排他锁(Exclusive Lock)
排他锁(Exclusive Lock) , 简称X锁。
若事务T对数据对象A加上X锁,则只允许T读取和修改A,其他任何事务都不能再对A加任何类型的锁,直到T释放A上的锁。这就保证了其他事务在T释放A上的锁之前不能再读取和修改A。
规则1:写一个数据之前加X锁, 事务提交之后释放该X锁。
共享锁(Share lock)
共享锁(Share lock) ,简称S锁, 这个锁和之前的排他锁X锁有区别, 主要用于读取数据。
如果一个数据加了X锁, 就没法加S锁,没法再加X锁。
如果一个数据加了S锁, 就可以加S锁,没法再加X锁。
规则1:读一个数据之前加S锁, 读完之后立刻释放该S锁。
规则2:读一个数据之前加S锁, 事务提交之后立刻释放该S锁。
“丢失修改”的问题
事务1的修改被事务2的修改覆盖了,事务1的修改像是丢失了。
排他锁可以解决两个人同时修改导致的“丢失修改”的问题,事务1修改的时候不能被其他事务修改。
读未提交(最低的事务隔离级别)-脏数据
现象:不会丢失数据,事务1还未提交的修改能被事务2读取。可以读到没有提交或者回滚的内容 (脏数据)。
原理:写数据时加上X锁,直到事务结束, 读的时候不加锁。
读已提交-不可重复读
现象:能避免“丢失数据”和“脏数据”,事务1能读到其他已提交事务的修改,出现“不可重复读”的问题。
原理:写数据的时候加上X锁, 直到事务结束, 读的时候加上S锁, 读完数据立刻释放。(共享锁规则1)
可重复读-幻读
现象:能避免“丢失数据”和“脏数据”, “不可重复读”三个问题,事务1能读取到其他事务新插入读数据,出现“幻读”的问题。
原理:写数据的时候加上X锁, 直到事务结束, 读数据的时候加S锁, 也是直到事务结束。(共享锁规则2)
Serializable (串行化)
现象:能避免“丢失数据”和“脏数据”, “不可重复读”,“幻读”四个问题。
原理:严格有序执行,事务不能并发执行。
MVCC(多版本并发控制)
“串行化”隔离级别,虽然不会出错,但是效率实在太低了。 避免使用!!
“可重复读”,虽然会出现幻读,但是也能忍受。但为了实现可重复读, 需要在事务中对读操作加锁,并且得持续到整个事务结束,效率也一般,可选择使用。
隔离级别在可重复读和读已提交情况下,有没有可能在在读的时候不用加锁,也能实现可重复读?
MVCC实现了保证可重复读并在读数据的时候不需要加锁操作!! ps:但是在写数据的时候,MySQL还是要加锁的,防止写-写冲突。读写不互相等待,能极大地提高数据库的并发能力啊。
原理
给数据库里面的每张表加两个隐藏的字段:事务ID,回滚指针。(事务ID就表明这一行数据是哪个事务操作的,事务ID是一个递增的数字,每次开始新事务,这个数字就会增加。)
扩展一个Read View的数据结构记录版本数据,它有三个部分:
(1) 当前活跃的事务列表 ,即[101,102]
(2) Tmin ,就是活跃事务的最小值, 在这里 Tmin = 101
(3) Tmax, 是系统中最大事务ID(不管事务是否提交)加上1。 在这里例子中,Tmax = 103
(注: 在可重复读的隔离级别下,当第一个Read操作发生的时候,Read view就会建立。 在Read Committed隔离级别下,每次发出Read操作,都会建立新的Read view。)
流程变化
原始数据
| 事务ID | 回滚指针 | name | age |
| 100 | null | sf | 30 |
开启两个事务
| 事务id101 | 事务id102 |
| 开始事务 标记1 | |
| select * from users where name='sf'; | 开始事务 |
| do others things | update users set age = 35 where name='sf'; 标记2 提交事务 |
| select * from users where name='sf'; |
在标号1 的地方,数据是这样的: 与此同时,需要建立一个叫做Read View的数据结构。
| 事务ID | 回滚指针 | name | age |
| 100 | null | sf | 30 |
在标号为2的地方,数据是这样的:事务2做了修改,所以事务ID修改为102,回滚指针指向上一个事务ID的数据,即事务ID100
| 事务ID | 回滚指针 | name | age |
| 102 | 上一版本的数据 | sf | 35 |
按照可重复读的要求,事务1无论读多少次总能读到age=30的那行记录,即使事务2修改了age,也不受影响。
那么如何用来判断这些数据版本记录中哪些对你来说是可见的(可读的)。 ”
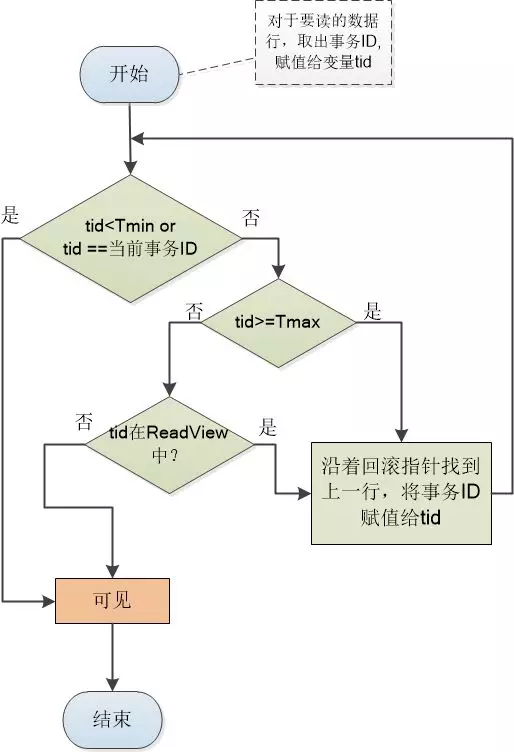
对于上面的例子,ReadView 中事务列表是[101,102], Tmin= 101, Tmax = 103,第一次读和第二次读是什么样子。
当事务101第一次读的时候,只有一条记录, tid = 100 ,小于Tmin,所以是可以读的。 然后事务102做了修改。
当事务101第二次读的时候,tid=102,程序走到了‘tid是否在Read View中这一分支,由于102确实在Read View的活动事务列表中,那就顺着回滚指针找到下一行记录,即tid为100那一行,再次判断,这就和第一次读一样了。

