数十款阿里云产品限时折扣中,
赶紧点击这里,领劵开始云上实践吧!
课程主讲简介:
于恒,阿里巴巴机器智能技术实验室技术专家,中科院计算所博士,研究方向是机器翻译,在自然语言处理和人工智能领域顶级国际会议ACL、EMNLP、COLING等发表多篇论文。曾在三星中国研究院和搜狗负责机器翻译工作,参与上线搜狗翻译和搜狗海外搜索等产品。目前在阿里翻译平台组担任Tech-leader,主持上线了阿里神经网络翻译系统,为阿里巴巴国际化战略提供丰富的语言支持。
以下内容根据主讲嘉宾视频分享以及PPT整理而成。
2016年伊始,Google率先发布并上线了基于神经网络的机器翻译系统,其表现出的性能显著超越了之前工业界的所有系统,并且在某些特定领域已经接近了人类的翻译水准。传统翻译系统和神经网络的翻译系统之间的比较如下图所示:
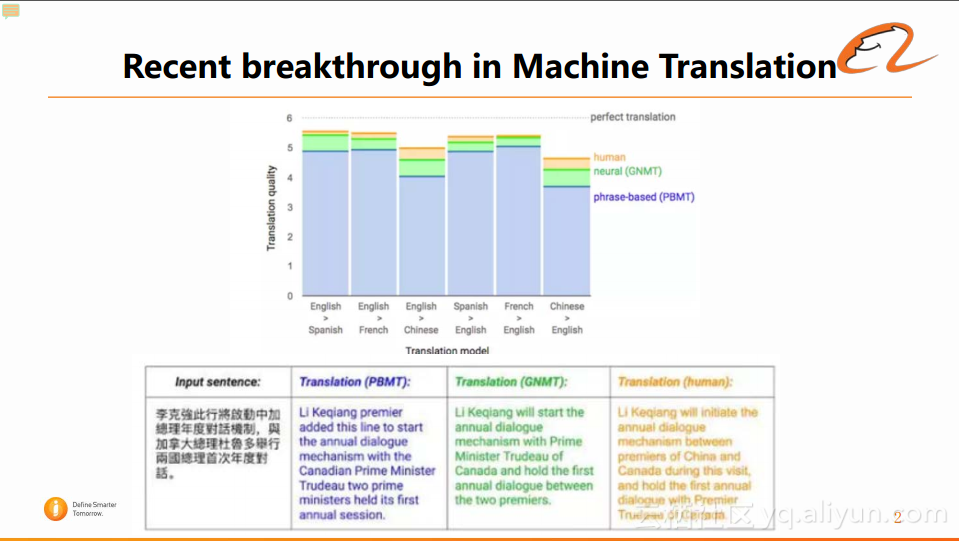
上图中,蓝色的部分代表传统的phrase-based(基于短语的翻译系统),而图中绿色的部分代表基于neural神经网络的系统。显然基于neural神经网络的系统在每个上语项都比传统的PBMT模型要表现得更好,并且在英语>西班牙语、西班牙语>英语和法语>英语这三个特定语言对上的翻译水准已经十分接近人类了。
具体的翻译对比可以参看上图中汉语>英语实际翻译的例子。可以看到,向系统中输入的中文语句中存在一个倒装的句式。在经过各自的翻译后,phrase-based的系统只是逐字的进行汉语>英语的翻译,而基于神经网络的系统实现了基本的翻译,还实现了语句的调序,使译文显得更加流利、更符合英文的表达特点,更加贴近于人工翻译,就仿佛机器理解了人类的对话一样。
从系统的机理来讲,传统的基于短语的翻译是基于词语对齐来实现的,而神经网络NMT则是使用了RNN(Recurrent neural Network,循环神经网络),借助于神经网络对原文和译文同时进行建模,实现了高效精准的翻译。这两种方法大致的实现过程如下图所示:
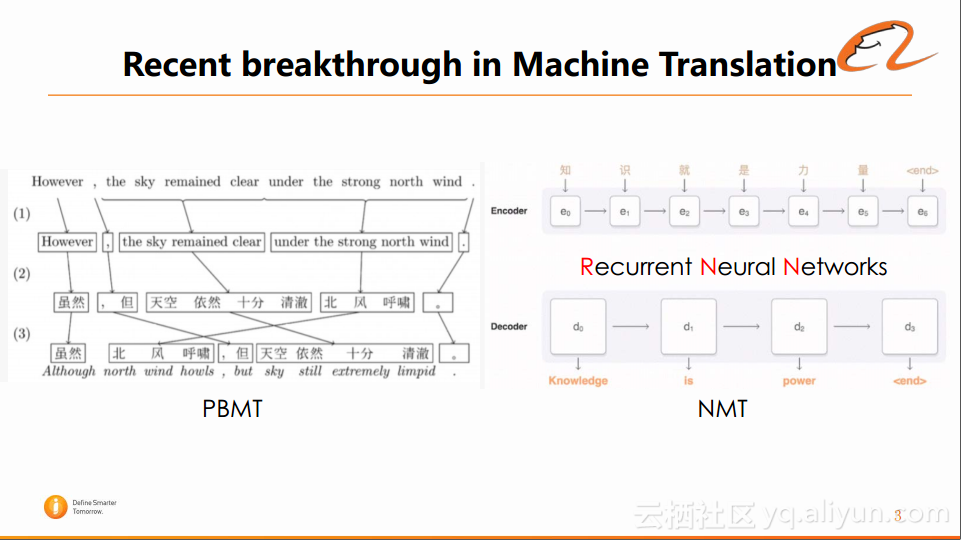
那么RNN是如何实现这种效果的呢?而这也是本次课程的重点所在。接下来将从以下几个方面进一步阐述RNN的原理及其更深层次的应用:
1、RNN原理,包括网络结构和Attention机制。
2、RNN的不足之处,并且引申出它的一个变种——LSTM。
3、通过三个案例介绍RNNs的“不讲理有效性”。
4、介绍RNN无法克服的问题及相关的建设性的解决方案。
