1.ActiveNameNode修改hdfs-site.xml文件
点击(此处)折叠或打开
- [root@sht-sgmhadoopnn-01 hadoop]# vi hdfs-site.xml
-
- <!--动态许可datanode连接namenode列表-->
- <property>
- <name>dfs.hosts</name>
- <value>/hadoop/hadoop-2.7.2/etc/hadoop/include_datanode</value>
- </property>
-
- <!--动态拒绝datanode连接namenode列表 -->
- <property>
- <name>dfs.hosts.exclude</name>
- <value>/hadoop/hadoop-2.7.2/etc/hadoop/exclude_datanode</value>
- </property>
###StandbyNameNode节点可以不同步,也可以同步(我采取同步)
点击(此处)折叠或打开
- [root@sht-sgmhadoopnn-01 hadoop]# scp hdfs-site.xml root@sht-sgmhadoopnn-02:/hadoop/hadoop-2.7.2/etc/hadoop/
- hdfs-site.xml 100% 4711 4.6KB/s 00:00
2.创建include_datanode和exclude_datanode文件
点击(此处)折叠或打开
- [root@sht-sgmhadoopnn-01 hadoop]# vi /hadoop/hadoop-2.7.2/etc/hadoop/include_datanode
- sht-sgmhadoopdn-01
- sht-sgmhadoopdn-02
- sht-sgmhadoopdn-03
- sht-sgmhadoopdn-04
#在文件中罗列出能够访问namenode的所有datanode节点
点击(此处)折叠或打开
- [root@sht-sgmhadoopnn-01 hadoop]# vi /hadoop/hadoop-2.7.2/etc/hadoop/exclude_datanode
- sht-sgmhadoopdn-04
#在文件中罗列出拒绝访问namenode的所有datanode节点
###StandbyNameNode节点可以不同步,也可以同步(我采取同步)
点击(此处)折叠或打开
- [root@sht-sgmhadoopnn-01 hadoop]# scp include_datanode exclude_datanode root@sht-sgmhadoopnn-02:/hadoop/hadoop-2.7.2/etc/hadoop/
3.查看当前备份系数
在我的测试环境中,目前节点为4台,备份系数为4,将备份系数从4降低到3
点击(此处)折叠或打开
- [root@sht-sgmhadoopnn-01 hadoop]# more hdfs-site.xml
- <property>
- <name>dfs.replication</name>
- <value>4</value>
- </property>
- [root@sht-sgmhadoopnn-01 hadoop]# hdfs fsck /
- 16/03/06 21:49:10 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
- Connecting to namenode via http://sht-sgmhadoopnn-01:50070/fsck?ugi=root&path=%2F
