第 1 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
LogMiner 配置使用手册
1 Logminer 简介
1.1 LogMiner介绍
Oracle LogMiner 是 Oracle 公司从产品 8i 以后提供的一个实际非常有用的分析工具,使
用该工具可以轻松获得 Oracle 在线/归档日志文件中的具体内容,特别是该工具可以分析出所
有对于数据库操作的 DML 和 DDL 语句。该工具特别适用于调试、审计或者回退某个特定的事
务。
LogMiner分析工具实际上是由一组PL/SQL包和一些动态视图(Oracle8i内置包的一部分)
组成,它作为 Oracle 数据库的一部分来发布是 8i 产品提供的一个完全免费的工具。但该工具和
其他Oracle 内建工具相比使用起来显得有些复杂,主要原因是该工具没有提供任何的图形用户
界面(GUI)。
1.2 LogMiner作用
在 Oracle 8i 之前,Oracle 没有提供任何协助数据库管理员来读取和解释重作日志文件内容
的工具。系统出现问题,对于一个普通的数据管理员来讲,唯一可以作的工作就是将所有的log
文件打包,然后发给 Oracle 公司的技术支持,然后静静地等待 Oracle 公司技术支持给我们最
后的答案。然而从8i以后,Oracle 提供了这样一个强有力的工具--LogMiner。
LogMiner 工具即可以用来分析在线,也可以用来分析离线日志文件,即可以分析本身自己
数据库的重作日志文件,也可以用来分析其他数据库的重作日志文件。
总的说来,LogMiner工具的主要用途有:
1. 跟踪数据库的变化:可以离线的跟踪数据库的变化,而不会影响在线系统的性能。
2. 回退数据库的变化:回退特定的变化数据,减少 point-in-time recovery 的执行。
3. 优化和扩容计划:可通过分析日志文件中的数据以分析数据增长模式
1.3 使用详解
1.3.1 安装LogMiner
在使用 LogMiner 之前需要确认 Oracle 是否带有进行 LogMiner 分析包,一般来说第 2 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
Windows操作系统 Oracle10g 以上都默认包含。如果不能确认,可以 DBA身份登录系统,查
看系统中是否存在运行LogMiner所需要的dbms_logmnr、dbms_logmnr_d包,如果没有需
要安装 LogMiner工具,必须首先要运行下面这样两个脚本:
1、$ORACLE_HOME/rdbms/admin/dbmslm.sql
2、$ORACLE_HOME/rdbms/admin/dbmslmd.sql.
这两个脚本必须均以DBA用户身份运行。其中第一个脚本用来创建DBMS_LOGMNR 包,
该包用来分析日志文件。第二个脚本用来创建DBMS_LOGMNR_D包,该包用来创建数据字典
文件。
创建完毕后将包括如下过程和视图:
类型 过程名 用途
过程 Dbms_logmnr_d.build 创建一个数据字典文件
过程 Dbms_logmnr.add_logfile 在类表中增加日志文件以供分析
过程 Dbms_logmnr.start_logmnr 使用一个可选的字典文件和前面确定要分析日志
文件来启动LogMiner
过程 Dbms_logmnr.end_logmnr 停止LogMiner分析
视图 V$logmnr_dictionary 显示用来决定对象ID 名称的字典文件的信息
视图 V$logmnr_logs 在LogMiner启动时显示分析的日志列表
视图 V$logmnr_contents LogMiner启动后,可以使用该视图在 SQL 提示
符下输入SQL语句来查询重做日志的内容
1.3.2 创建数据字典文件
LogMiner 工具实际上是由两个新的 PL/SQL 内建包((DBMS_LOGMNR 和 DBMS_
LOGMNR_D)和四个 V$动态性能视图(视图是在利用过程 DBMS_LOGMNR.START_LOGMNR
启动 LogMiner 时创建)组成。在使用 LogMiner 工具分析 redo log 文件之前,可以使用
DBMS_LOGMNR_D 包将数据字典导出为一个文本文件。该字典文件是可选的,但是如果没有
它,LogMiner 解释出来的语句中关于数据字典中的部分(如表名、列名等)和数值都将是 16
进制的形式,我们是无法直接理解的。例如,下面的sql 语句:
INSERT INTO dm_dj_swry (rydm, rymc) VALUES (00005, '张三');
LogMiner解释出来的结果将是下面这个样子,
insert into Object#308(col#1, col#2) values (hextoraw('c30rte567e436'),
hextoraw('4a6f686e20446f65'));
创建数据字典的目的就是让 LogMiner 引用涉及到内部数据字典中的部分时为他们实际的
名字,而不是系统内部的 16 进制。数据字典文件是一个文本文件,使用包 DBMS_LOGMNR_D第 3 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
来创建。如果我们要分析的数据库中的表有变化,影响到库的数据字典也发生变化,这时就需要
重新创建该字典文件。另外一种情况是在分析另外一个数据库文件的重作日志时,也必须要重新
生成一遍被分析数据库的数据字典文件。
创建数据字典文件之前需要配置LogMiner文件夹:
CREATE DIRECTORY utlfile AS 'D:\oracle\oradata\practice\LOGMNR';
alter system set utl_file_dir='D:\oracle\oradata\practice\LOGMNR' scope=spfile;