一、RNN的原理
1、RNN网络结构
RNN的循环网络结构如下图所示:
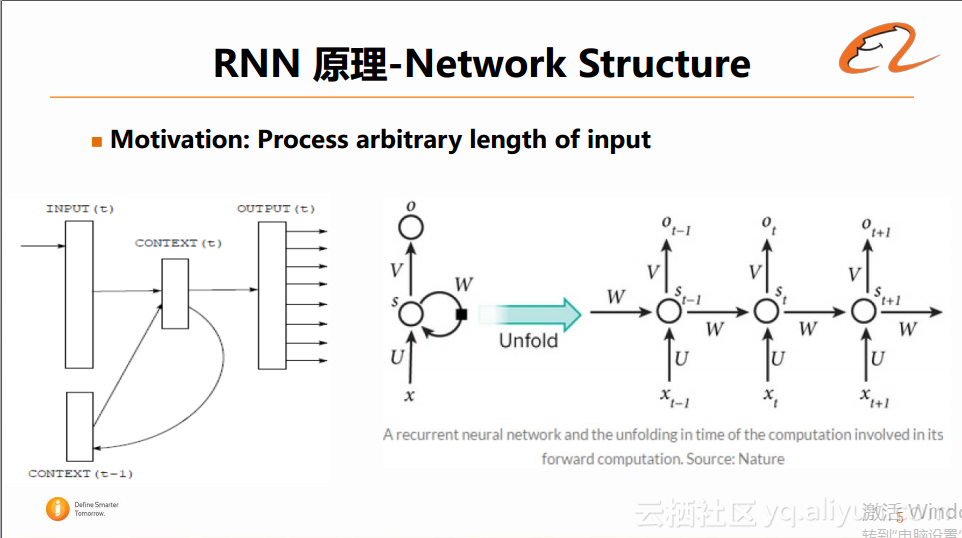
如图中左侧所示,RNN主要包括以下几个网络层:第一层是输入层,第二层是隐藏层(也叫context层),第三层输出层。其中隐藏层是一个循环的结构,当前t时刻的context(t),是由连接上一次训练的隐藏层context(t–1)生成。这样设计的好处在于可以对任意长度的sequence进行建模,这也是它区别于传统网络结构(要求输入的sequence的长度是固定已知的)的一个比较本质的区别。因此RNN适用于处理人类自然语言或者语音等。
如果对RNN的循环结构进行分解,在展开后,可以发现它其实是由很多神经网络堆砌在一起的,并且它每一层之间的参数都是共享的,导致RNN是一个非常深的网络结构,这种神经网络的叠加的结构也是它的优点所在。
如果用形式化的语言对网络结构进行表述,可以表示成ht=fw(ht-1, xt)。如下图所示:
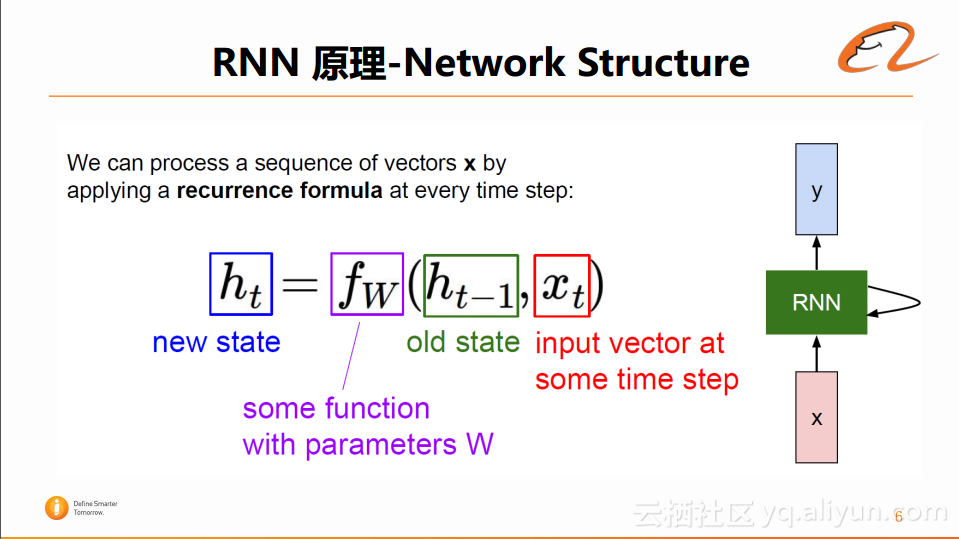
显然,当前t时刻隐藏层的状态ht,是由t-1时刻的隐藏层的状态和t时刻的输入xt通过函数fw来决定的。对该等式进行进一步拆分后,可以发现上述函数fw通常是用tanh函数来进行数字变换,拆分后的等式如下图所示:
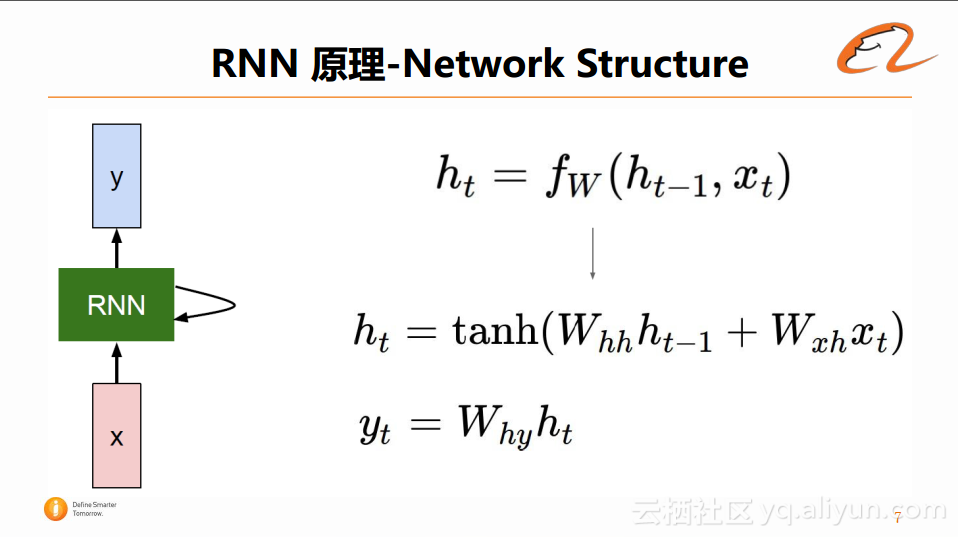
t时刻的状态ht,是由前一时刻的状态ht-1与Whh做矩阵相乘,再加上t时刻的输入xt与Wxh做矩阵相乘,将这两者之和进行tanh变换得到的。而t时刻的网络层的输出yt,是由t时刻的隐藏层状态ht与Why做一个矩阵相乘得到的。
可以看到整个网络中,所需要学习的参数有三个,第一个是隐藏层和隐藏层之间的Whh,第二个是输入层和隐藏层之间的Wxh,第三个是输出层和隐藏层之间的Why。
如果对RNN的整个的计算过程进行展开,如下图所示:
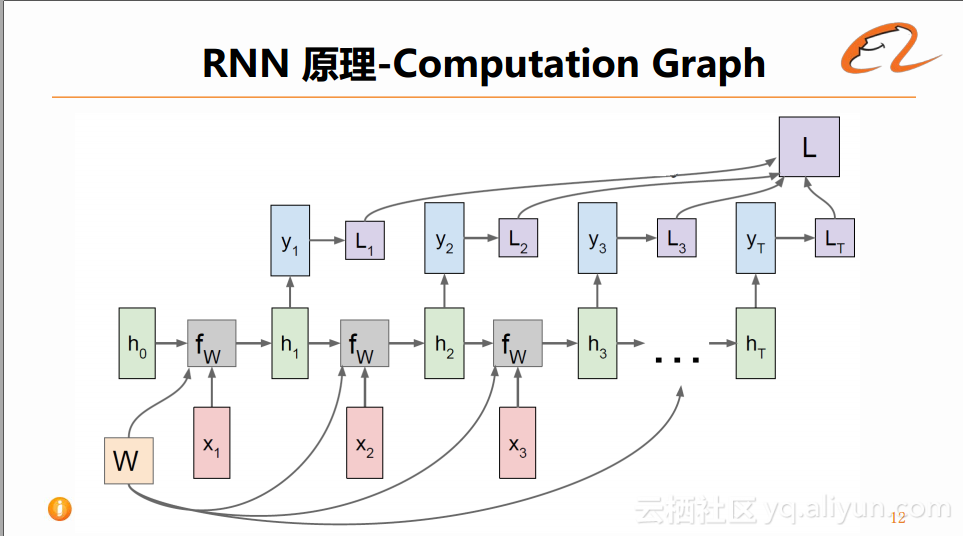
在t=0时刻,随机初始化一个隐藏层的状态h0,然后输入x1,通过函数fw进行数字变换后得到t=1时刻的隐藏层状态h1。然后以此类推,计算出从t=0时刻到t=T时刻的全部隐藏层状态。在这个过程中,每个time-step共用同一组权重矩阵W。对于每个time-step的隐藏层状态,还会借助于矩阵权重W计算得到输出y1...yT。以上就是网络的计算过程。
