InnoDB存储引擎中自适应哈希索引使用的是散列表(Hash Table)的数据结构。但是散列表不只存在于自适应哈希中,在每个数据库中都存在。设想一个问题,当前我的内存为128G,我怎么得到内存中的某一个被缓存的页呢?内存中查询速度很快,但是也不可能遍历所有内存。这时,对于字典操作,O(1)的散列技术就能有很好的用武之地。
哈希表
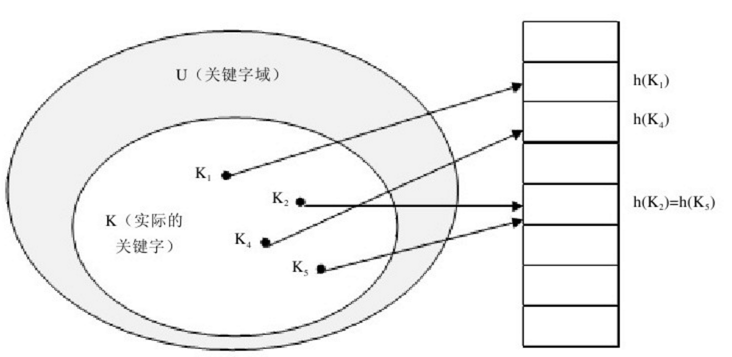
哈希表(Hash Table)也称散列表,由直接寻址表改进而来,所以我们先来看直接寻址表。当关键字的全域U比较小时,直接寻址是一种简单而有效的技术。假设某应用要用到一个动态集合,其中每个元素都有一个取自全域U={0,1,……,m-1}此处的m不是一个很大的数。同时假设没有两个元素具有相同的关键字。
用一个数组(即直接寻址表)T[0..m-1]表示动态集合,其中每个位置(或称槽或桶)对应全域U中的一个关键字。槽k指向集合中一个关键字为k的元素。如果该集合中没有关键字为k的元素,则T[k]=NULL。
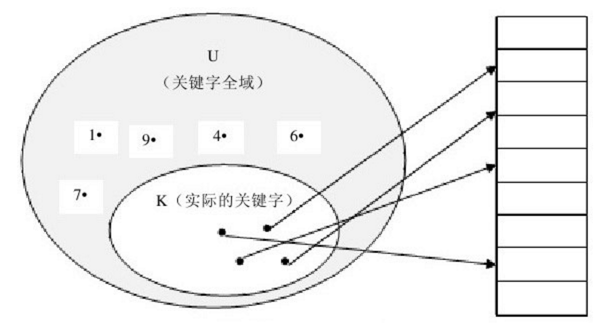
直接寻址技术存在一个很明显的问题:如果域U很大,在典型计算机的可用容量限制下,要在机器中存储大小为U的表T就有点不实际,甚至是不可能的。如果实际要存储的关键字集合K相对于U来说很小,因而分配给T的大部分空间都要浪费掉。
因此,哈希表出现了,在哈希方式下,该元素处于h(k)中,亦即利用哈希函数h、根据关键字k计算出槽的位置。函数h将关键字域U映射到哈希表T[0..m-1]的槽位上。
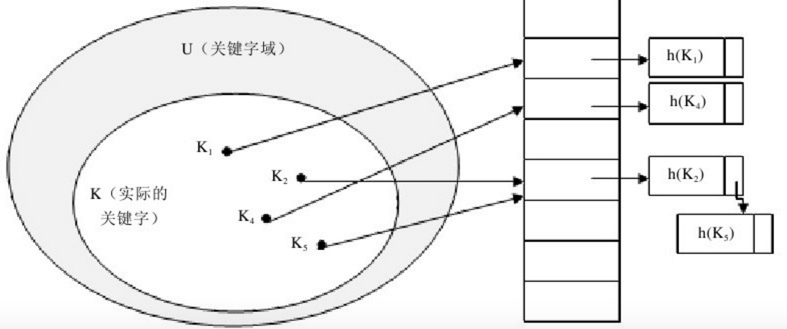
哈希表技术很好地解决了直接寻址遇到的问题,但是这样做有一个小问题,两个关键字可能映射到同一个槽上。一般将这种情况称之为发生了碰撞(collision)。数据库中一般采用最简单的碰撞解决技术,称之为链接法(chaining)。
在链接法中,把散列到同一槽中的所有元素都放在一个链表中。槽j中有一个指针,他指向由所有散列到j的元素构成的链表的头;如果不存在这样的元素,则j中为NULL。
最后要考虑的是哈希函数了,哈希函数h必须很好地进行散列。最好的情况是能避免碰撞的发生;即使不能避免,也应该使碰撞在最小程度下产生。一般来说,都将关键字转换成自然数,然后通过除法散列、乘法散列或全域散列来实现。数据库中一般采用除法散列的方法。
在用来设计哈希函数的除法散列法中,通过取k除以m的余数,来将关键字k映射到m个槽的某一个去。即哈希函数为:h(k)=k mod m
InnoDB存储引擎中的哈希算法
InnoDB存储引擎使用哈希算法对字典进行查找,其冲突机制采用链表方式,哈希函数采用除法散列方式。对于缓冲池页的哈希表来说,在缓冲池中的Page页都有一个chain指针,它指向相同哈希函数值的页。而对于除法散列,m的取值为略大于2倍的缓冲池页数量的质数。
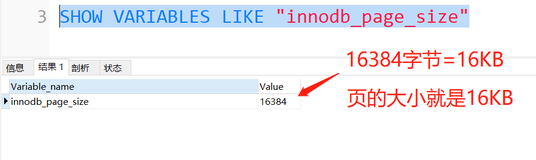
