摘要:MXNet是深度学习领域的主流框架之一,本文从特点,架构及编程模式等方面展开了对MXNet的全面介绍。解答如何在阿里云上快速部署和运行MXNet,以及介绍了阿里云上的MXNet一些性能实践。
数十款阿里云产品限时折扣中,赶紧点击这里,领劵开始云上实践吧!
演讲嘉宾简介:
谢峰(撷峰),阿里云异构计算技术专家。有丰富的X86、ARM、GPU虚拟化技术经验,加入阿里云之前,曾作为主要开发者参与基于API Remoting方案的GPU虚拟化项目,并负责基于Xen的NVIDIA vGPU虚拟化技术的引入和产品落地,并对智能手机虚拟化技术有深入研究。目前从事阿里云GPU异构计算基础设施的研发以及GPU在深度学习等领域的应用研究和性能调优等工作。
以下内容根据演讲嘉宾视频分享以及PPT整理而成。
本次的分享主要围绕以下三个方面:
一、MXNet 简介
二、阿里云上部署和运行MXNet
三、阿里云上的MXNet性能实践
一、MXNet 简介
1.MXNet特点
MXNet是一个全功能,灵活可编程和高扩展性的深度学习框架。所谓深度学习,顾名思义,就是使用深度神经网络进行的机器学习。神经网络本质上是一门语言,我们通过它可以描述应用问题的理解。比如,卷积神经网络(CNN)可以表达空间相关性的问题,使用循环神经网络(RNN)可以表达时间连续性方面的问题。MXNet支持深度学习模型中的最先进技术,当然包括卷积神经网络(CNN),循环神经网络(RNN)中比较有代表性的长期短期记忆网络(LSTM)。根据问题的复杂性和信息如何从输入到输出一步一步提取,我们通过将不同大小,不同层按照一定的原则连接起来,最终形成完整的深层的神经网络。MXNet有三个特点,便携(Portable),高效(Efficient),扩展性(Scalable)。
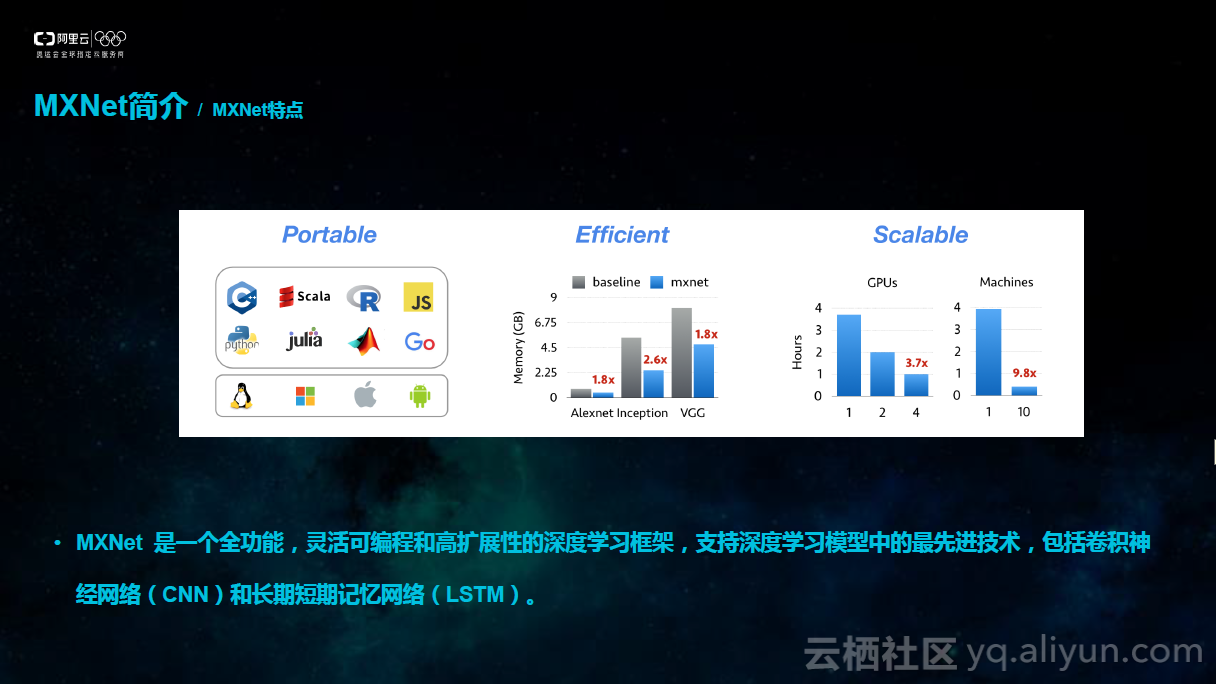
首先看第一个特点,便携(Portable)指方便携带,轻便以及可移植。MXNet支持丰富的编程语言,如常用的C++,python,Matlab,Julia,JavaScript,Go等等。同时支持各种各样不同的操作系统版本,MXNet可以实现跨平台的移植,支持的平台包括Linux,Windows,IOS和Android等等。
第二点,高效(Efficient)指的是MXNet对于资源利用的效率。而资源利用效率中很重要的一点是内存,因为在实际的运算当中,内存通常是一个非常重要的瓶颈,尤其对于GPU,嵌入式设备而言,内存显得更为宝贵。神经网络通常需要大量的临时空间,例如每层的输入,输出变量,每个变量需要独立的内存空间,这回带来高额度的内存开销。如何优化内存开销,对于深度学习框架而言是非常重要的事情。MXNet在这方面做了特别的优化,有数据表明,在运行多达1000层的深层神经网络任务时,MXNet只需要消耗4GB的内存。阿里也与Caffe做过类似的比较之后也验证了这项特点。
