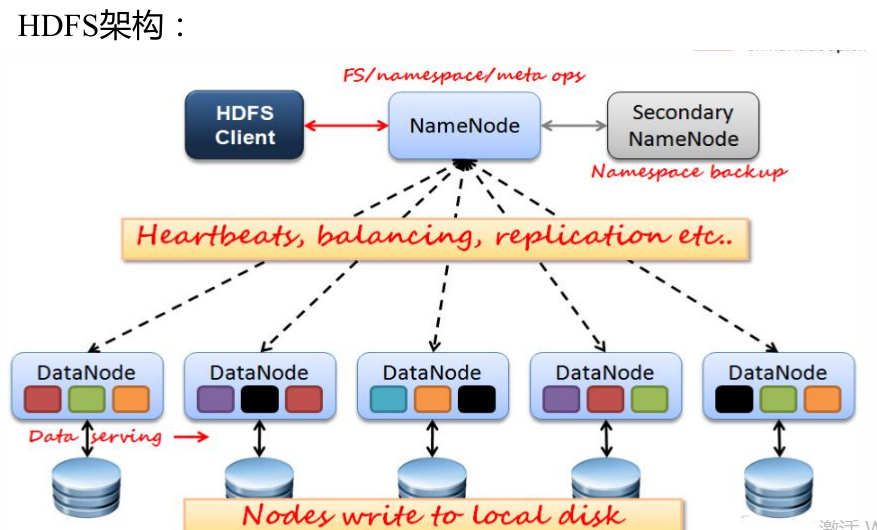
在对NameNode节点进行格式化时,调用了FSImage的saveFSImage()方法和FSEditLog.createEditLogFile()存储当前的元数据。Namenode主要维护两个文件,一个是fsimage,一个是editlog。
fsimage :保存了最新的元数据检查点,包含了整个HDFS文件系统的所有目录和文件的信息。对于文件来说包括了数据块描述信息、修改时间、访问时间等;对于目录来说包括修改时间、访问权限控制信息(目录所属用户,所在组)等。简单的说,Fsimage就是在某一时刻,整个hdfs 的快照,就是这个时刻hdfs上所有的文件块和目录,分别的状态,位于哪些个datanode,各自的权限,各自的副本个数等。
注意:Block的位置信息不会保存到fsimage,Block保存在哪个DataNode(由DataNode启动时上报)。
editlog :主要是在NameNode已经启动情况下对HDFS进行的各种更新操作进行记录,HDFS客户端执行所有的写操作都会被记录到editlog中。
读取元数据:
启动NameNode节点时,又要从镜像和编辑日志中读取元数据。
写入元数据:
在NameNode运行时会将内存中的元数据信息存储到所指定的文件,即${dfs.name.dir}/current目录下的fsimage文件,此外还会将另外一部分对NameNode更改的日志信息存储到${dfs.name.dir}/current目录下的edits文件中。fsimage文件和edits文件可以确定NameNode节点当前的状态,这样在NameNode节点由于突发原因崩溃时,可以根据这两个文件中的内容恢复到节点崩溃前的状态,所以对NameNode节点中内存元数据的每次修改都必须保存下来。但是如果每次都保存到fsimage文件中,这样效率就特别低效,所以引入编辑日志文件edits,保存对对元数据的修改信息,也就是fsimage文件保存NameNode节点中某一时刻内存中的元数据(即目录树),edits保存这一时刻之后的对元数据的更改信息。
镜像的保存:

SecondaryNameNode:主要由两个作用,一是镜像备份(不是NN的备份,但可以做备份),二是日志与镜像的定期合并。
第一步:将hdfs更新记录写入一个新的文件——edits.new。
第二步:将fsimage和editlog通过http协议发送至secondary namenode。
第三步:将fsimage与editlog合并,生成一个新的文件——fsimage.ckpt。这步之所以要在secondary namenode中进行,是因为比较耗时,如果在namenode中进行,或导致整个系统卡顿。
第四步:将生成的fsimage.ckpt通过http协议发送至namenode。
第五步:重命名fsimage.ckpt为fsimage,edits.new为edits。
第六步:等待下一次checkpoint触发SecondaryNameNode进行工作,一直这样循环操作。
注:checkpoint触发的条件可以在core-site.xml文件中进行配置。fs.checkpoint.period表示多长时间记录一次hdfs的镜像。默认是1小时。fs.checkpoint.size表示一次记录多大的size,默认64M。例如如下:
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
<description>The number of seconds between two periodic checkpoints.
</description>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
<description>The size of the current edit log (in bytes) that triggers
a periodic checkpoint even if the fs.checkpoint.period hasn't expired.
</description>
</property>