开篇
在实际的过程中,总需要对一些数据进行排序,在众多的排序算法中,快速排序是较为常用的排序算法之一。而网上对于快速排序的中文资料还不是很全。写 这篇博文主要记录一些自己对于快速排序的了解,以及对快速排序的性能的分析。我将在这里记录下我对快速排序的认识和学习过程 ,用尽可能简单明了的叙述来阐述我的理解。
快速排序基于算法中很重要的思想是 分治。所以会先介绍一下分治思想,然后对算法原理进行介绍,接着会分析算法的性能并对算法作进一步的讨论。
注:为了便于说明问题,本博文中会用到部分《introduction to algorithm》中的图片。
关键词:快速排序、分治、递归
“大事化小”——从分治说起
分治?
分治法是算法中常用的策略之一,很多算法都是基于分治法的,今天要说的快速排序也一样。为了能更好的理解快速排序,先简单的介绍一下分治法。
顾名思义,分治,可理解为分而治之。就是把原问题(递归地)分解为多个子问题(一般是和原问题本质相同的问题,只是规模上的缩小,如果现在不能理解请看后文解释),解决这些子问题,合并其结果,获得原问题的解。
简单的说就是“大事化小” 把复杂的问题分为多个简单问题,解决了这些简单问题,原问题也就随之解决了。
如何分治
从上面的分析中可知道,用分治的思想解决问题的步骤大致为:
分解(Divide):将原问题分为一系列子问题
解决(Conquer):递归的解决子问题。如果子问题足够小,直接解决子问题
合并(Combine):将子问题的结果合并为原问题的
借助下图,可更清晰的了解分治的思想:
如上图所示,原问题是规模为 n 的问题,在树的第一层,把问题分为规模为n/2的两个子问题,如果解决了这两个子问题,把它们合并就能得到原问题的解。
现在来看其中的一个子问题,为了解决他们,又把它分为两个规模更小的问题n/4。解决了规模为n/4的问题,合并之就能得到规模 n/2 的问题的解。
按照上面的思想,把原问题递归的分解为规模小的问题,然后合并之就能得到原问题的解。
到现在对分治的思想应该有了一定的认识,其实分治思想可谓博大精深,不是三言两语能讨论清楚的,这里这说明一个基本思想,就不做深入讨论了。
快速排序原理
基本思想:
上文已经说过快速排序是基于分治思想的,把问题的规模递归的变小,然后依次解决子问题,自后得到原问题的解。
既然是基于分治思想,那么快速排序步骤也和分治一样:
我们假设原问题是要对数组 A[p,r] 中的数据进行排序
分解(Divide):
将数组 A[p,-------,r] 分为两个数组 A[p,....,q-1 ] 和 A[q+1,.....r] 使得 数组 A[p,....,q-1 ]中的每一个数都小于q ,数组 A[p,....,q-1 ]中的每一个数都大于q。
其实这步的关键就是找到那个 q 然后遍历数组,把小于 q 的元素放在 q 的左边,大于q 的元素放在右边。这样就使得 q 左边的元素都小于 q 右边的元素。
当问题被分解的足够小,当 q 左边只有一个元素 a ,q 右边也只有一个元素 b 的时候,那么 a q b 就是一个有序数组,其实这也就完成了一次排序。
解决(conquer):
(递归调用快速排序),对数组 A[p,....,q-1 ] 和 A[q+1,.....r] 进行排序。对于其中的一个数组将被分为更小的数组,直到数组内数据有序。
随着问题规模的减小,数组内的元素也在减小,当数组内元素只有3 个的时候,它的下一次分解会产生两个规模为 1 的问题,这也就是上面说的“数组内部有序”的状态了。
下面是一个图示:
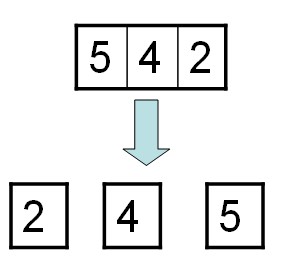
假设问题一直被分解,直到上图中数组有三个元素的状态 ,这个状态再分解就得到箭头下方所指的状态,可以发现,这个状态已经是有序的了,直接合并,就能得到有序序列。
合并(combine):
如上文所说,两个数组都是经过排序的(其实每个数组内只有一个元素了,所以也不存在什么排序),所以直接合并就能得到有序的数组。
算法说明
算法
下面是快速排序的算法说明:
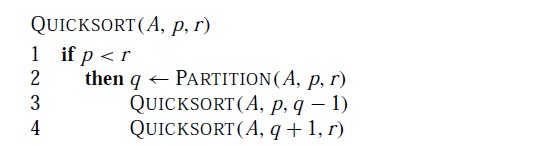
快速排序的函数是"QUICKSORT()"该函数有三个参数,
第一个参数A 表示要排序的数组,也就是给该函数传入要排序的数组的指针。
第二个参数p 和 第三个参数 r 标记出了要排序的数组的范围,即:这函数将数组A 的第p个到第 r 个参数排序。