第三点,扩展性(Scalable)在深度学习当中一个非常重要的性能指标。更高效的扩展可以让训练新模型的速度得到显著提高,或者在相同的时间内,大幅度提高模型复杂性。扩展性指两方面,首先是单机扩展性,另一个是多机扩展性。MXNet在单机扩展性和多机扩展性方面都有非常优秀的表现。所以扩展性(Scalable)是MXNet最大的一项优势,也是最突出的特点。
2.MXNet编程模式
对于一个优秀的深度学习系统,或者一个优秀的科学计算系统,最重要的是如何设计编程接口,它们都采用一个特定领域的语言,并将其嵌入到主语言当中。比如numpy将矩阵运算嵌入到python当中。嵌入一般分为两种,其中一种嵌入较浅,每种语言按照原来的意思去执行,叫命令式编程,比如numpy和Torch都属于浅深入,命令式编程。另一种则是使用更深的嵌入方式,提供了一整套针对具体应用的迷你语言,通常称为声明式编程。用户只需要声明做什么,具体执行交给系统去完成。这类编程模式包括Caffe,Theano和TensorFlow等。

目前现有的系统大部分都采用上图所示两种编程模式的一种,两种编程模式各有优缺点。所以MXNet尝试将两种模式无缝的结合起来。在命令式编程上MXNet提供张量运算,而声明式编程中MXNet支持符号表达式。用户可以自由的混合它们来快速实现自己的想法。例如我们可以用声明式编程来描述神经网络,并利用系统提供的自动求导来训练模型。另一方面,模型的迭代训练和更新模型法则中可能涉及大量的控制逻辑,因此我们可以用命令式编程来实现。同时我们用它来进行方便地调式和与主语言交互数据。
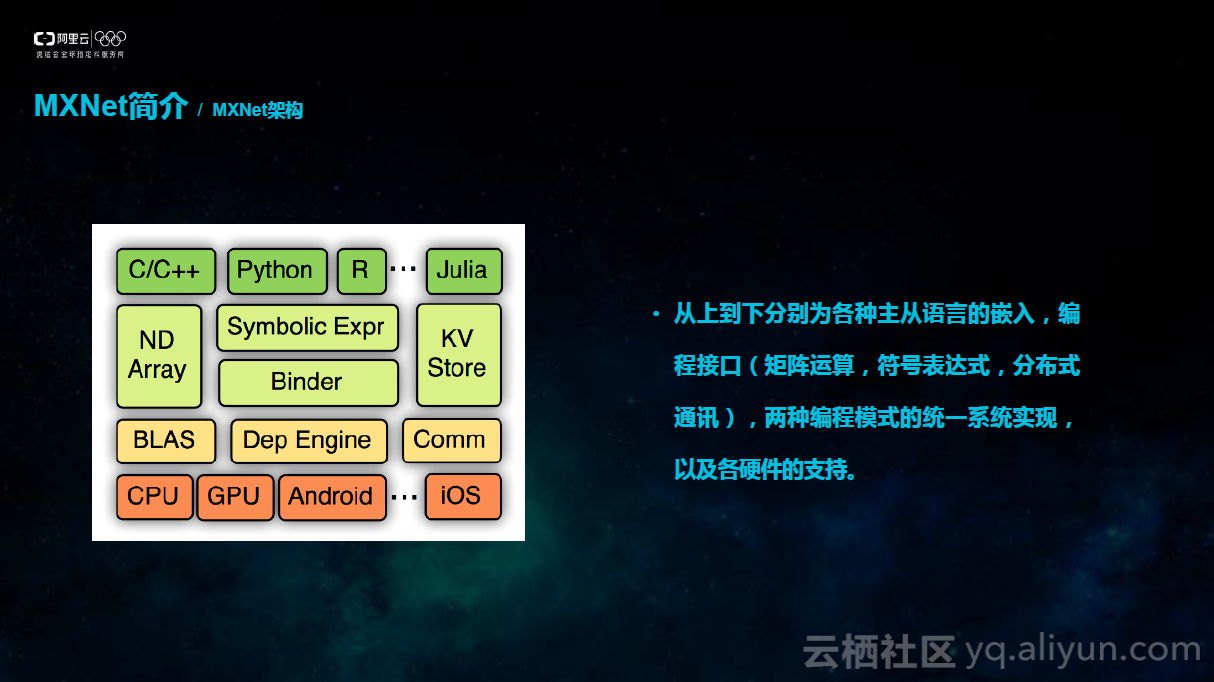
3.MXNet架构
下图中左边是MXNet架构图,从上到下是分别为各种主从语言的嵌入,编程接口(矩阵运算NDArray,符号表达式Symbolic Expression,分布式通讯KVStore),还有两种编程模式的统一系统实现,其中包括依赖引擎,还有用于数据通信的通信接口,以及CPU,GPU等各硬件的支持,还有对Android,IOS等多种操作系统跨平台支持。在三种主要编程接口(矩阵运算NDArray,符号表达式Symbolic Expression,分布式通讯KVStore)中,重点介绍KVStore.