- FSCK started by root (auth:SIMPLE) from /172.16.101.55 for path / at Sun Mar 06 21:49:12 CST 2016
- ...............Status: HEALTHY
- Total size: 580152025 B
- Total dirs: 17
- Total files: 15
- Total symlinks: 0
- Total blocks (validated): 14 (avg. block size 41439430 B)
- Minimally replicated blocks: 14 (100.0 %)
- Over-replicated blocks: 0 (0.0 %)
- Under-replicated blocks: 0 (0.0 %)
- Mis-replicated blocks: 0 (0.0 %)
- Default replication factor: 3
- Average block replication: 4.0
- Corrupt blocks: 0
- Missing replicas: 0 (0.0 %)
- Number of data-nodes: 4
- Number of racks: 1
- FSCK ended at Sun Mar 06 21:49:12 CST 2016 in 8 milliseconds
###参数Default replication factor为3,而hdfs-site.xml文件中dfs.replication值为4,说明设置了,然而集群没有重启生效。
故在本次实验中只需修改hdfs-site.xml文件而不需要重启集群,和 修改参数Average block replication值从4到3(hdfs dfs -setrep -w 3 -R /)。
4.修改参数
点击(此处)折叠或打开
- [root@sht-sgmhadoopnn-01 hadoop]# more hdfs-site.xml
- <property>
- <name>dfs.replication</name>
- <value>3</value>
- </property>
- [root@sht-sgmhadoopnn-01 hadoop]# scp hdfs-site.xml root@sht-sgmhadoopnn-02:/hadoop/hadoop-2.7.2/etc/hadoop/
-
- [root@sht-sgmhadoopnn-01 hadoop]# hdfs dfs -setrep -w 3 -R /
###文件系统假如灰常大,建议在业务峰谷时操作这条命令,因为耗时。
遇到的疑问:
在进行文件备份系数的降低时,能够很快的进行Replication set,但是在Waiting for的过程中却很长时间没有完成。
最终只能手动Ctrl+C中断,个人猜测在这个过程中HDFS正视图对数据文件进行操作,在删除一个副本容量的数据。
因此,我们应该对dfs.replication的数值做出很好的规划,尽量避免需要降低该数值的情况出现。
###步骤4导致datanode1节点数据块删除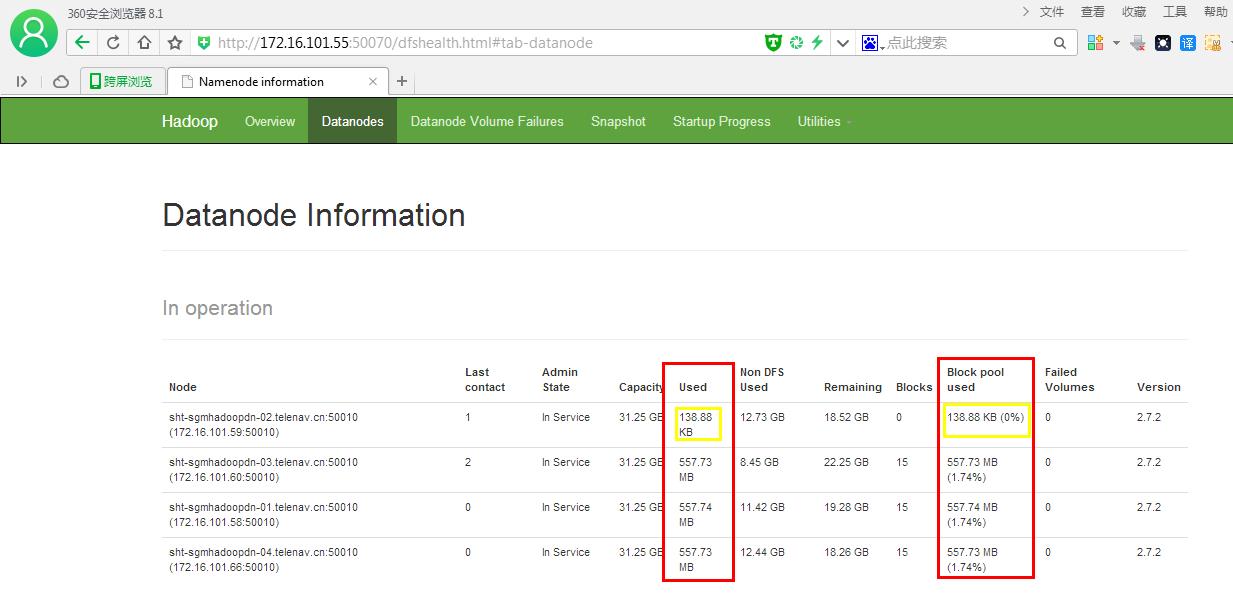
5.再次hdfs fsck /
点击(此处)折叠或打开
- [root@sht-sgmhadoopnn-01 hadoop]# hdfs fsck /
- 16/03/06 22:45:45 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
- Connecting to namenode via http://sht-sgmhadoopnn-01:50070/fsck?ugi=root&path=%2F
