1.已有环境:
Hadoop-2.7.2+zookeeper-3.4.6完全分布式环境搭建(HDFS、YARN HA)
2. 下载解压hbase-1.2.0-bin.tar.gz和设置环境HBASE_HOME变量
vi /etc/profile 增加内容如下:[集群所有节点设置]
执行 source /etc/profile
3. 修改hbase-env.sh
5.
修改regionservers文件
7.启动HBase HA
8.验证
是否已经启动hbase集群和验证who is master and who is Backup Master
1).进程和查询服务器状态
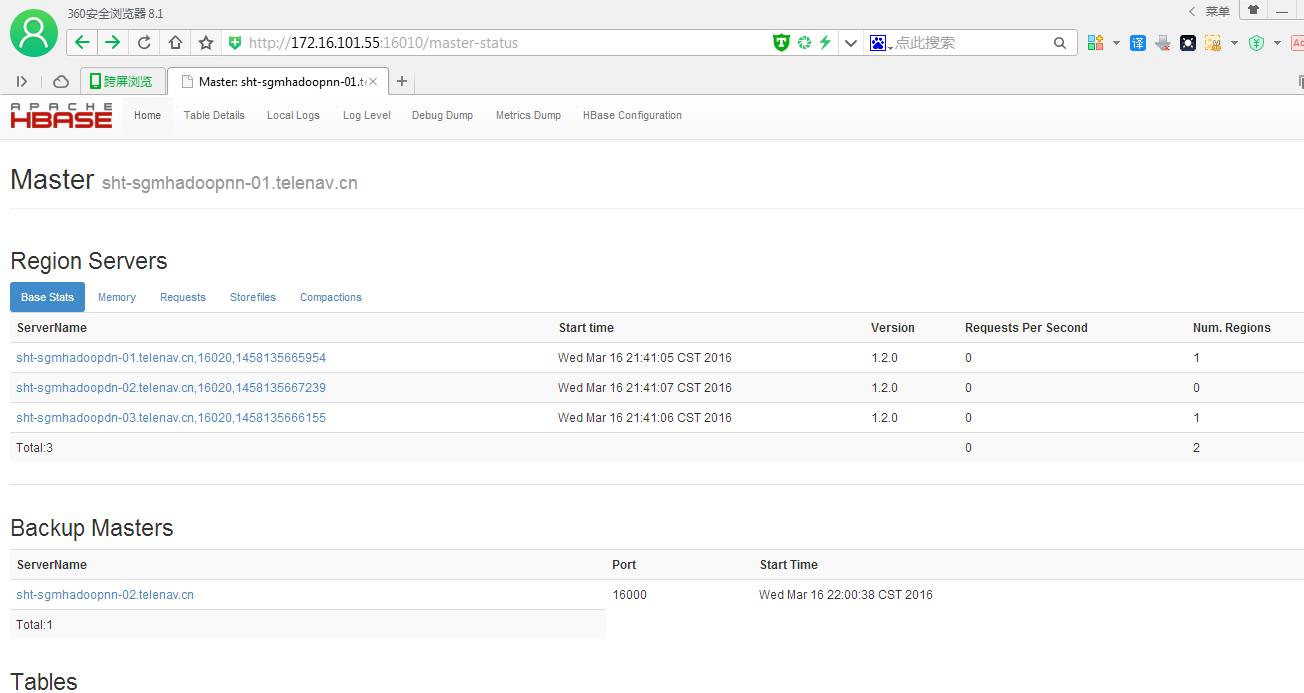
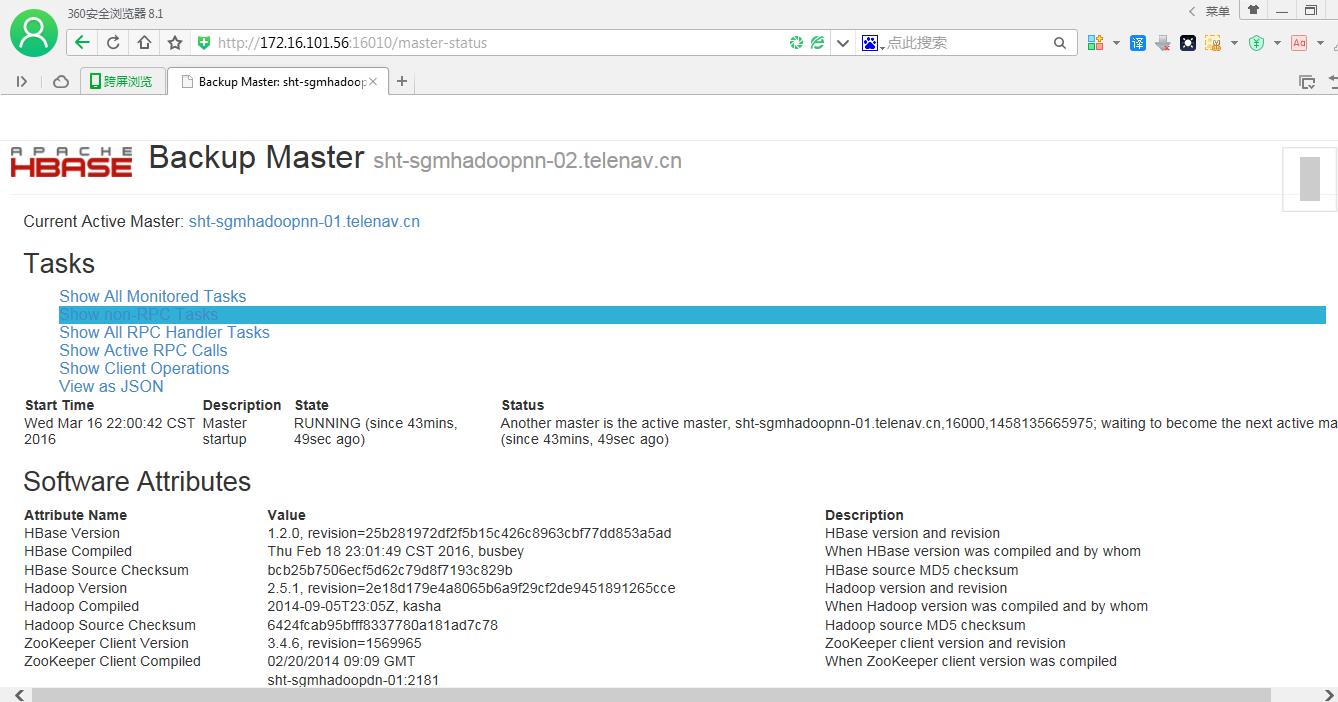
4).web 页面
2. 下载解压hbase-1.2.0-bin.tar.gz和设置环境HBASE_HOME变量
点击(此处)折叠或打开
- [root@sht-sgmhadoopnn-01 tmp]# wget http://archive.apache.org/dist/hbase/1.1.5/hbase-1.1.5-bin.tar.gz
- [root@sht-sgmhadoopnn-01 tmp]# tar -xvf hbase-1.1.5-bin.tar.gz
- [root@sht-sgmhadoopnn-01 tmp]# mv /tmp/hbase-1.1.5 /hadoop/hbase
- [root@sht-sgmhadoopnn-01 tmp]# cd /hadoop/hbase/conf
- [root@sht-sgmhadoopnn-01 conf]# pwd
- /hadoop/hbase/conf
点击(此处)折叠或打开
export HBASE_HOME=/hadoop/hbase
PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:HBASE_HOME/bin:$PATH
export $PATH
PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:HBASE_HOME/bin:$PATH
export $PATH
3. 修改hbase-env.sh
export JAVA_HOME="/usr/java/jdk1.7.0_67-cloudera"
export HBASE_CLASSPATH=/hadoop/hadoop-2.7.2/etc/hadoop
#设置到Hadoop的etc/hadoop目录是用来引导Hbase找到Hadoop,也就是说hbase和hadoop进行关联【必须设置,否则hmaster起不来】
export HBASE_MANAGES_ZK=false
#不启用hbase自带的zookeeper
4.修改hbase-site.xml
点击(此处)折叠或打开
- <configuration>
- <!--hbase.rootdir的前端与$HADOOP_HOME/conf/core-site.xml的fs.defaultFS一致 -->
- <property>
- <name>hbase.rootdir</name>
- <value>hdfs://mycluster/hbase</value>
- </property>
- <property>
- <name>hbase.cluster.distributed</name>
- <value>true</value>
- </property>
-
- <!--本地文件系统的临时文件夹。可以修改到一个更为持久的目录上。(/tmp会在重启时清除) -->
