热门
【刷题】Leetcode 415 字符串相加 和 34 字符串相乘
【Linux】开始使用gdb吧!
【Python 基础】检查字符串是否只包含数字和字母?
【刷题】双指针入门
【Python 基础】如何将一个字符串转化为全大写和全小写?
【Python 基础】remove、del和pop有什么区别?
【C++】继续学习 string类 吧
【Python 基础】递推式构造字典(dictionary comprehension)
【Python 基础】Python中的异常处理是如何进行的?
【C++】STL学习之旅——初识STL,认识string类
【Easyx】easyx从入门到精通 — 初步入门
电子好书发您分享《AutoTalk第七期:自动化工具-OpenAPI在线调试》
【刷题】Leetcode 1609.奇偶树
电子好书发您分享《2023龙蜥操作系统大会阿里云分论坛:释放云算力 繁荣云生态》
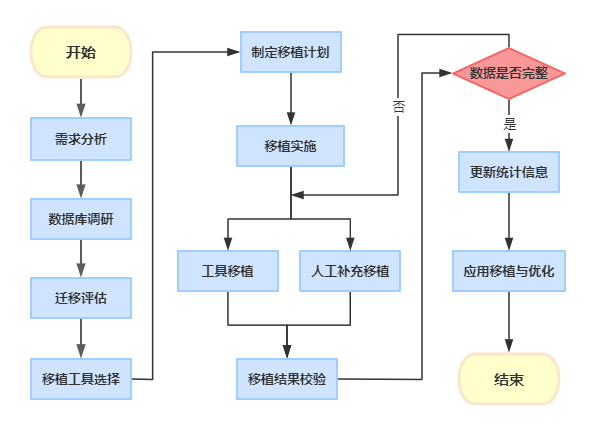
这篇文章教会你:从 SQL Server 移植到 DM(上)
电子好书发您分享《AutoTalk第八期:自动化场景之高效创建安全合规新账号》
SQL Server语法基础:入门到精通
etcd入门指南
【刷题】 leetcode 面试题 08.05.递归乘法
前后端分离项目Docker部署指南(下)
【C++】C++ 入门 — 命名空间,输入输出,函数新特性
前后端分离项目Docker部署指南(上)
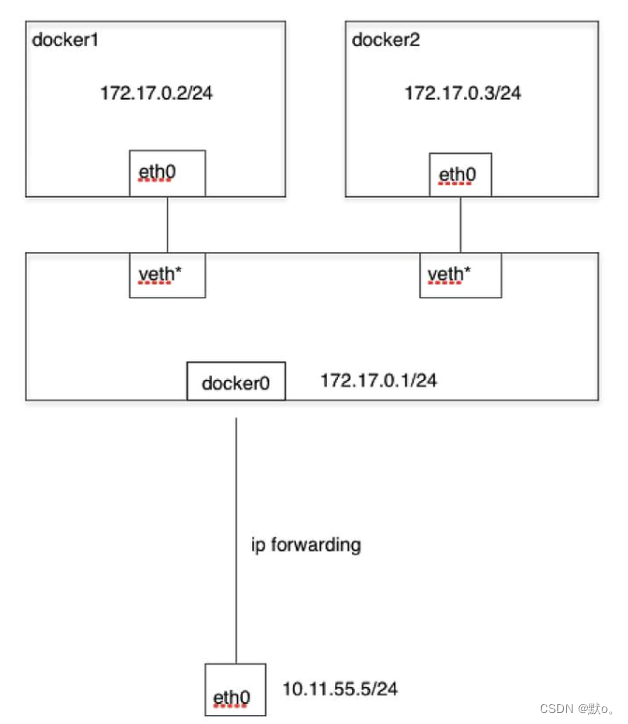
深入理解Docker自定义网络:构建高效的容器网络环境
Docker自定义JDK镜像并拉取至阿里云镜像仓库全攻略
【Linux】 开始使用 gcc 吧!!!
【刷题】 leetcode 面试题 01.06 字符串压缩
Docker数据集与自定义镜像:构建高效容器的关键要素
从零开始掌握Docek的基础知识与应用技巧
【Linux】开始使用 vim 吧!!!
