Storm 工作原理
Storm简介
1.Storm是一套分布式的、可靠的,可容错的用于处理流式数据的系统。
2.Storm也是基于C/S架构来进行工作的,C负责将数据处理的方式的jar(Topology)发送给S,S解析C发送过来的jar(Topology),并按一定规则jar变成多个Task((Spout/Bolt)),生成相关的进程和线程运行里面的Task。
相关述语说明:
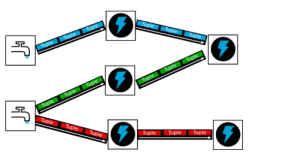
1.Topology(拓扑):storm中运行的一个实时应用程序(Storm的一个任务单元),因为各个组件间的消息流动形成逻辑上的一个拓扑结构(所以叫Topology)。Topolog是一组由Spouts(数据源)和Bolts(数据操作)通过Stream Groupings进行连接组成的图。
2.tuple(元组):一次消息传递的基本单元。本来应该是一个key-value的map,但是由于各个组件间传递的tuple的字段名称已经事先定义好,所以tuple中只要按序填入各个value就行了,所以就是一个value list.
3.Stream:以tuple为单位组成的一条有向无界的数据流。(就是tuple在各个组件中流动时的描述)
4.Spout组件:就是一个继承了某个基类的类,里面有类的方法进行相关的操作,用于获取数据,并传递数据到Bolt。
5.Bolt组件:就是一个继承了某个基类的类,里面有类的方法进行相关的操作,用于对Spout组件发送过来的数据进行处理。
6.Worker进程,用于运行Topology子集(可能Topology的不同组件(Spout/Bolt)会放在不同的Worker进程来运行)的进程。
7.executor线程,为Worker进程中的一个线程,executor可能会同时运行多个组件(Spout/Bolt),当然同一个executor运行的组件类型是一样的。
8.Task,任务,就是组件(Spout/Bolt),一般是一个executor线程运行一个Task
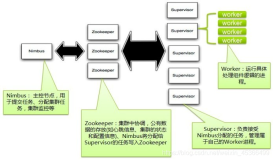
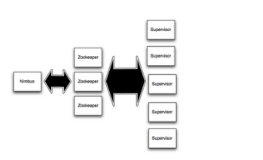
9.Nimbus进程,控制节点(Nimbus节点),主结点运行一个叫做Nimbus的守护进程,它负责在集群内分发代码,为每个工作结点指派任务和监控失败的任务。
10.Supervisor进程,工作节点(Supervisor节点),工作结点运行一个叫做Supervisor的守护进程,每个工作节点都是topology中一个子集的实现。
11.zookeeper,集群协调软件(C/S),是完成nimbus和supervisor之间协调的服务。
12.storm UI,只提供对topology的监控和统计。
架构图:

topology工作原理
1.Storm集群中有两种节点,一种是控制节点(Nimbus节点),另一种是工作节点(Supervisor节点)。
2.所有Topology任务的 提交必须在Storm客户端节点上进行(需要配置 storm.yaml文件),由Nimbus节点分配给其他Supervisor节点进行处理。
3.Nimbus节点首先将提交的Topology进行分片(Spout/Bolt),分成一个个的Task,并将Task和Supervisor相关的信息提交到 zookeeper集群上。
4.Supervisor会去zookeeper集群上认领自己的Task,通知自己的Worker进程进行Task的处理。
topology工作流程
1.提交Topology后,Storm会把代码首先存放到Nimbus节点的inbox目录下,之后,会把当前Storm运行的配置生成一个 stormconf.ser文件放到Nimbus节点的stormdist目录中,在此目录中同时还有序列化之后的Topology代码文件
2.在设定Topology所关联的Spouts和Bolts时,可以同时设置当前Spout和Bolt的executor数目和task数目,默认情况下,一个Topology的task的总和是和executor的总和一致的。之后,系统根据worker(Topology的worker配置参数)的数目,尽量平均的分配这些task的执行。worker在哪个supervisor节点上运行是由storm(随机申请到可用的就OK)本身决定的。
3.Storm看一下那些Worker进程可用,就申请worker(Topology的worker配置参数)的数目给这个Topology。
4.Storm尽量平均的分配这些task到worker。
5.任务分配好之后,Nimbus节点会将任务的信息提交到zookeeper集群,同时在zookeeper集群中会有workerbeats节点,这里存储了当前Topology的所有worker进程的心跳信息。
6.Supervisor 节点会不断的轮询zookeeper集群,在zookeeper的assignments节点中保存了所有Topology的任务分配信息、代码存储目 录、任务之间的关联关系等,Supervisor通过轮询此节点的内容,来领取自己的任务,启动worker进程运行。
7.一个Topology运行之后,就会不断的通过Spouts来发送Stream流,通过Bolts来不断的处理接收到的Stream流,Stream流是无界的。
8.最后一步会不间断的执行,除非手动结束Topology。
Storm简介
1.Storm是一套分布式的、可靠的,可容错的用于处理流式数据的系统。
2.Storm也是基于C/S架构来进行工作的,C负责将数据处理的方式的jar(Topology)发送给S,S解析C发送过来的jar(Topology),并按一定规则jar变成多个Task((Spout/Bolt)),生成相关的进程和线程运行里面的Task。
相关述语说明:
1.Topology(拓扑):storm中运行的一个实时应用程序(Storm的一个任务单元),因为各个组件间的消息流动形成逻辑上的一个拓扑结构(所以叫Topology)。Topolog是一组由Spouts(数据源)和Bolts(数据操作)通过Stream Groupings进行连接组成的图。
2.tuple(元组):一次消息传递的基本单元。本来应该是一个key-value的map,但是由于各个组件间传递的tuple的字段名称已经事先定义好,所以tuple中只要按序填入各个value就行了,所以就是一个value list.