在实际的网络训练过程当中,可以根据每一个输出y得到它对应的Loss,将这些Loss组合在一起就可以得到所需的反向传播的Loss,然后通过随机梯度下降的方式进行反向传播并更新网络中的参数W,这样就完成了整个的训练过程。
如下图所示是RNN循环结构:
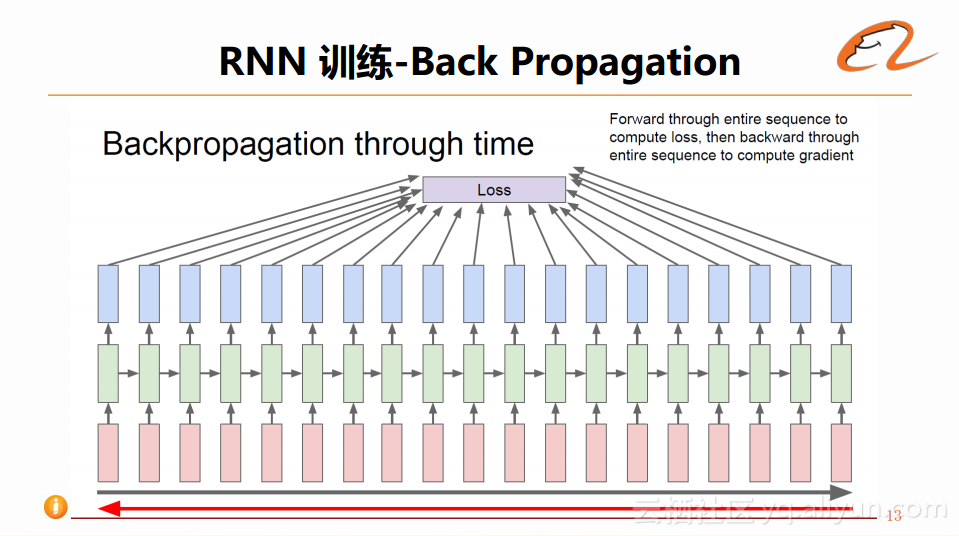
图中的每次循环都对应着不同的time-step,其算法的名字叫做Backpropagation through time。即对于一个长sequence,从第一个时间点计算到最后一个时间点,得到所有Loss之后,从最后一个时间点开始回传,直到到达最初的时间点,同时进行权重更新。
这样的算法其实存在一定的问题,当序列过长的时候,一次回传必须要等整个序列完成解码之后才能开始,这样会导致速度变慢,会影响整个模型收敛的速度。
所以产生了一种更加常用的算法——Truncated Backpropagation through time,如下图所示:
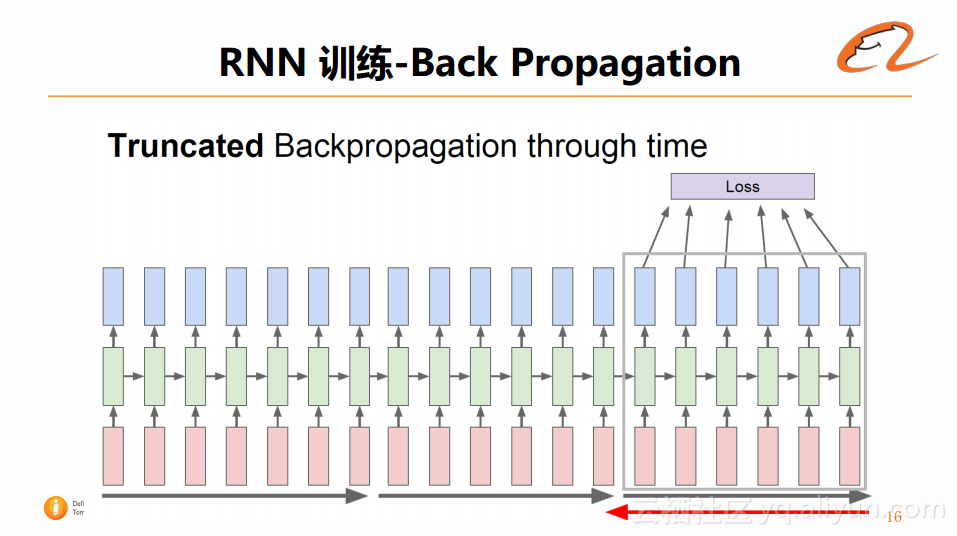
它的思想是将长序列截断成为多个短序列,然后对这些短序列进行权值更新。这样的好处在于,在对某个长序列进行计算,在中间某个时刻的时候,可以先返回一批梯度对参数进行更新,然后再此基础上对剩余的部分进行计算。这样权值更新的次数会增多,收敛速度也会加快。
2、具体案例实现
下面借助一个具体的例子——字符级别的语言模型来实现上述的过程,如图所示:
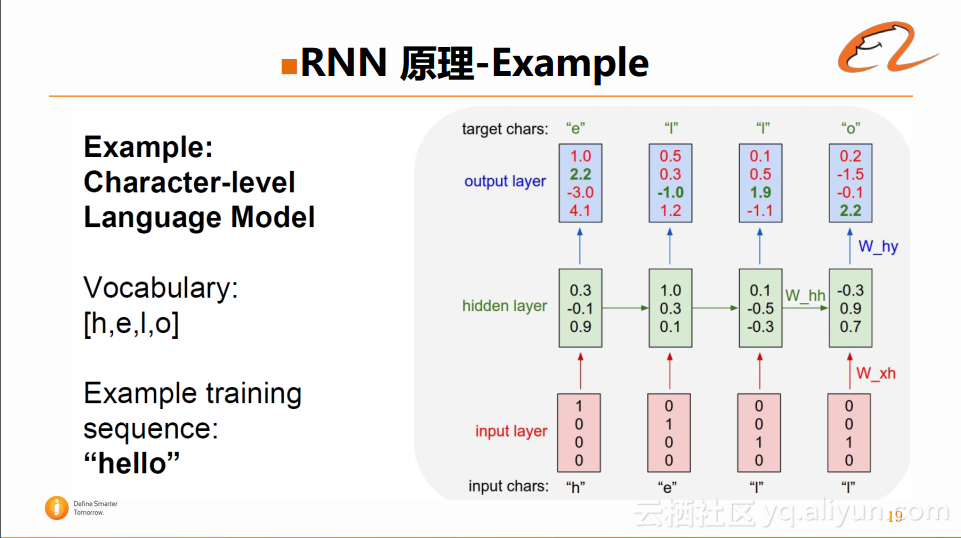
语言模型的思路与RNN是比较接近的,即当前时刻输出的概念是如之前的历史时刻相关的。对于序列“hello”而言,它由五个字符组成,包含有四类字母——‘h’、‘e’‘l’‘o’,在实际的训练过程中,第一个输入自然是‘h’,然后依次是‘e’、‘l’和‘l’,对于最
后一个字符‘o’,则不进行建模。如上图所示,先建立输入层(input layer),然后根据不同的输入得到其隐藏层(hidden layer)状态,即当前隐藏层状态是基于前一隐藏层状态得到的,对于每一个隐藏层,通过计算得到一个输出,该输出代表着当前字符可能生成的下一个字符,这样就得到了上述的计算图。在计算得到输出后,可以根据该输出已经相应的参考答案得到相应的Loss,借此进行参数更新。
以上是训练部分,具体的解码过程如下图:
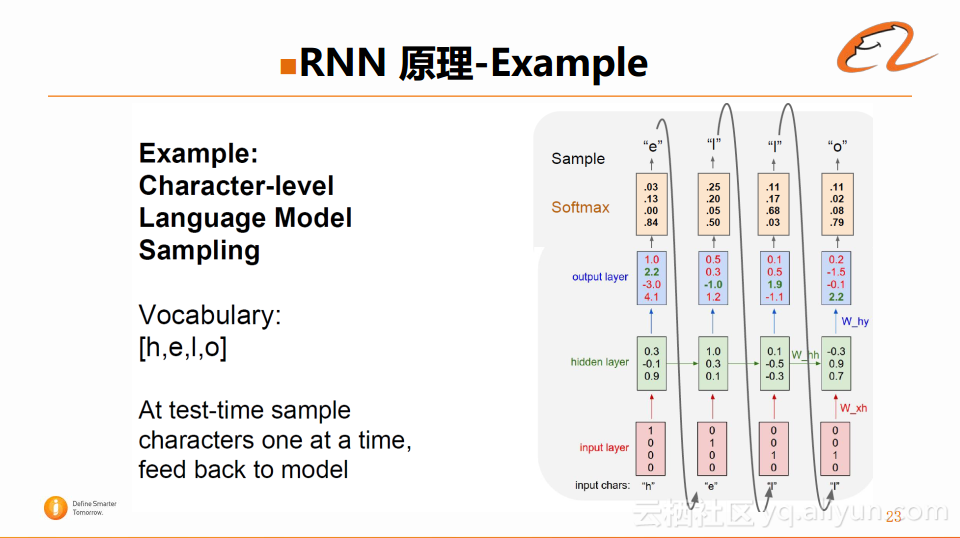