Shell脚本入门:从基础到实践,轻松掌握Shell编程
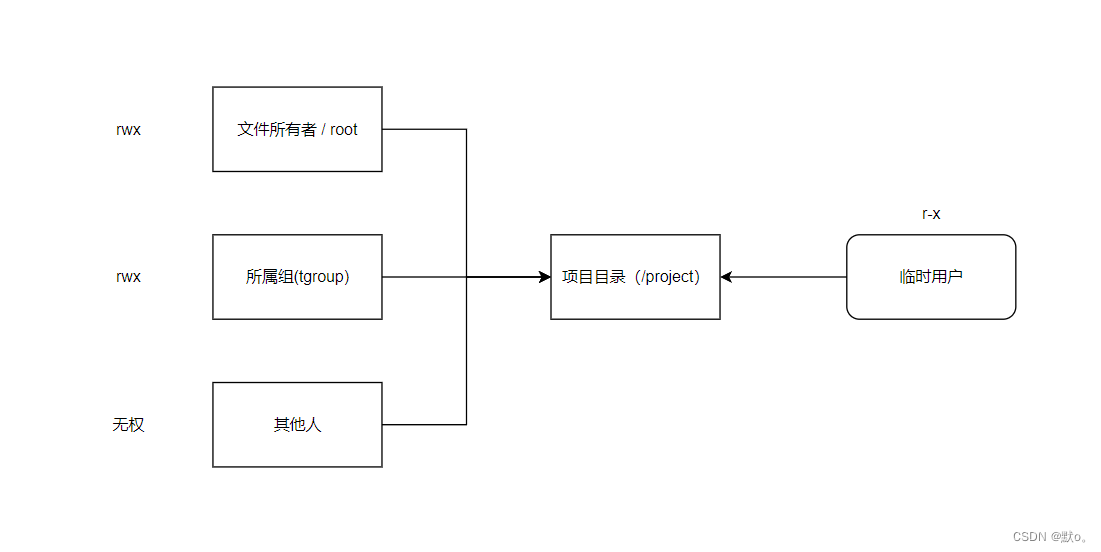
【Linux】权限 !
Linux系统中前后端分离项目部署指南
在Linux系统上实现高效安装与部署环境的全方位指南
【刷题】 leetcode 2 .两数相加
