问题现象
- 在zabbix系统中,对Hadoop集群的历史监控数据分析时,发现在执行大Job任务时,某些服务节点的cpu sys态很高;
- 具体以hadoop_A服务节点为例,在10:15-10:40这个时间段,cpu user态为60%,而sys态则高达35%;
- 对于整个Hadoop集群,并不是所有的节点都会出现sys过高的问题,产生此类问题的都是部署CentOS6系统的节点。
定位分析
- 根据zabbix系统中cpu sys很高的问题发生时间,找到触发问题的大Job,以便于后面的问题重现和问题验证;
- 对问题节点hadoop_A的硬件信息和OS系统日志/var/log/messages进行初步检查,并未发现异常;
- 重启Job,重现问题。并使用nmon工具对问题节点hadoop_A的资源负载进行粗粒度的实时监测;
hadoop_A节点上某一时刻瞬时的负载状态如下图: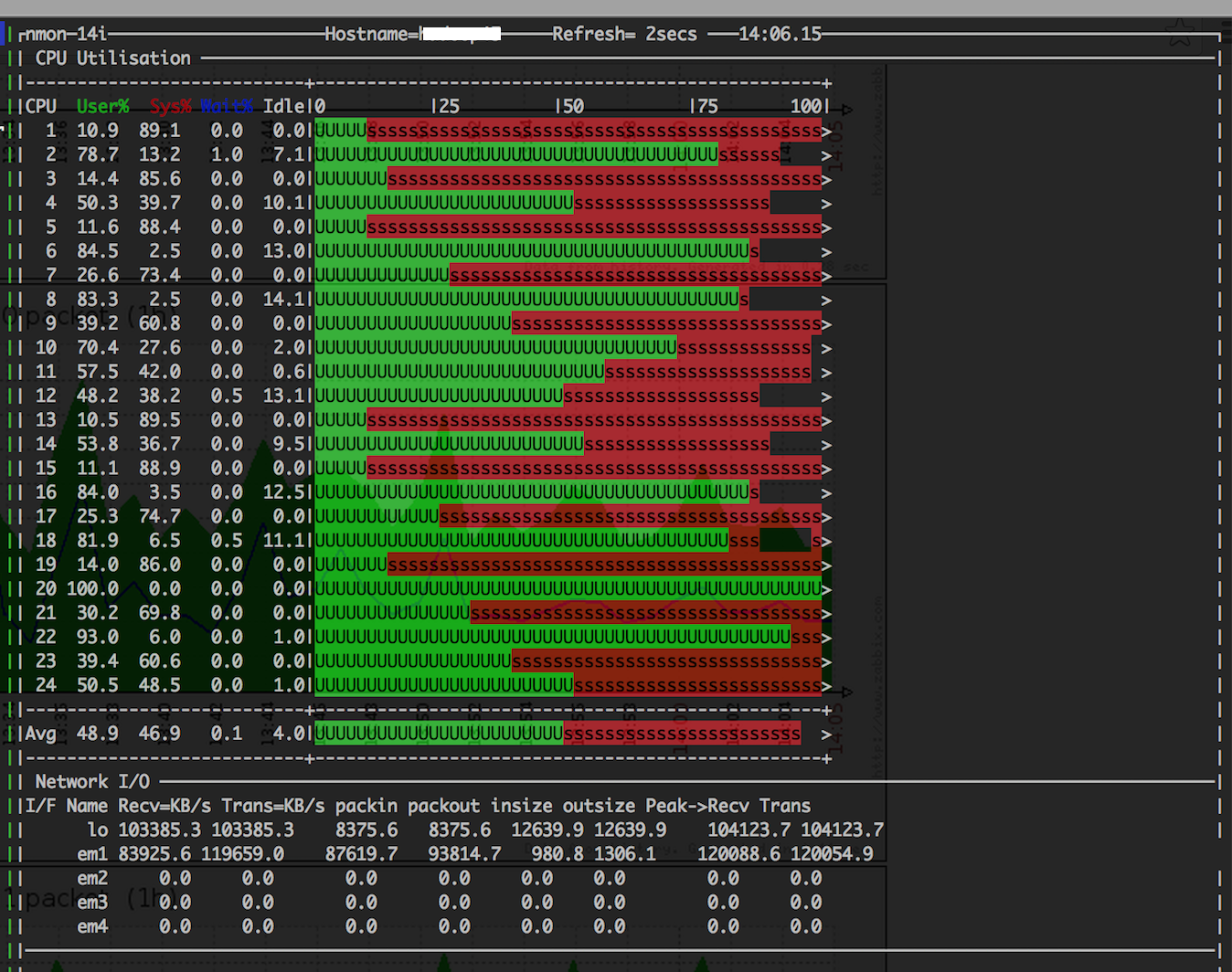