创建字典文件需要以DBA用户登录,创建到上面配置好的LogMiner文件夹中:
CONN LOGMINER/ LOGMINER@PRACTICE AS SYSDBA
EXECUTE dbms_logmnr_d.build(dictionary_filename => 'dictionary.ora', dictionary_
location =>'D:\oracle\oradata\practice\LOGMNR');
1.3.3 加入需分析的日志文件
Oracle 的 LogMiner 可以分析在线(online)和归档(offline)两种日志文件,加入分析
日志文件使用 dbms_logmnr.add_logfile 过程,第一个文件使用 dbms_logmnr.NEW 参数,
后面文件使用 dbms_logmnr.ADDFILE 参数。
1、创建列表
BEGIN
dbms_logmnr.add_logfile(logfilename=>'D:\oracle\oradata\practice\REDO03.LO
G',options=>dbms_logmnr.NEW);
END;
/
2、添加其他日志文件到列表
BEGIN
dbms_logmnr.add_logfile(logfilename=>'D:\oracle\oradata\practice\ARCHIVE\A
RC00002_0817639922.001',options=>dbms_logmnr.ADDFILE);
dbms_logmnr.add_logfile(logfilename=>'D:\oracle\oradata\practice\ARCHIVE\A
RC00003_0817639922.001',options=>dbms_logmnr.ADDFILE);
END;
/
1.3.4 使用LogMiner 进行日志分析
Oracle 的 LogMiner 分析时分为无限制条件和限制条件两种,无限制条件中分析所有加入
到分析列表日志文件,限制条件根据限制条件分析指定范围日志文件。
第 4 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
1、无限制条件
EXECUTE
dbms_logmnr.start_logmnr(dictfilename=>'D:\oracle\oradata\practice\LOGMNR\
dictionary.ora');
2、有限制条件
通过对过程DBMS_ LOGMNR.START_LOGMNR中几个不同参数的设置(参数含义见表1),
可以缩小要分析日志文件的范围。通过设置起始时间和终止时间参数我们可以限制只分析某一时
间范围的日志。
参数 参数类型 默认值 含义
StartScn 数字型 0 分析重作日志中SCN≥StartScn 日志文件部分
EndScn 数字型 0 分析重作日志中SCN≤EndScn 日志文件部分
StartTime 日期型 1998-01-01 分析重作日志中时间戳≥StartTime 的日志文件
部分
EndTime 日期型 2988-01-01 分析重作日志中时间戳≤EndTime 的日志文件部
分
DictFileName 字符型 字典文件该文件包含一个数据库目录的快照。
如下面的例子,我们仅仅分析 2013 年6 月8日的日志,:
EXECUTE dbms_logmnr.start_logmnr(
DictFileName => dictfilename=>'D:\..\practice\LOGMNR\dictionary.ora',
StartTime =>to_date('2013-6-8 00:00:00','YYYY-MM-DD HH24:MI:SS')
EndTime =>to_date(''2013-6-8 23:59:59','YYYY-MM-DD HH24:MI:SS '));
也可以通过设置起始SCN和截至 SCN来限制要分析日志的范围:
EXECUTE dbms_logmnr.start_logmnr(
DictFileName =>'D:\..\practice\LOGMNR\dictionary.ora',
StartScn =>20,
EndScn =>50);
1.3.5 观察分析结果(v$logmnr_contents)
到现在为止,我们已经分析得到了重作日志文件中的内容。动态性能视图
v$logmnr_contents包含 LogMiner分析得到的所有的信息。
SELECT sql_redo FROM v$logmnr_contents;
如果我们仅仅想知道某个用户对于某张表的操作,可以通过下面的 SQL 查询得到,该查询
可以得到用户 LOGMINER对表EMP所作的一切工作。
SELECT sql_redo FROM v$logmnr_contents WHERE username='LOGMINER' AND 第 5 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
tablename='EMP';
序号 名称 含义
1 SCN 特定数据变化的系统更改号
2 TIMESTAM 数据改变发生的时间
3 COMMIT_TIMESTAMP 数据改变提交的时间
4 SEG_OWNER 数据发生改变的段名称
5 SEG_NAME 段的所有者名称
6 SEG_TYPE 数据发生改变的段类型
7 SEG_TYPE_NAME 数据发生改变的段类型名称
8 TABLE_SPACE 变化段的表空间
9 ROW_ID 特定数据变化行的ID
10 SESSION_INFO 数据发生变化时用户进程信息
11 OPERATION 重做记录中记录的操作(如 INSERT)
12 SQL_REDO 可以为重做记录重做指定行变化的 SQL 语句(正
向操作)
13 SQL_UNDO 可以为重做记录回退或恢复指定行变化的 SQL
语句(反向操作)
需要强调一点的是,视图 v$logmnr_contents 中的分析结果仅在我们运行过程