【刷题】leetcode 1 . 两数之和
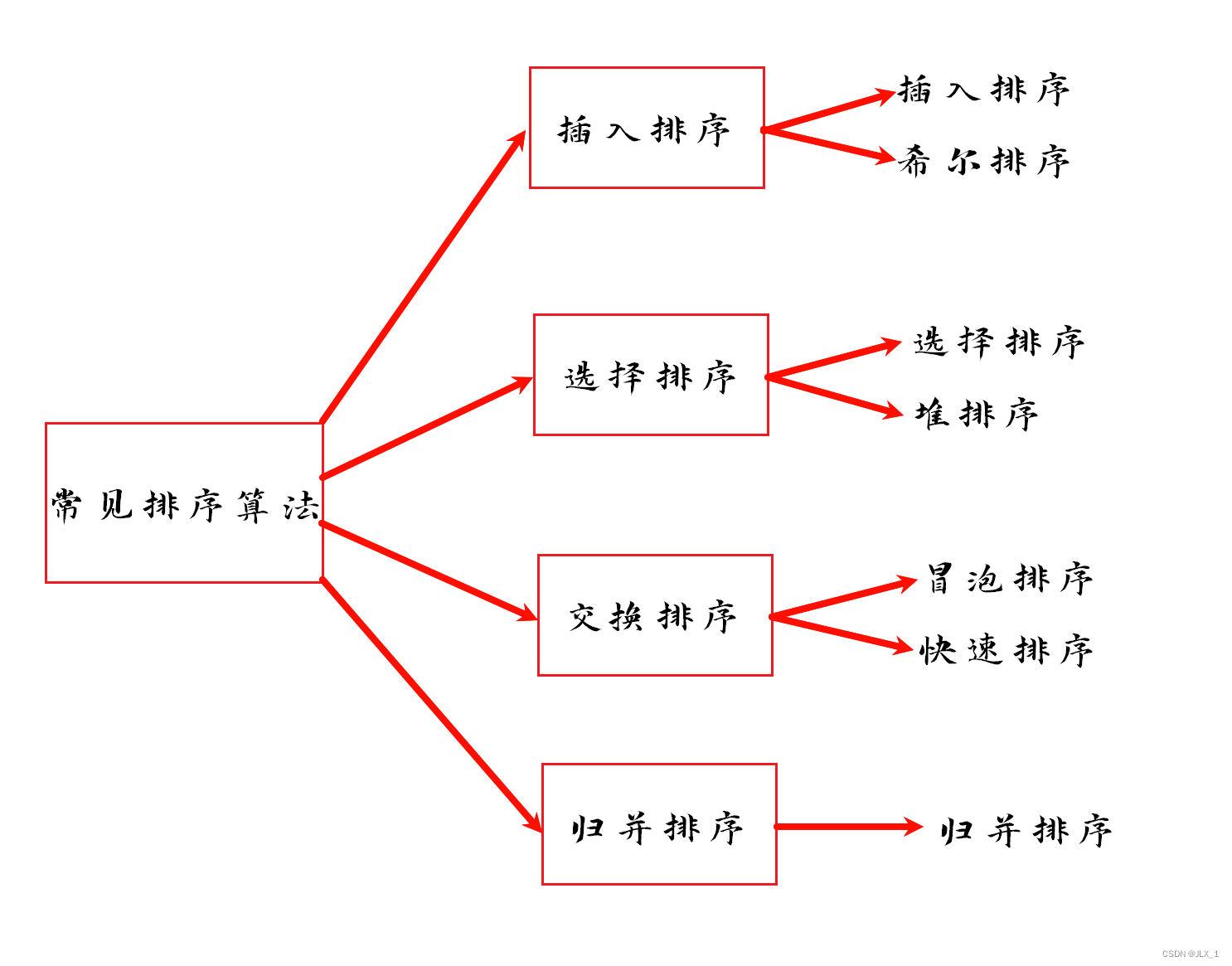
【六大排序详解】终篇 :冒泡排序 与 快速排序
构建高效可靠的微服务架构:策略与实践
深入探索Linux:ACL权限、特殊位与隐藏属性的奥秘
