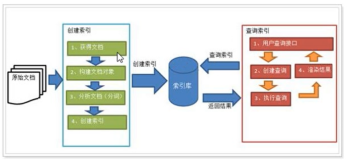
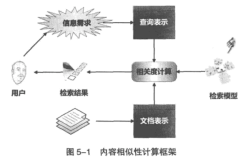
package src;
import java.io.StringReader;
import java.util.Date;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.SimpleAnalyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.cjk.CJKAnalyzer;
import org.apache.lucene.analysis.cn.ChineseAnalyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.DateField;
import org.apache.lucene.document.DateTools;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryParser.MultiFieldQueryParser;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.BooleanClause;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.FuzzyQuery;
import org.apache.lucene.search.Hits;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.QueryFilter;
import org.apache.lucene.search.RangeQuery;
import org.apache.lucene.search.Sort;
import org.apache.lucene.search.SortField;
import java.util.Date;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.Hits;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.search.highlight.QueryScorer;
import org.apache.lucene.search.highlight.SimpleFragmenter;
import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
public class LuceneSearch {
public static void main(String[] args) throws Exception{
LuceneSearch test = new LuceneSearch();
//
Hits h = null;
h = test.search("显示 ");
test.printResult(h);
h = test.search("jy");
test.printResult(h);
h = test.search("djy");
test.printResult(h);
h = test.search("料不");
test.printResult(h);
h = test.search("人");
test.printResult(h);
}
public LuceneSearch(){
try{
searcher = new IndexSearcher(IndexReader.open("E://lucene//test4//index"));
}catch(Exception e){
e.printStackTrace();
}
}
//声明一个IndexSearcher对象
private IndexSearcher searcher = null;
//声明一个Query对象
private Query query = null;
ChineseAnalyzer analyzer = new ChineseAnalyzer();
Highlighter highlighter = null;
public final Hits search(String keyword){
System.out.println("正在检索关键字:"+keyword);
try{
Date start = new Date();
/***** 一个关键字,对一个字段进行查询 *****/
QueryParser qp = new QueryParser("content",analyzer);
query = qp.parse(keyword);
// Hits hits = searcher.search(query);
/***** 模糊查询 *****/
// Term term = new Term("content",keyword);
// FuzzyQuery fq = new FuzzyQuery(term);
// Hits hits = searcher.search(fq);
/***** 一个关键字,在两个字段中查询 *****/
/*
* 1.BooleanClause.Occur[]的三种类型:
* MUST : + and
* MUST_NOT : - not
* SHOULD : or
* 2.下面查询的意思是:content中必须包含该关键字,而title有没有都无所谓
* 3.下面的这个查询中,Occur[]的长度必须和Fields[]的长度一致。每个限制条件对应一个字段
*/
// BooleanClause.Occur[] flags = new BooleanClause.Occur[]{BooleanClause.Occur.SHOULD,BooleanClause.Occur.MUST};
// query=MultiFieldQueryParser.parse(keyword,new String[]{"title","content"},flags,analyzer);
/***** 两个(多个)关键字对两个(多个)字段进行查询,默认匹配规则 *****/
/*
* 1.关键字的个数必须和字段的个数相等
* 2.由于没有指定匹配规定,默认为"SHOULD"
* 因此,下面查询的意思是:"title"中含有keyword1 或 "content"含有keyword2.
* 在此例中,把keyword1和keyword2相同
*/
// query=MultiFieldQueryParser.parse(new String[]{keyword,keyword},new String[]{"title","content"},analyzer);
/***** 两个(多个)关键字对两个(多个)字段进行查询,手工指定匹配规则 *****/
/*
* 1.必须 关键字的个数 == 字段名的个数 == 匹配规则的个数
* 2.下面查询的意思是:"title"必须不含有keyword1,并且"content"中必须含有keyword2
*/
// BooleanClause.Occur[] flags = new BooleanClause.Occur[]{BooleanClause.Occur.MUST_NOT,BooleanClause.Occur.MUST};
// query=MultiFieldQueryParser.parse(new String[]{keyword,keyword},new String[]{"title","content"},flags,analyzer);
/***** 对日期型字段进行查询 *****/
/***** 对数字范围进行查询 *****/
/*
* 1.两个条件必须是同一个字段
* 2.前面一个条件必须比后面一个条件小,否则找不到数据
* 3.new RangeQuery中的第三个参数,表示是否包含"="
* true: >= 或 <=
* false: > 或 <
* 4.找出 55>=id>=53 or 60>=id>=57:
*/
// Term lowerTerm1 = new Term("id","53");
// Term upperTerm1 = new Term("id","55");
// RangeQuery rq1 = new RangeQuery(lowerTerm1,upperTerm1,true);
//
// Term lowerTerm2 = new Term("id","57");
// Term upperTerm2 = new Term("id","60");
// RangeQuery rq2 = new RangeQuery(lowerTerm2,upperTerm2,true);
//
// BooleanQuery bq = new BooleanQuery();
// bq.add(rq1,BooleanClause.Occur.SHOULD);
// bq.add(rq2,BooleanClause.Occur.SHOULD);
//手工拼范围
// query = QueryParser.Parse("{200004 TO 200206}", "pubmonth", new SimpleAnalyzer());
// Lucene用[] 和{}分别表示包含和不包含.
