在本年度的NIPS上,MIT 计算机科学和人工智能实验室的研究员们提交了结合对抗学习和无监督学习两种方法的研究。

MIT计算机科学和人工智能实验室(CSAIL)的研究员开发了一个深度学习算法,能够自动生成视频,并预测出接下来的视频内容。
研究成果论文将在下周在巴塞罗那举行的NIPS(Conference on Neural Information Processing Systems)上发表。CSAIL的研究团队让该算法观看了200万条视频,这些视频加起来如果要回放的话,需要2年的时间才能播完。
视频包含了日常生活的常见场景,以让机器更好地适应正常的人类交流行为。更重要的是,这些视频是“野生”的,也就是说,它们都是非标签的。简单地说,就是研究员不会给算法提供理解视频内容的任何线索。
在这一视频数据集的基础上,算法将基于200万条视频中获得的观察,尝试从零开始生成视频,这和人类创作视频的步骤是一样的 。随后,生成的视频会被填入另一个深度学习算法中,新的算法负责判断哪些视频是机器生成的,哪些是“真实”的。这种训练机器的方法叫对抗式学习(adversarial learning)。
研究使用的神经网络工作原理
计算机视觉研究领域中,许多研究者都在攻克类似的问题,其中就包括MIT的教授Bill Freeman,他在“视觉动态”(visual dynamics)领域的工作也能提前创造出视频中下一帧。但是,他的模型聚焦于推断性的视频,Torralba的视频能够生成全新的视频,这些视频内容此前是从未讲过的。
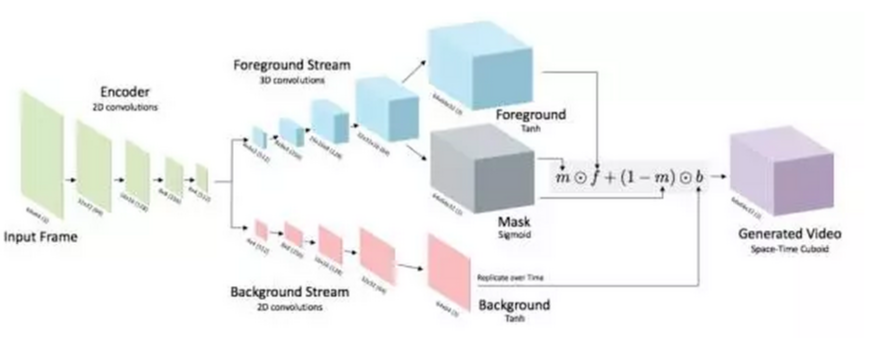
图来自 : Carl Vondrick, MIT CSAIL
此前的系统都是一帧一帧地创建场景,这会带来巨大的失误概率,这项研究聚焦于一次处理整个场景,算法每秒生成32帧图像。“一帧一帧地创建场景,意味着信息是被分成很多块的”,Vondrick说,“我们采用同时预测所有帧的方法。”
当然,一次生成所有的帧也有缺点:在变得更精确的同时,长视频中的计算机模型会变得更加复杂。
为了创建出多帧的效果,研究者教会模型在不受背景的影响下生成前景,然后,把对象放到场景中,让模型学习哪一个物体是移动的,哪一个不动。团队使用了“对抗学习”的方法,在多次尝试后,生成器学会如何“欺骗”区分器(discriminator)。
“双流架构”,生成视频更逼真
“在这一模型的早期原型中,我们的发现是,生成器(也就是神经网络)会改变背景或者在背景中加入异常的动态图片,来尝试欺骗其他的网络”,CSAIL博士候选人、论文第一作者Carl Vondrick说,“我们需要告诉模型一个概念,那就是现实世界在大多数情况下都是静态的。”
为了改正这一问题,Vondrick和他的同事创造了一个“双流架构”(two-stream architecture),这一架构会强迫生成的网络在前景中的对象移动时,对静态的背景进行渲染。
这种”双流架构“模型生成许多更加逼真的视频。算法生成的视频是64X64分辨率的,包含了32帧(标准的电影是每秒24帧,这意味着算法生成的视频有1秒~1.5秒),视频描绘的内容包括沙滩、火车站以及新生儿的脸(下图,这相当吓人)。

虽然听起来从零开始生成几秒的视频并没有多了不起,但是这比起此前的研究已经有了显著的进步,此前使用深度学习框架,只能生成一个视频中的几帧,并且在内容上,也会受到更为严格的参数限制。
让机器生成视频遇到的一个主要难点在于,视频中的物体是动态的,特别是人物,常常被渲染成模糊的一团,虽然研究者都在坚持:“我们的模型有潜力生成非常好的动态场景”。
确实,这种场景是非常值得赞叹的。研究者向亚马逊的Mechanical Turk的工作人员展示了一段由机器生成的视频和原来“真”的视频,向他们求证哪一段视频更为真实,结果,有20%的人选择了机器生成的视频。
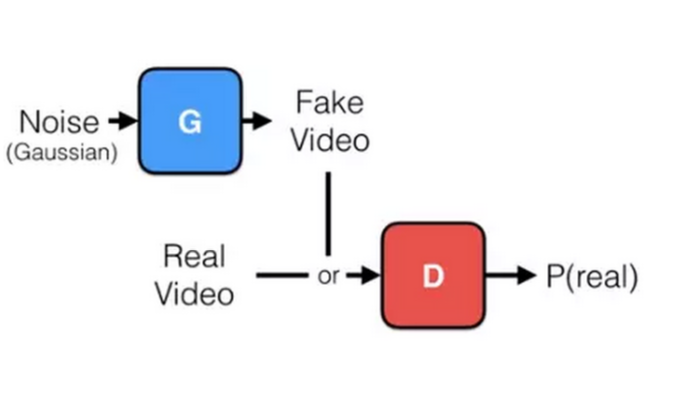
团队采用了两个神经网络,互相对抗,其中一个尝试欺骗另一个,让它认为自己生成的视频是“真”的。图:MIT CSAIL
除了生成原始视频,这一研究另一个亮眼的成果是能在已有的视频和照片上进行应用。当研究者把深度学习算法应用到一个静态的帧中,算法就能够识别出照片中的物体,把它们制作成32帧的动图,生成”非常合乎常理“的动作。Vondrick说,根据自己的了解,这是首次实现让机器从静态图片中生成多帧的视频。
这种预测对象或人的运动的能力对于未来机器融入现实世界是至关重要的,因为这将允许机器不采取可能伤害人的动作,或者帮助人们不伤害自己。根据Vondrick的说法,这一研究成果对无人监督的机器学习也有促进作用,因为这种类型的机器视觉算法接收的是来自未标记视频的所有输入数据。
如果机器真的想要善于识别和分类对象,它们将需要能够在没有标签数据的情况下这样做。
但是对于Vondrick来说,他的研究中最令人兴奋的可能性之一却跟科学或现实世界没什么关系。他纯粹是想让机器创作一段视频。
“从某种程度上来说,我对让机器自己创作一段视频或者电视节目非常痴迷”,Vondrick说,“我们只生成了一秒钟的视频,但随着我们的进步,也许可以生成几分钟的视频,讲一个连贯的故事。我们现在还做不到,但我认为我们迈出了第一步。”





