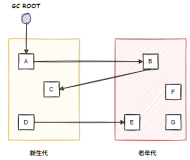
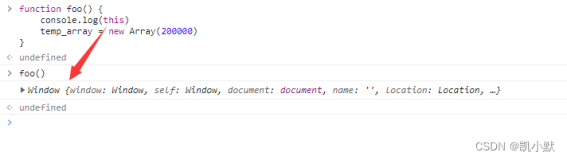
使用java开源项目经常需要调优jvm,以优化gc。对于gc,如果对象都是短时对象,那么jvm相对容易优化,假如碰上像solr使用自带java cache的项目,那么gc严重受限于cache,因为cache对象并非短时对象,以至于young gc常常伴有大量的内存对象拷贝,严重影响gc性能。
Ehcache BigMemory
Java的内存管理机制极其不适用于cache,最好的办法是使用jni实现的cache系统。另一种通用办法:Ehcache BigMemory(http://ehcache.org/)。BigMemory extends Ehcache's' capabilities with an off-heap store that frees you from GC’s constraints.
对于BigMemory,直接下载免费的32G限制的版本(注: 每个jvm进程最多使用32G的off-heap空间,对大多数应用已足够)。
关于如何使用,参见官方文档: http://terracotta.org/documentation/4.0/bigmemorygo/get-started
使用示例可参考代码中自带的样例:bigmemory-go-4.0.0/code-samples/src/main/java/com/bigmemory/samples
样例代码缺少编译配置build.xml, 将下面的 build.xml 放在 bigmemory-go-4.0.0/code-samples 即可使用ant 编译示例代码:

<project name="bigmemory" basedir="."> <property name="build.dir" value="${basedir}/build" /> <property name="src.class.dir" value="${build.dir}" /> <property name="src.dir" value="${basedir}/src" /> <property name="lib.dir" value="${basedir}/../lib" /> <property name="config.dir" value="${basedir}/config" /> <path id="base.classpath"> <pathelement location="${src.class.dir}" /> <pathelement location="${config.dir}" /> <fileset dir="${lib.dir}"> <include name="**/*.jar" /> </fileset> </path> <path id="classpath"> <path refid="base.classpath" /> <fileset dir="${lib.dir}"> <include name="**/*.jar" /> </fileset> </path> <path id="build.src.path"> <pathelement location="${src.class.dir}" /> </path> <target name="clean" description="clean"> <delete dir="${build.dir}" /> </target> <target name="compile" depends="clean" description="compile"> <mkdir dir="${src.class.dir}" /> <javac srcdir="${src.dir}" destdir="${src.class.dir}" source="1.6" debug="on" encoding="utf-8" includeantruntime="false"> <classpath refid="base.classpath" /> </javac> </target> <target name="jar" depends="compile" description="jar"> <jar destfile="${build.dir}/bigmemory.jar"> <fileset dir="${src.class.dir}"> <exclude name="**/timer/**" /> </fileset> </jar> </target> </project>
配置说明:bigmemory-go-4.0.0/config-samples/ehcache.xml 详细说明了配置参数。
限制:
1、存储对象全部使用 java.io.Serializable 做序列化和反序列化,性能有损失。
2、off-heap空间一经分配不可调整。
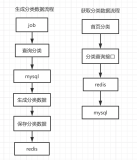
solr缓存
引入Ehcache bigmemory是为了优化solr的缓存。下面代码是基于solr cache基类实现的ehcache缓存类,使用上同于solr.FastLRUCache,需要ehcache的外部配置文件。
package org.apache.solr.search; import org.apache.solr.common.SolrException; import org.apache.solr.common.util.NamedList; import org.apache.solr.common.util.SimpleOrderedMap; import org.apache.solr.core.SolrCore; import java.util.*; import java.util.concurrent.atomic.AtomicLong; import java.io.IOException; import java.net.URL; import net.sf.ehcache.Cache; import net.sf.ehcache.CacheManager; import net.sf.ehcache.Element; import net.sf.ehcache.config.CacheConfiguration; import net.sf.ehcache.config.Configuration; import net.sf.ehcache.config.MemoryUnit; /** * @version $Id: EhCacheWrapper.java 2013-03-27 zhenjing chen $ */ public class EhCacheWrapper implements SolrCache { /* An instance of this class will be shared across multiple instances * of an LRUCache at the same time. Make sure everything is thread safe. */ private static class CumulativeStats { AtomicLong lookups = new AtomicLong(); AtomicLong hits = new AtomicLong(); AtomicLong inserts = new AtomicLong(); AtomicLong evictions = new AtomicLong(); } private CumulativeStats stats; // per instance stats. The synchronization used for the map will also be // used for updating these statistics (and hence they are not AtomicLongs private long lookups; private long hits; private long inserts; private long evictions; private long warmupTime = 0; private CacheManager manager = null; private Cache map; private String name; private String cache_name; private int autowarmCount; private State state; private CacheRegenerator regenerator; private String description="Eh LRU Cache"; private static int cache_index = 0; private static Map<String, CacheManager> managerPool = null; private static Map<String, Integer> managerFlag = null; private static CacheManager managerTemplate = null; static{ managerPool = new HashMap<String, CacheManager>(); managerFlag = new HashMap<String, Integer>(); managerTemplate = new CacheManager("/data/conf/ehcache.xml"); } private Cache GetCache() { // use cache pool Set<String> set = managerFlag.keySet(); Iterator<String> it = set.iterator(); while(it.hasNext()) { String cacheName = it.next(); if( managerFlag.get(cacheName) == 0 ) { // not used manager = managerPool.get(cacheName); System.out.println("EhCacheWrapper Cache Name(Pool): " + cacheName); managerFlag.put(cacheName, 1); cache_name = cacheName; return manager.getCache(cacheName); } } // add zhenjing String cacheName = name + cache_index; System.out.println("EhCacheWrapper Cache Name: " + cacheName); // create Cache from template Cache orig = managerTemplate.getCache(name); CacheConfiguration configTmp = orig.getCacheConfiguration(); configTmp.setName(cacheName); Configuration managerConfiguration = new Configuration(); managerConfiguration.setName(cacheName); manager = new CacheManager(managerConfiguration.cache(configTmp)); // put to cache pool managerFlag.put(cacheName, 1); managerPool.put(cacheName, manager); // get cache cache_index++; cache_name = cacheName; return manager.getCache(cacheName); } public Object init(Map args, Object persistence, CacheRegenerator regenerator) { state=State.CREATED; this.regenerator = regenerator; name = (String)args.get("name"); String str = (String)args.get("size"); final int limit = str==null ? 