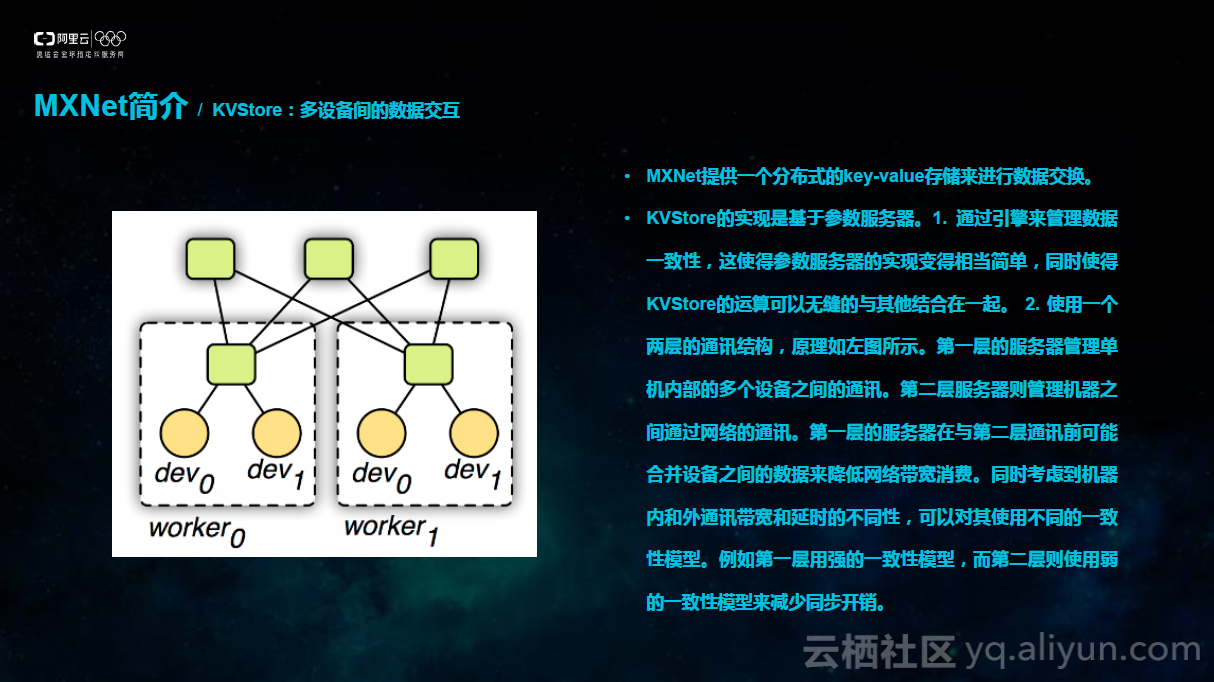
KVStore是MXNet提供的一个分布式的key-value存储,用来进行数据交换。KVStore的本质上的实现是基于参数服务器。1.通过引擎来管理数据一致性,这使得参数服务器的实现变得相当简单,同时使得KVStore的运算可以无缝的与其他部分结合在一起。2.使用一个两层的通讯结构,原理如下图所示。第一层的服务器管理单机内部的多个设备之间的通讯。第二层服务器则管理机器之间通过网络的通讯。第一层的服务器在与第二层通讯前可能合并设备之间的数据来降低网络带宽消费。同时考虑到机器内和外通讯带宽和延时的不同性,可以对其使用不同的一致性模型。例如第一层用强的一致性模型,而第二层则使用弱的一致性模型来减少同步开销。在第三部分会介绍KVStore对于实际通讯性能的影响。
二、阿里云上部署和运行MXNet
1.阿里云提供的弹性GPU服务
深度学习的发展依赖于三个重要的要素。第一,算法的大幅改进;第二个是大数据的提供;第三个是算力的大幅提升。其中GPU的性能大幅度提升是对算力的巨大贡献。阿里云提供的弹性GPU计算计算服务,提供了丰富的GPU实例、软件(镜像市场)和服务(如容器服务)来给客户。
1)GPU实例支持M40、P4、P100、V100多种GPU,和丰富的CPU、内存配置,覆盖深度学习训练和推理场景。
2)镜像市场提供了预装NVIDIA GPU 驱动和CUDA 库的镜像,以及预装开源深度学习框架(包括MXNet)的镜像。