'dbms_logmrn.start_logmnr'这个会话的生命期中存在。这是因为所有的 LogMiner 存储都在
PGA内存中,所有其他的进程是看不到它的,同时随着进程的结束,分析结果也随之消失。
最后,使用过程DBMS_LOGMNR.END_LOGMNR终止日志分析事务,此时 PGA内存区域
被清除,分析结果也随之不再存在。
2 数据同步 Oracle 数据库设置
Oracle 数据使用 LogMiner查看执行 SQL语句,其中需要进行如下四步骤是指:
1. 设置数据库为归档模式;
2. 设置 LogMiner字典文件路径等;
3. 创建数据同步用户(如用户名为 LOGMINER,该用户拥有DBA权限);
4. 验证配置是否成功; 第 6 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
2.1 设置数据库为归档模式
2.1.1 查看数据库是否为归档模式
使用 SqlPlus或者命令行界面连接数据库(以下以命令行界面操作)
--进入SqlPlus程序
sqlplus /nolog
--使用DBA用户登录到源数据库中
conn system/system@practic as sysdba
--查看PRACTICE数据库是否处于归档模式
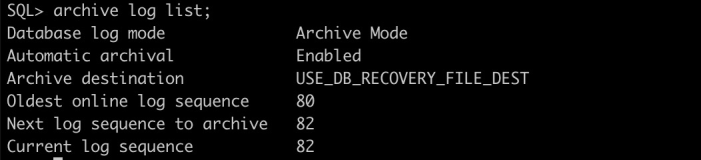
SELECT dbid, name, log_mode FROM v$database;
或者 ARCHIVE LOG LIST;
如果显示数据库显示为归档模式,则设置数据库为归档模式可跳过;如果显示数据库为非归档模
式则需要进行以下设置。
上图显示数据库未进行归档,需要进行归档设置。 第 7 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
2.1.2 设置归档模式
创建 ARCHIVE 文件夹,ARCHIVE 文件夹路径根据所在服务器进行设置,在下面操作中设置为"
D:\oracle\oradata\practice\ARCHIVE"
--设置归档日志文件路径
ALTER SYSTEM SET log_archive_dest="D:\oracle\oradata\practice\ARCHIVE";
--日志文件名称格式:
ALTER SYSTEM SET log_archive_format="ARC%S_%R.%T" SCOPE=SPFILE;
--修改完毕后,关闭数据库,以 MOUNT方式启动
SHUTDOWN IMMEDIATE;
STARTUP MOUNT;
--设置数据库为归档模式
ALTER DATABASE ARCHIVELOG; 第 8 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
(注意:如果重启数据失败,请参考第4 章节异常问题处理)
2.1.3 验证归档是否设置成功
--查看PRACTICE数据库是否处于归档模式
SELECT dbid, name, log_mode FROM v$database;
或者 ARCHIVE LOG LIST;
--验证参数设置是否起作用
SELECT dest_id, status, destination FROM v$archive_dest WHERE dest_id =1;
--在参数文件设置已经起作用,打开数据库 第 9 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
ALTER DATABASE OPEN;
2.2 LogMiner设置
2.2.1 创建LogMiner 文件夹
创建 LOGMNR文件夹,路径为"D:\oracle\oradata\practice\LOGMNR"
2.2.2 设置LogMiner 字典文件路径
--创建数据字典文件
CREATE DIRECTORY utlfile AS 'D:\oracle\oradata\practice\LOGMNR';
alter system set utl_file_dir='D:\oracle\oradata\practice\LOGMNR' scope=spfile; 第 10 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
2.2.3 开启LogMiner 日志补充模式
--创建数据字典文件
alter database add supplemental log data;
2.2.4 重启数据库验证
--修改完毕后,关闭数据库,以 MOUNT方式启动
SHUTDOWN IMMEDIATE;
STARTUP;
--查看Logminer文件夹是否设置
SHOW PARAMETER utl_file_dir; 第 11 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
2.3 创建数据同步用户
在数据库创建LOGMINER用户,该用户需要具有DBA权限
--在源数据库创建 LOGMINER用户,并赋予 DBA权限
CREATE USER LOGMINER IDENTIFIED BY LOGMINER;
GRANT CONNECT, RESOURCE,DBA TO LOGMINER;
3 使用 LogMiner 读取日志例子
在使用 LogMiner 读取归档/在线日志需要按照第 2 章节进行设置,设置完毕后可以对归档
和在线日志进行分析。特别是需要开启 LogMiner 日志补充模式,如果没有开始 LogMiner 补
充模式将无法查看 DDL语句,按照测试结果看,只有开始 LogMiner日志补充模式后,才能查
看 DDL语句,在此之前进行DDL将无法进行查看。 第 12 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
3.1 使用LogMiner 读取在线日志
3.1.1 测试数据准备
