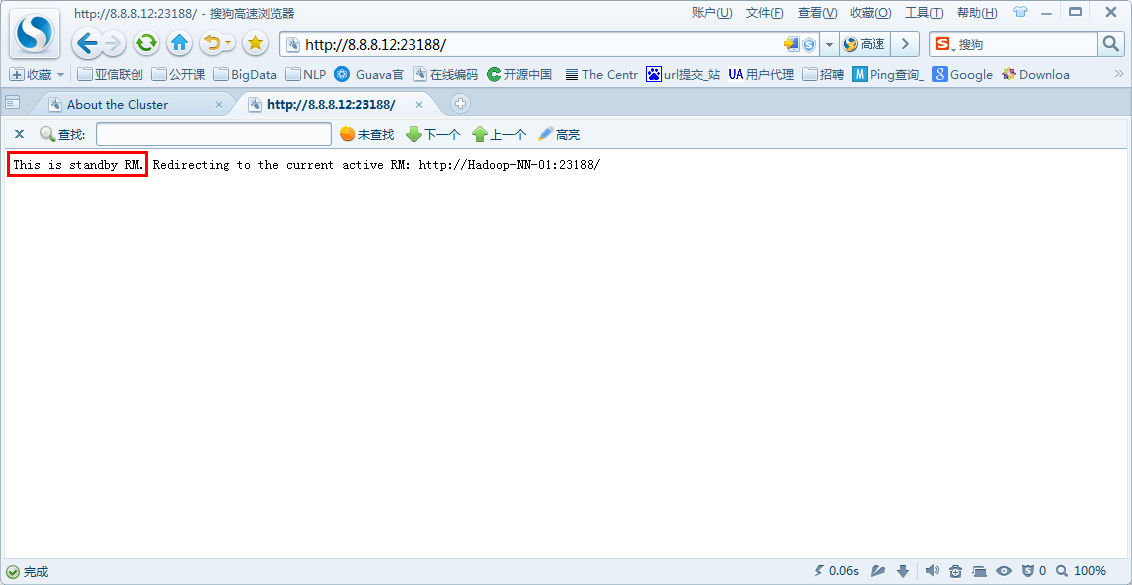
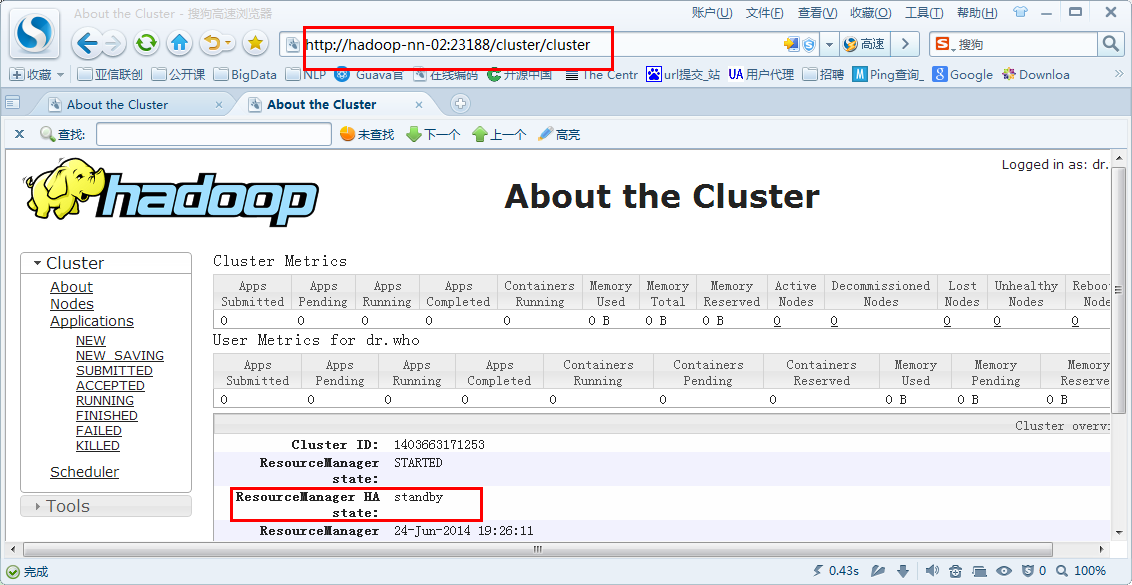 (3)停止
(3)停止
Hadoop-NN-01:stop-yarn.sh
Hadoop-NN-02:yarn-daeman.sh stop resourcemanager
转载:
http://shihlei.iteye.com/