3)提供容器服务一键部署、运行深度学习任务,提供ROS资源编排服务创建需要的GPU实例资源等等。

阿里云的容器服务可以提供分布式的运算模型,并且可以利用阿里云丰富的存储资源,如使用高效云盘或者SSD云盘,OSS对象存储,可以使用NAS文件存储来存储用户训练数据。
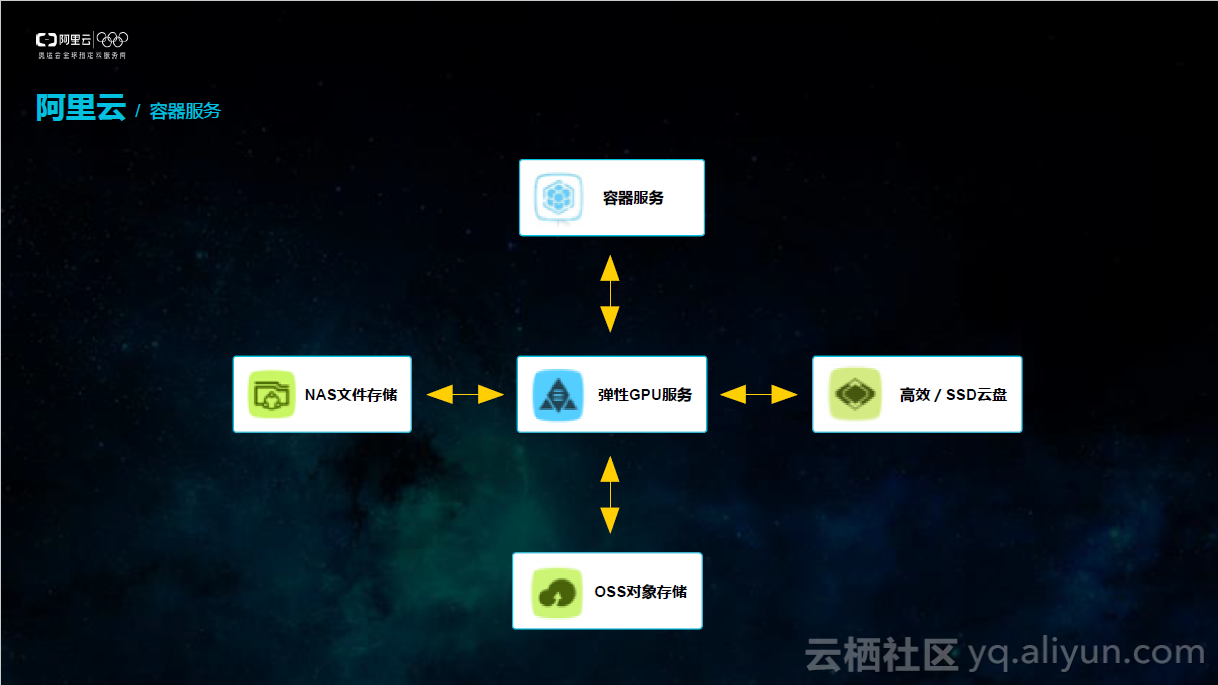
阿里云可以基于容器,实现弹性GPU服务一键式部署,包括支持GPU资源调度,挂载共享存储,负载均衡,弹性伸缩,CPU、GPU监控以及丰富的日志管理。
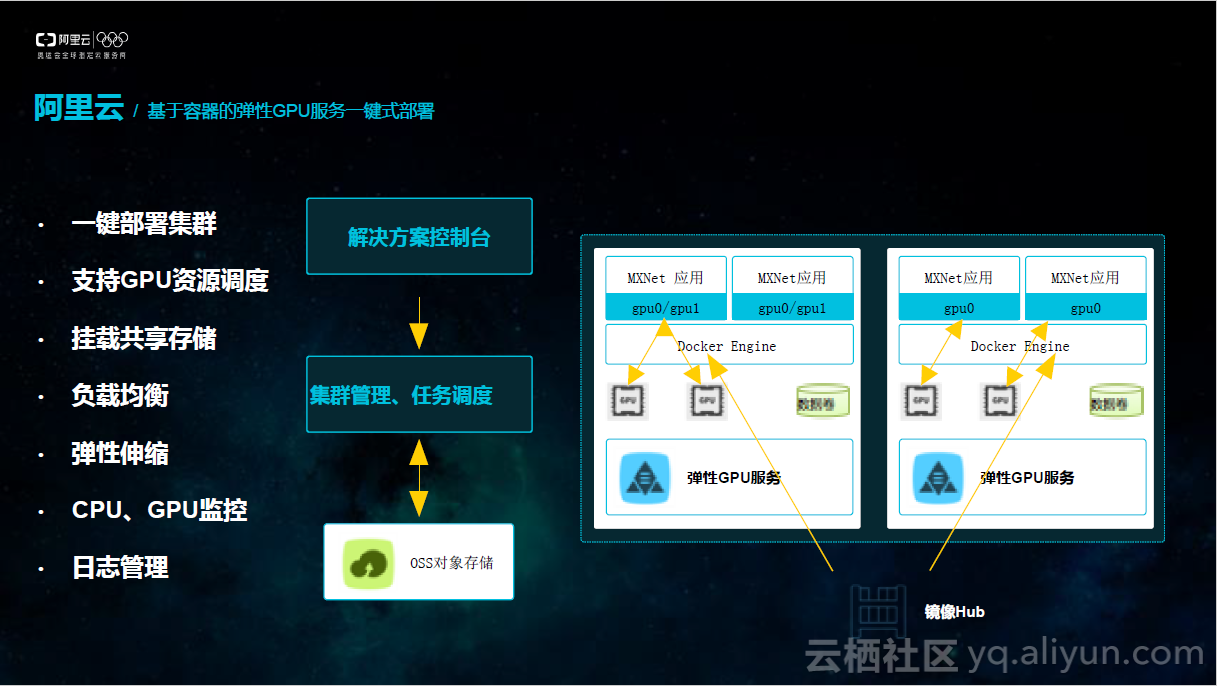
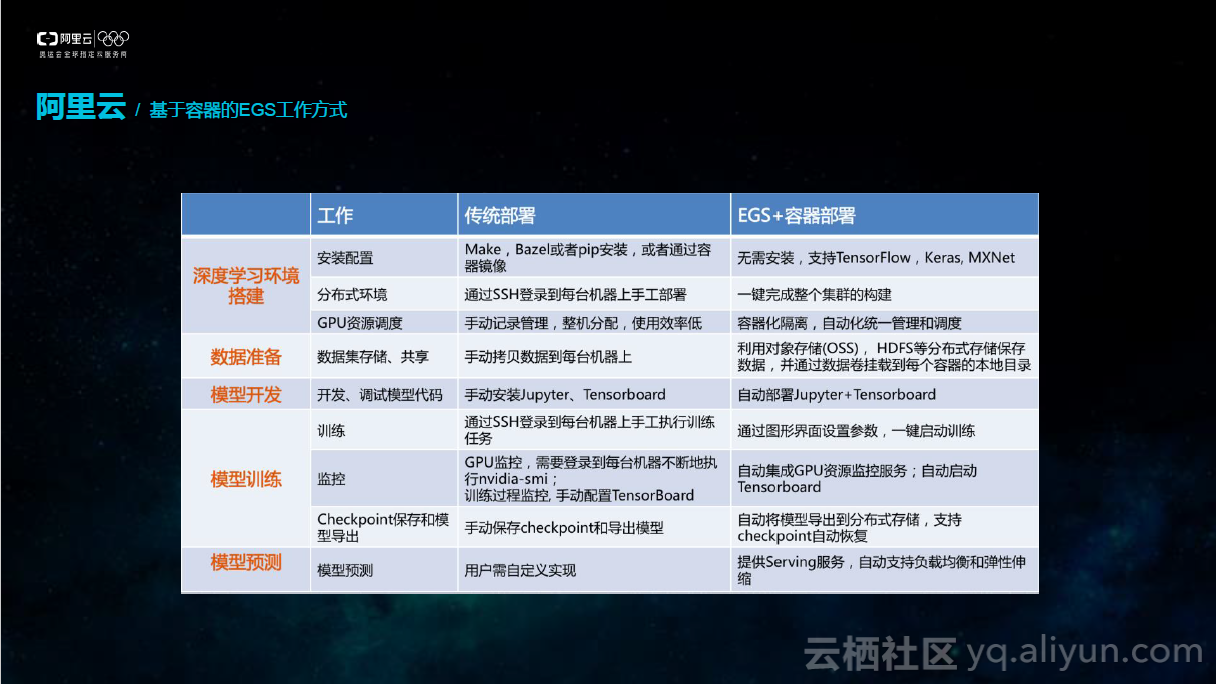
基于容器的工作方式相对于很多传统的方式有非常多巨大便利。我们需要搭建深度学习环境,对数据做准备,对模型进行开发,然后对开发的模型进行训练和预测。而传统的部署过程全部都需要手动完成,这是极其复杂的过程。利用容器的一键式部署可以极大缩短部署时间
2.使用容器服务部署MXNet
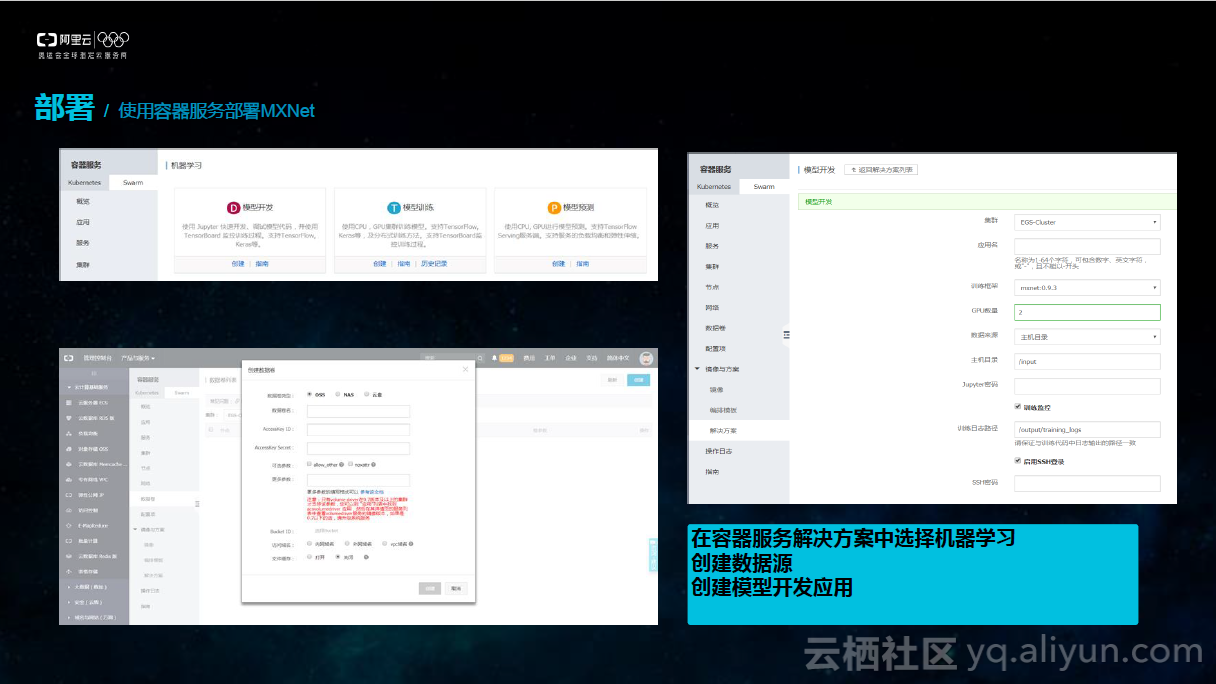
下面是使用容器服务部署MXNet的过程。首先可以在阿里云控制台上找到容器服务解决方案,如下图所示。在当中选择机器学习,可以看到支持模型开发,模型训练及模型预测。选择创建数据卷,可以选择OSS,NAS云盘等多种不同的存储设备,之后将训练数据放到存储设备上;可以选择模型开发,并且创建一个GPU集群,选择需要的训练框架,GPU数据,数据来源。数据来源可以是主机目录,或者是之前创建的数据源。之后便可以部署MXNet框架任务,部署过程是非常方便的。
