热门
【机器学习】在使用K-means聚类算法时,如何选择K的值?
【机器学习】为什么K-means算法使用欧式距离度量?
【机器学习】描述K-means算法的步骤
【机器学习】K-means聚类的停止标准是什么?
【机器学习】解释什么是K-means聚类?
【机器学习】K-means和KNN算法有什么区别?
【机器学习】K-means聚类有哪些应用?
【机器学习】贝叶斯统计中,“先验概率”和“后验概率”的区别?
SQL脚本把多行SQL数据变成一条多列数据
Go语言学习12-数据的使用
好看的html网站维护源码
50
49
48
47
46
45
基于51单片机的车辆倒车雷达报警系统
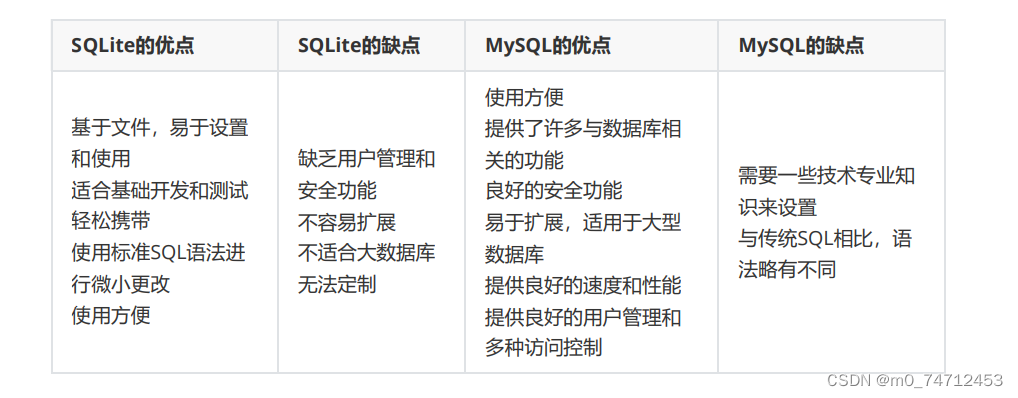
SQLite数据库介绍以及安装
linux守护进程介绍 | Linux的热拔插UDEV机制
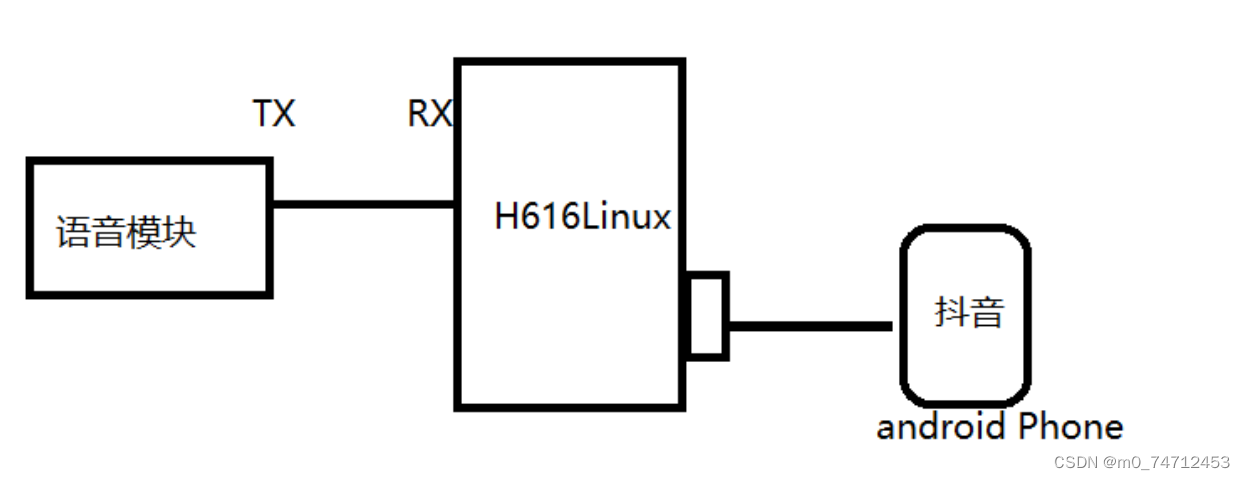
基于linux串口实现语音刷抖音
SU-03T语音模块的使用
用Source Insight软件创建工程具体操作
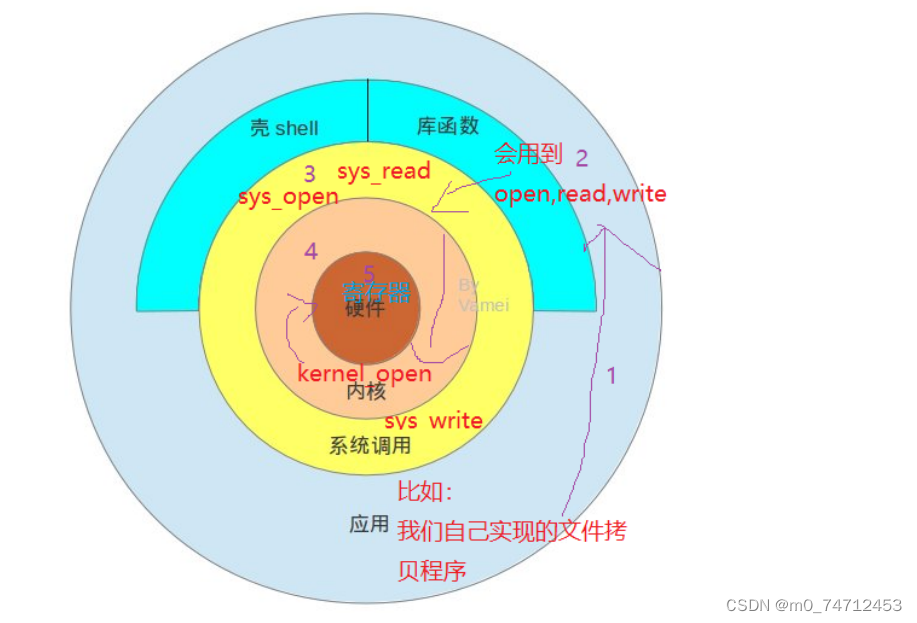
linux下实现串口功能