- FSCK started by root (auth:SIMPLE) from /172.16.101.55 for path / at Sun Mar 06 22:45:47 CST 2016
- ................Status: HEALTHY
- Total size: 580152087 B
- Total dirs: 17
- Total files: 16
- Total symlinks: 0
- Total blocks (validated): 15 (avg. block size 38676805 B)
- Minimally replicated blocks: 15 (100.0 %)
- Over-replicated blocks: 0 (0.0 %)
- Under-replicated blocks: 0 (0.0 %)
- Mis-replicated blocks: 0 (0.0 %)
- Default replication factor: 3
- Average block replication: 3.0
- Corrupt blocks: 0
- Missing replicas: 0 (0.0 %)
- Number of data-nodes: 4
- Number of racks: 1
- FSCK ended at Sun Mar 06 22:45:47 CST 2016 in 7 milliseconds
-
- The filesystem under path '/' is HEALTHY
- You have mail in /var/spool/mail/root
- [root@sht-sgmhadoopnn-01 hadoop]#
### Average block replication值为3.0
6.第一次动态刷新配置hdfs dfsadmin -refreshNodes
点击(此处)折叠或打开
- [root@sht-sgmhadoopnn-01 hadoop]# hdfs dfsadmin -refreshNodes
- Refresh nodes successful for sht-sgmhadoopnn-01/172.16.101.55:8020
- Refresh nodes successful for sht-sgmhadoopnn-02/172.16.101.56:8020
7.通过过hdfs dfsadmin -report或http://172.16.101.55:50070/dfshealth.html#tab-datanode
http://172.16.101.55:50070/dfshealth.html#tab-datanode
###刚开始状态为Decommission In Progress,会平衡数据的(datanode1当前数据量used:138.88kb,blocks:0, 会被复制平衡数据块)
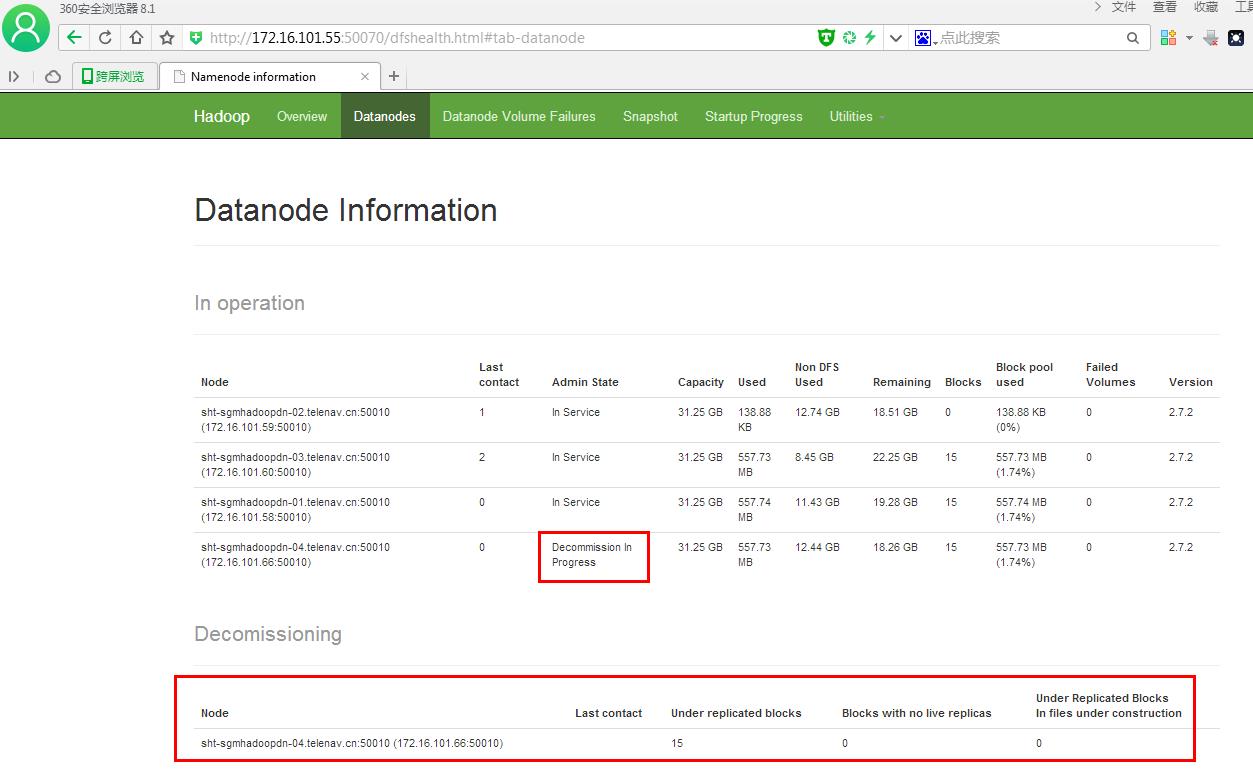
###过一会状态为Decommissioned
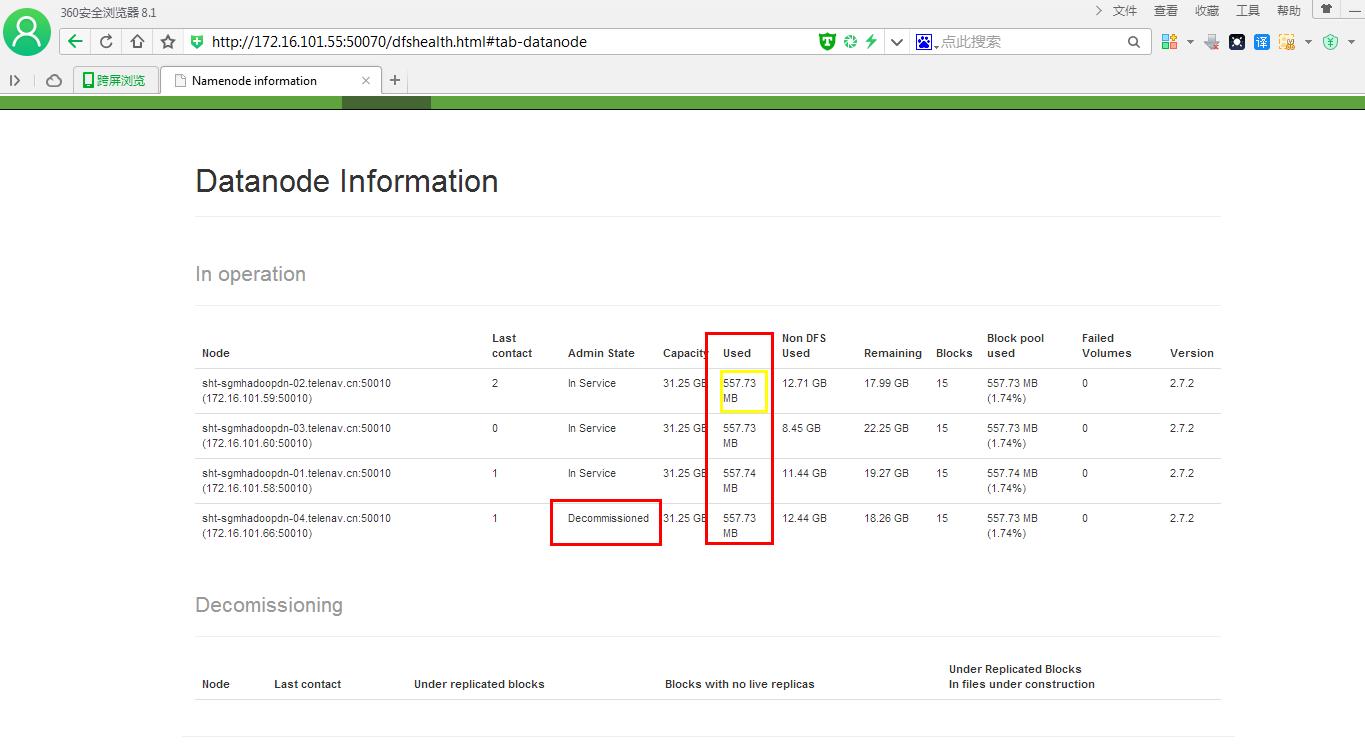
需要注意的是:
在删除节点时一定要停止所有Hadoop的Job,否则程序还会向要删除的节点同步数据,这样也会导致Decommissioned的过程一直无法完成。
8.当状态为Decommissioned后,运行命令hadoop-daemon.sh stop datanode或者直接kill -9 datanode进程
点击(此处)折叠或打开
- [root@sht-sgmhadoopdn-04 sbin]# jps
- 14508 DataNode
- 11025 Jps