//String temp = "startDate:["+nextWeek[0]+" TO "+nextWeek[1]+"] ";
// temp = temp + " OR endDate:["+nextWeek[0]+" TO "+nextWeek[1]+"]";
// Query query1 = qp.parse(temp);
// Hits hits = searcher.search(bq);
/***** 排序 *****/
/*
* 1.被排序的字段必须被索引过(Indexecd),在索引时不能 用 Field.Index.TOKENIZED
* (用UN_TOKENIZED可以正常实现.用NO时查询正常,但排序不能正常设置升降序)
* 2.SortField类型
* SCORE、DOC、AUTO、STRING、INT、FLOAT、CUSTOM
* 此类型主要是根据字段的类型选择
* 3.SortField的第三个参数代表是否是降序
* true:降序 false:升序
*/
// Sort sort = new Sort(new SortField[]{new SortField("id", SortField.INT, true)});
// Hits hits = searcher.search(query,sort);
/*
* 按日期排序
*/
// Sort sort = new Sort(new SortField[]{new SortField("createTime", SortField.INT, false)});
/***** 过滤器 ******/
// QueryParser qp1 = new QueryParser("content",analyzer);
// Query fquery = qp1.parse("我");
//
// BooleanQuery bqf = new BooleanQuery();
// bqf.add(fquery,BooleanClause.Occur.SHOULD);
//
// QueryFilter qf = new QueryFilter(bqf);
Hits hits = searcher.search(query);
Date end = new Date();
System.out.println("检索完成,用时"+(end.getTime()-start.getTime())+"毫秒");
return hits;
}catch(Exception e){
e.printStackTrace();
return null;
}
}
public void printResult(Hits h){
if(h.length() == 0){
System.out.println("对不起,没有找到您要的结果.");
}else{
for(int i = 0; i < h.length(); i++){
try{
Document doc = h.doc(i);
System.out.println("结果"+(i+1)+":"+doc.get("id")+" createTime:"+doc.get("createTime")+" title:"+doc.get("title")+" content:"+doc.get("content"));
//System.out.println(doc.get("path"));
}catch(Exception e){
e.printStackTrace();
}
}
}
System.out.println("--------------------------------------");
}
}
需要说明的一点是,本例用到了Chinese分析器,需要导入相应的包!
import java.io.StringReader;
import java.util.Date;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.SimpleAnalyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.cjk.CJKAnalyzer;
import org.apache.lucene.analysis.cn.ChineseAnalyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.DateField;
import org.apache.lucene.document.DateTools;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryParser.MultiFieldQueryParser;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.BooleanClause;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.FuzzyQuery;
import org.apache.lucene.search.Hits;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.QueryFilter;
import org.apache.lucene.search.RangeQuery;
import org.apache.lucene.search.Sort;
import org.apache.lucene.search.SortField;
import java.util.Date;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.Hits;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.search.highlight.QueryScorer;
import org.apache.lucene.search.highlight.SimpleFragmenter;
import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
public class LuceneSearch {
public static void main(String[] args) throws Exception{
LuceneSearch test = new LuceneSearch();
//
Hits h = null;
h = test.search("显示 ");
test.printResult(h);
h = test.search("jy");
test.printResult(h);
h = test.search("djy");
test.printResult(h);
h = test.search("料不");
test.printResult(h);
h = test.search("人");
test.printResult(h);
}
public LuceneSearch(){
try{
searcher = new IndexSearcher(IndexReader.open("E://lucene//test4//index"));
}catch(Exception e){
e.printStackTrace();
}
}
//声明一个IndexSearcher对象
private IndexSearcher searcher = null;
//声明一个Query对象
private Query query = null;
ChineseAnalyzer analyzer = new ChineseAnalyzer();
Highlighter highlighter = null;
public final Hits search(String keyword){
System.out.println("正在检索关键字:"+keyword);
try{
Date start = new Date();
/***** 一个关键字,对一个字段进行查询 *****/
QueryParser qp = new QueryParser("content",analyzer);
query = qp.parse(keyword);
// Hits hits = searcher.search(query);
/***** 模糊查询 *****/
// Term term = new Term("content",keyword);
// FuzzyQuery fq = new FuzzyQuery(term);
// Hits hits = searcher.search(fq);
/***** 一个关键字,在两个字段中查询 *****/
/*
* 1.BooleanClause.Occur[]的三种类型:
* MUST : + and
* MUST_NOT : - not
* SHOULD : or
* 2.下面查询的意思是:content中必须包含该关键字,而title有没有都无所谓
* 3.下面的这个查询中,Occur[]的长度必须和Fields[]的长度一致。每个限制条件对应一个字段
*/
// BooleanClause.Occur[] flags = new BooleanClause.Occur[]{BooleanClause.Occur.SHOULD,BooleanClause.Occur.MUST};
// query=MultiFieldQueryParser.parse(keyword,new String[]{"title","content"},flags,analyzer);
/***** 两个(多个)关键字对两个(多个)字段进行查询,默认匹配规则 *****/
/*
* 1.关键字的个数必须和字段的个数相等
* 2.由于没有指定匹配规定,默认为"SHOULD"
* 因此,下面查询的意思是:"title"中含有keyword1 或 "content"含有keyword2.