3.基于Docker使用NVIDIA GPU CLOUD部署
我们还可以使用开源Docker部署NVIDIA GPU CLOUD镜像。NVIDIA GPU CLOUD实际上是一个开放的深度学习的容器镜像的仓库。我们可以通过安装最新的Docker,以及安装nvidia-docker的插件,之后注册NGC,pull最新的MXNet容器镜像。在MXNet容器镜像当中,NVIDIA装了最新的CUDA Driver,最新的深度学习加速库cuDNN,以及多GPU加速库NCCL等。所以我们可以使用已经优化好的整套软件来部署到系统之上。
4.一个简单MXNet单机训练任务的运行例子
1)选择一个单机图像分类模型的训练作为示例
2)选择CNN网络Inception-v3,选择Imagenet数据集
3)Github下载最新的MXNet源码,并且在Example中找到图像分类
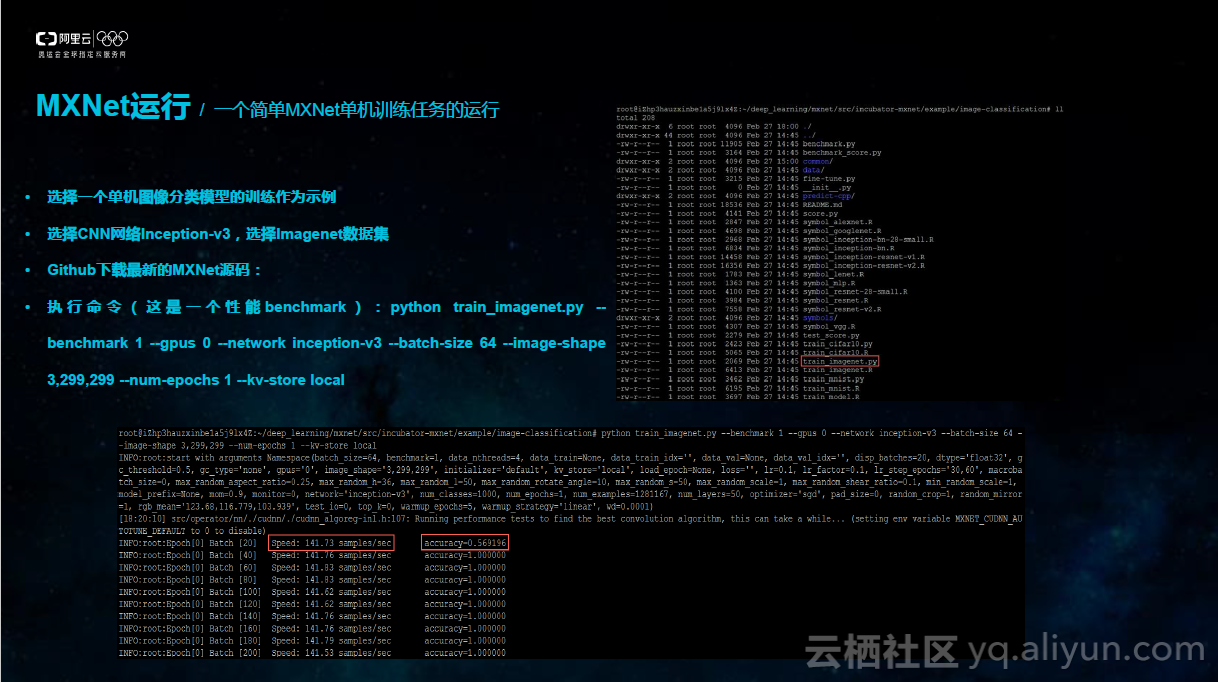
4) 并执行命令,运行train_imagenet.py(这是一个性能benchmark):python train_imagenet.py --benchmark1 --gpus 0 --network inception-v3 --batch-size 64 --image-shape 3,299,299 --num -epochs 1 --kv-store local