- 15517 NodeManager
- [root@sht-sgmhadoopdn-04 sbin]# ./hadoop-daemon.sh stop datanode
- stopping datanode
- [root@sht-sgmhadoopdn-04 sbin]# jps
- 11056 Jps
- 15517 NodeManager
- [root@sht-sgmhadoopdn-04 sbin]#
9.由于Hadoop 2.X引入了YARN框架,所以对于每个计算节点都可以通过NodeManager进行管理,同理启动NodeManager进程后,即可将其加入集群。在新增节点,运行sbin/yarn-daemon.sh start nodemanager即可,反之手动执行命令sbin/yarn-daemon.sh stop nodemanager。在ResourceManager,通过yarn node -list查看集群情况。
点击(此处)折叠或打开
- [root@sht-sgmhadoopdn-04 sbin]# ./yarn-daemon.sh stop nodemanager
- stopping nodemanager
- [root@sht-sgmhadoopdn-01 ~]# yarn node -list
- 16/03/06 23:39:06 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
- Total Nodes:4
- Node-Id Node-State Node-Http-Address Number-of-Running-Containers
- sht-sgmhadoopdn-04.telenav.cn:54705 RUNNING sht-sgmhadoopdn-04.telenav.cn:23999 0
- sht-sgmhadoopdn-03.telenav.cn:7573 RUNNING sht-sgmhadoopdn-03.telenav.cn:23999 0
- sht-sgmhadoopdn-02.telenav.cn:38316 RUNNING sht-sgmhadoopdn-02.telenav.cn:23999 0
- sht-sgmhadoopdn-01.telenav.cn:43903 RUNNING sht-sgmhadoopdn-01.telenav.cn:23999 0
- [root@sht-sgmhadoopdn-04 sbin]# jps
- 11158 Jps
- [root@sht-sgmhadoopdn-04 sbin]#
10.【注释掉】要从集群中删除的datanode机器
点击(此处)折叠或打开
- [root@sht-sgmhadoopnn-01 hadoop]# vi allow_datanode
- sht-sgmhadoopdn-01
- sht-sgmhadoopdn-02
- sht-sgmhadoopdn-03
- #sht-sgmhadoopdn-04
- [root@sht-sgmhadoopnn-01 hadoop]# vi exclude_datanode
- #sht-sgmhadoopdn-04
- [root@sht-sgmhadoopnn-01 hadoop]# scp allow_datanode exclude_datanode root@sht-sgmhadoopnn-02:/hadoop/hadoop-2.7.2/etc/hadoop/
###这里我并不需要也注释掉slaves文件,因为dfs.hosts级别要比slaves文件要高些,当然注释掉slaves文件中sht-sgmhadoopdn-04机器也是无可厚非的!!!