--以LOGMINER用户登录(非DBA登录)创建 AAAAA表(Oracle11g请注意用户名、密码大
小写)
CONNECT LOGMINER/LOGMINER@PRACTICE
CREATE TABLE AAAAA(field001 varchar2(100));
INSERT INTO AAAAA (field001) values ('000000');
INSERT INTO AAAAA (field001) values ('0000010');
commit;
3.1.2 创建数据字典文件
数据库对象发生变化,需要重新创建数据字典文件
--以LOGMINER用户(DBA权限)登录,生成字典文件
CONN LOGMINER/LOGMINER@PRACTICE AS SYSDBA
EXECUTE dbms_logmnr_d.build(dictionary_filename => 'dictionary.ora', dictionary_loca
tion =>'D:\oracle\oradata\practice\LOGMNR');
3.1.3 确认当前处于联机状态的日志文件
--需要确认当前处于联机状态的日志文件
SELECT group#, sequence#, status, first_change#, first_time FROM V$log ORDER BY first_change#; 第 13 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
从上图可以看出在线日志REDO03 处于ACTIVE状态中
3.1.4 加入需分析的日志文件
--加入解析在线日志文件
BEGIN
dbms_logmnr.add_logfile(logfilename=>'D:\oracle\oradata\practice\REDO03.LOG',opti
ons=>dbms_logmnr.NEW);
END;
/
3.1.5 使用LogMiner 进行分析
--启动LogMiner进行分析
EXECUTE
dbms_logmnr.start_logmnr(dictfilename=>'D:\oracle\oradata\practice\LOGMNR\dictio
nary.ora');
第 14 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
3.1.6 观察分析结果
--查询相关操作日志
SELECT sql_redo, sql_undo, seg_owner
FROM v$logmnr_contents
WHERE seg_name='AAAAA'
AND seg_owner='LOGMINER';
3.2 使用LogMiner 读取归档日志
3.2.1 测试数据准备
--以 LOGMINER 用户登录(非 DBA 权限)创建 EMP 表(Oracle11g 请注意用户名、密码大小
写)
CONN LOGMINER/ LOGMINER@PRACTICE
CREATE TABLE EMP
(EMPNO NUMBER(4) CONSTRAINT PK_EMP PRIMARY KEY, 第 15 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
ENAME VARCHAR2(10),
JOB VARCHAR2(9),
MGR NUMBER(4),
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER(2));
--插入EMP数据
INSERT INTO EMP VALUES
(7369,'SMITH','CLERK',7902,to_date('17-12-1980','dd-mm-yyyy'),800,NULL,20);
INSERT INTO EMP VALUES
(7499,'ALLEN','SALESMAN',7698,to_date('20-2-1981','dd-mm-yyyy'),1600,300,30);
INSERT INTO EMP VALUES
(7521,'WARD','SALESMAN',7698,to_date('22-2-1981','dd-mm-yyyy'),1250,500,30);
INSERT INTO EMP VALUES
(7566,'JONES','MANAGER',7839,to_date('2-4-1981','dd-mm-yyyy'),2975,NULL,20);
COMMIT;
--从v$log视图中找出日志文件的序号
CONNECT system/system@practice as sysdba
ALTER SYSTEM SWITCH LOGFILE;
select sequence#, FIRST_CHANGE#, NEXT_CHANGE#,name from v$archived_log order
by sequence# desc; 第 16 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
3.2.2 创建数据字典文件
确保按照 2.2 进行 logMiner设置
--以LOGMINER用户(DBA权限)登录,生成字典文件
CONN LOGMINER/ LOGMINER@PRACTICE AS SYSDBA
EXECUTE dbms_logmnr_d.build(dictionary_filename => 'dictionary.ora', dictionary_loca
tion =>'D:\oracle\oradata\practice\LOGMNR');
3.2.3 加入需分析的日志文件
--加入解析日志文件
BEGIN
dbms_logmnr.add_logfile(logfilename=>'D:\oracle\oradata\practice\ARCHIVE\ARC000
02_0817639922.001',options=>dbms_logmnr.NEW);