- 通过上图,注意到网络流量达到了119.7MB/s,接收和发送的峰值都超过了120MB/s,初步怀疑网口在某一时间成为瓶颈,导致内核的sys过高。对hadoop_A的网口计数器细化分析,系统在uptime了83天的状态下,网口计数器中除overruns指标达22万之外,其他的网络指标正常。 这说明网络确实曾达到过峰值,也丢过包,但频率非常低,sys过高的问题应该不是网络负载过高触发。
ifconfig查询网口的计数器状态如下图: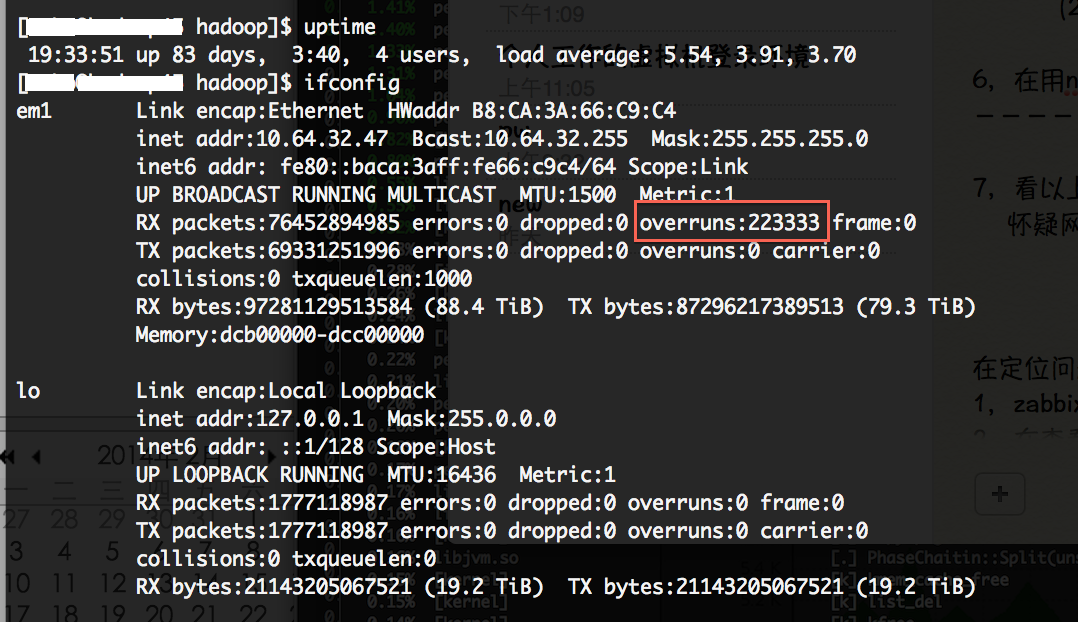
- 需要对系统进行更细粒度的分析,找出系统sys态消耗在什么地方。在hadoop_A节点上部署perf工具,通过perf top对kernel事件采样,实时分析内核事件。
perf top在某一时刻的状态图如下: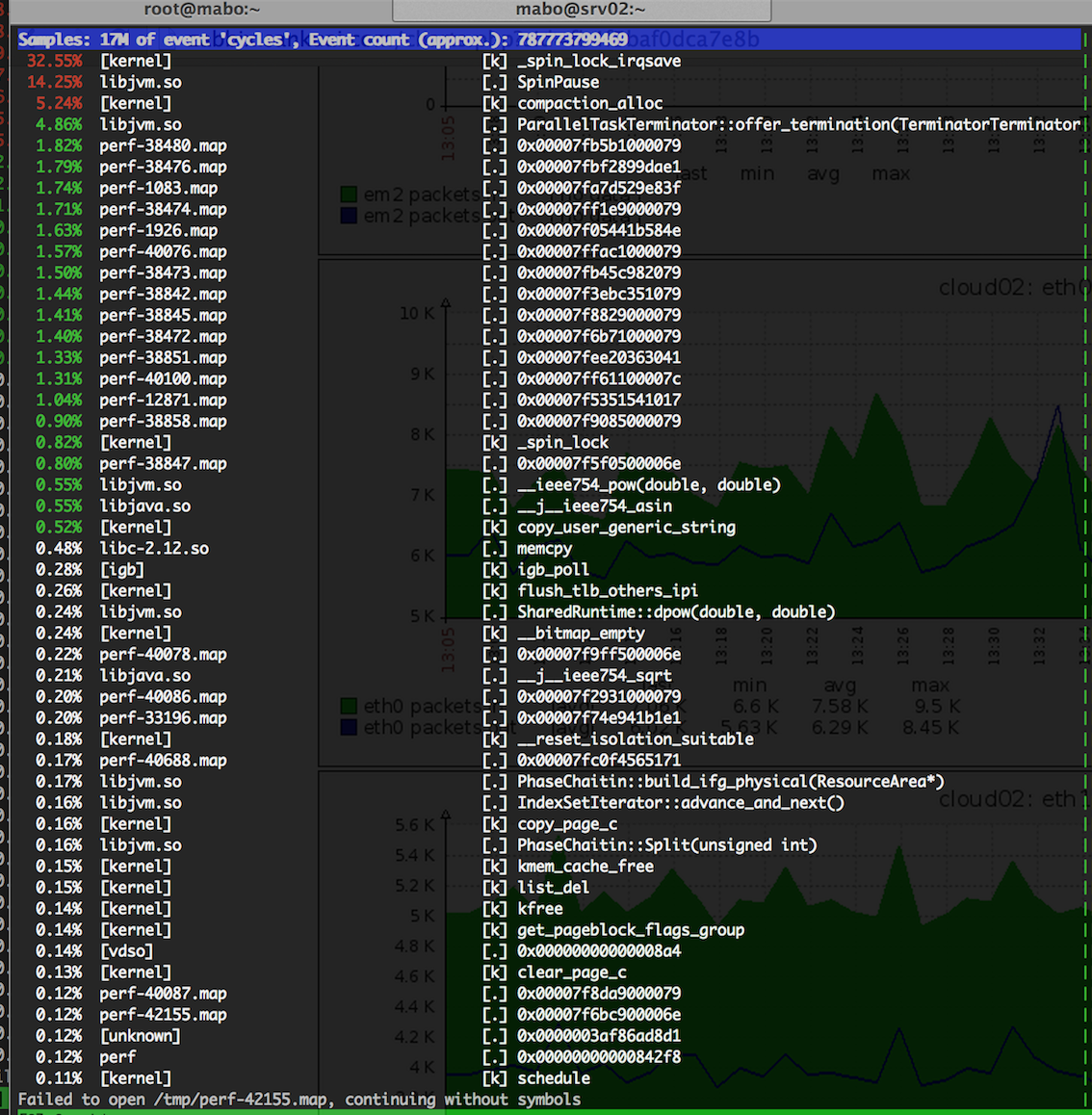
