网上有一些都是在Linux下使用安装Eclipse来进行hadoop应用开发,但是大部分Java程序员对linux系统不是那么熟悉,所以需要在windows下开发hadoop程序,所以经过试验,总结了下如何在windows下使用Eclipse来开发hadoop程序代码。
1、 需要下载hadoop的专门插件jar包
hadoop版本为2.3.0,hadoop集群搭建在centos6x上面,插件包下载地址为:http://download.csdn.net/detail/mchdba/8267181,jar包名字为hadoop-eclipse-plugin-2.3.0,可以适用于hadoop2x系列软件版本。
2、 把插件包放到eclipse/plugins目录下
为了以后方便,我这里把尽可能多的jar包都放进来了,如下图所示: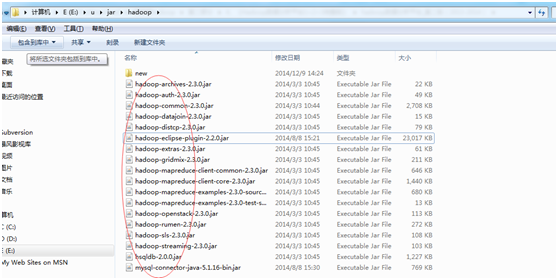
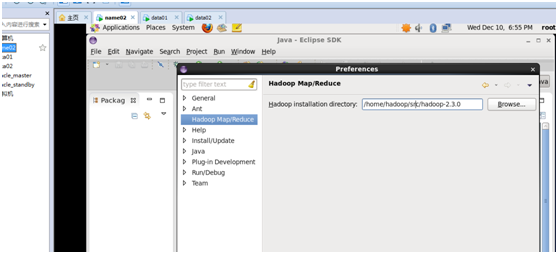
3、重启eclipse,配置Hadoop installation directory
如果插件安装成功,打开Windows—Preferences后,在窗口左侧会有Hadoop Map/Reduce选项,点击此选项,在窗口右侧设置Hadoop安装路径。
4、配置Map/Reduce Locations
打开Windows-->Open Perspective-->Other
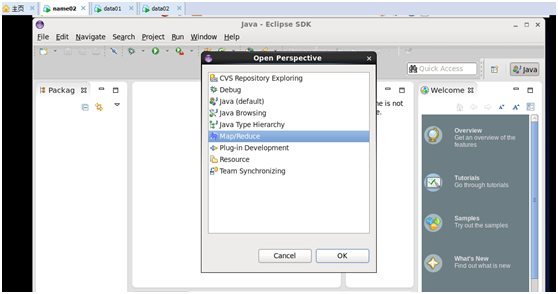
选择Map/Reduce,点击OK,在右下方看到有个Map/Reduce Locations的图标,如下图所示: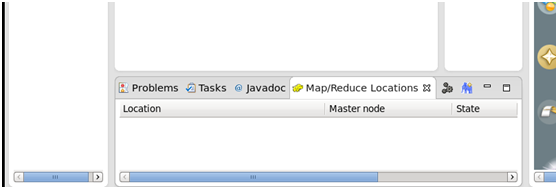
点击Map/Reduce Location选项卡,点击右边小象图标,打开Hadoop Location配置窗口:
输入Location Name,任意名称即可.配置Map/Reduce Master和DFS Mastrer,Host和Port配置成与core-site.xml的设置一致即可。
去找core-site.xml配置:
<property> <name>fs.default.name</name> <value>hdfs://name01:9000</value> </property>
在界面配置如下:
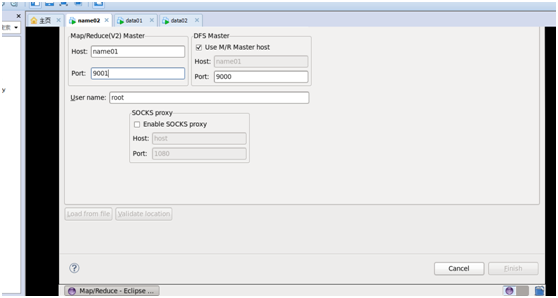