例如:当前参数innodb_buffer_pool_size的设置大小为10MB,则共有640个16KB的页。那对于缓冲池页内存的哈希表来说,需要分配640×2=1280个槽,但是1280不是质数,需要取比1 280略大的一个质数,应该是1399,所以在启动时会分配1399个槽的哈希表,用来哈希查询所在缓冲池中的页。哈希表本身需要20个字节,每个槽需要4个字节,因此一共需要20+4×1399=5616个字节。其中哈希表的20个字节从innodb_additional_mem_pool_size中进行分配,4×1399=5596个字节从系统申请分配。因此在对InnoDB存储引擎进行内存分配规划时,也应该规划好哈希表这部分内存,这部分内存一般从系统分配,没有参数可以控制。对于前面我们说的128GB的缓冲池内存,则分配的哈希表和槽一共需要差不多640MB的额外内存空间。
那InnoDB存储引擎对于页是怎么进行查找的呢?上面只是给出了一般的算法,怎么将要查找的页转换成自然数呢?
InnoDB存储引擎的表空间都有一个space号,我们要查的应该是某个表空间的某个连续16KB的页,即偏移量offset。InnoDB存储引擎将space左移20位,然后加上这个space和offset,即关键字K=space<<20+space+offset,然后通过除法散列到各个槽中。
自适应哈希索引
自适应哈希索引采用之前,我们讨论哈希表的方式实现。不同的是,这又是数据库自己创建并使用的,DBA本身并不能对其进行干预。当在配置文件中启用了参数innodb_adaptive_hash_index后,数据库启动时会自动创建槽数为innodb_buffer_pool_size/256个的哈希表。例如,对当前参数innodb_buffer_pool_size设置为10MB,则启动时InnoDB存储引擎会创建一个有10M/256=40 960个槽的自适应哈希表。
自适应哈希索引经哈希函数映射到一个哈希表中,因此自适应哈希索引对于字典类型的查找非常快速,如SELECT * FROM TABLE WHERE index_col='xxx',但是对于范围查找就无能为力了。通过命令SHOW ENGINE INNODB STATUS可以看到当前自适应哈希索引的使用状况,如:
show engine innodb status\G
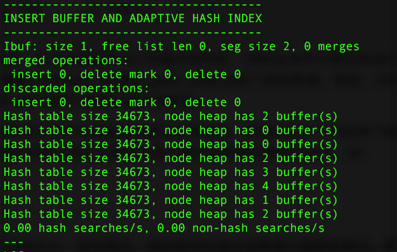
现在可以看到自适应哈希索引的使用信息了,包括自适应哈希索引的大小、使用情况、每秒使用自适应哈希索引搜索的情况。需要注意的是,哈希索引只能用来搜索等值的查询,如select * from table where index_col='xxx',而对于其他查找类型,如范围查找,是不能使用哈希索引的。因此,这里出现了non-hash searches/s的情况。hash searches:non-hash searches可以大概知道使用哈希索引后的效率。
由于自适应哈希索引是由InnoDB存储引擎自己控制的,所以这里的信息只供我们参考而已。不过我们可以通过参数innodb_adaptive_hash_index来禁用或启动此特性,默认为开启。