摘要:随着十二点的钟声响起,无数人盯着购物车开启了一年一度的“剁手”之旅。可你有没有想过这购物狂欢的背后是什么支撑起了数据规模如此庞大的计算任务?其实不只是“双十一”,每一个用户的点击和浏览,每一件宝贝的排序和推荐,还有贴心的“猜你喜欢”,在这背后“操控”一切的“手”又是什么?本文将带领大家一探究竟。
本期直播精彩回顾,
戳这里!
演讲嘉宾简介:
范朝盛(花名:朝圣),阿里巴巴搜索事业部算法专家,北京大学数学与计算机科学博士,2016年加入阿里巴巴,现主要从事推荐系统特征、模型、架构和大规模机器学习框架的研发工作。
以下内容根据演讲嘉宾视频分享以及PPT整理而成。
本次分享的主要围绕以下三个方面:
一.业务背景
二.XPS机器学习平台
三.XNN深度学习算法
一.业务背景
·业务场景和机器学习的问题
业务场景主要包括三个方面:
(1)
搜索:比如用户在淘宝中输入检索词,网站则会展示出相应宝贝信息的场景。
(2)广告:包括搜索广告,精准定向广告和品牌广告等场景。
(3)推荐:将淘宝客户端网页从上到下滑动,其中很多场景均为推荐子场景。
在这些业务场景中蕴含着各种各样的问题,从技术的角度看,主要的三类问题是经典的数据挖掘问题、图像问题(低质量图像的识别、图像的分类)和语义问题(NLP问题,例如研究检索词和宝贝的标题表示)。从上面的简单介绍中可以看出,阿里团队的业务场景较为复杂,而机器学习在处理这些问题的过程中所扮演的角色是十分重要的。
对于机器学习,需要建模的问题主要有如下几种:
(1)点击率预估:用户曝光,点击宝贝后预估点击率,淘宝所特有的收藏率预估和加入购物车的概率预估,同时还会预估用户点击一个宝贝之后进行购买的转化行为概率的预估。
(2)点击质量好坏的预估,这对于为用户推荐商品操作极为重要。
(3)相关性预估:相关性指的是用户所触达的商品与用户真正相关的可能性,比如用户可能会点击推荐的热门商品,但这种商品与用户之间的相关性系数并不高。
这些问题的解决都需要从用户行为数据获取样本,阿里团队会收集用户日志,然后从中提取机器学习所需要的特征,并且加入相应的标签,例如点击、收藏、加入购物车等。用户行为转化都是比较直觉的,而对于点击质量的好坏,则可以定义用户停留小于一定的时间属于一个bad case ,超过一定的时间属于一个good case,如此来定制标签。
·面临的挑战及解决方法
有了用户数据之后,接下来看一下机器学习过程中可能要面临的挑战。淘宝的机器学习模型要面临的挑战主要有三种:
(1)样本多:在搜索领域已经可以达到每天几百亿的样本规模,而在推荐领域比如首页底部的“猜你喜欢”模块的样本也能够达到百亿规模。每天百亿规模,三个月就可以达到万亿规模,这样庞大的样本数量十分难能可贵,同样也具有很大的挑战性,阿里团队就需要设计专用的机器学习平台来处理解决此类问题。