运行效果如下图中所示,我们可以发现运行之后屏幕会实时打印出当前运行的性能及精度,性能单位:每秒处理的图像张数。
三、阿里云上的MXNet性能实践
1.阿里云GPU服务器MXNet性能数据
首先来看单GPU性能数据,选择Inception-V3网络,用MXNet在ImageNet数据集上做图像分类模型训练的Benchmark性能测试。从下图中的测试数据来看,我们发现搭载V100的GN6实例因为使用TensorCore混合精度,性能接近搭载P100的GN5实例的3倍。可以看到由于NVIDIA每年在GPU硬件上的性能巨大的提升,使得在GPU上运行深度学习的速度大幅度提升。

之后看单机多GPU性能数据,使用GN5(P100)8卡实例,同样测试了MXNet的图像分类模型训练的单机扩展性。从下图中发现AlexNet,GoogleNet,Inception-V3和ResNet152等四种经典的卷积神经网络测试当中,单机多卡接近线性加速。这证明了MXNet在单机的扩展性上的确非常优秀。
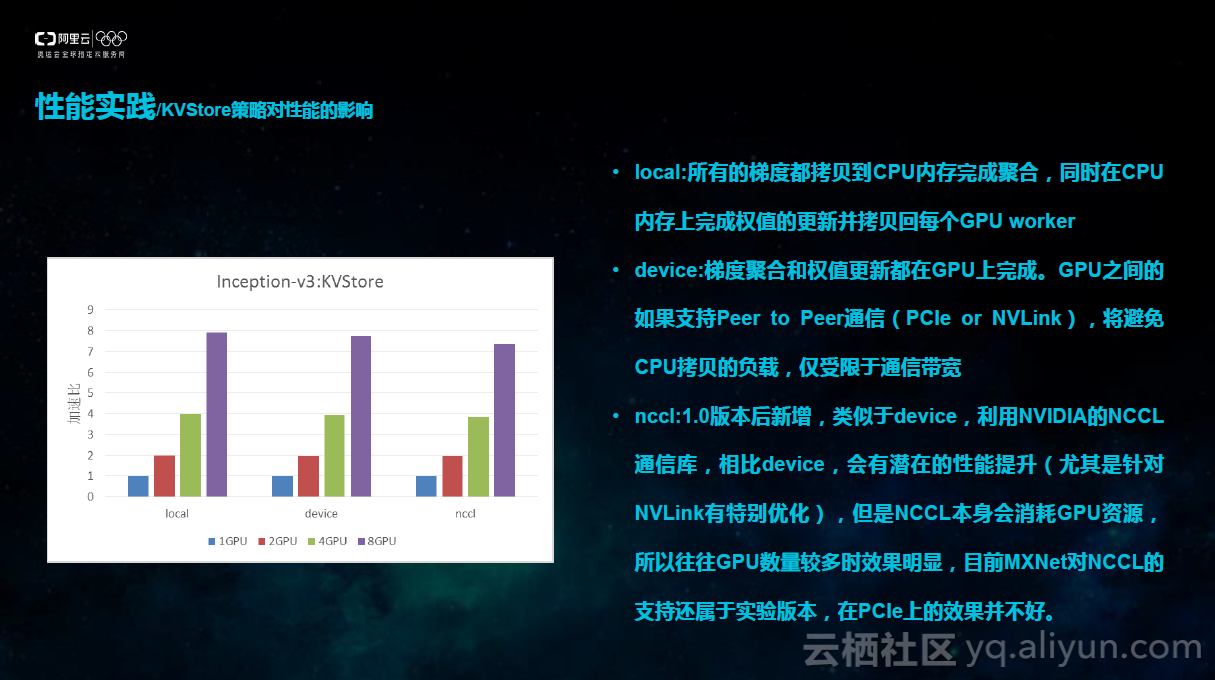
2.KVStore策略对性能的影响
在第一部分有提到KVStore是MXNet数据通讯的模块。KVStore策略对最终性能有巨大影响。深度学习过程有两部分组成,前向和后向。