网络安全与信息安全:防范漏洞、应用加密技术及提升安全意识
构建高效机器学习模型的策略与实践
【六大排序详解】中篇 :选择排序 与 堆排序
从基础到高级:Linux用户与用户组权限设置详解
【六大排序详解】开篇 :插入排序 与 希尔排序
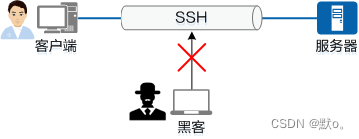
SSH:加密安全访问网络的革命性协议
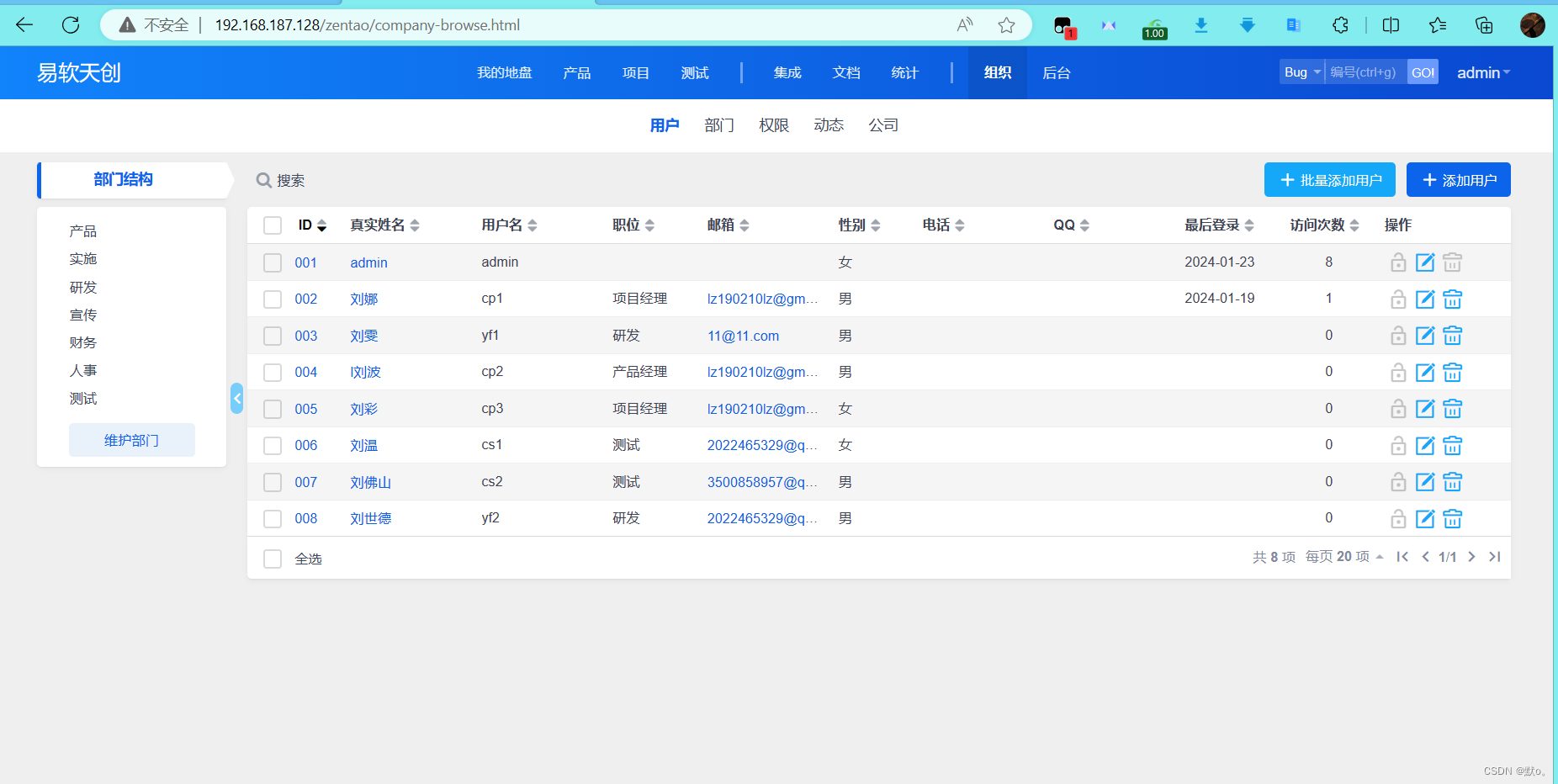
医疗天使禅道使用工作流程:优化医疗服务的必经之路
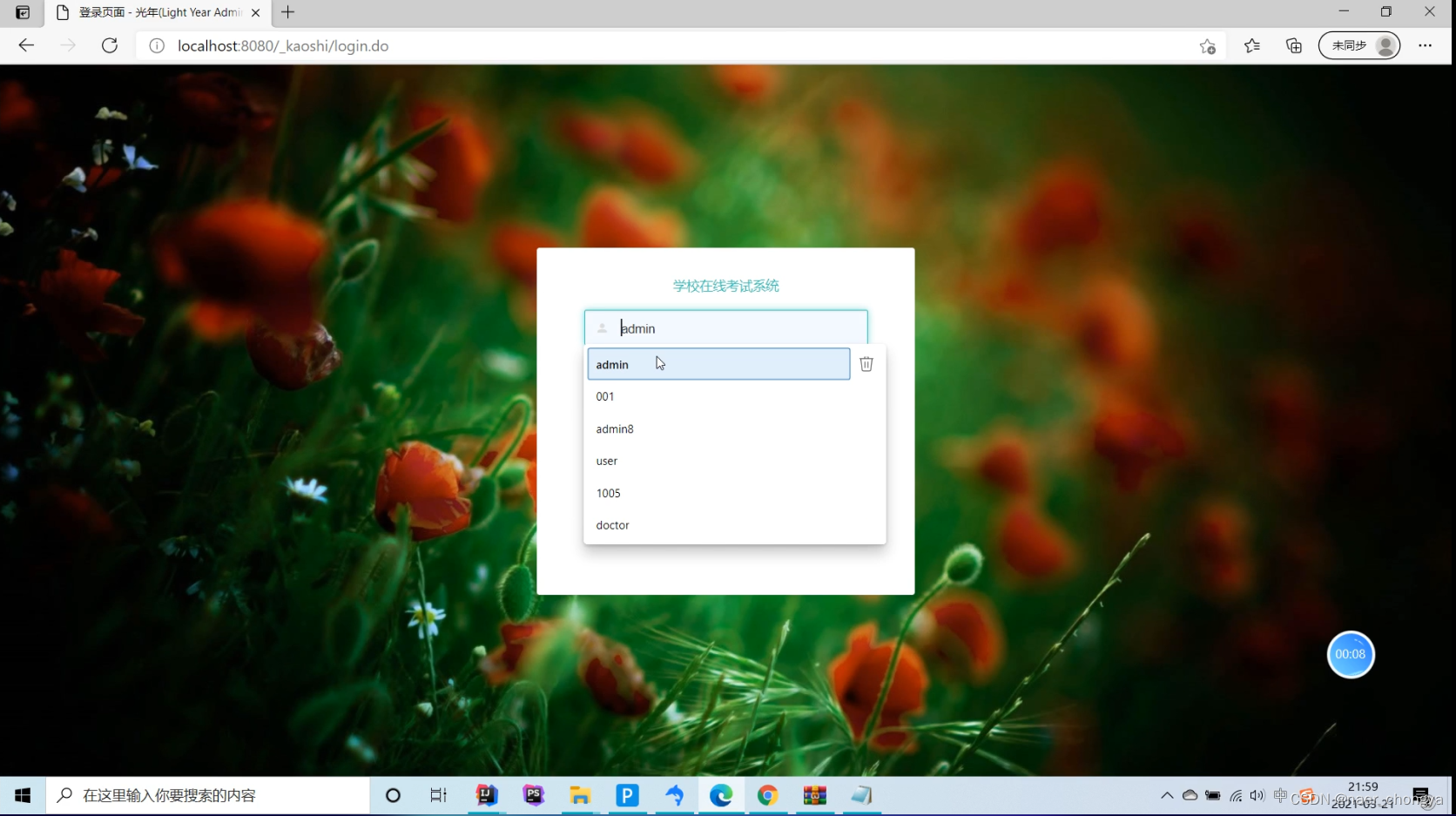
基于SSM的学校在线考试系统的设计与实现