(2)特征多:特征多主要表现在如下几个方面。首先特征的属性非常繁杂,种类多,总量大。整个淘宝网购平台上有几亿的用户和十几亿的产品,而用户的检索词也是各种各样,非常丰富;淘宝每天还会产生几百亿甚至上千亿的用户行为;而对于用户属性,阿里团队为用户绘制了非常详细的用户画像,所以每个用户的属性十分丰富,与此相同,宝贝的属性也很多。同时,阿里团队通过阿里基础特征服务(ABFS)的框架引入了更多的特征,该框架大规模地引入了用户侧的实时特征统计和产品侧实时特征统计。例如用户最近点击的一系列的宝贝(可能会有上百个),用户三天、五天、七天的点击率的统计,产品的点击率与转化率和该产品在两个小时内被不同类型的人群购买的分布等等。ABFS同时还引入了用户在翻页时上下文的一些特征,例如用户翻页到第三页时可以将第二页的信息可以实时地推送给用户,有助于在建模时作为上下文(context)特征来使用。此外,在ABFS中还建立了图像和语义的表示向量,每一张图片可以被形成一个向量,每个标题(title)词和搜索(query)词也会形成一个向量,然后加入到机器学习的训练集之中,所以综合来看,在基础属性已经非常庞大的基础上,阿里基础特征服务又提供了更多的特征信息,这些特征经过适当的特征组合之后,总量很轻易地就能够达到万亿规模,而处理如此规模的训练数据是一个非常迷人的问题,同时也需要很多特别的设计来方便进行训练。
(3)计算和存储资源有限:在有限的资源条件下如何发挥最大效益和充分协调如此多的任务也是阿里机器学习团队面临的主要挑战之一。
为了应对这些挑战,阿里团队建立了一个机器学习的平台XPS(eXtreme Parameter Server)。该平台实现了流式学习算法选型,即在XPS平台上样本只会经过一次训练而不会反复,因为万亿规模的样本不可能全部加载到内存中进行训练,所以采用了这种方式。阿里团队还会尽量在XPS平台上开发一些创新型的算法,例如xftrl、xltr、xsvd和xnn等,同时也更鼓励一些在此平台上工作的技术人员去开发一些微创新的算法,让XPS平台成为一个专用的大规模机器学习的开发平台,使其具有自己的特色。在XPS平台的命名中选取了eXtreme这个词,蕴含的寓意是追求极致的训练性能和线上效果,这也是阿里团队的理想和目标,如今团队正向着这个目标奋力前进。想要了解整个XPS平台系统的读者可以阅读下面这篇文章自我学习:《扛过双11的千亿级特征分布式机器学习平台XPS》,文章的链接:https://mp.weixin.qq.com/s/TFTf1-x4s35iebiOEMXURQ 这篇文章对XPS系统作了更加详细完整的介绍。
二. XPS机器学习平台
这一部分将为大家简要介绍XPS机器学习平台的整体结构和工程特点。
1.整体结构
首先介绍一下Parameter Server结构,它包括三个部分,分别是Server、Coordinator和Worker,如下图所示:
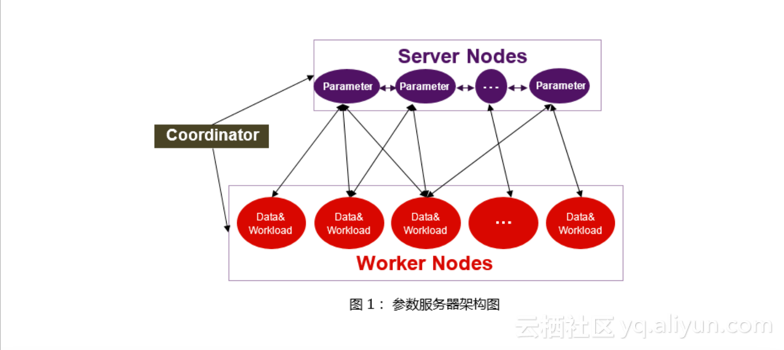
其中Coordinator主要用做中心调度控制,完成Server和Worker的分组,当出现failover的情况时,coordinator可以对failover进行恢复;Worker主要是读取数据,计算梯度并且将其发送给server,是比较独立的一个部分,但Worker不仅计算梯度,有时候还会发送一些特征的曝光点集到Server上进行更新;Server主要用于存储和更新模型参数,其上存储了整个需要用作线上预估的模型的所有参数以及这些参数的附加信息,比如梯度、历史梯度、版本信息和每个特征的曝光点等等这些信息都是存储在Server上的。