###其实主要是之前的步骤,nn-01机器操作同步给nn-02了,所以在此步骤,也应当一致
疑问:怎样清除Decommissioned datanode information?通过执行hdfs dfsadmin -refreshNodes命令还是重启集群?
疑问:怎样清除Decommissioned datanode information?通过执行hdfs dfsadmin -refreshNodes命令还是重启集群?
疑问:怎样清除Decommissioned datanode information?通过执行hdfs dfsadmin -refreshNodes命令还是重启集群?
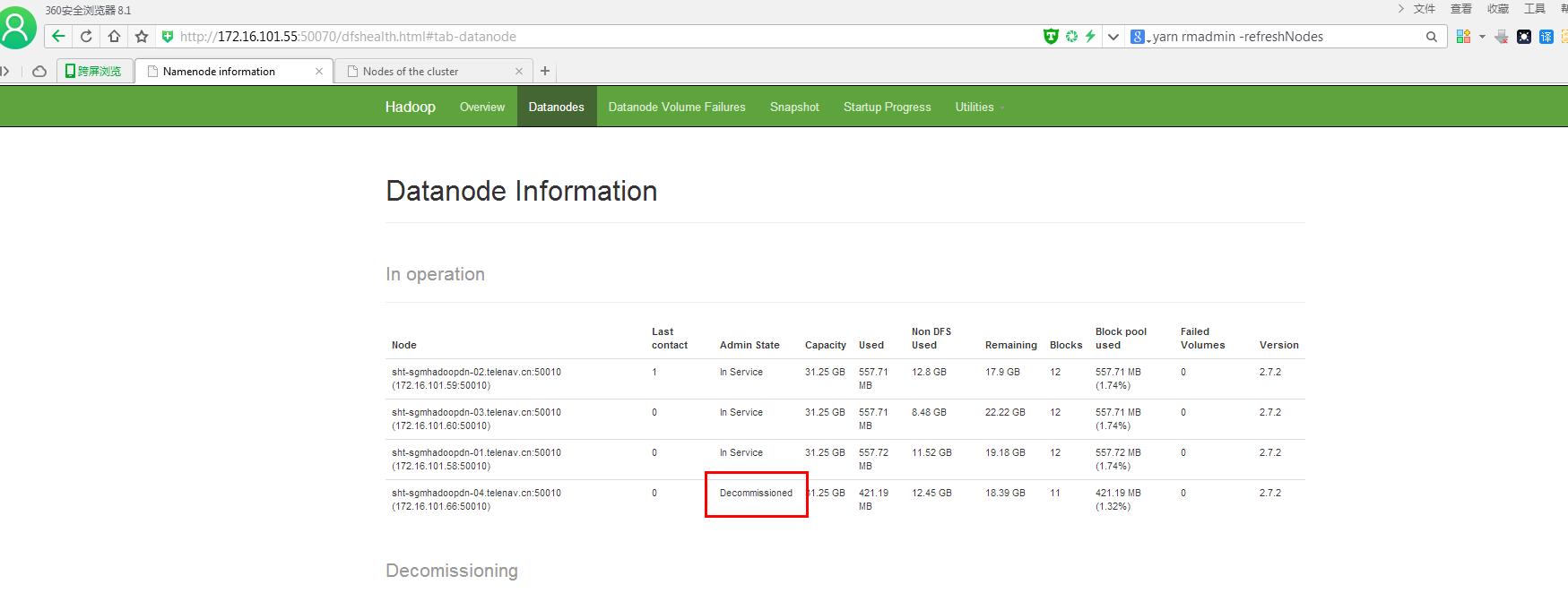
11. 第二次动态刷新配置hdfs dfsadmin –refreshNodes(正确做法,无需重启集群,适用于生产环境)