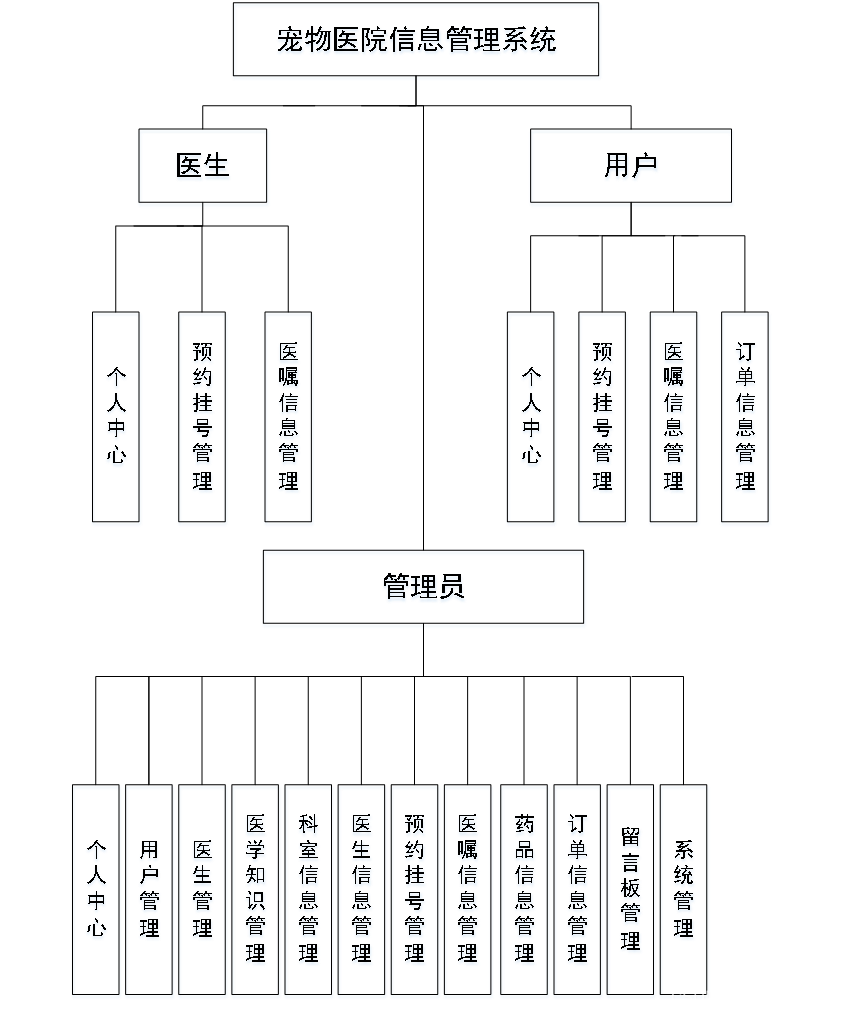
基于SSM的宠物医院信息管理系统
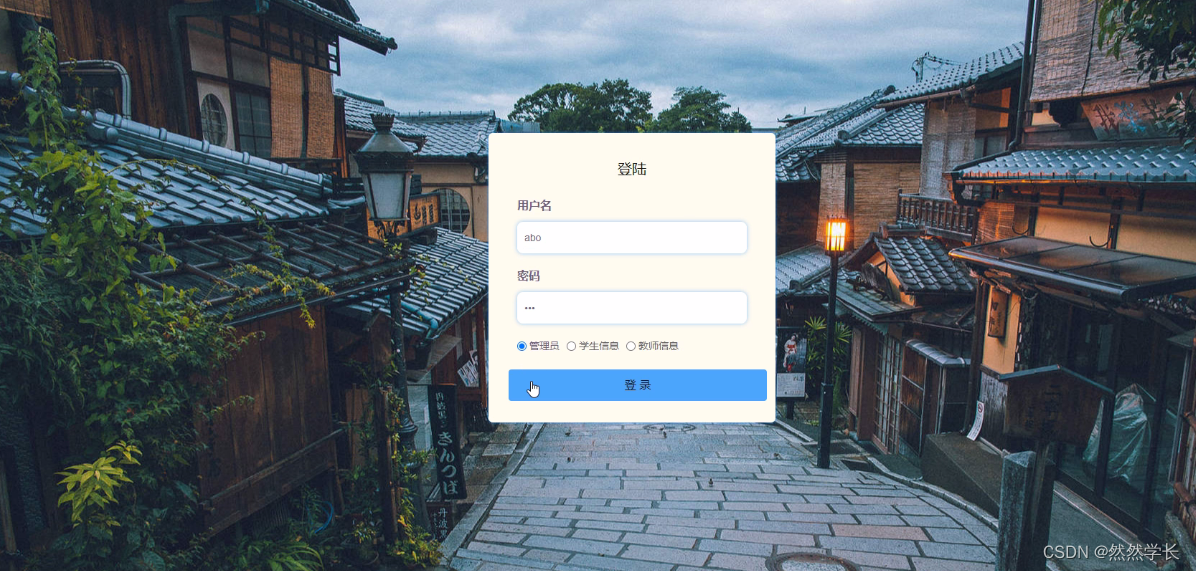
Java毕设之JSP师生交流平台
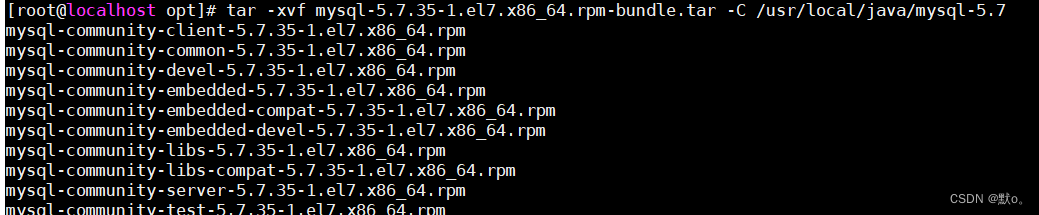