点击"Finish"按钮,关闭窗口。点击左侧的DFSLocations—>myhadoop(上一步配置的location name),如能看到user,表示安装成功,但是进去看到报错信息:Error: Permission denied: user=root,access=READ_EXECUTE,inode="/tmp";hadoop:supergroup:drwx---------,如下图所示:
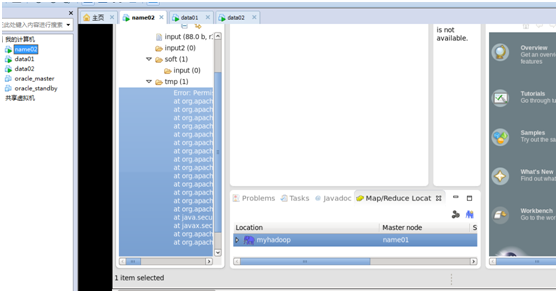
应该是权限问题:把/tmp/目录下面所有的关于hadoop的文件夹设置成hadoop用户所有然后分配授予777权限。
cd /tmp/
chmod 777 /tmp/
chown -R hadoop.hadoop /tmp/hsperfdata_root
之后重新连接打开DFS Locations就显示正常了。
Map/Reduce Master (此处为Hadoop集群的Map/Reduce地址,应该和mapred-site.xml中的mapred.job.tracker设置相同)
(1):点击报错:
An internal error occurred during: "Connecting to DFS hadoopname01".
java.net.UnknownHostException: name01
直接在hostname那一栏里面设置ip地址为:192.168.52.128,即可,这样就正常打开了,如下图所示: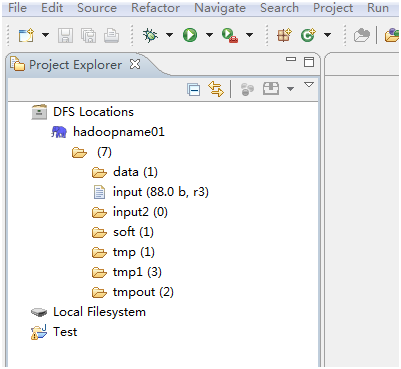
5、新建WordCount项目
File—>Project,选择Map/Reduce Project,输入项目名称WordCount等。
在WordCount项目里新建class,名称为WordCount,报错代码如下:Invalid Hadoop Runtime specified; please click 'Configure Hadoop install directory' or fill in library location input field,报错原因是目录选择不对,不能选择在跟目录E:\hadoop下,换成E:\u\hadoop\就可以了,如下所示:
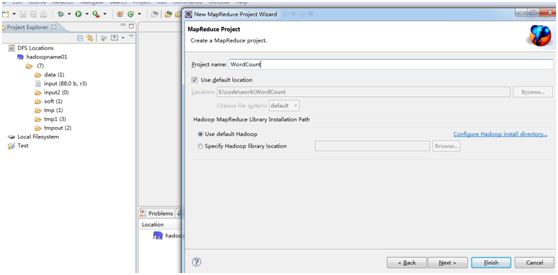
一路下一步过去,点击Finished按钮,完成工程创建,Eclipse控制台下面出现如下信息:
14-12-9 下午04时03分10秒: Eclipse is running in a JRE, but a JDK is required
Some Maven plugins may not work when importing projects or updating source folders.