当我们在做ps设计时,一个优雅的ps设计能够让用户像单机编程一样快速开发分布式程序,这样做的好处是用户只需要面对Worker来进行编程,而Server和Coordinator的功能尽量对用户屏蔽。XPS的框架设计使得用户只需要关心Worker上的损失函数和怎样计算参数的梯度,而对于Server和Coordinator很少涉及,从而方便用户快速地实现大规模的机器学习的算法。
接下来便进入正题,首先介绍一下XPS的结构图,如下图所示:

从图中可以看出,XPS的底层数据存储用到了MaxCompute,同时还包括Streaming DataHub和Kafka这样的实时数据流;在调度和计算资源层,XPS系统包含了飞天集群调度和CPU与GPU这些资源的控制,在此之上第三层是XPS整个平台;在XPS平台之上是一些对外的算法接口,例如现在提供的XNN、XFTRL、XSVD、XGBOOST和FM等一些算法;最上层的是业务方,业务方可以通过在ODPS中直接调用算法接口,就可以拉起XPS系统。
在MaxCompute集群上,XPS系统可以高效的利用巨大规模的计算资源和存储资源。同时XPS系统会推荐使用者搭建近线的流式学习平台。平台采用近线的流式学习模式,即尽量选择让曝光流等待点击流完成之后再产出训练数据。例如使用者可以设置在其应用场景内用户曝光之后5分钟或者15分钟之内点击都算点击,如此可以保证曝光和点击纠正出来的样本是稳定的。XPS系统同样支持实时学习模式,通过Streaming DataHub和Kafka来引入实时学习的模式,但在实际应用中基于稳定性的原因,使用更多的则是近线的流式学习模式;而在强化学习这样的业务场景下,更多的会采用实时学习模式。
看到这里,读者可能会好奇XPS系统的性能表现如何。下面就列举一些参数来让大家直观的看到XPS系统的性能高低:首先XPS系统的通信性能要比MPI通信提升数倍,原因在于XPS系统的底层设计相比于MPI系统更为优良。另外XPS系统的Server数能够横向扩展到800个,而每个Server有40G的内存,并且在此规模下仍然保持良好的收敛性。有经验的读者会知道,目前一般的平台当Server和worker数过多时会带来一些异步性损失的问题,从而导致模型收敛效果差,甚至不收敛。针对此问题,我们设计了一套解决异步损失的方案,从而使得worker和server线性扩展。当前XPS平台可以在7小时内运行完一个百亿规模的DNN模型,这在目前来说是一个比较快的速度。
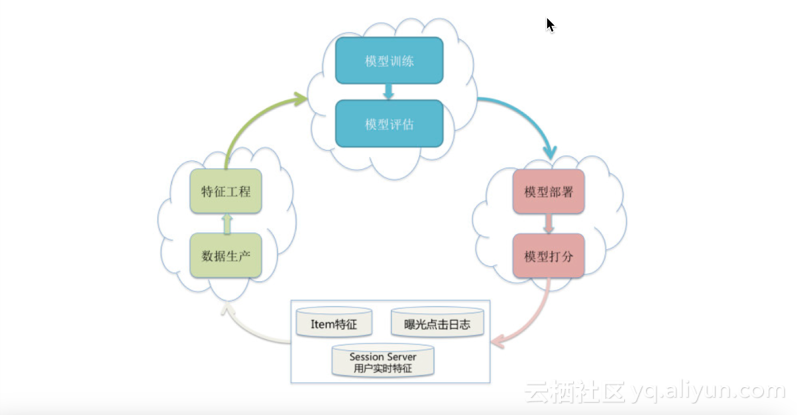