通过perf top监控可以断定:kernel中存在频繁的spin_lock_irqsave内核系统调用, sys态消耗过高应该与此有关。 - 重启Job,再次重现问题,并利用perf工具对内核函数的调用关系采样:
perf record -a -g -F 1000 sleep 30
采样结束后,在当前目录上会生成一个perf.data文件,使用perf工具查看函数调用关系:
perf report -g
perf report查看到的调用关系如下图: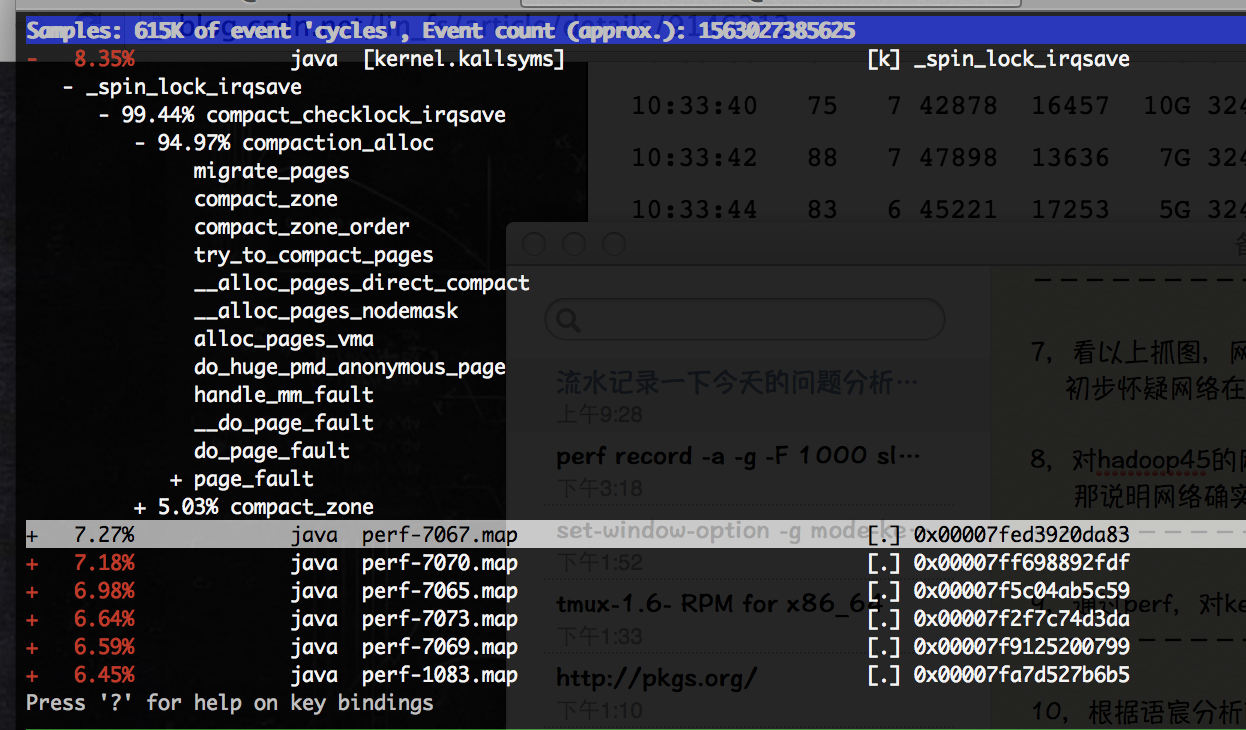
- 通过调用依赖关系分析,spin_lock_irqsave主要called by compaction_alloc,初步推测问题由kernel的内存管理部分触发。