前向指的是通过正向运算取得结果,然后利用损失函数,计算结果与基准结果的偏差,再对偏差进行反向求导,计算偏差减小的最大梯度方向,在最大梯度方向减少偏差从而更新新的权值,再利用新的权值运算新的结果。不断反复迭代运算,最终结果会无限逼近最终想要达到的基准结果。那么在迭代运算的过程当中,会涉及到两个主要数据流向。并行计算当中,会有很多的设备。以GPU为例,就是有很多GPU worker,每个workers计算完自己的梯度之后要汇集到一起合成完整梯度,所以会有梯度聚合的梯度流向。第二个数据流向,计算完梯度后,在梯度反向对网络权值进行更新,之后更新后的权值会更新到每个GPU worker上。
KVStore的不同参数主要是两个不同数据流向的选择,目前的KVStore可以支持local和device两种参数,在1.0版本之后,新增了nccl参数。
1)local:所有的梯度都拷贝到CPU内存完成聚合,同时在CPU内存上完成权值的更新并拷贝回每个GPUworker。这种方式主要在于CPU与GPU,主要的性能负载在于CPU拷贝的负载。
2)device:梯度聚合和权值更新都在GPU上完成。GPU之间的如果支持Peer to Peer通信(PCIe or NVLink),将避免CPU拷贝的负载,可以大大减轻CPU的负担,仅受限于通信带宽。PCIe 与NVLink通信带宽不同,NVLink具备告诉的Peer to Peer通信带宽