下面是对这个算法的分析:
算法的第1行判断要排序的数组是范围是否合法,p 表示的是开始的位置, r表示的是结束的位置,所以只有p<r 才能进行排序。
第2 行:其实就是一个问题分解的过程,从数组中选一个元素q(可能是任意选择的,也可能存在其他的选择方式);
然后将数组A中的元素分为两部分:小于q的部分[p....q-1]放在q的左边,和大于q的部分[q+1....r]放在q 的右边。至此,原来要排序的数组A[p...r]被分为了两部分。
只要按照上面所做的,再对这两个新产生是数组进行排序就行了。也就是第3 和第4行所做的事情。
分治思想的体现:
从中也可以看出分治的思想,算法中的第2行通过q 把原问题分解为两个规模较小的问题,注意:只是规模缩小了,问题的本质并没有改变,对于被缩小后的问题,还是要进行排序。第3 、4 用同样的方法来处理问题。因为问题的本质没变,只是规模的缩小,所以还是可以调用解原问题的那个函数,只要修改参数就可以了。这时候我们就能更好的理解函 数"QUICKSORT"了,它有三个参数,后面的两个参数正是用来控制问题规模的。可能有人已经看出来了,这里还体现出递归的思想:在解决的过程中调用 自身。当然了 ,对于递归这里就不做深入讨论了。
关键部分:
在上面的算法中,其实最关键的还是第2 行的那个Partition()。正是这个函数,将问题分解成了问题本质不变而规模变小的子问题,这个函数的实现也是这个算法的关键。
基本思路:
Partition(A,p,r)的目的是将从数组A[p....r]中选一个数q,将小于q的元素放在q左边,大于q的放在右边。可以先自己思考 一下这个算法能怎样实现。
一种简单的想法是:申请一个大小为(r-q)的空间B[ ],遍历数组A[p...r],将每一元素和q比较,如果小于q 就从左边放入新申请的空间中,如果大于,就从右边放入。
最后把A[p...r]中的内容用b[ ]中的内容替换。当然,这是最直观的思维,这样做明显的空间和时间复杂度都不好。所以这不是快速排序中所采用的策略。
下面是快速排序所使用的Partition(A,p,r)的实现:
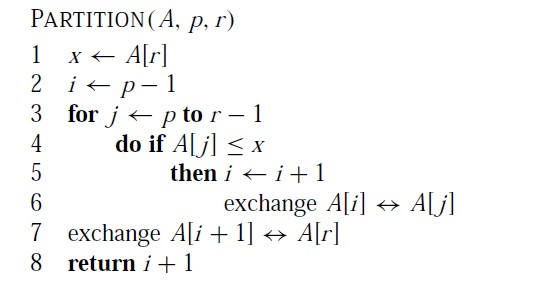
我的建议是:最好自己先分析一下这个算法,也很值得分析。我觉得它对空间和时间的处理真的很妙。画一个图会对分析很有帮助。
下面对这个函数的实现做一些简单分析:
第1行,函数选择x=A[r]来作为分界点,也就是上面所讨论的q。通过它把数组分为两部分。
第2行,定义了变量i,i 是一个维护“小于区”的指针。i 左边的元素都是小于分界点x 的元素。每当发现一个小于x的元素,就把它放在i 的后面,同时 i++;
第3行,for 循环并定义变量 j ,j 遍历整个数组,并和分界点x 进行比较(第4行)如果元素A[j]<=x,那么就把这个元素加入到小于分界点x的区域。同时i ++,
具体的实现就是5、6行的功能。
第7行,已经完成遍历,小于分界点x 的元素都在i 左边的区域中,右边的区域都是大于x 的,所以只要将分界点元素加入到他们中间即可。
实例是学习知识的最好途径!
本例将描述该算法对一个包含8个 元素的数组的操作过程。具体的操作过程如下图所示,函数中的变量在途中都已标出。
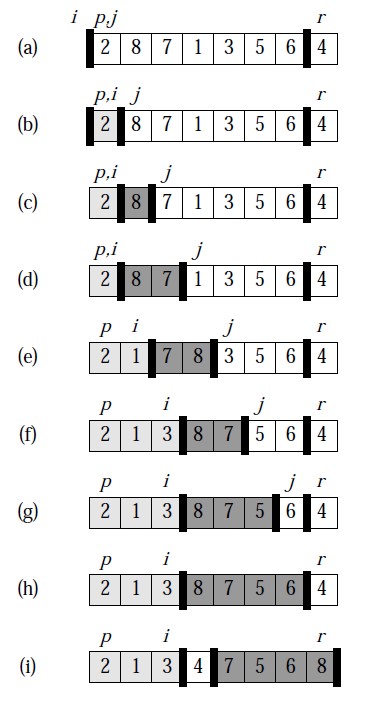
可结合算法和上文的算法分析来看这个图,思路就会变得清晰了。
算法性能分析
通过上面的算法分析已经知道,如果能“尽快地”把原问题分为规模小的问题(可直接求解的问题),那么它的效率是比较好的。如果每次划分都能平均的将 规模缩小一半,那么这种划分就是能最快到达目的的。而这种划分的结果直接和分界点 q 相关,如果每次划分时的q 选的足够好,也就是小于q 的元素个数等于 大于 q 的元素个数,那么这将是最好的情况。
当然现实中的情况不可能是这样,因为q 的选择往往是随机的。而且如果专门为选择一个合适的 q 又用一个函数来实现,那么算法的效率将得不到保障。
总结下上面所说的就是:快速排序的运行时间与划分是否对称有关。
最坏情况:
最坏情况也就是要划分最多次数。只要每次划分都把规模为n的问题分解为 n-1 和 1 。这种情况每一次的划分都出现这种极不对称的划分,它的效率将是最低的。
假设对规模为n 的问题的划分代价为f(n).