[root@sht-sgmhadoopnn-01 hadoop]# hdfs dfsadmin -refreshNodes
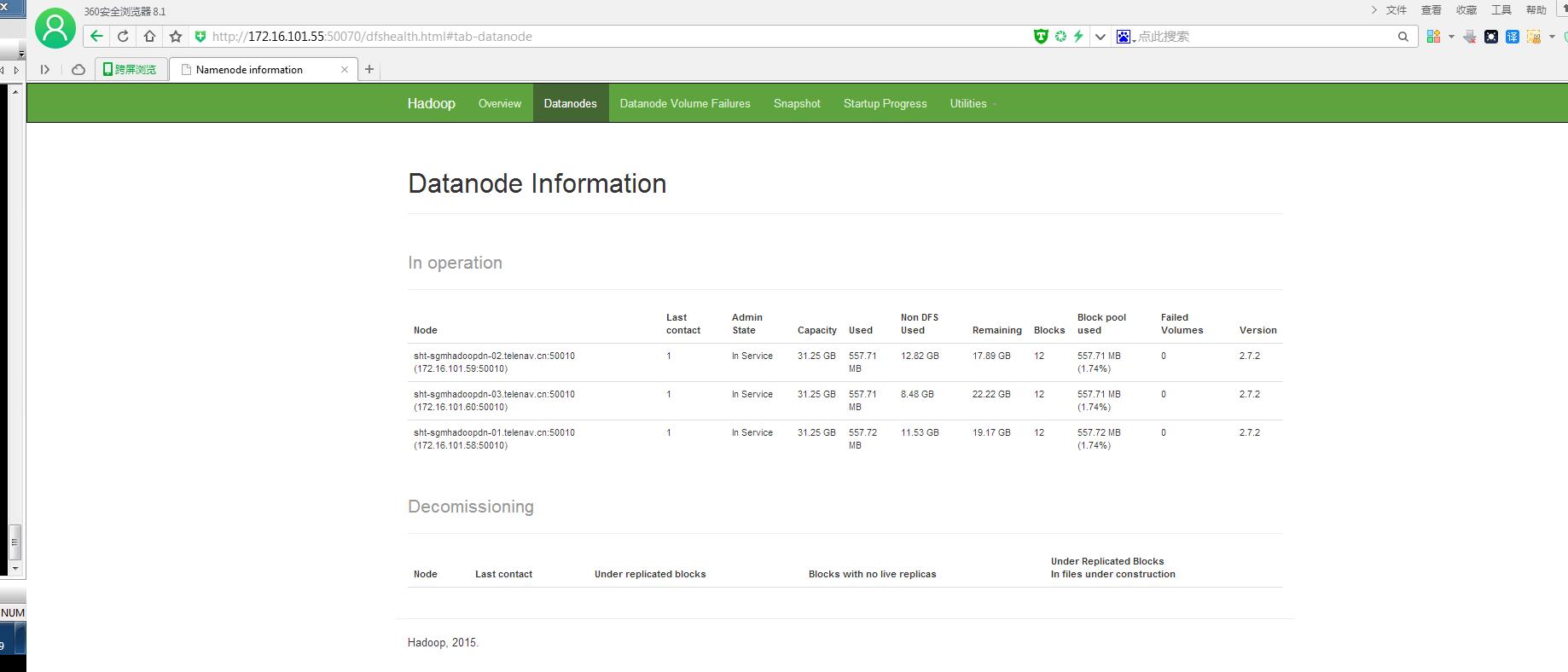
### Decommissioned datanode信息清除干净!
12.通过重启集群测试(也是正确做法,需要重启集群,不适用于生产环境,需要注释掉slaves文件中不需要连接到namenode机器)
停止集群
[root@sht-sgmhadoopnn-01 sbin]# stop-yarn.sh
[root@sht-sgmhadoopnn-02 sbin]# yarn-daemon.sh stop resourcemanager
[root@sht-sgmhadoopnn-01 sbin]# stop-dfs.sh
重启集群
[root@sht-sgmhadoopnn-01 sbin]# start-dfs.sh
[root@sht-sgmhadoopnn-01 sbin]# start-yarn.sh
[root@sht-sgmhadoopnn-02 sbin]# yarn-daemon.sh start resourcemanager
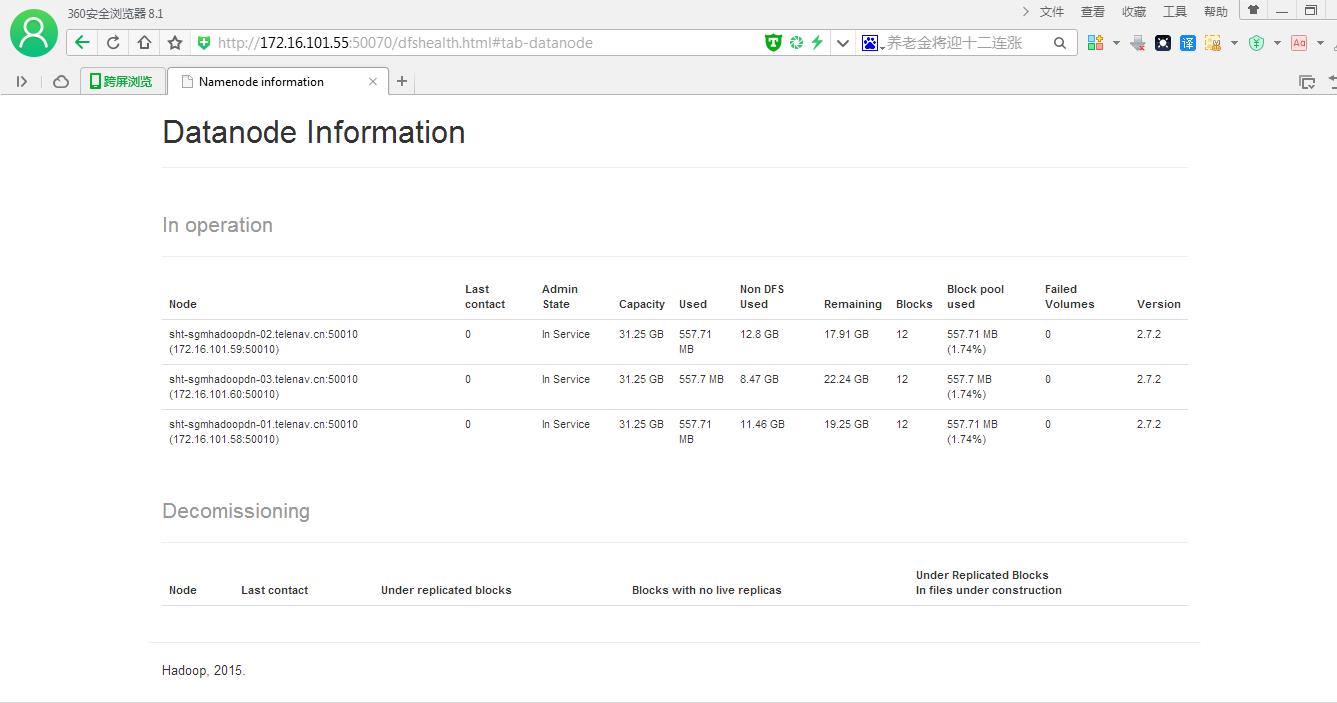
### Decommissioned datanode信息清除干净!
13.运行yarn rmadmin -refreshNodes清除sht-sgmhadoopnn-04 nodemanager信息
通过命令或者web查看:
yarn node -list