3)ccl:1.0版本后新增,类似于device,利用NVIDIA的NCCL通信库,相比device,会有潜在的性能提升(尤其是针对NVLink有特别优化),但是NCCL本身会消耗GPU资源,所以往往GPU数量较多时效果明显,目前MXNet对NCCL的支持还属于实验版本,在PCIe上的效果并不好。从下图数据来看,对于Inception-V3网络来说,使用local参数性能最优,使用device较差,nccl最差。当然因为nccl对于NVLink有特别优化,后续阿里云上会推出最新NVLink版本的V100的实例。可以期待在新的设备之上,会有更优的表现。
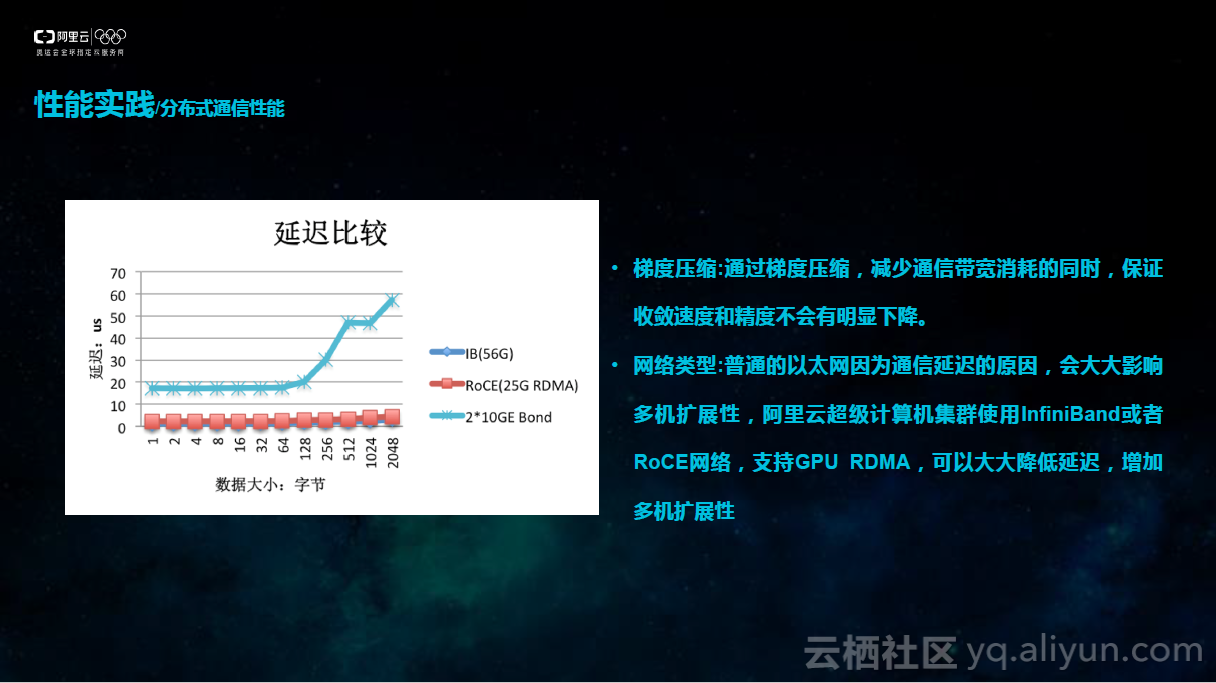
3.分布式通信性能
前面提到的都是单机通信,主要取决于通信基础设施,比如PCle和NVLink带宽。在多机通信中性能主要瓶颈在于网络通信。普通的我们使用的以太网因为通信延迟的原因,会大大影响多机扩展性。从下图中可以看到,InfiniBand(IB)网络和RoCE网络因为支持RDMA,大大降低了通信延迟,相比之下,20G的以太网格延迟会大大提升。为了改善延迟,阿里云超级计算机集群使用InfiniBand或者RoCE网络,支持GPURDMA,可以大大降低延迟,增加多机扩展性。
当然,对于现有的普通以太网络,也可以通过别的方法优化通信带宽的减少,比方说梯度压缩。通过梯度压缩,减少通信带宽消耗的同时,保证收敛速度和精度不会有明显下降。MXNet官方提供了梯度压缩算法,按照官方数据,最佳的时候可以达到两倍的训练速度提升,同时收敛速度和精度的下降不会超过百分之一。
本文由云栖志愿小组董黎明整理,编辑百见