3.Stream:以tuple为单位组成的一条有向无界的数据流。(就是tuple在各个组件中流动时的描述)
4.Spout组件:就是一个继承了某个基类的类,里面有类的方法进行相关的操作,用于获取数据,并传递数据到Bolt。
5.Bolt组件:就是一个继承了某个基类的类,里面有类的方法进行相关的操作,用于对Spout组件发送过来的数据进行处理。
6.Worker进程,用于运行Topology子集(可能Topology的不同组件(Spout/Bolt)会放在不同的Worker进程来运行)的进程。
7.executor线程,为Worker进程中的一个线程,executor可能会同时运行多个组件(Spout/Bolt),当然同一个executor运行的组件类型是一样的。
8.Task,任务,就是组件(Spout/Bolt),一般是一个executor线程运行一个Task
9.Nimbus进程,控制节点(Nimbus节点),主结点运行一个叫做Nimbus的守护进程,它负责在集群内分发代码,为每个工作结点指派任务和监控失败的任务。
10.Supervisor进程,工作节点(Supervisor节点),工作结点运行一个叫做Supervisor的守护进程,每个工作节点都是topology中一个子集的实现。
11.zookeeper,集群协调软件(C/S),是完成nimbus和supervisor之间协调的服务。
12.storm UI,只提供对topology的监控和统计。
架构图:
topology工作原理
1.Storm集群中有两种节点,一种是控制节点(Nimbus节点),另一种是工作节点(Supervisor节点)。
2.所有Topology任务的 提交必须在Storm客户端节点上进行(需要配置 storm.yaml文件),由Nimbus节点分配给其他Supervisor节点进行处理。
3.Nimbus节点首先将提交的Topology进行分片(Spout/Bolt),分成一个个的Task,并将Task和Supervisor相关的信息提交到 zookeeper集群上。
4.Supervisor会去zookeeper集群上认领自己的Task,通知自己的Worker进程进行Task的处理。
topology工作流程
1.提交Topology后,Storm会把代码首先存放到Nimbus节点的inbox目录下,之后,会把当前Storm运行的配置生成一个 stormconf.ser文件放到Nimbus节点的stormdist目录中,在此目录中同时还有序列化之后的Topology代码文件
2.在设定Topology所关联的Spouts和Bolts时,可以同时设置当前Spout和Bolt的executor数目和task数目,默认情况下,一个Topology的task的总和是和executor的总和一致的。之后,系统根据worker(Topology的worker配置参数)的数目,尽量平均的分配这些task的执行。worker在哪个supervisor节点上运行是由storm(随机申请到可用的就OK)本身决定的。
3.Storm看一下那些Worker进程可用,就申请worker(Topology的worker配置参数)的数目给这个Topology。
4.Storm尽量平均的分配这些task到worker。
5.任务分配好之后,Nimbus节点会将任务的信息提交到zookeeper集群,同时在zookeeper集群中会有workerbeats节点,这里存储了当前Topology的所有worker进程的心跳信息。
6.Supervisor 节点会不断的轮询zookeeper集群,在zookeeper的assignments节点中保存了所有Topology的任务分配信息、代码存储目 录、任务之间的关联关系等,Supervisor通过轮询此节点的内容,来领取自己的任务,启动worker进程运行。
7.一个Topology运行之后,就会不断的通过Spouts来发送Stream流,通过Bolts来不断的处理接收到的Stream流,Stream流是无界的。
8.最后一步会不间断的执行,除非手动结束Topology。
本文转自 张冲andy 博客园博客,原文链接: http://www.cnblogs.com/andy6/p/8470017.html ,如需转载请自行联系原作者