14-12-9 下午04时03分13秒: Refreshing [/WordCount/pom.xml]
14-12-9 下午04时03分14秒: Refreshing [/WordCount/pom.xml]
14-12-9 下午04时03分14秒: Refreshing [/WordCount/pom.xml]
14-12-9 下午04时03分14秒: Updating index central|http://repo1.maven.org/maven2
14-12-9 下午04时04分10秒: Updated index for central|http://repo1.maven.org/maven2
6, Lib包导入:
需要添加的hadoop相应jar包有:
/hadoop-2.3.0/share/hadoop/common下所有jar包,及里面的lib目录下所有jar包,
/hadoop-2.3.0/share/hadoop/hdfs下所有jar包,不包括里面lib下的jar包,
/hadoop-2.3.0/share/hadoop/mapreduce下所有jar包,不包括里面lib下的jar包,
/hadoop-2.3.0/share/hadoop/yarn下所有jar包,不包括里面lib下的jar包,
大概18个jar包左右。
7,Eclipse直接提交mapreduce任务所需要环境配置代码如下所示:
- package wc;
- import java.io.IOException;
- import java.util.StringTokenizer;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.util.GenericOptionsParser;
-
- public class W2 {
-
- public static class TokenizerMapper extends
- Mapper<Object, Text, Text, IntWritable> {
- private final static IntWritable one = new IntWritable(1);
- private Text word = new Text();
- public void map(Object key, Text value, Context context)
- throws IOException, InterruptedException {
- StringTokenizer itr = new StringTokenizer(value.toString());
- while (itr.hasMoreTokens()) {
- word.set(itr.nextToken());
- context.write(word, one);
- }
- }
- }
-
- public static class IntSumReducer extends
- Reducer<Text, IntWritable, Text, IntWritable> {
- private IntWritable result = new IntWritable();
- public void reduce(Text key, Iterable<IntWritable> values,
- Context context) throws IOException, InterruptedException {
- int sum = 0;
- for (IntWritable val : values) {
- sum += val.get();
- }
- result.set(sum);
- context.write(key, result);
- }
- }
-
- public static void main(String[] args) throws Exception {
-
- Configuration conf = new Configuration(); System.setProperty(\
8、运行
8.1、在HDFS上创建目录input
[hadoop@name01 hadoop-2.3.0]$ hadoop fs -ls /
[hadoop@name01 hadoop-2.3.0]$ hadoop fs -mkdir input
mkdir: `input': No such file or directory
[hadoop@name01 hadoop-2.3.0]$ PS:fs需要全目录的方式来创建文件夹
如果Apache hadoop版本是0.x 或者1.x,
bin/hadoop hdfs fs -mkdir -p /in
bin/hadoop hdfs fs -put /home/du/input /in
如果Apache hadoop版本是2.x.
bin/hdfs dfs -mkdir -p /in
bin/hdfs dfs -put /home/du/input /in
如果是发行版的hadoop,比如Cloudera CDH,IBM BI,Hortonworks HDP 则第一种命令即可。要注意创建目录的全路径。另外hdfs的根目录是 /
2、拷贝本地README.txt到HDFS的input里
[hadoop@name01 hadoop-2.3.0]$ find . -name README.txt
./share/doc/hadoop/common/README.txt
[hadoop@name01 ~]$ hadoop fs -copyFromLocal ./src/hadoop-2.3.0/share/doc/hadoop/common/README.txt /data/input
[hadoop@name01 ~]$
[hadoop@name01 ~]$ hadoop fs -ls /
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2014-12-15 23:34 /data
-rw-r--r-- 3 hadoop supergroup 88 2014-08-26 02:21 /input
You have new mail in /var/spool/mail/root
[hadoop@name01 ~]$
3,运行hadoop结束后,查看输出结果
(1),直接在hadoop服务器上面查看
[hadoop@name01 ~]$ hadoop fs -ls /data/
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2014-12-15 23:29 /data/input
drwxr-xr-x - hadoop supergroup 0 2014-12-15 23:34 /data/output
[hadoop@name01 ~]$
(2),去Eclipse下查看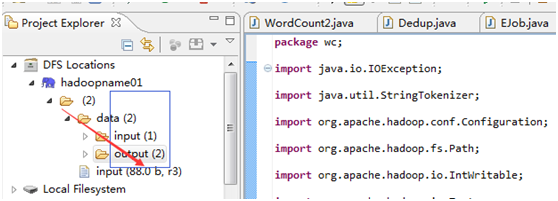
(3),在控制台上查看信息
- 2014-12-16 15:34:01,303 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(996)) - session.id is deprecated. Instead, use dfs.metrics.session-id
- 2014-12-16 15:34:01,309 INFO [main] jvm.JvmMetrics (JvmMetrics.java:init(76)) - Initializing JVM Metrics with processName=JobTracker, sessionId=
- 2014-12-16 15:34:02,047 INFO [main] input.FileInputFormat (FileInputFormat.java:listStatus(287)) - Total input paths to process : 1
- 2014-12-16 15:34:02,120 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:submitJobInternal(396)) - number of splits:1
- 2014-12-16 15:34:02,323 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:printTokens(479)) - Submitting tokens for job: job_local1764589720_0001
- 2014-12-16 15:34:02,367 WARN [main] conf.Configuration (Configuration.java:loadProperty(2345)) - file:/tmp/hadoop-hadoop/mapred/staging/hadoop1764589720/.staging/job_local1764589720_0001/job.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.retry.interval; Ignoring.