假设拿到的第一个字符是‘h’,但是却不知道该字符的后续字符是什么,然后借助模型,经过隐藏层,得到输出层的输出,通过Softmax对输出进行概率化,然后取其中生成概率最大的字符作为输出。显然在输入字符‘h’时,最后得到的概率最大的字符就是‘e’,然后以此类推,就可以得到“hello”这个序列的预测。整个流程就是通过当前输入的字符预测出下一个字符,最终预测出一个完整的序列。
3、Attention机制
注意力机制(Attention Mechanism)在很多任务中对性能有着很大的影响。例如在sequence to sequence model中(第一个sequence指原文,第二个sequence指译文),如下图所示:
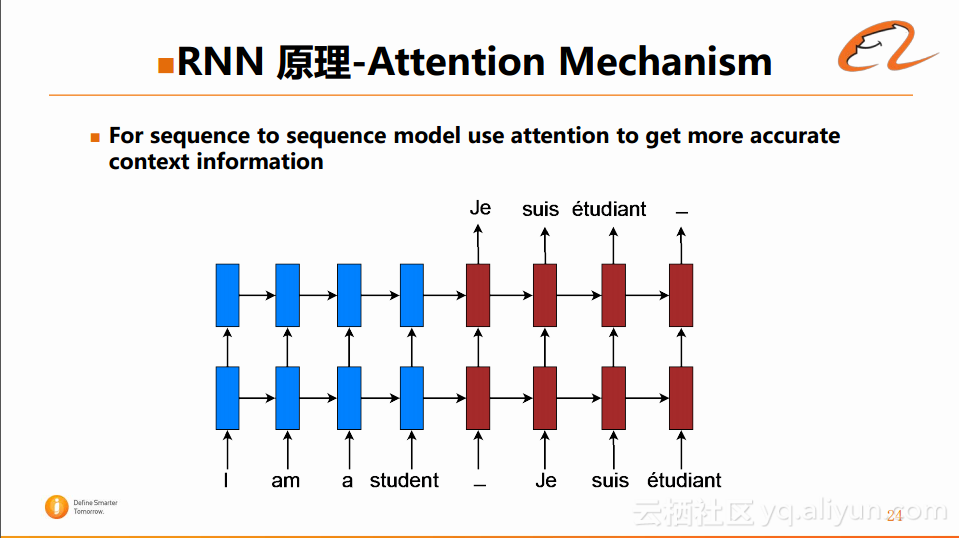
图中将英文的“I am a student”翻译成法文,在即将生成目标端的词语的时候,RNN模型会将源端的所有信息压缩在一个隐藏层当中,然后将该信息输入下一个sequence中进行翻译的预测。当源端的序列很长的时候,一个隐藏层很难存放这么多源端的信息,这样在信息严重压缩之后,在目标端生成翻译的时候,会导致所需的上下文的信息是不够的。这也是RNN在实际使用中常遇到的一个问题,在目前可以采用下图中的方法进行避免:
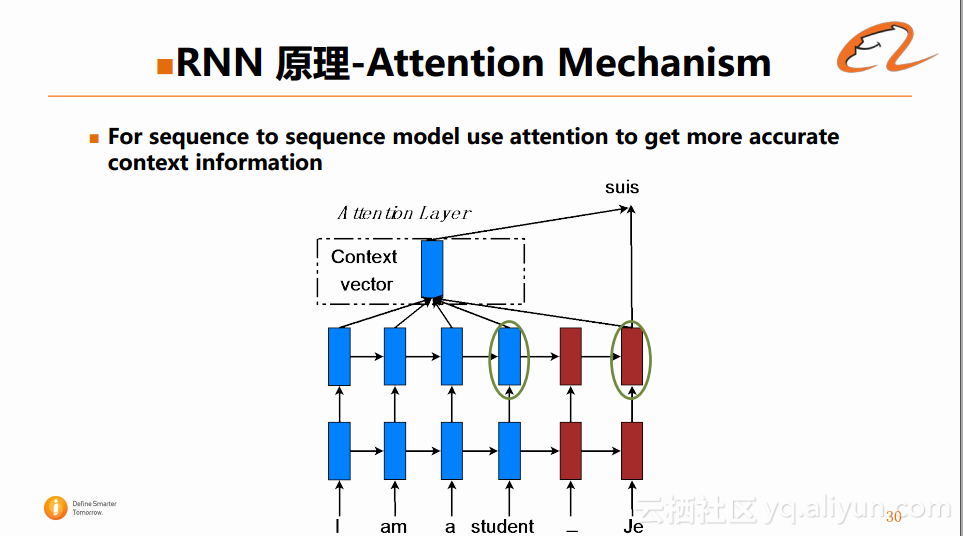
在生成第二个单词的时候,根据目标端的隐藏层状态和源端的每一个隐藏层之间做相似度的计算,根据规划得到一个权重的得分,接着生成一个上下文的Attention Layer,借助于这个Attention Layer作用于生成第二个词的过程,进而生成正确的翻译。Attention的这种机制其实是很符合翻译的这种直觉的,即生成每一个词的时候,关注的源端位置是不一样的。在实际的应用中,Attention的这种机制的表现也非常好,这个也解决了RNN在长序列压缩中造成的信息丢失的问题。
二、RNN存在的问题及其变种——LSTM
前文中介绍的Backpropagation,即从sequence的末尾将梯度传回至sequence的开头。但是在梯度回传的过程中,它每一次的回传都要与循环网络的参数W(实际上是W的转置矩阵)进行矩阵相乘,其实际的数值转换的公式如下图:
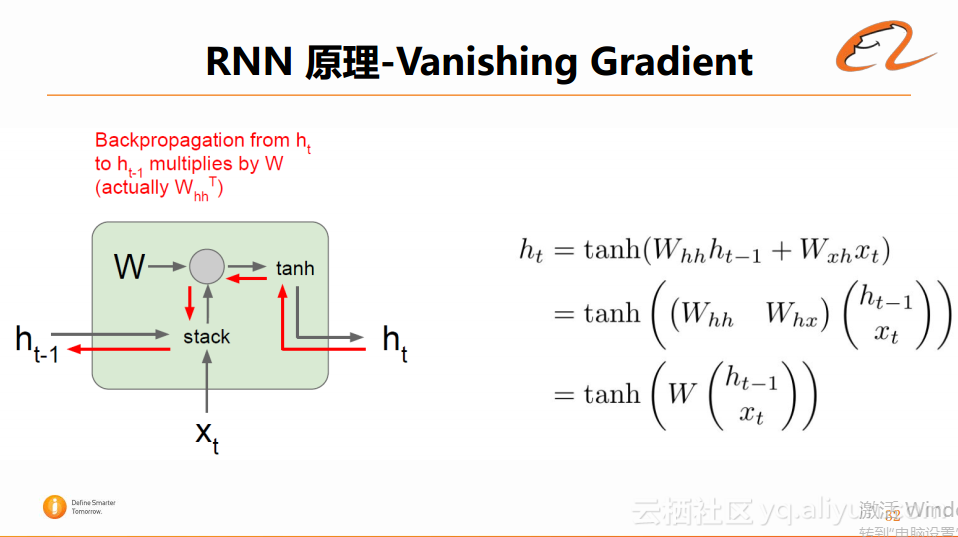
由于在每一次回传的过程中都需要与W进行矩阵相乘,并且重复进行tanh计算,如下图所示:
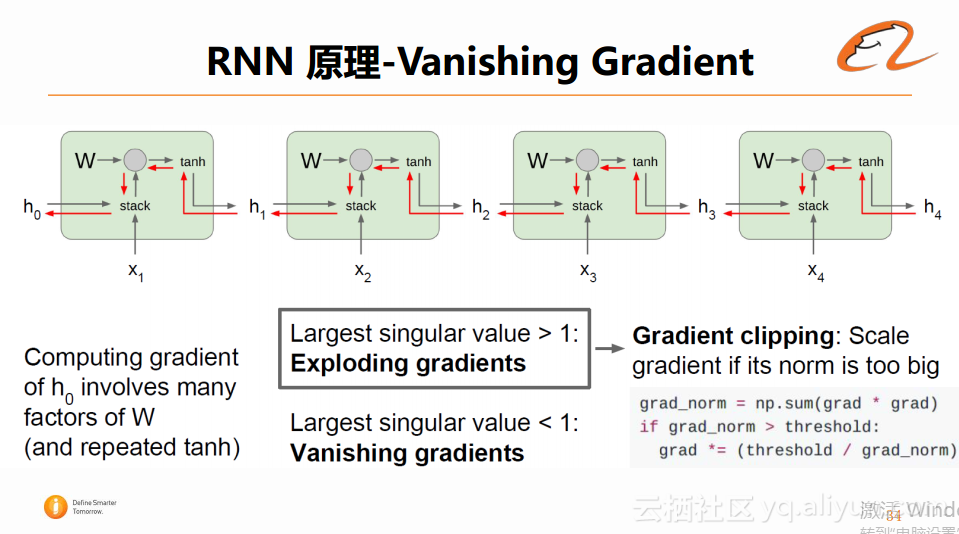