联想到centos 6相对于centos 5在kernel内存管理模块的一些改进点(如transparent huge page, 基于numa的内存分配等),有没有可能是CentOS6新增的THP特性导致cpu sys过高?再在google上搜一把相关函数名的关键字,印证这个猜测。
问题验证
- 选择在节点hadoop_A上面做验证测试,通过以下内核参数优化关闭系统THP特性:
echo never > /sys/kernel/mm/redhat_transparent_hugepage/enabled echo never > /sys/kernel/mm/redhat_transparent_hugepage/defrag
- 重启触发问题的大Job,在hadoop_A节点未出现cpu sys 状态过高的现象。
- 在生产系统上运行24小时后,通过zabbix系统观察,其他内核未优化节点如hadoop_B,hadoop_C等节点依然存在cpu sys态过高的问题,而关闭了THP特性的hadoop_A节点没有出现cpu sys态过高的问题,验证了之前的分析。
hadoop_B和hadoop_C依然存在cpu sys态过高的问题: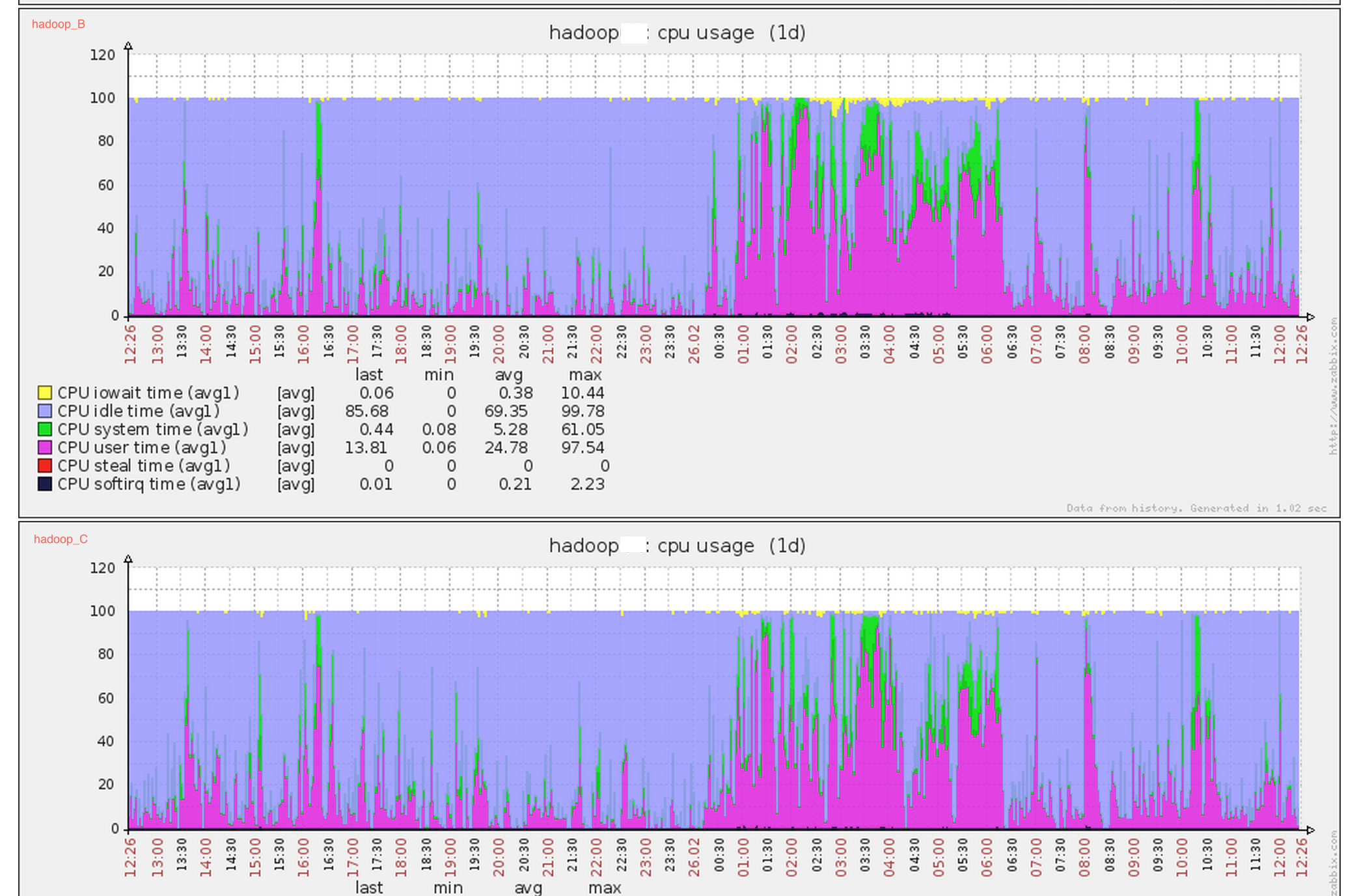
hadoop_A cpu sys态正常: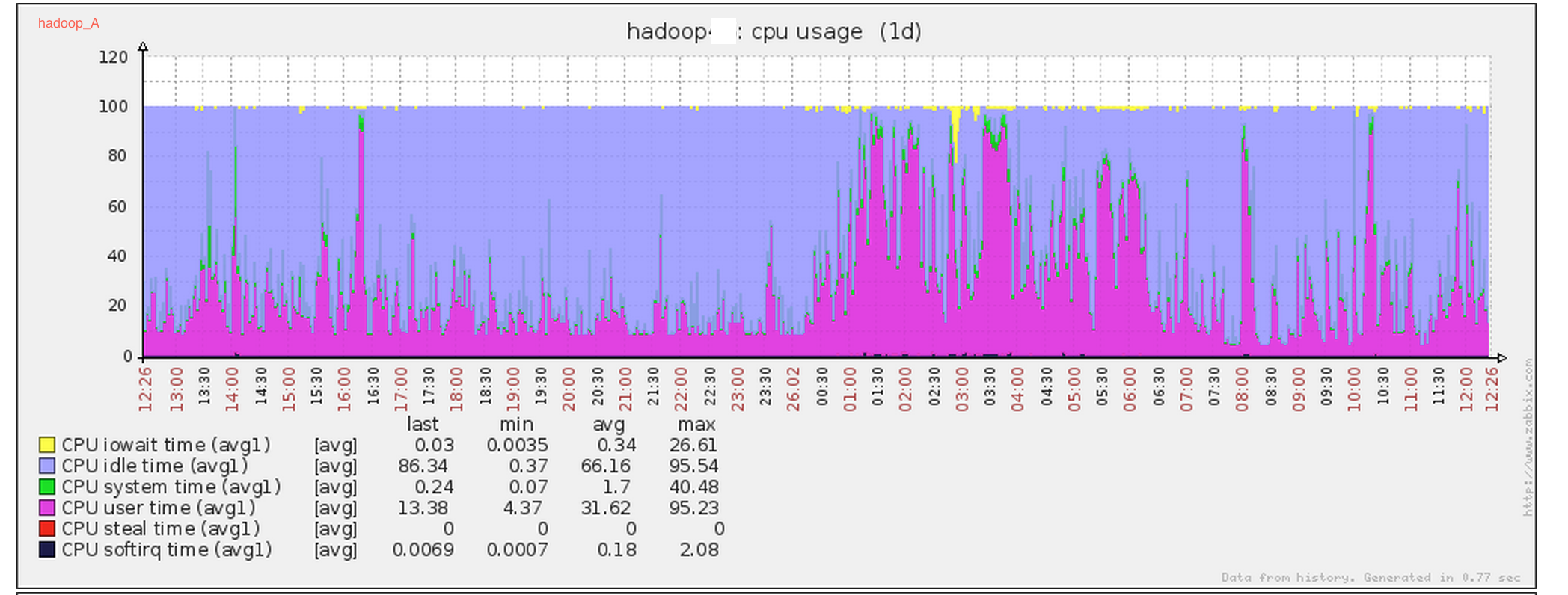
结论
将Hadoop集群中所有CentOS6类型节点的THP特性关闭掉(在CentOS6中,THP特性默认都是打开的),关闭方法如下:
echo never > /sys/kernel/mm/redhat_transparent_hugepage/enabled echo never > /sys/kernel/mm/redhat_transparent_hugepage/defrag
值得注意的是,需要在puppet系统中部署该项优化,以免节点重启导致修改丢失。
参考
事后,在redhat官网和cloudera官网也搜到了相关的内容,附录下来,供参考。
- 在redhat的官网上,有对THP特性的细化说明:
https://access.redhat.com/site/documentation/en-US/Red_Hat_Enterprise_Linux/6/html/Performance_Tuning_Guide/s-memory-transhuge.html - 在cloudera的CDH4部署说明中,也建议将系统的THP的compaction特性关闭:
http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH4/4.2.2/CDH4-Installation-Guide/cdh4ig_topic_11_6.html
转: http://tech.meituan.com/cpu_sys_high_in_hadoop_cluster.html