接下来介绍一下XPS系统的整个数据流转过程:首先通过一个线上的曝光点击日志结合ABFS产生的Session Server的实时用户特征,同时结合Item的实时特征,产出整个数据流,然后传给ABFS进行数据生产和特征加工。ABFS会把一条数据变成一条特征,然后传送给XPS模型训练平台进行模型训练。在训练时,我们引入了一个Test Future的机制,能在训练的时候把握一个模型的质量,当模型健康的时候将其推送到线上进行部署。而线上采用的是分布式部署,模型部署完毕之后还会进行打分,打分的同时当一些新的请求发送过来时,我们同时把用户的实时特征、曝光点击日志和Item的特征打印到日志中去,然后形成一个如下图所示的循环。整个循环是比较强调“换血”的过程的,即预估时的样本状态也就是再次需要训练的时候的样本状态。
2.工程特点
阿里团队对XPS系统底层做了很多各种各样的优化,从而使其拥有更好的性能。
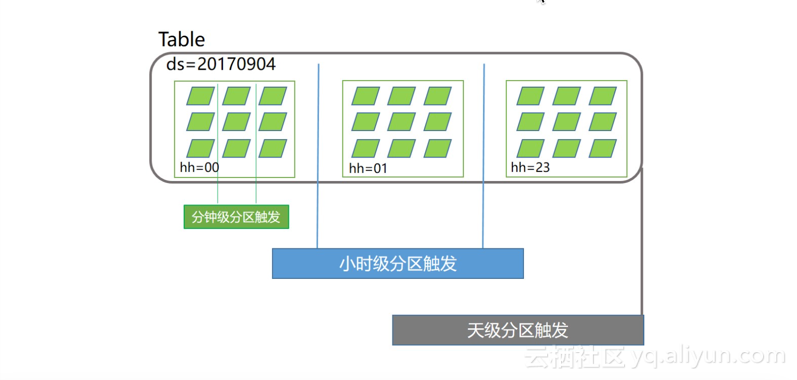
(1)首先介绍的是一个多级分区增量训练的机制,即在MaxCompute中的数据存储可以分为分钟、小时和天三个级别,这使得用户在进行模型训练时可以动态地选择分区来进行增量级别的训练。举个例子,假如一个用户训练一个任务需要三个月的时间,那么用户可以选择使用天级别的数据分区快速运行完数据,然后部署到线上之后可以选择采用小时级别的训练流程,使其每个小时产出一个增量的模型来进行部署。当用户的任务需要紧急调控的时候,可以适当地选择分钟级别的更新来使模型具有更好地实时性。由此看来XPS整个平台的数据采用了多级分区增量训练,它具有良好的灵活性,且可以通过简单的配置去除不达标的“脏数据”。
(2)第二个特点是流式评估模式(Test-Future-Data),这种评估模式十分有趣。首先介绍一下流式评估模式的概念,可以拿它与经典的静态测试来做个比较。传统的静态测试分为两种,第一种测试方式会采样一定比例的数据例如20%作为测试数据,测试的是模型分布已知的情况下的数据状况,该测试方式缺陷明显,当前测试的结果并不能很好的反应和预估未来的测试状况。第二种静态测试的方式则是Test-LastDay-Data,该方式会训练N-1天,然后测试第N天,该方式的缺点在于用户同时调整多个模型时必须使训练数据完全固定下来,然后把最后一天当作测试,每次迭代数据都要等待整个过程运行完进行测试。而流式评估模式就是在静态测试的基础上进行了一定的扩展,以动态测试为出发点,在“未来”的数据流上评估整个模型的质量。该评估模式会在训练过程中不断地提取未来的Minibatch作为测试集进行测试。一个简单的例子是假设有N个Minibatch,现在已经训练到第M个,此时可以指定第M+1个到第M+10个Minibatch作为一个小测试集来测试整个模型质量。该测试模式的好处是可以实时反映模型的质量,当模型数据出现问题时,通过准度等指标可以快速发现问题,从而帮助用户快速调整参数。并且当用户突然发现收敛的模型在线上服务出现问题时,可以通过查看模型的动态AUC来发现奇异的任务。流式评估模式已经被XPS平台用户所熟知和采纳,由于流式测试模式可以使用户实时并行调控多个模型,所以现在的用户已经习惯于采用这种方便高效的动态测试模式进行测试,而不是用传统的静态测试。
读到这里可能部分读者对流式评估模式过程的了解仍旧模糊,下面就通过一个直观图来展示一下流式评估的过程:
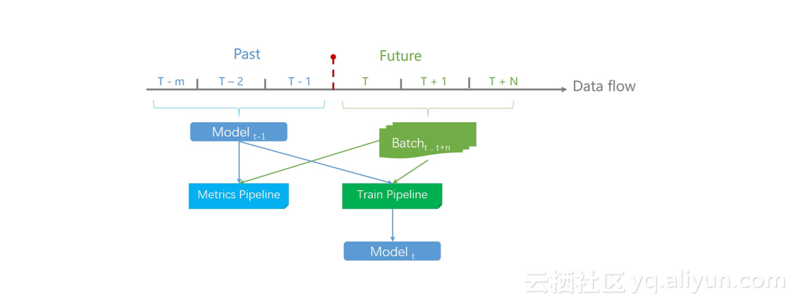
对于T-1时刻的模型,基于流式评估会计算其在T到T+N时刻的数据流的评价指标。这些评价指标包括AUC、PCOPC、MAE和RMSE,其中PCOPC是指整个场景的预估准确率和真实准确率的比值,它代表了机器学习任务的偏度。例如点击率为0.5,若预估值为0.6,则预估偏高;相反,若预估值为0.4,则预估偏低。在训练时,用户通过PCOPC指标可以发现之前的一些算法的预估值偏度存在一定的问题,而在流式评估模式下,用户可以在调参的时候很快地发现这些问题。与此同时,流式评估模式会统计诸如正样本数、负样本数和模型规模等指标,从而帮助用户在整个学习过程中可以方便地进行模型的裁剪以及整个场景中样本的监控。
(3)XPS系统的第三个底层优化是通信优化,这也是整个XPS系统中最重要的优化。
※小包的问题的优化。
首先介绍一下小包问题,在整个XPS系统中,Worker和Server之间存在非常多的小包交互,每次通信的信息量在1到2 MB之间,如果Server的数量有100个左右,那么分配到每个Server上的参数key分片的大小可以达到1到10 KB的规模。对于通信频率的问题,假设每个Worker上有四五个数据结构的话,每次的pull和push为两次通信,那么每个Worker上的通信次数就可以达到8到10次,即每个batch有2到10次通信,这样的通信频率是非常高的。这就涉及到一个延迟敏感的问题,在计算和通信的性能占比中要尽量降低通信所占的比例,单次通信要控制在毫秒级,防止拉低整个集群的效率,从而把更多的性能投入到计算当中去。
对于小包问题的优化方法大概分成三种。第一种是把通信请求小包合并成大包,对于dense神经网络发送梯度时不是每一层都发送,而是把多层梯度合并成一个长向量后进行通信;而对于sparse特征组则可以将多个特征组合并成一个向量进行通信,以此来降低通信的频率;第二种优化方式是降低Worker和Server端的锁开销,Worker端是一个读取数据然后计算梯度的过程,所以是全链路无锁的;而Server端引入了一个多分片的Actor模式,即每个线程管理的范围已知,所以包内无需加锁,如此以来锁开销就会大大降低;最后一种优化的方式降低序列化、反序列化对象的创建和内存拷贝。
※稀疏矩阵通信优化
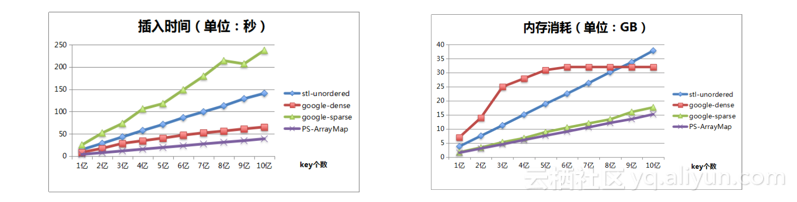
在整个XPS系统或Parameter Server架构的通信中有大量的SparseId(即我们通常所说的大规模离散ID),这就形成了稀疏矩阵通信优化的需求,目的是降低内部通信的频率。对于这个问题,阿里团队经过长时间的探索后发现已有的如Google Dense和Google Sparse等类库均不能满足XPS平台稀疏矩阵的高频通信需求。