热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
平台设计-联系信息的存储
Java 中文官方教程 2022 版(十九)(3)
Java 中文官方教程 2022 版(十九)(2)
前端场景的代码部署方式都有那些?
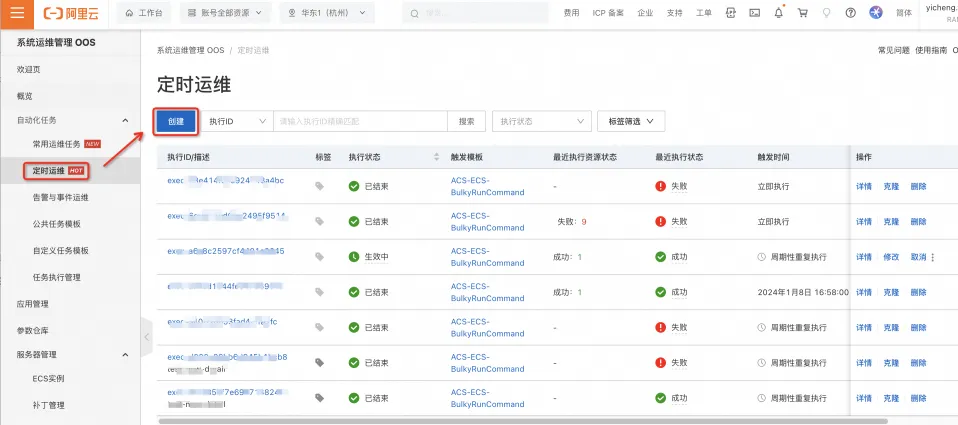
通过OOS实现定时备份Redis实例转储到OSS
Java 中文官方教程 2022 版(十九)(1)
前端目前的发展状况有哪些挑战和机遇呢
前端发展史
平台设计-字典缓存
平台设计-部署模式
深入了解API:详解应用程序接口的作用和原理
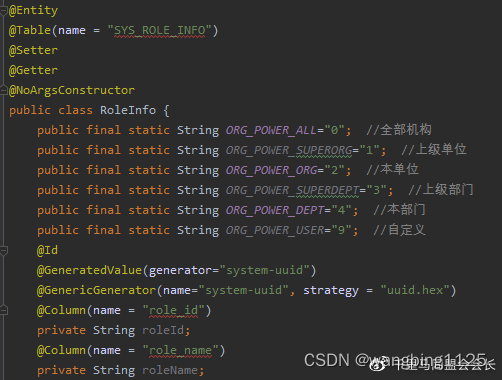
平台设计-功能权限
平台设计-数据相关类
平台设计-系统配置
平台设计-字典管理
平台设计-用户权限体系
Oracle 12c的TOP N语句:数据排名的“快速通道”
Oracle 12c的临时UNDO:数据的“临时保镖”
Java 中文官方教程 2022 版(十八)(4)
Java 中文官方教程 2022 版(十八)(3)
Oracle 12c的Adaptive执行计划:数据的“聪明导航员”
Oracle 12c的内存列存储:数据的“闪电侠”
Java 中文官方教程 2022 版(十八)(2)
Oracle 12c的多重索引:数据的“多维导航仪”
开发指南021-swagger的使用
Oracle 12c的不可见字段:数据的“隐形斗篷”
开发指南020-banner
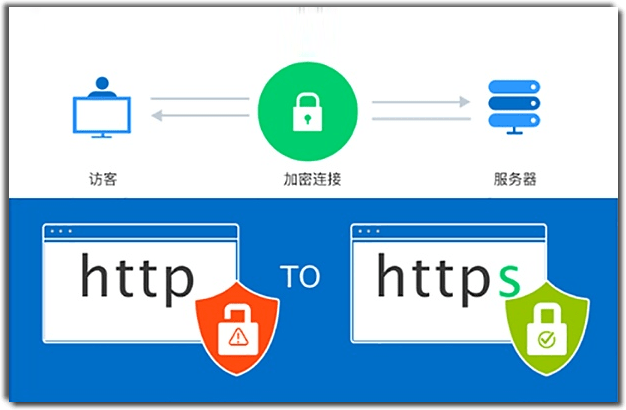
深入理解SSL数字证书:定义、工作原理与网络安全的重要性
Java 中文官方教程 2022 版(十八)(1)
Oracle 12c的自动数据优化(ADO)与热图:数据管理的“瘦身”与“透视”艺术
开发指南019-版本标识
开发指南018-前端存储
开发指南017- 移动前端结构
开发指南016-前端图标规范
开发指南015-前端缓存的信息
Oracle 12c多租户架构:数据管理的“摩天大楼”
开发指南014-PC前端编程步骤
Oracle物化视图:数据的“快照”艺术
Oracle RMAN:守护数据的神秘魔法师
Oracle数据泵:数据迁移的魔法棒
Oracle RAC:数据库集群的舞动乐章
Oracle闪回:时光倒流,数据重现的魔法
Oracle中的Dual表:数据世界的“神奇小盒子”
Oracle中的触发器与序列:自增列的魔法组合
Oracle序列:数据世界的“自动售货机”
现代信息技术下的系统集成:挑战与机遇
Oracle用户事件触发器:数据库世界的“福尔摩斯”
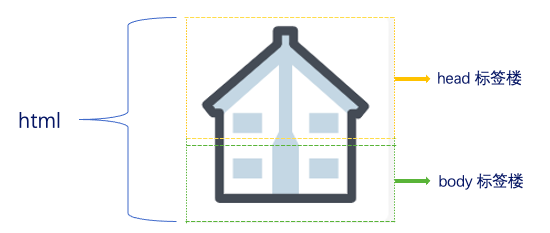
HTML的基本结构