linux下OLED屏开发-IIC协议
实现linux定时器
官方外设库SDA安装和验证
修改开发板内核启动日志输出级别
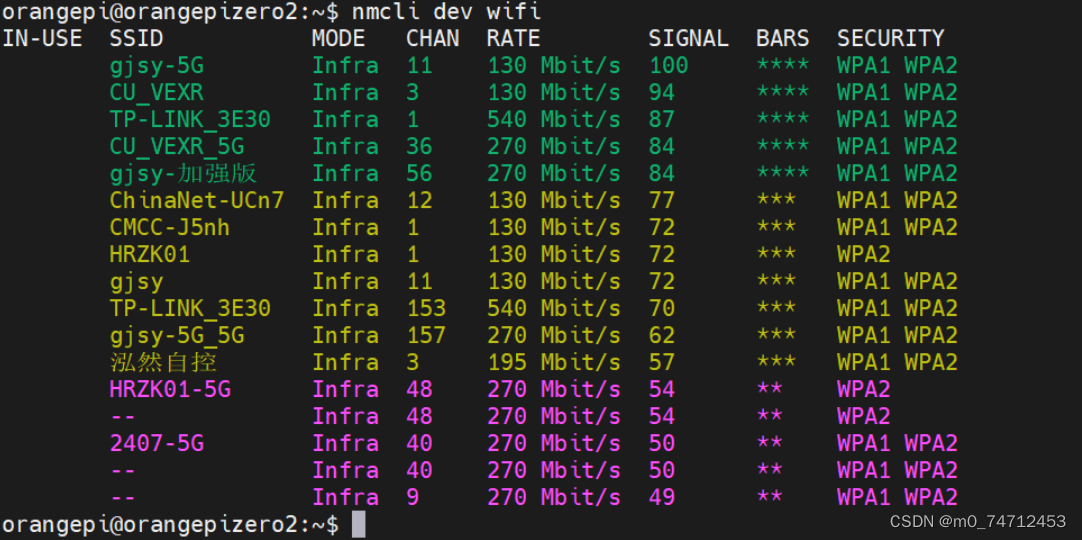
开发板配置网络ssh登入
香橙派刷机和系统登入
实现贪吃蛇小游戏
基于Arduino UNO的循迹小车
基于Arduino UNO的智能摇头避障小车
网络编程知识点总结(7)
网络编程知识点总结(6)
网络编程知识点总结(5)
网络编程知识点总结(4)
网络编程知识点总结(3)
2391. 收集垃圾的最少总时间
CentOS 安装 Portainer
网络编程知识点总结(2)
网络编程知识点总结(1)
linux条件变量知识点总结
Objection Detection 手记
什么是死锁?互斥锁进入死锁怎么解决?
linux互斥锁(pthread_mutex)知识点总结
linux线程创建等待及退出总结
linux线程与进程的区别及线程的优势
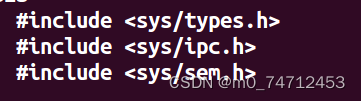
linux信号量与PV操作知识点总结
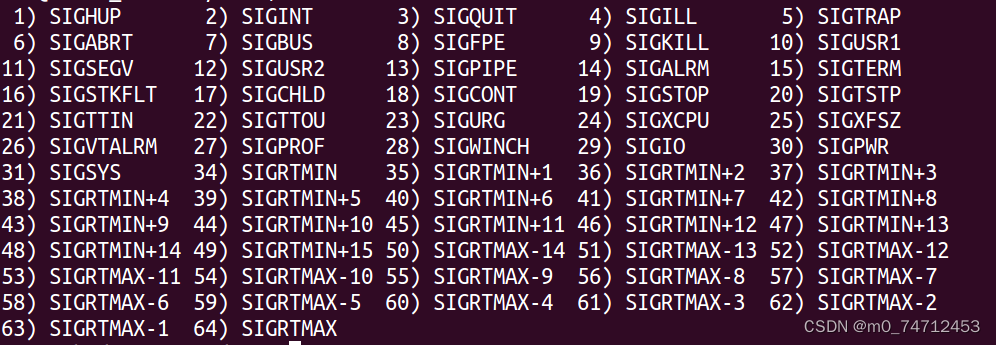
Linux 信号知识点总结