- <property>
- <name>hbase.tmp.dir</name>
- <value>/hadoop/hbase/tmp</value>
- </property>
-
- <!--如果只设置单个 Hmaster,那么 hbase.master 属性参数需要设置为 master5:60000 (主机名:60000) -->
- <!--如果要设置多个 Hmaster,那么我们只需要提供端口 60000,因为选择真正的 master 的事情会有 zookeeper 去处理 -->
- <property>
- <name>hbase.master</name>
- <value>60000</value>
- </property>
-
- <!--这个参数用户设置 ZooKeeper 快照的存储位置,默认值为 /tmp,显然在重启的时候会清空。因为笔者的 ZooKeeper 是独立安装的,所以这里路径是指向了 $ZOOKEEPER_HOME/conf/zoo.cfg 中 dataDir 所设定的位置 -->
- <property>
- <name>hbase.zookeeper.property.dataDir</name>
- <value>/hadoop/zookeeper/data</value>
- </property>
-
- <property>
- <name>hbase.zookeeper.quorum</name>
- <value>sht-sgmhadoopdn-01,sht-sgmhadoopdn-02,sht-sgmhadoopdn-03</value>
- </property>
- <!--表示客户端连接 ZooKeeper 的端口 -->
- <property>
- <name>hbase.zookeeper.property.clientPort</name>
- <value>2181</value>
- </property>
- <!--ZooKeeper 会话超时。Hbase 把这个值传递改 zk 集群,向它推荐一个会话的最大超时时间 -->
- <property>
- <name>zookeeper.session.timeout</name>
- <value>120000</value>
- </property>
-
- <!--当 regionserver 遇到 ZooKeeper session expired , regionserver 将选择 restart 而不是 abort -->
- <property>
- <name>hbase.regionserver.restart.on.zk.expire</name>
- <value>true</value>
- </property>
- </configuration>
点击(此处)折叠或打开
- sht-sgmhadoopdn-01
- sht-sgmhadoopdn-02
- sht-sgmhadoopdn-03
6.分发文件夹
点击(此处)折叠或打开
- [root@sht-sgmhadoopnn-01 hadoop]# scp -r hbase root@sht-sgmhadoopnn-02:/hadoop
- [root@sht-sgmhadoopnn-01 hadoop]# scp -r hbase root@sht-sgmhadoopdn-01:/hadoop
- [root@sht-sgmhadoopnn-01 hadoop]# scp -r hbase root@sht-sgmhadoopdn-02:/hadoop