END;
/ 第 17 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
3.2.4 使用LogMiner 进行分析
--启动LogMiner进行分析
EXECUTE
dbms_logmnr.start_logmnr(dictfilename=>'D:\oracle\oradata\practice\LOGMNR\dictio
nary.ora');
3.2.5 观察分析结果
--查询相关操作日志
SELECT sql_redo, sql_undo
FROM v$logmnr_contents
WHERE seg_name='EMP'
AND seg_owner='LOGMINER'; 第 18 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
4 其他
4.1 异常问题处理
4.1.1 出现ORA-12514错误
如果出现 ORA-12514 错误时,如下图所示: 第 19 页 共 20 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
需要修改 listerner.ora 文件,具体在 Oracle 安装目录\NETWORK\ADMIN 下,当前操作为"
D:\oracle\product\10.2.0\db_1\NETWORK\ADMIN\listener.ora "加入如下设置
(SID_DESC =
(GLOBAL_DBNAME = practice)
(ORACLE_HOME = D:\oracle\product\10.2.0\db_1)
(SID_NAME = practice)
)
设置后需要重新启动TNSListener,即可生效
4.1.2 出现ORA-16018错误
如果出现 ORA-16018 错误时,如下图所示:
该问题是数据库开启了闪回功能,归档文件默认情况下是保存到闪回路径中,简单的处理方式是
在设置归档路径中加入scope=spfile 参数
--设置归档日志文件路径
ALTER SYSTEM SET log_archive_dest="D:\oracle\oradata\practice\ARCHIVE"
scope=spfile;
此时查看闪回路径,该路径并未影响,只不过闪回文件和归档文件保存到各自文件夹中
第 1 页 共 7 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
Oracle Logminer 性能测试
1 测试介绍
1.1 测试目的
通过模拟不同环境下 LogMiner 解析联机/归档日志文件运行情况,通过测试所获取
的数据分析,通过对以下两点的验证来确定通过 LogMiner技术技术可行性:
1、在日志文件不同大小、不同数据压力情况下对数据库服务器内存、CPU 的影响;
2、并通过查询 LogMiner 的动态表和实际物理表中数据数目是否一致,验证其准确
性。
1.2 测试环境
用途及说明 硬件配置 软件配置 其它说明
数据库服务器
型号:T420i
处理器:Intel(R)core(TM) i5
CPU M430
主频:2.2G
内存:2G
硬盘:300G
操作系统:WindowXP
数据库及版本:Oracle10.2g
IP地址:10.88.54.83
测试机
型号:T420i
处理器:Intel(R)core(TM) i5
CPU M430
主频:2.2GHz
内存:1.8 GB
显示器:1280*800 宽屏
操作系统:windows xp
浏览器及版本:ie8
1.3 测试方案
1.3.1 性能影响(针对目标一)
为了模拟实际运行环境,加入了 Logminer运行背景环境,分别测试数据库在无操作、
300 个插入/秒操作、500 个插入/秒操作情况下运行情况,并且对比日志文件50M、100M第 2 页 共 7 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
大小下运行情况
联机日志大小 读取文件个数 运行作业数目 插入数据量
方案一 50M
1 个 0 个 0 笔/秒
3 个 0 个 0 笔/秒
5 个 0 个 0 笔/秒
10 个 0 个 0 笔/秒
方案二 50M
1 个 500 个 估计300 笔/秒
3 个 500 个 估计300 笔/秒
5 个 500 个 估计300 笔/秒
10 个 500 个 估计 300 笔/秒
方案三 50M(未运行
CPU80%,680M)
1 个 1000 个 估计 500 笔/秒
3 个 1000 个 估计500 笔/秒
5 个 1000 个 估计500 笔/秒
10 个 1000 个 估计 500 笔/秒
方案四 100M(未运行
CPU25%,464M)
1 个 500 个 估计300 笔/秒
3 个 500 个 估计300 笔/秒
5 个 500 个 估计300 笔/秒
10 个 500 个 估计 300 笔/秒
1.3.2 准确性(针对目标二)
1、数据类型
序号 数据类型 是否支持 问题处理
1 BINARY_DOUBLE 8.1 及以上
2 BINARY_FLOAT 8.1 及以上
3 CHAR 8.1 及以上
4 DATE 8.1 及以上
需设置时间格式,否则只能同步日期
alter system set
nls_date_format='yyyy-MM-dd
HH24:mi:ss' scope=spfile;
5 INTERVAL DAY 8.1 及以上
6 INTERVAL YEAR 8.1 及以上
7 NUMBER 8.1 及以上
8 NVARCHAR2 8.1 及以上
9 RAW 8.1 及以上
10 TIMESTAMP 8.1 及以上
11 TIMESTAMP 8.1 及以上 第 3 页 共 7 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
WITH LOCAL