那么,对于规模为n 的问题的时间为:T(n)=T(n-1)+T(1)+f(n)。
T(1): 数组中只有一个元素,已经是最小,不用继续分解规模,所以划分时间f(1)=0;
所以 T(n)=T(n-1)+f(n)
这样看来, 如果将每一层的递归代价加起来,每分解一次,其时间复杂度为f(n*n) (n的平方)
如果每一层的划分都是极不对称的,那么算法的运行时间就是:f(n*n) 。
最佳情况:
上文中已经说过最佳情况,对于规模为n 的问题,最佳情况分为两个规模为n/2 的问题。表达其运行时间的递归式为:
T(n)<=2T(n/2)+f(n)
该递归式的解为:T(n)=O(n lg n).
划分的两端都是对称的,所以从渐进意义上看,算法运行的就更快了。
平衡的划分:
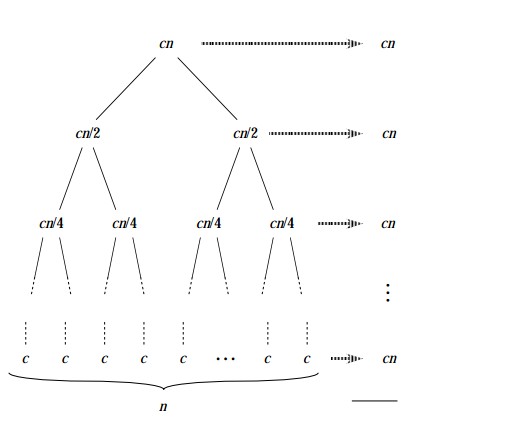
最佳情况和最坏情况都是实际情况中的两个极端,在实际中比较少见,所以这里讨论一下两者的折中。这里假设每次划分的过程总是产生9:1 的划分,应该比较“接近”实际情况了。
这时,快速排序的时间递归式为:
T(n)<=T(9n/10)+T(n/10)+cn
这里,我们显示的写出了f(n)中的常数c。下图显示了这个递归过程的递归树:
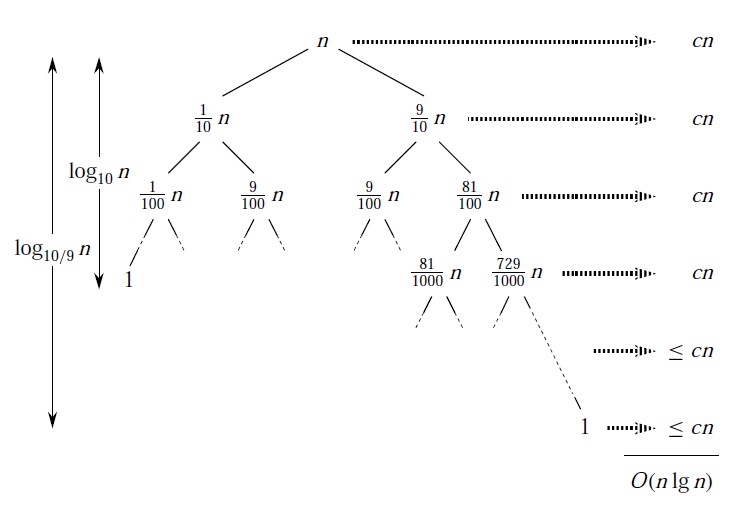
请注意这个树的每一层代价都是cn ,直到图中的倒数第三行未知,在此之前各层的代价至多为cn,后面的代价总是小于cn,
所以才有T(n)<=T(9n/10)+T(n/10)+cn。
这种情况下,快排的复杂度总为O(n lg n).从渐进意义上来说,这和平均划分的效果是一样的。
小结
关于快速排序的具体算法是现在网上有很多,这里就不写出来了,关键的是掌握其中的思想。
即:递归、分治。
转自:http://www.cnblogs.com/yanlingyin/archive/2012/04/16/2441979.html

微信公众号: 猿人谷
如果您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】
如果您希望与我交流互动,欢迎关注微信公众号
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。