- 2014-12-16 15:34:02,368 WARN [main] conf.Configuration (Configuration.java:loadProperty(2345)) - file:/tmp/hadoop-hadoop/mapred/staging/hadoop1764589720/.staging/job_local1764589720_0001/job.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.attempts; Ignoring.
- 2014-12-16 15:34:02,682 WARN [main] conf.Configuration (Configuration.java:loadProperty(2345)) - file:/tmp/hadoop-hadoop/mapred/local/localRunner/hadoop/job_local1764589720_0001/job_local1764589720_0001.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.retry.interval; Ignoring.
- 2014-12-16 15:34:02,682 WARN [main] conf.Configuration (Configuration.java:loadProperty(2345)) - file:/tmp/hadoop-hadoop/mapred/local/localRunner/hadoop/job_local1764589720_0001/job_local1764589720_0001.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.attempts; Ignoring.
- 2014-12-16 15:34:02,703 INFO [main] mapreduce.Job (Job.java:submit(1289)) - The url to track the job: http://localhost:8080/
- 2014-12-16 15:34:02,704 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1334)) - Running job: job_local1764589720_0001
- 2014-12-16 15:34:02,707 INFO [Thread-4] mapred.LocalJobRunner (LocalJobRunner.java:createOutputCommitter(471)) - OutputCommitter set in config null
- 2014-12-16 15:34:02,719 INFO [Thread-4] mapred.LocalJobRunner (LocalJobRunner.java:createOutputCommitter(489)) - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
- 2014-12-16 15:34:02,853 INFO [Thread-4] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(448)) - Waiting for map tasks
- 2014-12-16 15:34:02,857 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:run(224)) - Starting task: attempt_local1764589720_0001_m_000000_0
- 2014-12-16 15:34:02,919 INFO [LocalJobRunner Map Task Executor #0] util.ProcfsBasedProcessTree (ProcfsBasedProcessTree.java:isAvailable(129)) - ProcfsBasedProcessTree currently is supported only on Linux.
- 2014-12-16 15:34:03,281 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:initialize(581)) - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@2e1022ec
- 2014-12-16 15:34:03,287 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:runNewMapper(733)) - Processing split: hdfs://192.168.52.128:9000/data/input/README.txt:0+1366
- 2014-12-16 15:34:03,304 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:createSortingCollector(388)) - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
- 2014-12-16 15:34:03,340 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:setEquator(1181)) - (EQUATOR) 0 kvi 26214396(104857584)
- 2014-12-16 15:34:03,341 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(975)) - mapreduce.task.io.sort.mb: 100
- 2014-12-16 15:34:03,341 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(976)) - soft limit at 83886080
- 2014-12-16 15:34:03,341 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(977)) - bufstart = 0; bufvoid = 104857600
- 2014-12-16 15:34:03,341 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(978)) - kvstart = 26214396; length = 6553600
- 2014-12-16 15:34:03,708 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1355)) - Job job_local1764589720_0001 running in uber mode : false
- 2014-12-16 15:34:03,710 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1362)) - map 0% reduce 0%
- 2014-12-16 15:34:04,121 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) -
- 2014-12-16 15:34:04,128 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1435)) - Starting flush of map output
- 2014-12-16 15:34:04,128 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1453)) - Spilling map output
- 2014-12-16 15:34:04,128 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1454)) - bufstart = 0; bufend = 2055; bufvoid = 104857600
- 2014-12-16 15:34:04,128 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1456)) - kvstart = 26214396(104857584); kvend = 26213684(104854736); length = 713/6553600
- 2014-12-16 15:34:04,179 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:sortAndSpill(1639)) - Finished spill 0
- 2014-12-16 15:34:04,194 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:done(995)) - Task:attempt_local1764589720_0001_m_000000_0 is done. And is in the process of committing
- 2014-12-16 15:34:04,207 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - map
- 2014-12-16 15:34:04,208 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:sendDone(1115)) - Task \'attempt_local1764589720_0001_m_000000_0\' done.