TIME ZONE
12 VARCHAR2 8.1 及以上
13 LONG 9.2 及以上
14 CLOB 10.1 及以上 需要设置如下:
ALTER DATABASE ADD SUPPLEMENTAL
LOG DATA (ALL) COLUMNS;
插入时分为两条语句,另外插入二进制数据
未进行测试
15 BLOB 10.0 及以上
2、DDL语句测试(未测试完毕)
序号 类型 是否支持
1 创建表(Create table) 支持
2 删除表(Drop table)
支持,出现两个语句,首先修改表
名为临时表名,然后删除该临时表
监控该类型需要进行合并处理
3 创建作业(Create job) 不支持
4 创建序列(Create sequence) 支持
5 创建存储过程(Create pocedure) 支持
6 增加字段(alter table TABLE add column) 支持
7 删除字段(alter table emp drop column) 支持
8 修改字段(alter table emp modify column) 支持
9 修改列名(alter table rename column) 支持
10 修改表名(rename emp to TABLE) 支持
11 清除表数据(truncate table TABLE) 支持
12 删除表(drop table TABLE) 支持
13 恢复被删除的表(Flashback table TABLE to before
drop) 支持
14 NOT NULL约束(alter table TABLE modify
COLUMN not null) 支持
15 UNIQUE 约束 支持
16 PRIMARY KEY 约束 支持
17 FOREIGN KEY 约束 支持
18 CKECK 约束 支持
19 禁用/激活约束 支持
20 删除约束 支持
21 创建不唯一索引 支持 第 4 页 共 7 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
22 创建唯一索引 支持
23 创建位图索引 支持
24 创建反序索引 支持
25 创建函数索引 支持
26 修改索引 支持
27 合并索引 支持
28 重建索引 支持
29 删除索引 支持
30 创建视图(CREATE VIEW) 支持
31 修改视图(CREATE OR REPLACE VIEW) 支持
32 删除视图(DROP VIEW) 支持
33 创建序列(CREATE SEQUENCE) 支持
34 修改序列(ALTER SEQUENCE) 支持
35 删除序列(DROP SEQUENCE) 支持
3、其他问题测试
序号 问题 现象及处理方式
1 主子表插入数据测试 能够正常插入及同步
2 事务提交(commit、rollback)
能够看到提交和未提交的内容,考虑在产品设计
中加入
DBMS_LOGMNR.COMMITTED_DATA_ON
LY
参数,该参数只读取已经提交事务
3 批量更新时,影响多条数据,在联机日志
中每一条更新数据对应生成一条语句 不影响,可同步获取再执行
4 更新和删除语句中带rowid
加入去除rowid 参数
dbms_logmnr.NO_ROWID_IN_STMT
5
2 测试结论
2.1 测试初步结论
1. 从性能影响测试中可以看出: 第 5 页 共 7 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
a) logminer加载分析过程随机器根据负载不同在 6~21 秒完成;
b) 加载分析过程并不随日志文件个数增加在时间、CPU、内存有较大变化;
c) 加载分析过程中受分析日志文件个数最大是内存,其次是 CPU,耗时应影响较小;
2. 从准确性测试来看
a) 通过设置基本上能够获取 DML语句(其中 LOB 字段还需要进行测试);
b) 从现有情况来看,DDL支持并不充分,需要进一步测试;
第 6 页 共 7 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
联机日志大小
读取
文件
个数
运行作
业数目 插入数据量
生成字典
文件 加载处理 分析处理 log_content
s
数据量
大
小
(M)
时
间
(秒)
耗时
(秒)
CPU(%
)
内存
(M)
耗时
(秒)
CPU(%
)
内存
(M)
方案
一 50M
1 个 0 个 0 笔/秒
47.
5
12.
7
1 1 309 5.5 25 438 600
3 个 0 个 0 笔/秒 1 1 309 5.7 25 444 222,236
5 个 0 个 0 笔/秒 1 1 326 5.6 25 445 492,606
10个 0 个 0 笔/秒 1 1 326 5.6 25 445 1,149,284
方案
二 50M
1 个 500 个 估计300 笔/秒
47.
5 20
1 26 391 6.7 35 530 111,328
3 个 500 个 估计300 笔/秒 1 21 473 6.4 37 619 372,389
5 个 500 个 估计300 笔/秒 1 25 534 6.8 44 692 622,390
10个 500 个 估计300 笔/秒 1 30 624 6.7 39 780 1,254,748
方案
三
50M(未运行
CPU80%,680M)
1 个 1000个 估计500 笔/秒
47.
5
54.
7
3.5 71 688 15 80 806 35,892
3 个 1000个 估计500 笔/秒 1.5 41 688 14.4 78 777 384,743
5 个 1000个 估计500 笔/秒 1 68 687 75 805 652,148
10个 1000个 估计500 笔/秒 10 80 689 13.2 79 806 1,295,158
方案
四
50M(未运行
CPU80%,667M)
1 个 2000个 估计1000笔/秒
47.
5
73.
