朋友在500w的表上建索引,半个小时都没有结束。所以就讨论如何提速。
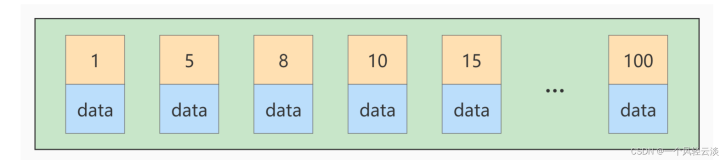
一.先来看一下创建索引要做哪些操作:
1. 把index key的data 读到内存
==>如果data 没在db_cache 中,这时候很容易有大量的db file scatter read wait
2. 对index key的data 作排序
==>sort_area_size 或者pga_aggregate_target 不够大的情况下,需要做 disk sort, 会有大量的driect path read/write , 另外,消耗大量CPU Time
3. 创建新的index segment ,把排过序的index data 写到所创建的index segment 里面
==>如果index 很大,那么,有时也会有redo log 相关等待,如:
log buffer space ,log file sync , log file parallel write 等
所以,在建大表索引时,可以增大pga,增大temp tablepace,并且用nologging或并行选项。
如:
create index idx_logs on logs(time) nologging parallel 4;
并行度一般看CPU 个数。当然在CPU 比较空闲的情况下可以多并行几个。对于单CPU不建议用并行,这样反而会增加创建时间。也可以根据v$session_wait 的资料,做针对性的tuning , 这样可以降低点时间。
补充知识:
查看cpu 信息:more /proc/cpuinfo
查看内存信息:more /proc/meminfo
查看操作系统信息:more /etc/issue
有关索引概念性的东西,请参考我的Blog:
Oracle 索引 详解
http://blog.csdn.net/tianlesoftware/archive/2010/03/05/5347098.aspx
二. 测试
自己也测试了下。测试环境:Oracle 11g R2, win7 64bit ,CPU T6670 2.2G 双核, 内存:4G。
1. 查看表的数据量:
SQL> select count(*) from custaddr;
COUNT(*)
----------
7230464
2. 查看现有索引:
SQL> select index_name,index_type from user_indexes where table_name='CUSTADDR';
INDEX_NAME INDEX_TYPE
------------------------------ ---------------------------
PK_CUSTADDR_TP_723 NORMAL
IX_CUSTADDR_ADDRABB_TP NORMAL
IX_CUSTADDR_TEAMID_TP NORMAL
IX_CUSTADDR_CUSTID_TP NORMAL
IX_CUSTADDR_COMPABB_TP NORMAL
IX_CUSTADDR_AREACODE NORMAL
IX_CUSTADDR_ADDR_TP NORMAL
已选择7行。
3. 删除索引:IX_CUSTADDR_CUSTID_TP
SQL> drop index IX_CUSTADDR_CUSTID_TP ;
索引已删除。
4. 默认方式创建索引:
SQL> SET timing on;
SQL> CREATE INDEX IX_CUSTADDR_CUSTID_TP ON CUSTADDR (CUSTID );
索引已创建。
已用时间: 00: 00: 48.37
单位:s
5. 用nologging 模式:
SQL> drop index IX_CUSTADDR_CUSTID_TP ;
索引已删除。
已用时间: 00: 00: 00.09
SQL> CREATE INDEX IX_CUSTADDR_CUSTID_TP ON CUSTADDR (CUSTID ) NOLOGGING;
索引已创建。
已用时间: 00: 00: 34.46
6. Nologging+ parallel 模式
SQL> drop index IX_CUSTADDR_CUSTID_TP ;
索引已删除。
已用时间: 00: 00: 00.17
SQL> CREATE INDEX IX_CUSTADDR_CUSTID_TP ON CUSTADDR (CUSTID ) NOLOGGING PARALLEL 2;
索引已创建。
已用时间: 00: 00: 52.56
SQL> drop index IX_CUSTADDR_CUSTID_TP ;
索引已删除。
已用时间: 00: 00: 00.07
SQL> CREATE INDEX IX_CUSTADDR_CUSTID_TP ON CUSTADDR (CUSTID ) NOLOGGING PARALLEL 4;
索引已创建。
已用时间: 00: 00: 53.44
看来在单CPU上,并行效果还不好.
7. Parallel 模式
SQL> drop index IX_CUSTADDR_CUSTID_TP ;
索引已删除。
已用时间: 00: 00: 00.02
SQL> CREATE INDEX IX_CUSTADDR_CUSTID_TP ON CUSTADDR (CUSTID ) PARALLEL 2;
索引已创建。
已用时间: 00: 00: 49.97
SQL> drop index IX_CUSTADDR_CUSTID_TP ;
索引已删除。
已用时间: 00: 00: 00.02
SQL> CREATE INDEX IX_CUSTADDR_CUSTID_TP ON CUSTADDR (CUSTID ) PARALLEL 4;
索引已创建。
已用时间: 00: 00: 50.25
从上面的测试数据可以看出,700万的数据,建索引,也在1分钟以内。 但是并行在单CPU上效果不明显,而且比光使用NOLOGGING还要慢,因为出现资源争用了,可能是CPU的争用,也可能是I/O的争用。
转: http://blog.csdn.net/tianlesoftware/article/details/5664019