- [root@sht-sgmhadoopnn-01 hadoop]# scp -r hbase root@sht-sgmhadoopdn-03:/hadoop
点击(此处)折叠或打开
- [root@sht-sgmhadoopnn-01 bin]# start-hbase.sh
- [root@sht-sgmhadoopnn-02 bin]# hbase-daemon.sh start master
1).进程和查询服务器状态
点击(此处)折叠或打开
##进程 [root@sht-sgmhadoopnn-01 bin]# jps
20519 NameNode
18925 Jps
20872 DFSZKFailoverController
26810 ResourceManager
13564 HMaster
[root@sht-sgmhadoopnn-02 logs]# jps
5265 NameNode
5449 DFSZKFailoverController
26319 Jps
12281 ResourceManager
21879 HMaster
[root@sht-sgmhadoopdn-01 bin]# jps
30488 QuorumPeerMain
25780 NodeManager
20286 DataNode
996 HRegionServer
6371 Jps
20399 JournalNode
### sht-sgmhadoopdn-02,03与01一样
##查询服务器状态 [root@sht-sgmhadoopnn-01 bin]# hbase shell 2016-03-16 22:55:36,551 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
HBase Shell; enter 'help' for list of supported commands.
Type "exit" to leave the HBase Shell
Version 1.2.0, r25b281972df2f5b15c426c8963cbf77dd853a5ad, Thu Feb 18 23:01:49 CST 2016
hbase(main):001:0> status 1 active master, 1 backup masters, 3 servers, 0 dead, 0.6667 average load
20519 NameNode
18925 Jps
20872 DFSZKFailoverController
26810 ResourceManager
13564 HMaster
[root@sht-sgmhadoopnn-02 logs]# jps
5265 NameNode
5449 DFSZKFailoverController
26319 Jps
12281 ResourceManager
21879 HMaster
[root@sht-sgmhadoopdn-01 bin]# jps
30488 QuorumPeerMain
25780 NodeManager
20286 DataNode
996 HRegionServer
6371 Jps
20399 JournalNode
### sht-sgmhadoopdn-02,03与01一样
##查询服务器状态 [root@sht-sgmhadoopnn-01 bin]# hbase shell 2016-03-16 22:55:36,551 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
HBase Shell; enter 'help' for list of supported commands.