这样在训练上会带来一些问题:
1、当W的值大于1且这个序列足够长的时候,这个回传的梯度的数值就会变得无限大。
这种时候,可以采用Gradient clipping的方法解决,即将梯度重新进行数值变换到一个可以接受的范围。
2、如果W的数值小于1,就可能会造成梯度消失(导致完全无法更新)的问题。
这种时候,无论对梯度进行什么数值操作,都无法使用梯度来对参数进行更新,这时候可以考虑改变RNN的网络结构来克服这个缺陷,LSTM也就应运而生了。
LSTM与RNN相比,它将原有的网络结构拆成了更细的结构,如下图所示:
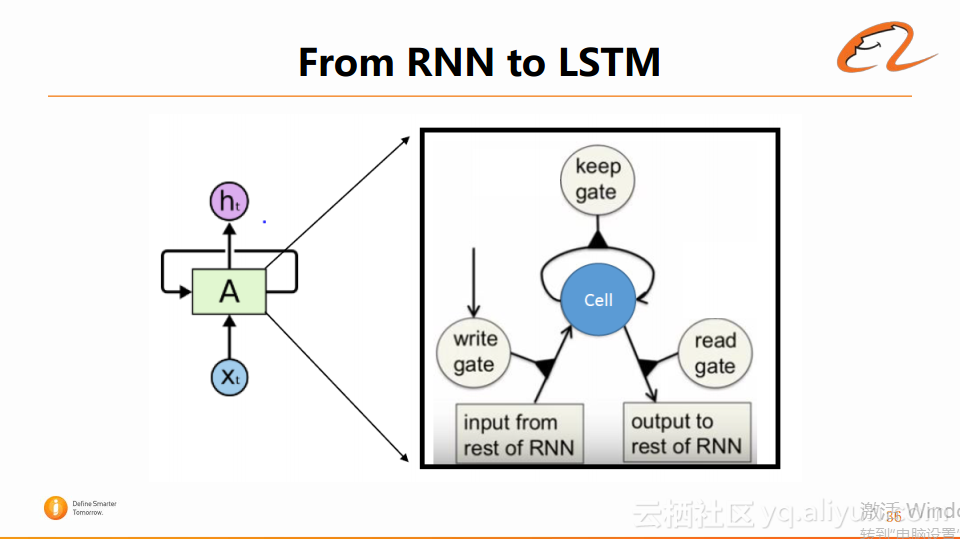
可以看到,LSTM引入几个门的限制,例如keep gate、write gate和read gate。通过这些门来控制LSTM的信息传输量。其实际的结构如下图所示:
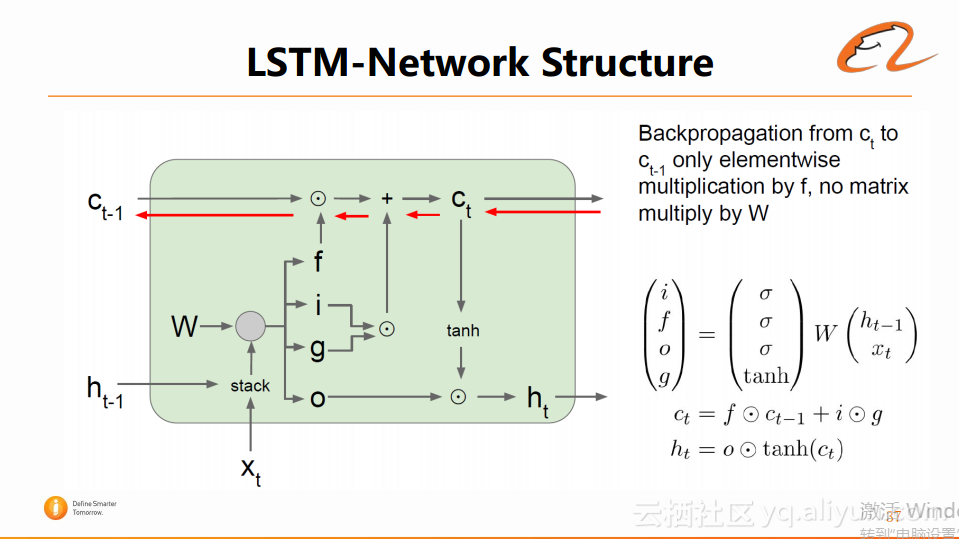
其中,f代表forget gate,i代表input gate,o代表output gate。上层的c在传输的过程中,只与这些门限的值进行数值变换,而不用跟整个网络参数W进行矩阵相乘,这样就避免了RNN回传梯度时可能发生的梯度爆炸或梯度消失的问题。
这些门限具体分为以下几种:
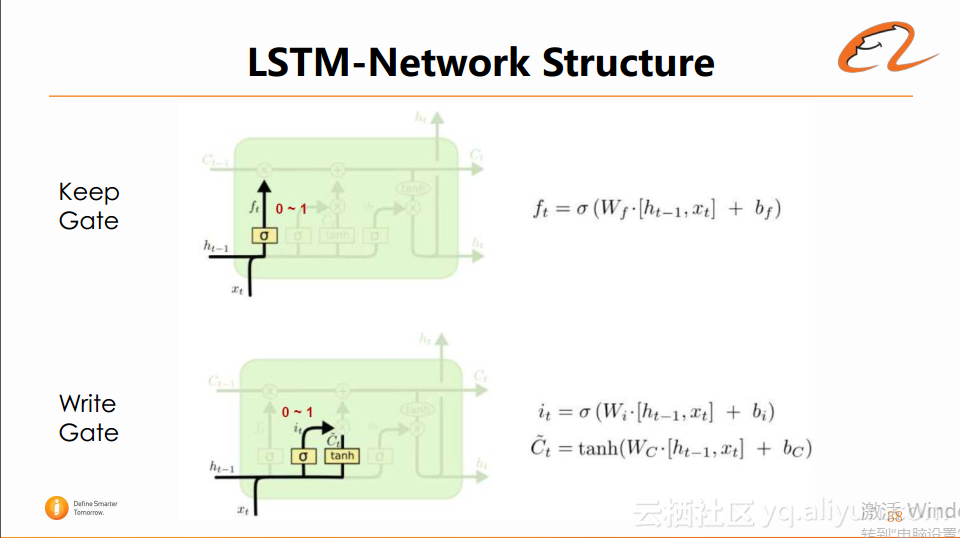
1、Keep Gate:它的作用是使LSTM的cell根据不同的输入去选择记忆或者遗忘前一个状态中的信息。
2、Write Gate:它用于控制LSTM的cell接受新的输入的百分比。
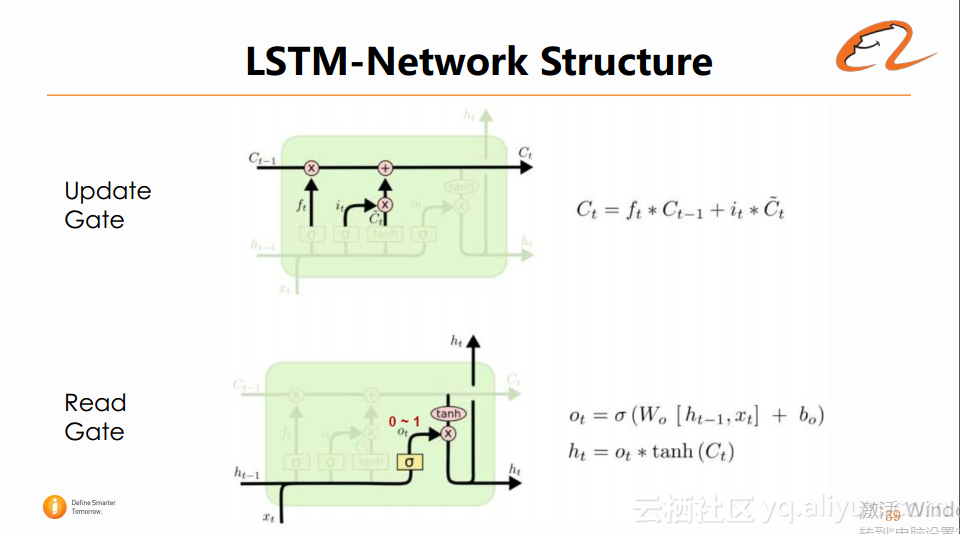
3、Update Gate:它实际上是对cell的更新,用于综合前一时刻状态与当前时刻状态。
4、Read Gate:它用于控制当前状态与Ct的信息的输入。
通过加入这几个门限,实际在循环网络结构ct-1到ct传播的过程中,只有一些较少的线性操作,并没有乘法操作。这样的好处在于它的gradient flow没有被过多的干扰,即整个流程中梯度的传播是非常通畅的,这样就解决了RNN中梯度爆炸或者梯度消失的问题。
而LSTM也存在一些变种:
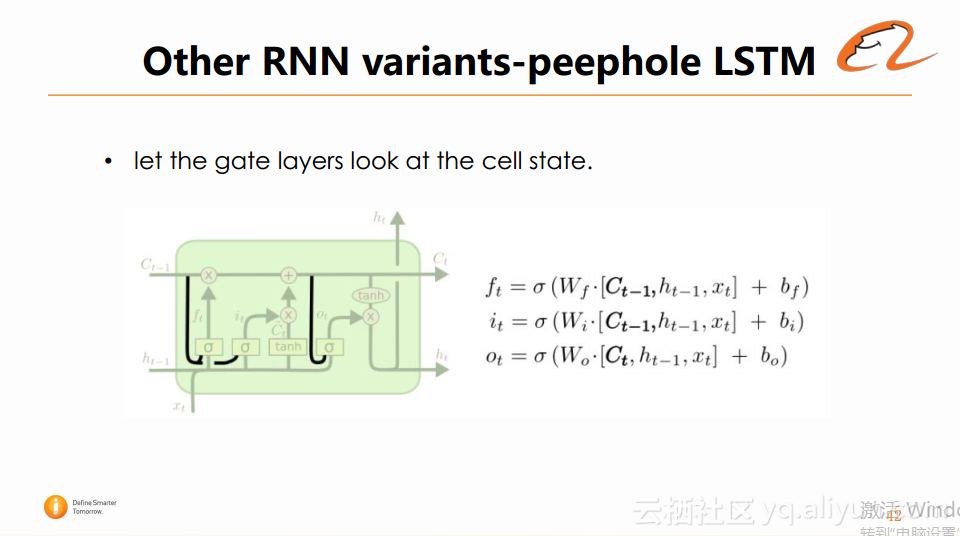
1、peephole LSTM。在LSTM中,门限的数值和cell都是无关的。但其实这些cell是可以加入门限的计算过程中,去影响每个门限的值,这样整体上信息的流动就会更加通畅,在门限的计算上也会更准确一些,在某些任务上会取得更好的效果。