7
5.5 84 691 14.6 78 808 133,844
3 个 2000个 估计1000笔/秒 11.4 70 691 12 75 809 390,029
5 个 2000个 估计1000笔/秒 5.5 76 690 13.6 76 806 668,013
10个 2000个 估计1000笔/秒 6.1 40 690 15.4 88 809 1,335,587
方案 100M(未运行 1 个 500 个 估计300 笔/秒 23. 8.7 0.8 26 484 4.1 30 573 268,715 第 7 页 共 7 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
五 CPU25%,464M) 3 个 500 个 估计300 笔/秒 8 0.9 25 534 3.2 36 622 768,989
5 个 500 个 估计300 笔/秒 0.9 27 581 3.2 35 662 1,324,447
10个 500 个 估计300 笔/秒 1.1 29 690 5.2 35 763 2,619,322
第 1 页 共 9 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
使用 Oracle Logminer 同步 Demo
1 Demo介绍
1.1 Demo设想
前面介绍了 Oracle LogMiner 配置使用以及使用 LogMiner 进行解析日志文件性能,在这
篇文章中将利用LogMiner进行数据同步,实现从源目标数据库到目标数据库之间的数据同步。
由于LogMiner支持的版本是8.1及以上,所以进行数据同步的Oracle数据库版本也必须是8.1
及以上。
当然在本文中介绍的是LogMiner进行数据同步例子,也可以利用LogMiner进行数据审计、
数据操作追踪等功能,由于这些从操作原理来说是一致,在本文不做讨论。
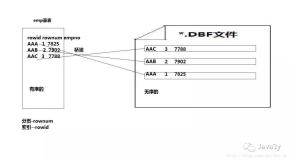
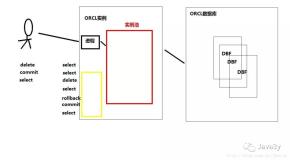
1.2 框架图
第 2 页 共 9 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
1.3 流程图
配置阶段
1、 控制端:指定源端、目标端数据库信息、LOGMINER同步时间等配置信息;
获取源端同步数据
2、 控制台:通过定时轮询的方式检测是否到达数据同步时间,如果是则进行数据同步,否
则继续进行轮询;
3、 源数据库:定时加载数据库归档日志文件到动态表v$logmnr_contents中;
4、 源数据库:根据条件读取指定sql 语句;
目标端数据入库
5、 源数据库:执行sql 语句。
2 代码分析
2.1 目录及环境配置
在该 Demo 项目中需要引入 Oracle JDBC 驱动包,具体项目分为四个类: 第 3 页 共 9 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
1. Start.java:程序入口方法;
2. SyncTask.java:数据同步 Demo 核心,生成字典文件和读取日志文件、目标数据库执
行SQL语句等;
3. DataBase.java:数据库操作基础类;
4. Constants.java:源数据库、目标数据库配置、字典文件和归档文件路径。
2.2 代码分析
2.2.1 Constants.java
在该类中设置了数据同步开始 SCN号、源数据库配置、目标数据库配置以及字典文件/日志
文件路径。需要注意的是在源数据库配置中有两个用户:一个是调用 LogMiner 用户,该用户
需要拥有 dbms_logmnr、dbms_logmnr_d两个过程权限,在该 Demo 中该用为为sync;另
外一个为 LogMiner读取该用户操作 SQL语句,在该Demo 中该用为为 LOGMINER。
package com.constants;
/**
* [Constants]|描述:Logminer配置参数
* @作者: ***
* @日期: 2013-1-15 下午01:53:57
* @修改历史:
*/
public class Constants {
/** 上次数据同步最后SCN号 */
public static String LAST_SCN = "0"; 第 4 页 共 9 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
/** 源数据库配置 */
public static String DATABASE_DRIVER="oracle.jdbc.driver.OracleDriver";
public static String
SOURCE_DATABASE_URL="jdbc:oracle:thin:@127.0.0.1:1521:practice";
public static String SOURCE_DATABASE_USERNAME="sync";
public static String SOURCE_DATABASE_PASSWORD="sync";
public static String SOURCE_CLIENT_USERNAME = "LOGMINER";
/** 目标数据库配置 */
public static String SOURCE_TARGET_URL="jdbc:oracle:thin:@127.0.0.1:1521:target";
public static String SOURCE_TARGET_USERNAME="target";
public static String SOURCE_TARGET_PASSWORD="target";
/** 日志文件路径 */
public static String LOG_PATH = "D:\\oracle\\oradata\\practice";
/** 数据字典路径 */
public static String DATA_DICTIONARY = "D:\\oracle\\oradata\\practice\\LOGMNR";
}
2.2.2 SyncTask.java
在该类中有两个方法,第一个方法为 createDictionary,作用为生成数据字典文件,另外一
个是startLogmur,该方法是 LogMiner分析同步方法。
/**
* <p>方法名称: createDictionary|描述: 调用logminer
/**
* <p>方法名称: startLogmur|描述:启动
生成数据字典文件</p>
* @param sourceConn 源数据库连接
* @throws Exception 异常信息
*/
public void createDictionary(Connection sourceConn) throws Exception{
String createDictSql = "BEGIN dbms_logmnr_d.build(dictionary_filename =>
'dictionary.ora', dictionary_location =>'"+Constants.DATA_DICTIONARY+"'); END;";
CallableStatement callableStatement = sourceConn.prepareCall(createDictSql);
callableStatement.execute();
}
logminer分析 </p>
* @throws Exception
*/
public void startLogmur() throws Exception{