* 在此例中,把keyword1和keyword2相同
*/
// query=MultiFieldQueryParser.parse(new String[]{keyword,keyword},new String[]{"title","content"},analyzer);
/***** 两个(多个)关键字对两个(多个)字段进行查询,手工指定匹配规则 *****/
/*
* 1.必须 关键字的个数 == 字段名的个数 == 匹配规则的个数
* 2.下面查询的意思是:"title"必须不含有keyword1,并且"content"中必须含有keyword2
*/
// BooleanClause.Occur[] flags = new BooleanClause.Occur[]{BooleanClause.Occur.MUST_NOT,BooleanClause.Occur.MUST};
// query=MultiFieldQueryParser.parse(new String[]{keyword,keyword},new String[]{"title","content"},flags,analyzer);
/***** 对日期型字段进行查询 *****/
/***** 对数字范围进行查询 *****/
/*
* 1.两个条件必须是同一个字段
* 2.前面一个条件必须比后面一个条件小,否则找不到数据
* 3.new RangeQuery中的第三个参数,表示是否包含"="
* true: >= 或 <=
* false: > 或 <
* 4.找出 55>=id>=53 or 60>=id>=57:
*/
// Term lowerTerm1 = new Term("id","53");
// Term upperTerm1 = new Term("id","55");
// RangeQuery rq1 = new RangeQuery(lowerTerm1,upperTerm1,true);
//
// Term lowerTerm2 = new Term("id","57");
// Term upperTerm2 = new Term("id","60");
// RangeQuery rq2 = new RangeQuery(lowerTerm2,upperTerm2,true);
//
// BooleanQuery bq = new BooleanQuery();
// bq.add(rq1,BooleanClause.Occur.SHOULD);
// bq.add(rq2,BooleanClause.Occur.SHOULD);
//手工拼范围
// query = QueryParser.Parse("{200004 TO 200206}", "pubmonth", new SimpleAnalyzer());
// Lucene用[] 和{}分别表示包含和不包含.
//String temp = "startDate:["+nextWeek[0]+" TO "+nextWeek[1]+"] ";
// temp = temp + " OR endDate:["+nextWeek[0]+" TO "+nextWeek[1]+"]";
// Query query1 = qp.parse(temp);
// Hits hits = searcher.search(bq);
/***** 排序 *****/
/*
* 1.被排序的字段必须被索引过(Indexecd),在索引时不能 用 Field.Index.TOKENIZED
* (用UN_TOKENIZED可以正常实现.用NO时查询正常,但排序不能正常设置升降序)
* 2.SortField类型
* SCORE、DOC、AUTO、STRING、INT、FLOAT、CUSTOM
* 此类型主要是根据字段的类型选择
* 3.SortField的第三个参数代表是否是降序
* true:降序 false:升序
*/
// Sort sort = new Sort(new SortField[]{new SortField("id", SortField.INT, true)});
// Hits hits = searcher.search(query,sort);
/*
* 按日期排序
*/
// Sort sort = new Sort(new SortField[]{new SortField("createTime", SortField.INT, false)});
/***** 过滤器 ******/
// QueryParser qp1 = new QueryParser("content",analyzer);
// Query fquery = qp1.parse("我");
//
// BooleanQuery bqf = new BooleanQuery();
// bqf.add(fquery,BooleanClause.Occur.SHOULD);
//
// QueryFilter qf = new QueryFilter(bqf);
Hits hits = searcher.search(query);
Date end = new Date();
System.out.println("检索完成,用时"+(end.getTime()-start.getTime())+"毫秒");
return hits;
}catch(Exception e){
e.printStackTrace();
return null;
}
}
public void printResult(Hits h){
if(h.length() == 0){
System.out.println("对不起,没有找到您要的结果.");
}else{
for(int i = 0; i < h.length(); i++){
try{
Document doc = h.doc(i);
System.out.println("结果"+(i+1)+":"+doc.get("id")+" createTime:"+doc.get("createTime")+" title:"+doc.get("title")+" content:"+doc.get("content"));
//System.out.println(doc.get("path"));
}catch(Exception e){
e.printStackTrace();
}
}
}
System.out.println("--------------------------------------");
}
}
需要说明的一点是,本例用到了Chinese分析器,需要导入相应的包!