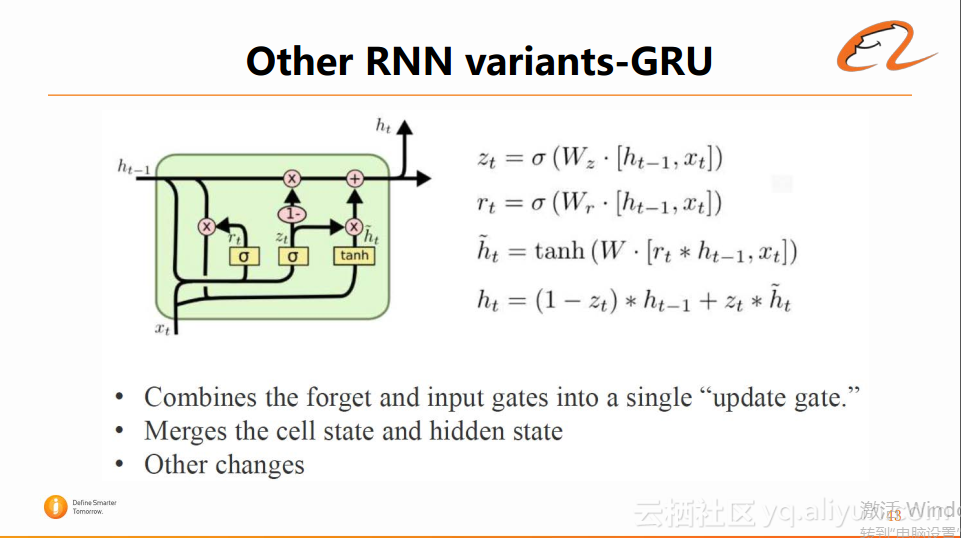
2、GRU。它将forget gate和input gate合成一个update gate,这个gate用于综合控制cell的读和写,这样可以简化LSTM的参数,此外它还将cell state和hidden state进行合并。总体而言,它是一个比LSTM更加简化的结构,在训练上更加容易(参数少)。
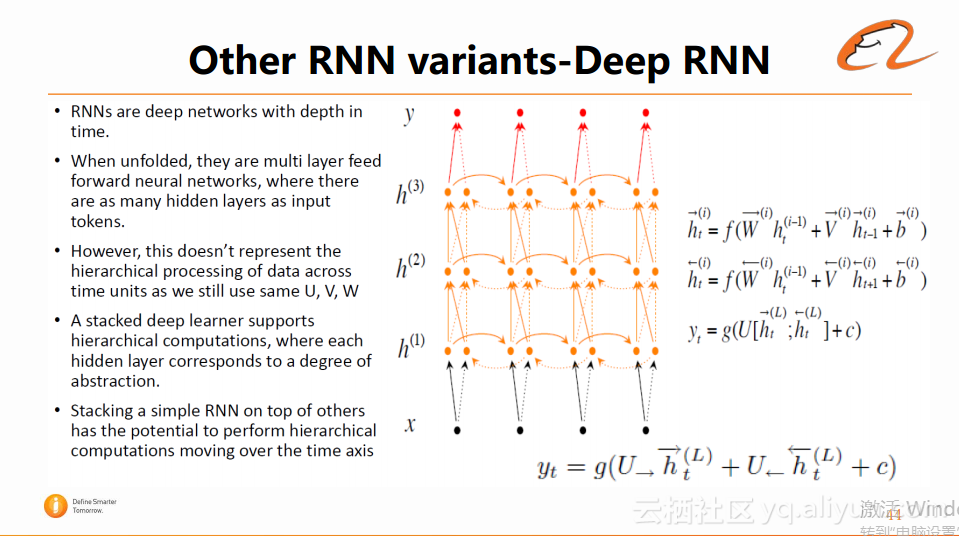
3、Deep RNN。在RNN中,比较缺乏CNN中的层次化的结构,为了解决这个问题,它将多个RNN累积在一起,形成一种层次化的结构,并且不同层之间也存在网络连接,这样的好处在于每一层都可以代表一个信息抽象,另外它会吸收computation network的优势——同时兼容RNN和CNN。这种网络结构在机器翻译、对话等领域都有很好的应用。
三、RNNs的“不讲理有效性”
1、Image Caption
Image Caption,即对图片的文字解释。如下图所示:
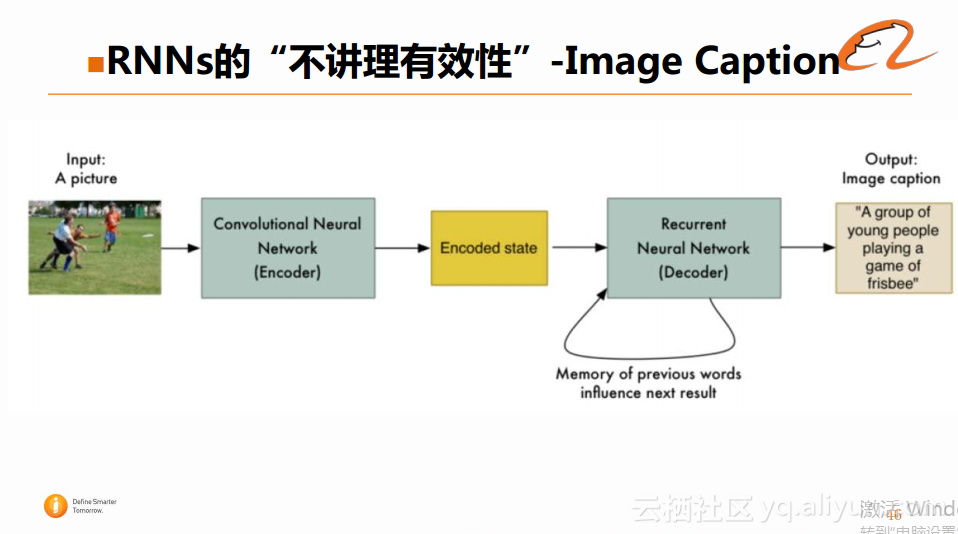
可以看到,输入是一张图片,输出是对该图片的文字解释。具体实现流程如下:首先使用CNN(卷积神经网络)进行建模,然后将这些信息综合到Encoded state中,将其作为RNN的输入,然后逐词生成图片的描述,最终得到完整的图片描述。
具体来看,它结合CNN和RNN的网络结构,如下图所示:
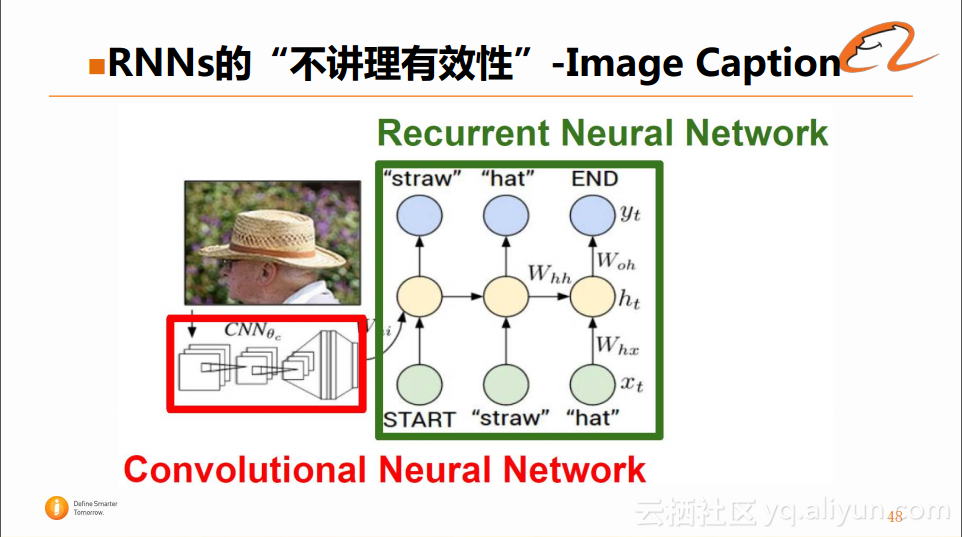
之所以这么使用,是因为CNN适用于图片的建模,而RNN适用于自然语言处理。因此可以先使用CNN对图片中的信息进行卷积,然后将得到的结果作为RNN的输入,去不断的生成图片的描述。
当然在这个过程中,也离不开Attention的机制,具体的流程如下图:
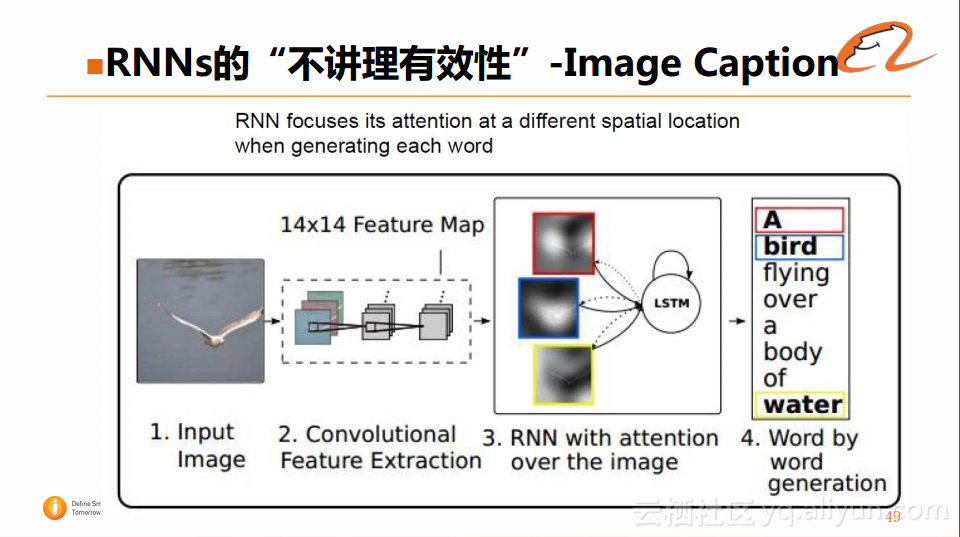
因为在生成图片的描述的时候,不同的词对应的图片的位置是不同的,如果采用Attention的机制,会使得图片信息的捕捉更为准确,而不是将图片的所有信息压缩到一个隐藏层里面,使得上下文的信息会更加丰富。
下图包含了一些有意思的例子:

第一幅图片在生成frisbee这个单词的时候,可以观察到,frisbee那块区域是高亮的,即它关注的区域十分正确。同样,在第二个图中的dog和第三个图中的stop都是Attention机制良好作用的体现。