第 5 页 共 9 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
Connection sourceConn = null;
Connection targetConn = null;
try {
ResultSet resultSet = null;
// 获取源数据库连接
sourceConn = DataBase.getSourceDataBase();
Statement statement = sourceConn.createStatement();
// 添加所有日志文件,本代码仅分析联机日志
StringBuffer sbSQL = new StringBuffer();
sbSQL.append(" BEGIN");
sbSQL.append("
dbms_logmnr.add_logfile(logfilename=>'"+Constants.LOG_PATH+"\\REDO01.LOG',
options=>dbms_logmnr.NEW);");
sbSQL.append("
dbms_logmnr.add_logfile(logfilename=>'"+Constants.LOG_PATH+"\\REDO02.LOG',
options=>dbms_logmnr.ADDFILE);");
sbSQL.append("
dbms_logmnr.add_logfile(logfilename=>'"+Constants.LOG_PATH+"\\REDO03.LOG',
options=>dbms_logmnr.ADDFILE);");
sbSQL.append(" END;");
CallableStatement callableStatement = sourceConn.prepareCall(sbSQL+"");
callableStatement.execute();
// 打印获分析日志文件信息
resultSet = statement.executeQuery("SELECT db_name, thread_sqn, filename FROM
v$logmnr_logs");
while(resultSet.next()){
System.out.println("已添加日志文件==>"+resultSet.getObject(3));
}
System.out.println("开始分析日志文件,起始scn号:"+Constants.LAST_SCN);
callableStatement = sourceConn.prepareCall("BEGIN
dbms_logmnr.start_logmnr(startScn=>'"+Constants.LAST_SCN+"',dictfilename=>'"+Consta
nts.DATA_DICTIONARY+"\\dictionary.ora',OPTIONS
=>DBMS_LOGMNR.COMMITTED_DATA_ONLY+dbms_logmnr.NO_ROWID_IN_STMT);END;");
callableStatement.execute();
System.out.println("完成分析日志文件");
// 查询获取分析结果
System.out.println("查询分析结果");
resultSet = statement.executeQuery("SELECT
scn,operation,timestamp,status,sql_redo FROM v$logmnr_contents WHERE
seg_owner='"+Constants.SOURCE_CLIENT_USERNAME+"' AND seg_type_name='TABLE' AND
operation !='SELECT_FOR_UPDATE'");
第 6 页 共 9 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
// 连接到目标数据库,在目标数据库执行redo语句
targetConn = DataBase.getTargetDataBase();
Statement targetStatement = targetConn.createStatement();
String lastScn = Constants.LAST_SCN;
String operation = null;
String sql = null;
boolean isCreateDictionary = false;
while(resultSet.next()){
lastScn = resultSet.getObject(1)+"";
if( lastScn.equals(Constants.LAST_SCN) ){
continue;
}
operation = resultSet.getObject(2)+"";
if( "DDL".equalsIgnoreCase(operation) ){
isCreateDictionary = true;
}
sql = resultSet.getObject(5)+"";
// 替换用户
sql = sql.replace("\""+Constants.SOURCE_CLIENT_USERNAME+"\".", "");
System.out.println("scn="+lastScn+",自动执行sql=="+sql+"");
try {
targetStatement.executeUpdate(sql.substring(0, sql.length()-1));
} catch (Exception e) {
System.out.println("测试一下,已经执行过了");
}
}
// 更新scn
Constants.LAST_SCN = (Integer.parseInt(lastScn))+"";
// DDL发生变化,更新数据字典
if( isCreateDictionary ){
System.out.println("DDL发生变化,更新数据字典");
createDictionary(sourceConn);
System.out.println("完成更新数据字典");
isCreateDictionary = false;
}
System.out.println("完成一个工作单元");
}
finally{ 第 7 页 共 9 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
if( null != sourceConn ){
sourceConn.close();
}
if( null != targetConn ){
targetConn.close();
}
sourceConn = null;
targetConn = null;
}
}
3 运行结果
3.1 源数据库操作
1、创建 AAAAA表,并插入数据
2、创建EMP1 表 第 8 页 共 9 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
3.2 运行 Demo
在控制台中输出如下日志
3.3 目标数据库结果
创建 AAAAA和EMP1 表,并在AAAAA插入了数据 第 9 页 共 9 页 出自石山园主,博客地址:http://www.cnblogs.com/shishanyuan
转:http://files.cnblogs.com/files/shishanyuan/3.%E4%BD%BF%E7%94%A8OracleLogminer%E5%90%8C%E6%AD%A5Demo.pdf