在此基础上,XPS系统利用多重数组跳表的技术实现了自定义的数组哈希表(ArrayHashmap),它采用了realloc和mremap的方式来手工管理内存,目的是为了保证数组哈希表的键(key)和其对应的值(value)分别处于连续的空间中,通俗的解释就是所有的键(key)连在一起,所有的值(value)连在一起,这样设计的优势显而易见,在通信时直接发送内存块的内容即可,而不需要像传统的Hashmap一样在通信时需要将目标key一个一个提取出来再打包发送,实现了序列化和反序列化的零拷贝。有了稀疏矩阵的通信优化之后,XPS整个系统的性能得到了质的飞跃,同时系统对于SDK层面的矩阵进行了封装并提供了相应的访问接口,从而使用户不需要感知底层实现,并且支持string和int64作为矩阵的索引,使得整个平台训练的key既可以是原始明文也可以是哈希化之后的对应值,方便开发人员进行调试和很多一次性的测试工作。以上就是XPS系统的整体工程优化的内容,通过这些优化让整个XPS系统能够在7个小时内完成百亿数据规模的训练,而每个训练样本具有100个特征。
三. XNN深度学习算法
1.算法思想
在介绍XNN的基本算法思想之前,首先介绍一下XPS算法体系的设计理念:
※如果非必要情况,无需采样。对于点击率较大的场景,尽量选择不采样。因为样本空间蕴含了所有用户和产品的各个维度的信息,不采样能够保持数据和特征的完整性。因为如果采样,丢掉的正样本或负样本若再次出现对整体现实效果的影响是未知的。通过不采样,我们可以还原每个特征在整个数据流中出现的曝光次数、关注次数和点击次数等信息,并使得这些信息变得可追踪,使得整个离线训练时的点击率、预估的情况与线上真实的点击率相匹配,而不存在PCOPC准度偏高或偏低的情况。
※整个算法体系的设计需要适应千亿规模的特征和万亿规模的样本。
※模型需要能适应业务的动态性变化。例如阿里“双十一”期间的各种业务需要进行动态调控,那么就需要模型能够迅速的提供实时反馈,从而帮助“双十一”取得更好的成交。
鉴于上述的三个设计理念,阿里团队建立了有层次的模型体系。其中主要的内容是从XPS系统开发起始至今这一段时间内提出的四个创新的算法:
通过扩展线性算法FTRL并落地业务场景提出了XFTRL算法,该算法对于传统的线性算法FTRL的各种参数进行了流式的衰减,并且通过指数衰减的方式引入了二正则以避免参数突然偏离的情况。
通过扩展推荐领域著名的矩阵分解学派算法SVD,在其中引入了SLIM思想,提出了XSVD算法。XSVD算法使传统的SVD算法能够进行大规模的流式计算。
提出了XLTR算法,并且在其中引入了自动做特征的过程和多目标学习的特性。
深度优化了经典的神经网络算法,提出了XNN算法。
下面重点介绍一下XNN算法的设计思想:
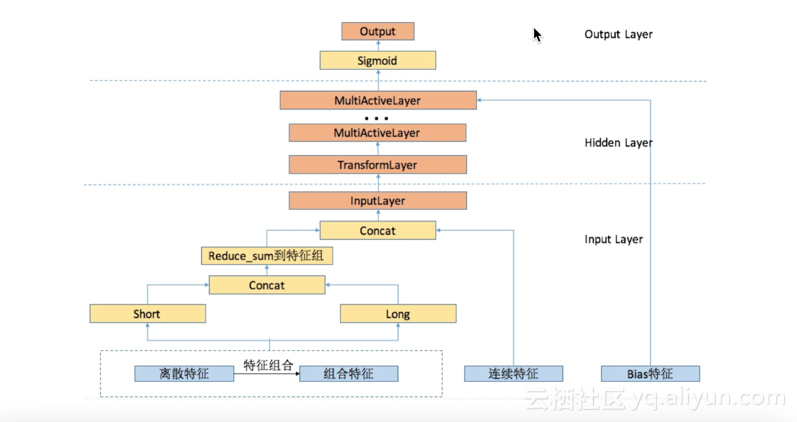
从下面的直观图中可以看到整个XNN算法的体系结构。XNN算法的底层是一些离散特征和组合特征,形成了每个特征或长或短的embedding,长的embedding会分为二维、四维、八维和十六维,这些特征concatenate在一起并且做group级别的Reduce_sum,然后再与其他特征组和连续特征比如点击率等concatenate在一起做联合训练,结合在一起的这些特征会被传入输入层进行转化,这种转化的目的是将特征均匀化和标准化,逐层上传到最上层后经过sigmoid激活函数处理后输出。另外会有一些blas特征(用户在翻页时的页面信息)放在上层,因为通过日常测试会发现此类特征放于XNN算法的底层其效果并不理想。