就实际而言,Image Caption是一个比较难的课题,上文中都是给的一个很好的例子,当然也会存在一些很差的例子。如下图所示:

第一幅图中,这个女生穿的衣服十分像一只猫,在实际的图像描述的生成过程中,这件衣服被错误的识别成了一只猫,最终才得到了图中的错误的描述。又如最后一幅图片中,运动员实际上在接球,但是他的运动形态没能被捕捉到,才生成了他在扔球的这样一个错误的描述。可以看到Image Caption目前还是处于一个实验的阶段,还没有达到商业化的水平。
2、QA
在RNNs应用中另外一个比较火的是QA(问答系统)。它实现的链路跟上个例子有所类似,但是有一个不同之处在于:对于输入的问题,它采用了RNN而不是CNN进行建模,具体实现流程如下图所示:
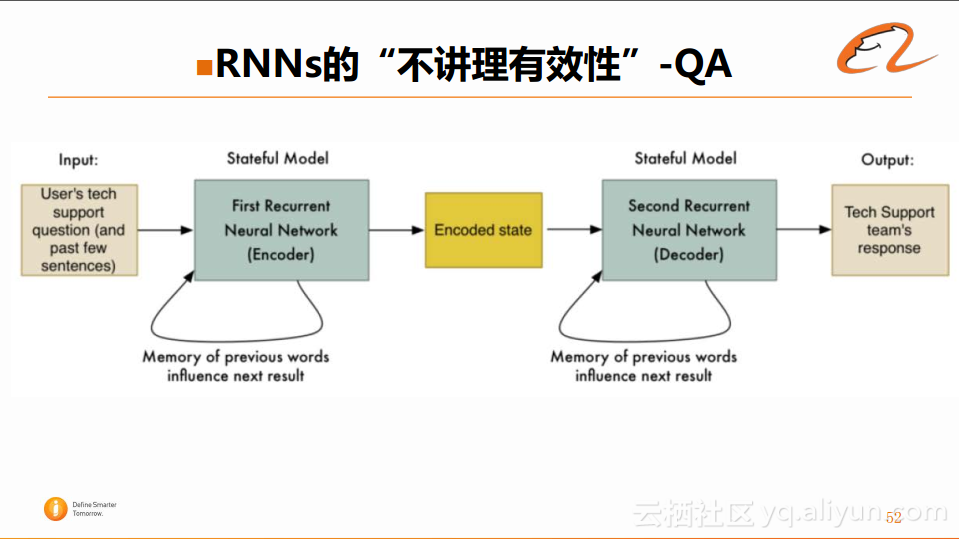
这就是人们常提到的Sequence to Sequence Model,即输入是Sequence,输出也是Sequence。对于输入的问题,先通过循环神经网络进行建模,然后将得到的Encoded state输入到另一个循环神经网络中,然后逐词的生成最终的回答。
在另一些例子里面,不仅会有文字的输入,还有图片等信息的输入,并且这些问题是基于图片中的场景来进行提问的,这样就会产生图片和文字联合组成QA的应用。以下图为例:
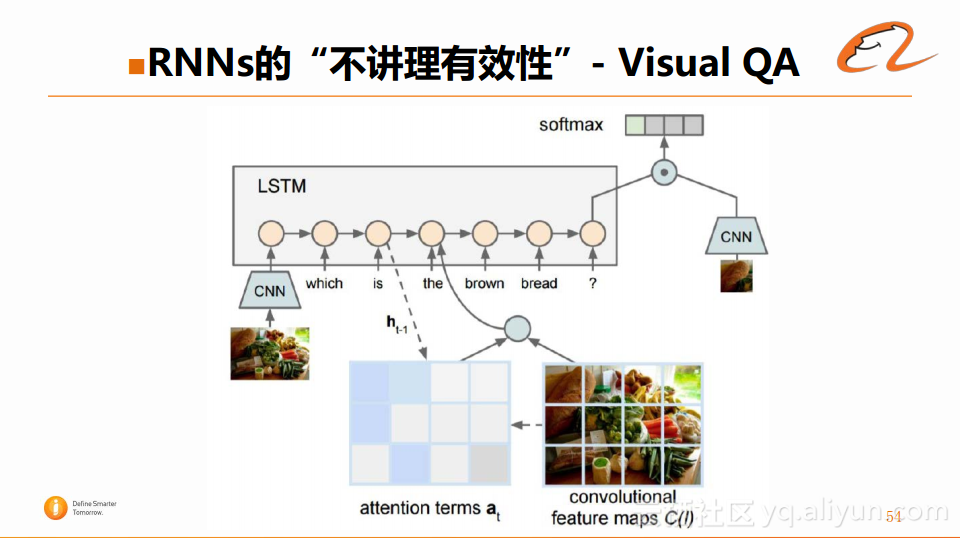
在LSTM建模的初始阶段,是使用了CNN将图片压缩作为了第一个隐藏层的状态,并且将问题也通过LSTM进行联合的建模,最终将整体的信息融入到encoder里面,并生成对应的翻译。从图中也可以看到,CNN和LSTM是可以紧密的联合在一起共同工作的,并且还可以通过Attention机制达到更好的交互。
下图是实际应用中一个比较有意思的例子:
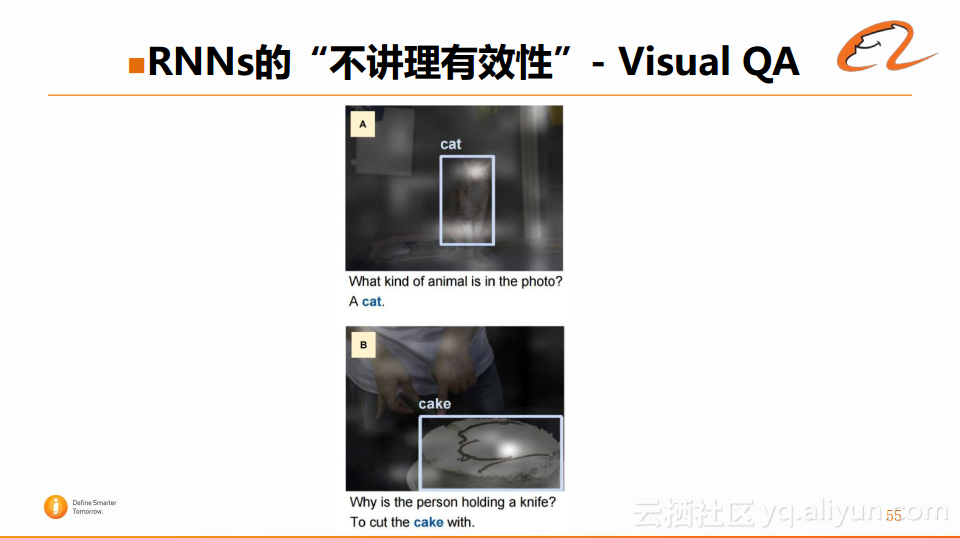
问A图中是哪种动物,在Attention机制中,捕捉到的这个猫的位置(白色方框)是比较集中的,这对于解答这个问题会起到很好的作用。在图B中问这个人拿到在切什么,显然白色方框聚焦的位置也是正确的。
3、Machine Translation
下图中这个例子就是机器翻译的链路,也是通过多层的RNN进行的建模,最终生成一个Final input matrix,然后借助Attention的机制,逐词生成目标翻译。