- 2014-12-16 15:34:04,208 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:run(249)) - Finishing task: attempt_local1764589720_0001_m_000000_0
- 2014-12-16 15:34:04,208 INFO [Thread-4] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(456)) - map task executor complete.
- 2014-12-16 15:34:04,211 INFO [Thread-4] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(448)) - Waiting for reduce tasks
- 2014-12-16 15:34:04,211 INFO [pool-6-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:run(302)) - Starting task: attempt_local1764589720_0001_r_000000_0
- 2014-12-16 15:34:04,221 INFO [pool-6-thread-1] util.ProcfsBasedProcessTree (ProcfsBasedProcessTree.java:isAvailable(129)) - ProcfsBasedProcessTree currently is supported only on Linux.
- 2014-12-16 15:34:04,478 INFO [pool-6-thread-1] mapred.Task (Task.java:initialize(581)) - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@36154615
- 2014-12-16 15:34:04,483 INFO [pool-6-thread-1] mapred.ReduceTask (ReduceTask.java:run(362)) - Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@e2b02a3
- 2014-12-16 15:34:04,500 INFO [pool-6-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java:<init>(193)) - MergerManager: memoryLimit=949983616, maxSingleShuffleLimit=237495904, mergeThreshold=626989184, ioSortFactor=10, memToMemMergeOutputsThreshold=10
- 2014-12-16 15:34:04,503 INFO [EventFetcher for fetching Map Completion Events] reduce.EventFetcher (EventFetcher.java:run(61)) - attempt_local1764589720_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
- 2014-12-16 15:34:04,543 INFO [localfetcher#1] reduce.LocalFetcher (LocalFetcher.java:copyMapOutput(140)) - localfetcher#1 about to shuffle output of map attempt_local1764589720_0001_m_000000_0 decomp: 1832 len: 1836 to MEMORY
- 2014-12-16 15:34:04,548 INFO [localfetcher#1] reduce.InMemoryMapOutput (InMemoryMapOutput.java:shuffle(100)) - Read 1832 bytes from map-output for attempt_local1764589720_0001_m_000000_0
- 2014-12-16 15:34:04,553 INFO [localfetcher#1] reduce.MergeManagerImpl (MergeManagerImpl.java:closeInMemoryFile(307)) - closeInMemoryFile -> map-output of size: 1832, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->1832
- 2014-12-16 15:34:04,564 INFO [EventFetcher for fetching Map Completion Events] reduce.EventFetcher (EventFetcher.java:run(76)) - EventFetcher is interrupted.. Returning
- 2014-12-16 15:34:04,566 INFO [pool-6-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - 1 / 1 copied.
- 2014-12-16 15:34:04,566 INFO [pool-6-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java:finalMerge(667)) - finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
- 2014-12-16 15:34:04,585 INFO [pool-6-thread-1] mapred.Merger (Merger.java:merge(589)) - Merging 1 sorted segments
- 2014-12-16 15:34:04,585 INFO [pool-6-thread-1] mapred.Merger (Merger.java:merge(688)) - Down to the last merge-pass, with 1 segments left of total size: 1823 bytes
- 2014-12-16 15:34:04,605 INFO [pool-6-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java:finalMerge(742)) - Merged 1 segments, 1832 bytes to disk to satisfy reduce memory limit
- 2014-12-16 15:34:04,605 INFO [pool-6-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java:finalMerge(772)) - Merging 1 files, 1836 bytes from disk
- 2014-12-16 15:34:04,606 INFO [pool-6-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java:finalMerge(787)) - Merging 0 segments, 0 bytes from memory into reduce
- 2014-12-16 15:34:04,607 INFO [pool-6-thread-1] mapred.Merger (Merger.java:merge(589)) - Merging 1 sorted segments
- 2014-12-16 15:34:04,608 INFO [pool-6-thread-1] mapred.Merger (Merger.java:merge(688)) - Down to the last merge-pass, with 1 segments left of total size: 1823 bytes
- 2014-12-16 15:34:04,608 INFO [pool-6-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - 1 / 1 copied.