用户可以通过不同的算子组件组合出适合不同业务场景的XNN变形算法,这种组合就用到了下面将要提到的XNN算子体系结构:
※XNN的初始化算子采用了正态分布和均匀分布,并且使用Lazy Initialization的初始化方式,即当用户使用该特征时才会进行初始化,避免过早初始化对性能的不必要开销。
※在优化算子方面,XNN使用了FTRL、AdaGrad、Adam和AmsGrad等算子,并且在原始基础上做了很多适合多种业务场景的优化。
※由于在分布式问题上存在许多异步性的问题,所以XNN算法提出了二阶梯度补偿和梯度折扣等异步性算子。
※XNN的激活算子采用了ReLU、SeLU和Sigmoid
下图中展示了XNN算法在Worker端和Server端的伪代码:


2.XNN算法的优化技巧
(1)输入层优化
特征模型化:XNN模型能够自动统计每个特征长期、中期和短期的session统计值,作为连续值特征加到输入层。因为ABFS能统计的维度总是有限的,但是通过特征模型化(Automatic Session)的方式可以统计到任何维度的Session而无需打印日志,大家可以把它看做是对Session的动态建模。
特征动态Embedding:在流式学习过程中,随着特征重要性增大,Session的维度会动态增长,以此达到内存动态负载均衡的目的。
输入层的优化对于整个神经网络来说是十分重要的,简单来说就是用好特征Embedding向量的加减乘除。
(2)Server更新模式优化
Hot Update: 例如用户登录后在短时间内浏览了大量的宝贝(瀑布流浏览),那么此用户的特征则是周期性的大量聚集和更新,然后“消失”,在这个过程中需要避免高频特征过度更新的问题。
Lazy Update:对于长尾的特征,要累计到一定的曝光数再更新,目的是避免长尾特征获得过多不置信权重而分走过多的长尾权重。
梯度修正:Pull和Push时根据权重值的差别进行梯度修正。
(3)算子优化
在算子优化方面,XNN算法会保持采用一些最新的算子如Adagrad、Adam和AmsGrad等,始终追随学术界的步伐并对这些最新的算子进行更新优化以便于应用到实际业务场景中去。同时XNN算法还会采用最新的激活函数例如Sigmoid、ReLU、LeakyReLU和SeLU等。
而算子优化中最重要的是流式指数衰减,即每次更新时对所有参数乘以一个相应的衰减值,从而保证最新的样本获得最大的权重。与此同时,对于点击率波动较大的场景,可以周期性地设置每个分区的启动学习速率以快速适应数据流的变化。XNN算法还提供了一些可以灵活修改的算子,充分根据梯度、历史梯度、历史更新次数等联合修正经典算子,其中历史更新次数是一个很重要的指标,它代表了一个特征在最近一段时间内的更新情况,根据这些信息设置置信度和打折率等能够使算子更加适应当前的业务需求。