1024 : Integer.parseInt(str); str = (String)args.get("initialSize"); final int initialSize = Math.min(str==null ? 1024 : Integer.parseInt(str), limit); str = (String)args.get("autowarmCount"); autowarmCount = str==null ? 0 : Integer.parseInt(str); // get cache map = GetCache(); CacheConfiguration config = map.getCacheConfiguration(); description = "Eh LRU Cache(MaxBytesLocalOffHeap=" + config.getMaxBytesLocalOffHeap() + ", MaxBytesLocalHeap=" + config.getMaxBytesLocalHeap() + ", MaxEntriesLocalHeap=" + config.getMaxEntriesLocalHeap() + ")"; if (persistence==null) { // must be the first time a cache of this type is being created persistence = new CumulativeStats(); } stats = (CumulativeStats)persistence; return persistence; } public String name() { return name; } public int size() { synchronized(map) { return map.getSize(); } } public Object put(Object key, Object value) { synchronized (map) { if (state == State.LIVE) { stats.inserts.incrementAndGet(); } // increment local inserts regardless of state??? // it does make it more consistent with the current size... inserts++; map.put(new Element(key,value)); return null; // fake the previous value associated with key. } } public Object get(Object key) { synchronized (map) { Element val = map.get(key); if (state == State.LIVE) { // only increment lookups and hits if we are live. lookups++; stats.lookups.incrementAndGet(); if (val!=null) { hits++; stats.hits.incrementAndGet(); //System.out.println(name + " EH Cache HIT. key=" + key.toString()); } } if( val == null) return null; return val.getObjectValue(); } } public void clear() { synchronized(map) { map.removeAll(); } } public void setState(State state) { this.state = state; } public State getState() { return state; } public void warm(SolrIndexSearcher searcher, SolrCache old) throws IOException { return; } public void close() { clear(); // flag un-used managerFlag.put(cache_name, 0); System.out.println("EhCacheWrapper Cache Name(Reuse): " + cache_name); } //////////////////////// SolrInfoMBeans methods ////////////////////// public String getName() { return EhCacheWrapper.class.getName(); } public String getVersion() { return SolrCore.version; } public String getDescription() { return description; } public Category getCategory() { return Category.CACHE; } public String getSourceId() { return " NULL "; } public String getSource() { return " NULL "; } public URL[] getDocs() { return null; } // returns a ratio, not a percent. private static String calcHitRatio(long lookups, long hits) { if (lookups==0) return "0.00"; if (lookups==hits) return "1.00"; int hundredths = (int)(hits*100/lookups); // rounded down if (hundredths < 10) return "0.0" + hundredths; return "0." + hundredths; /*** code to produce a percent, if we want it... int ones = (int)(hits*100 / lookups); int tenths = (int)(hits*1000 / lookups) - ones*10; return Integer.toString(ones) + '.' + tenths; ***/ } public NamedList getStatistics() { NamedList lst = new SimpleOrderedMap(); synchronized (map) { lst.add("lookups", lookups); lst.add("hits", hits); lst.add("hitratio", calcHitRatio(lookups,hits)); lst.add("inserts", inserts); lst.add("evictions", evictions); lst.add("size", map.getSize()); } lst.add("warmupTime", warmupTime); long clookups = stats.lookups.get(); long chits = stats.hits.get(); lst.add("cumulative_lookups", clookups); lst.add("cumulative_hits", chits); lst.add("cumulative_hitratio", calcHitRatio(clookups,chits)); lst.add("cumulative_inserts", stats.inserts.get()); lst.add("cumulative_evictions", stats.evictions.get()); return lst; } public String toString() { return name + getStatistics().toString(); } }
外部ehcache.xml配置:
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd" updateCheck="false" monitoring="autodetect" dynamicConfig="true" name="config"> <!-- <cache name="filterCache" maxEntriesLocalHeap="1024" eternal="true" overflowToOffHeap="true" maxBytesLocalOffHeap="1g"> </cache> <cache name="fieldValueCache" maxEntriesLocalHeap="1024" eternal="true" overflowToOffHeap="true" maxBytesLocalOffHeap="1g"> </cache> --> <cache name="queryResultCache" maxEntriesLocalHeap="1" eternal="true" overflowToOffHeap="true" maxBytesLocalOffHeap="800m"> </cache> <!-- ehcache not support documentCache, encoding format error. <cache name="documentCache" maxEntriesLocalHeap="1024" eternal="true" overflowToOffHeap="true" maxBytesLocalOffHeap="1g"> </cache> --> </ehcache>