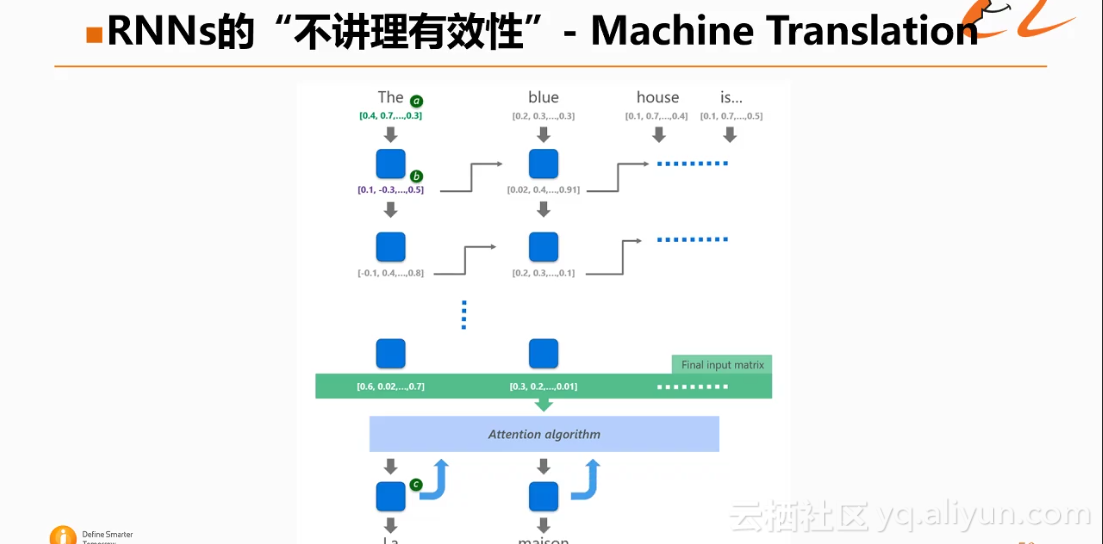
上图就是机器翻译过程的整体示意图。此外,Google提出的神经网络的翻译的架构如下图所示:
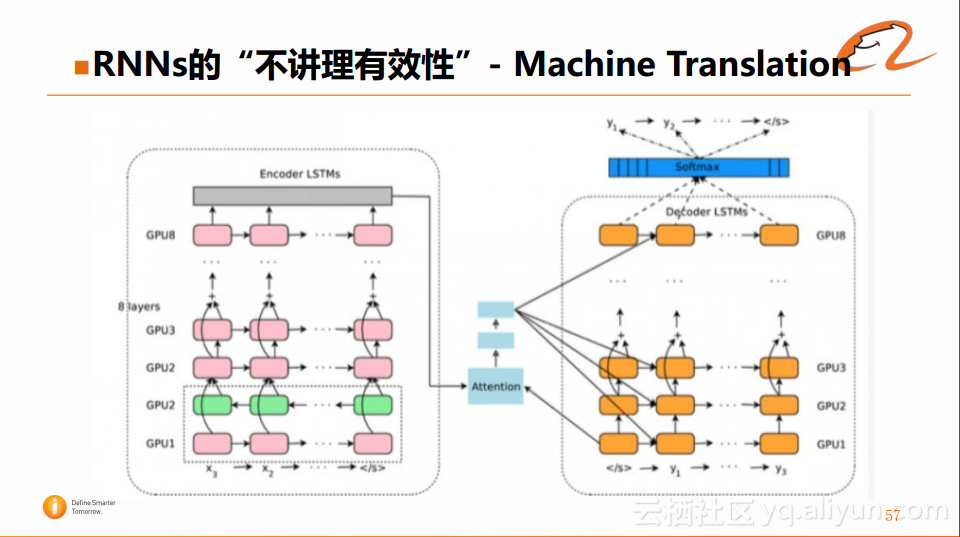
在Encoder端有八层LSTM堆砌在一起的,这样便于对输入句子的含义进行更好的理解。然后通过Attention连接到另外一个八层LSTM的Decoder端,最终将结果输出到一个Softmax,来进行翻译的预测。
实际还有一种另外的交互的翻译方式——Speech Translation,如下图所示:
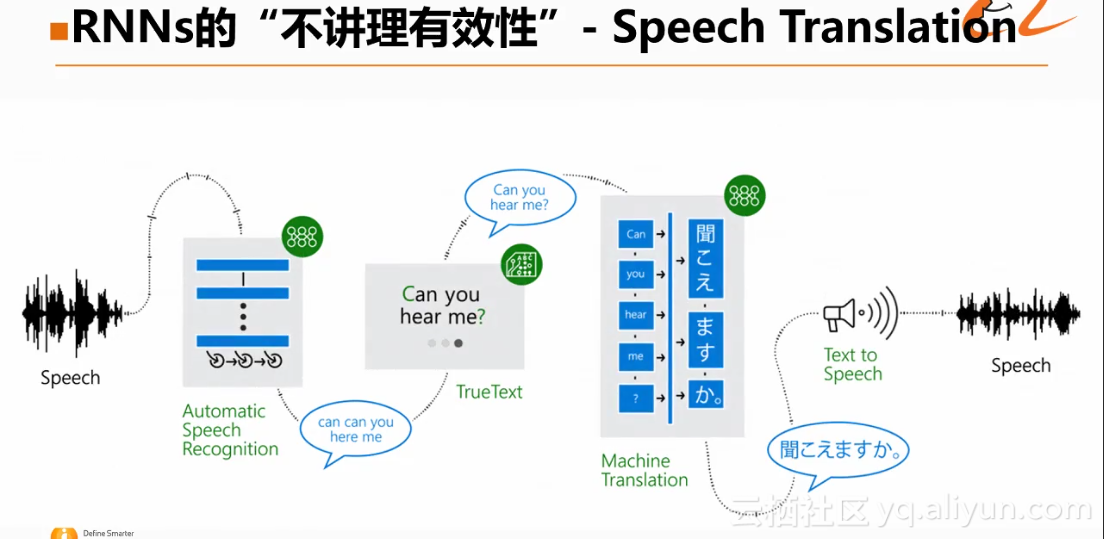
即通过一个语言的序列,通过一个神经网络,得到语音识别的结果,然后对该结果进行拼写纠正、标点处理等,得到一个较好的语音识别的text,再将其输入到神经网络机器翻译系统中,生成对应日文的翻译,再借助于Text to Speech的系统,生成对应的日文的语言。
四、RNNs的阿喀琉斯之踵
1、RNNs对层次信息的表示能力和卷积能力都存在一些不足。因此产生了一些如Deep RNN、Bidirectional RNN和Hierarchical RNN的变种,都希望通过更层次化的网络结构来弥补这种不足。
2、RNNs的并行度很低。它的当前时刻的隐藏层的状态依赖于之前时间的状态,并且训练和解码的并行度都很低。
为了解决上面的问题,提出了一种新的神经网络的架构——Transformer,如下图所示:
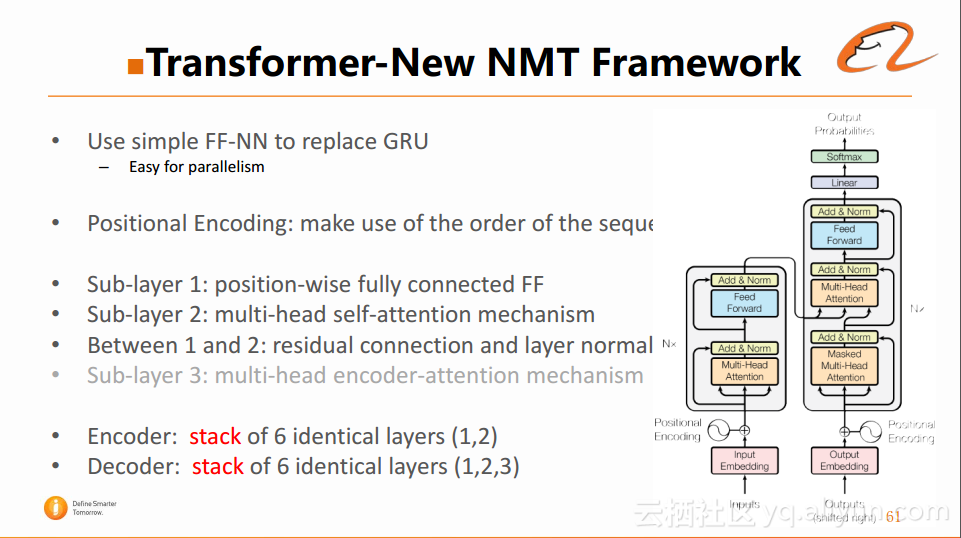
Transformer使用简单的FF-NN替代了GRU,这样就直接解决了在训练中难以并行的问题。但是由于取代了循环的结构,也会导致网络中各个位置的信息是缺乏的,也不知道序列的先后顺序。这时引入了一个Positional Encoding,对于每个位置都有一个Embedding来存储位置信息。在实际的网络结构中,可以分为几个Sub-layer:
Sub-layer1:即全连接的FF网络。
Sub-layer2:借助于sele-attention的机制来捕捉各个位置之间的关联关系。
Between 1 and 2:加入了residual connection和layer normal。
综上所述,而相比于RNN,Transformer有两大优点:
1、比RNN拥有更好的性能。
2、训练速度快了4倍。