XNN算子优化遵循“如无必要,无需正则”的原则,由于样本分布具有连续性,所以传统的训练集和测试集定义的“过拟合”不适应,对于相隔的样本可以看做近似“同分布”,因此适度过拟合效果更好。XNN利用参数指数衰减模式来替代2正则的作用,兼顾了数据的流式特点,同时利用特征动态擦除模式来替代1正则的作用,保证了稀疏性。
3.XNN的落地实用技巧
(1)特征的哈希化和动态擦除
在训练的过程中,特征的序列化会耗费许多时间,而特征的字符串化会占用很多内存,所以最好采用特征的哈希化。而训练中的特征变化较多,可以使用动态擦除的方式来去除一些较弱(如曝光较低)的特征,以此达到节约内存的目的。在训练时要保留组合特征,因为在数据挖掘和深度学习中的组合特征非常重要,对于持续的长尾优化来说这一点更是如此。
(2)样本和特征处理
XNN训练的样本务必充分打散,因为未能充分打散的样本会引发局部过拟合问题。对于特征的离散化问题,无需过度离散化,只需要保留到小数点后几位即可。而为了增强模型的表达能力,则可以用模型技术批量设计“新特征”,如Automatic Session。
(3)调参技巧
强烈建议读者使用Test-Future-Data评估模式,因为该模式可以监控PCOPC走势并及时调整训练的过程,能够极大地加速调参过程。当训练中不小心引入部分周期性特征时,需要移除此类周期特征以避免造成PCOPC的波动。训练时还可以随机打印百万分之一特征的梯度变化信息到Server端,以便于线上出现问题进行排查。
(4)快速一致性调试和分布式预估
建议用户将特征明文和特征哈希值均打印出来以便于进行调试,这与线上预估的设计存在一定联系。线上预估技术若采用标准分布式,则模型表会同时保留特征哈希值和分布式分列信息,因为分布式分列信息是动态变化的,所以增加了通信和存储的代价;比较快速的方法是基于Map-Reduce手工统计原始特征和分到哪些组,然后再和产出模型的哈希值作结合后进行分布式地上线。
(5)服务的动态性
由于资源和时间有限,所以需要快速响应业务的需求。例如“双十一”当天,其业务变化十分迅速,需要快速适应业务的变化。可以通过调整衰减指数和打折力度来增强或者削弱当前样本的重要性。当样本由于近期数据变化幅度较大(换血量过大)而出现“抖动”状况时,可以通过逐步降低历史梯度平方的最大值,加快机器学习的速率来适应业务的变化。
(6)快速迭代训练的建议
用好特征:如上文提到的分布式特征的重要性筛选,同时还需要移除周期特征,防止引起PCOPC的抖动;加入一些组合特征,这对于整个模型的点和边的渲染是非常重要的。
在快速迭代的过程中可以使用模型热启动的思想,即老模型的特征Embedding表达了复用,而新加的特征对应的神经网络的边设置一些初始值,然后直接续跑,比如在短期内运行新特征模型,结果也是收敛的,这样就可以做到快速上线。
四.总结
XPS团队打造的系列算法在集团内得到的广泛的应用,我们希望用技术去拓展商业的边界。得益于XPS系列算法,每天数百亿级别样本的场景可以进行全量不采样地进行流式训练,通过实时Session特征维度拓展特征体系,使得模型特征达到千亿规模。千亿特征的时代已经到来,让我们享受这数据的饕餮盛宴。
直播专题回顾,
戳这里!