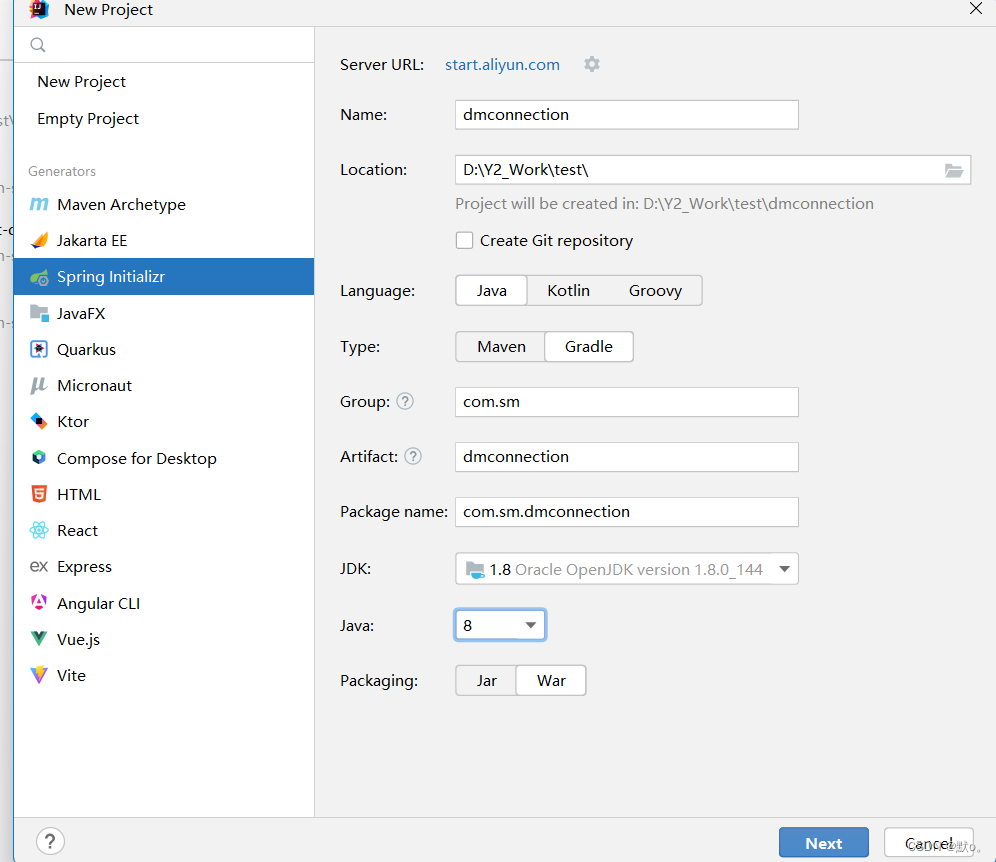
在IntelliJ IDEA中通过Spring Boot集成达梦数据库:从入门到精通
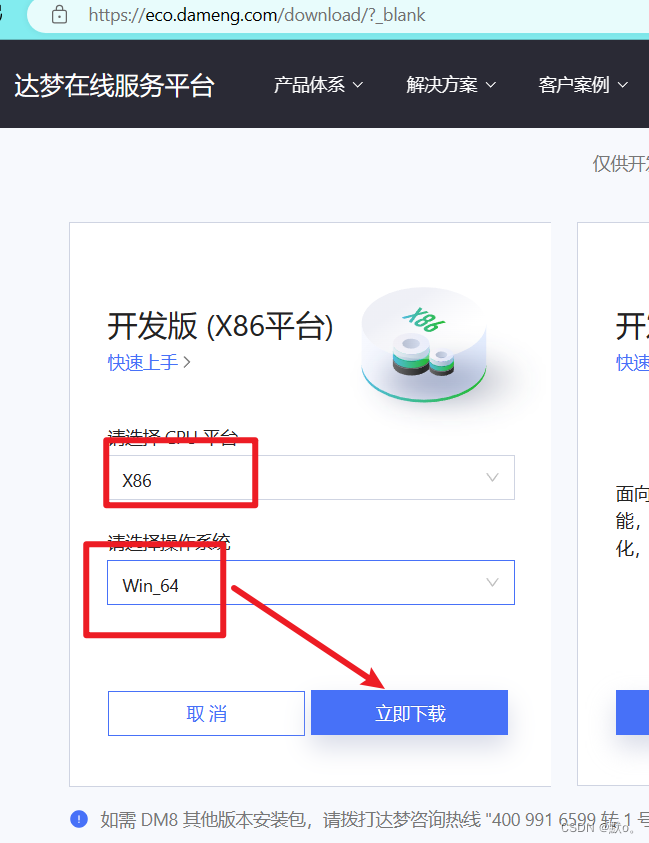
达梦数据库Windows安装教程:从准备到完成