http://172.16.101.55:8088/cluster/nodes
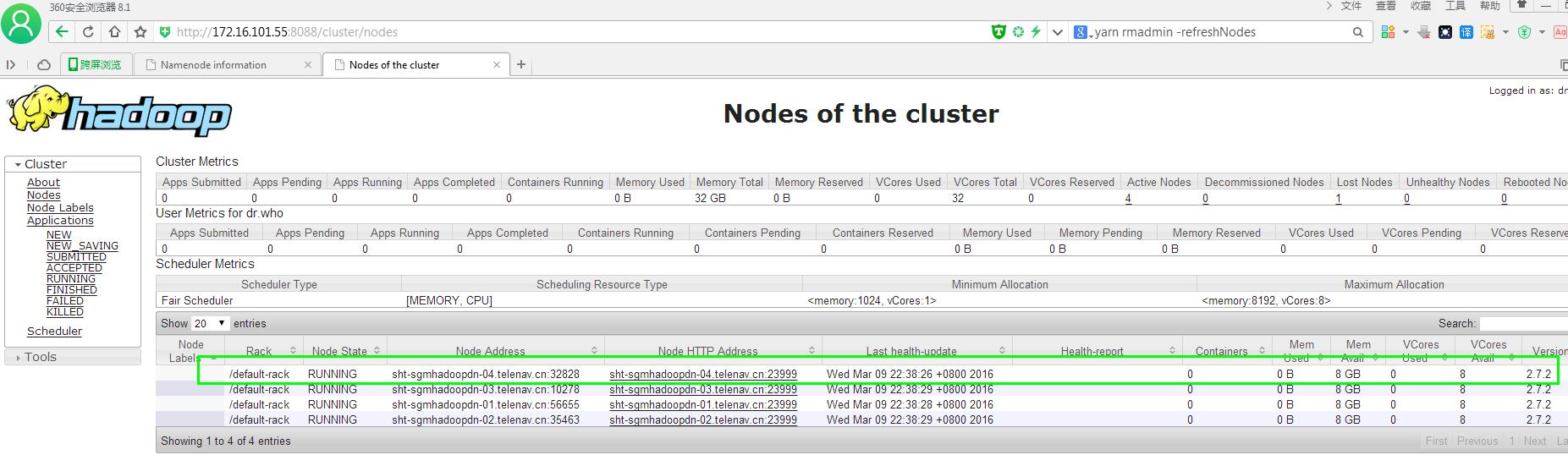
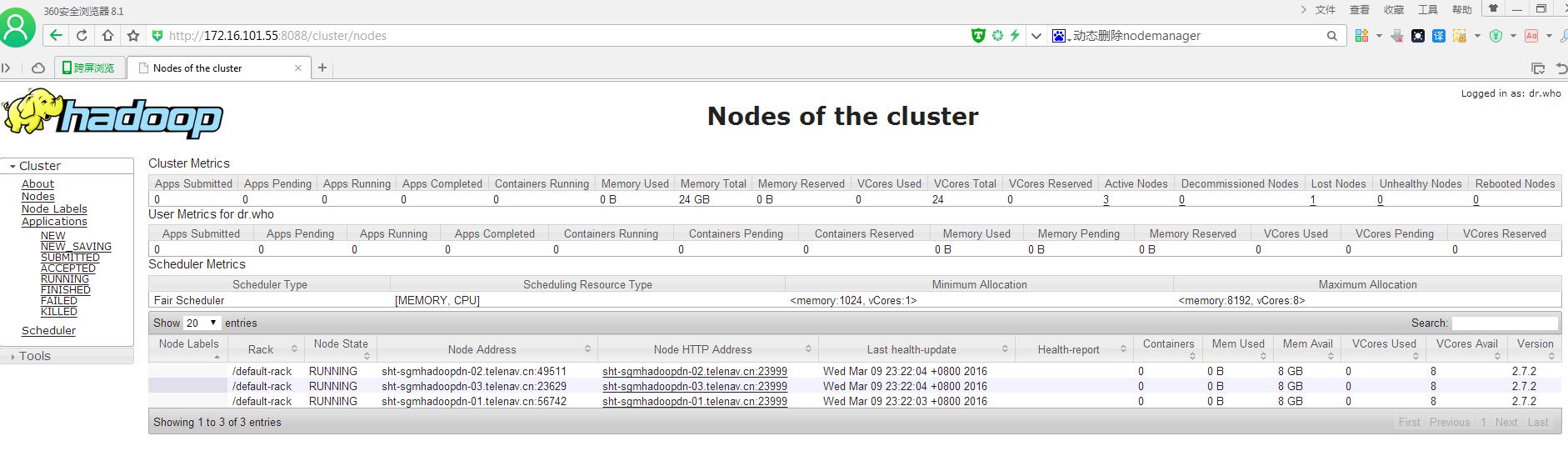
[root@sht-sgmhadoopnn-01 bin]# yarn rmadmin –refreshNodes
###刷新web
14.参数官网解释
http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
【dfs.hosts】 :
Names a file that contains a list of hosts that are permitted to connect to the namenode.
The full pathname of the file must be specified. If the value is empty, all hosts are permitted.
【dfs.hosts.exclude】 :
Names a file that contains a list of hosts that are not permitted to connect to the namenode.
The full pathname of the file must be specified. If the value is empty, no hosts are excluded.
[root@sht-sgmhadoopnn-01 hadoop]# hadoop dfsadmin -help
-refreshNodes: Updates the namenode with the set of datanodes allowed to connect to the namenode.
Namenode re-reads datanode hostnames from the file defined by
dfs.hosts, dfs.hosts.exclude configuration parameters.
Hosts defined in dfs.hosts are the datanodes that are part of
the cluster. If there are entries in dfs.hosts, only the hosts
in it are allowed to register with the namenode.
Entries in dfs.hosts.exclude are datanodes that need to be
decommissioned. Datanodes complete decommissioning when
all the replicas from them are replicated to other datanodes.
Decommissioned nodes are not automatically shutdown and
are not chosen for writing new replicas.