- 2014-12-16 15:34:04,643 INFO [pool-6-thread-1] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(996)) - mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
- 2014-12-16 15:34:04,714 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1362)) - map 100% reduce 0%
- 2014-12-16 15:34:04,842 INFO [pool-6-thread-1] mapred.Task (Task.java:done(995)) - Task:attempt_local1764589720_0001_r_000000_0 is done. And is in the process of committing
- 2014-12-16 15:34:04,850 INFO [pool-6-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - 1 / 1 copied.
- 2014-12-16 15:34:04,850 INFO [pool-6-thread-1] mapred.Task (Task.java:commit(1156)) - Task attempt_local1764589720_0001_r_000000_0 is allowed to commit now
- 2014-12-16 15:34:04,881 INFO [pool-6-thread-1] output.FileOutputCommitter (FileOutputCommitter.java:commitTask(439)) - Saved output of task \'attempt_local1764589720_0001_r_000000_0\' to hdfs://192.168.52.128:9000/data/output/_temporary/0/task_local1764589720_0001_r_000000
- 2014-12-16 15:34:04,884 INFO [pool-6-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - reduce > reduce
- 2014-12-16 15:34:04,884 INFO [pool-6-thread-1] mapred.Task (Task.java:sendDone(1115)) - Task \'attempt_local1764589720_0001_r_000000_0\' done.
- 2014-12-16 15:34:04,885 INFO [pool-6-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:run(325)) - Finishing task: attempt_local1764589720_0001_r_000000_0
- 2014-12-16 15:34:04,885 INFO [Thread-4] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(456)) - reduce task executor complete.
- 2014-12-16 15:34:05,714 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1362)) - map 100% reduce 100%
- 2014-12-16 15:34:05,714 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1373)) - Job job_local1764589720_0001 completed successfully
- 2014-12-16 15:34:05,733 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1380)) - Counters: 38
- File System Counters
- FILE: Number of bytes read=34542
- FILE: Number of bytes written=470650
- FILE: Number of read operations=0
- FILE: Number of large read operations=0
- FILE: Number of write operations=0
- HDFS: Number of bytes read=2732
- HDFS: Number of bytes written=1306
- HDFS: Number of read operations=15
- HDFS: Number of large read operations=0
- HDFS: Number of write operations=4
- Map-Reduce Framework
- Map input records=31
- Map output records=179
- Map output bytes=2055
- Map output materialized bytes=1836
- Input split bytes=113
- Combine input records=179
- Combine output records=131
- Reduce input groups=131
- Reduce shuffle bytes=1836
- Reduce input records=131
- Reduce output records=131
- Spilled Records=262
- Shuffled Maps =1
- Failed Shuffles=0
- Merged Map outputs=1
- GC time elapsed (ms)=13
- CPU time spent (ms)=0
- Physical memory (bytes) snapshot=0
- Virtual memory (bytes) snapshot=0
- Total committed heap usage (bytes)=440664064
- Shuffle Errors
- BAD_ID=0
- CONNECTION=0
- IO_ERROR=0
- WRONG_LENGTH=0
- WRONG_MAP=0
- WRONG_REDUCE=0
- File Input Format Counters
- Bytes Read=1366
- File Output Format Counters
- Bytes Written=1306
----------------------------------------------------------------------------------------------------------------
<版权所有,文章允许转载,但必须以链接方式注明源地址,否则追究法律责任!>
原博客地址: http://blog.itpub.net/26230597/viewspace-1370205/
原作者:黄杉 (mchdba)
----------------------------------------------------------------------------------------------------------------