Type "exit" to leave the HBase Shell
Version 1.2.0, r25b281972df2f5b15c426c8963cbf77dd853a5ad, Thu Feb 18 23:01:49 CST 2016
hbase(main):001:0> status 1 active master, 1 backup masters, 3 servers, 0 dead, 0.6667 average load
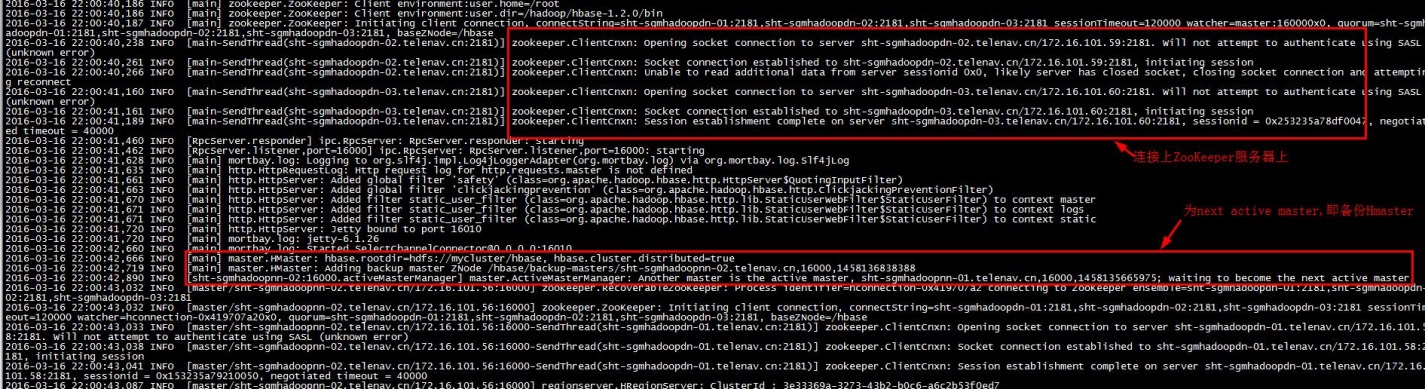
2).查看日志
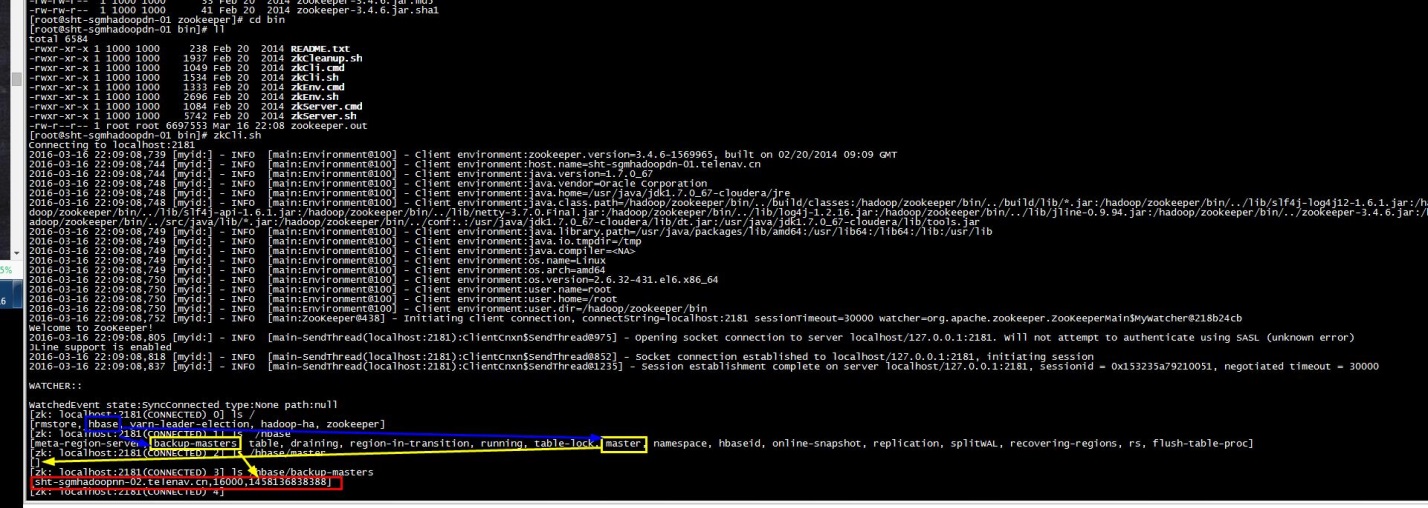
3).登录zookeeper
4).web 页面
why http://server:60010 web page for the running HBase1.1.5 Master???
After the 0.98 version port numbers have changed. It is now 16010 instead of 60010). Check this page for general UI troubleshooting: http://hbase.apache.org/book/trouble.tools.html