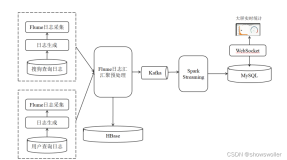
1,安装并成功能运行flume
2,安装并成功能运行kafka
3,安装并成功能运行zookeeper
4,开始整合flume收集的数据,写入kafka
a,修改flume的配置文加:
vim flume_kafka.conf
agent1.sources = r1
agent1.sinks = k1
agent1.channels = c1
# Describe/configure the source
agent1.sources.r1.type = exec
agent1.sources.r1.command=tail -f /opt/logs/usercenter.log
# Use a channel which buffers events in memory
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
agent1.sources.r1.channels = c1
agent1.sinks.k1.channel = c1
# # Describe the sink 这部分就是输入到kafka的写法
##############################################
agent1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.k1.topic = test
agent1.sinks.k1.brokerList = hadoop1:9092,hadoop2:9092,hadoop3:9092
agent1.sinks.k1.requiredAcks = 1
agent1.sinks.k1.batchSize = 20
##############################################
b,下载第三方插件
下载flume-kafka-plus:https://github.com/beyondj2ee/flumeng-kafka-plugin
把lib目录下的

和package下的

都放到flume的lib目录
如果,报错,请看这个文档
http://wenda.chinahadoop.cn/question/4079?notification_id=290954&rf=false&item_id=10382#!answer_10382
修改原有的flume-conf文件
在插件包里有一个flume-conf.properties,把这个文件放到flume的conf文件夹里
然后修改以下内容
|
1
2
3
4
5
6
7
|
producer.sources.s.
type
=
exec
producer.sources.s.
command
=
tail
-f -n+1
/opt/logs/test
.log
producer.sources.s.channels = c
……
producer.sinks.r.custom.topic.name=
test
……
consumer.sources.s.custom.topic.name=
test
|
c:启动服务
启动zookeeper集群
zkServer.sh start
zkServer.sh start
zkServer.sh start
还需要创建一个新的地址
zookeeper/bin/zkCli.sh
create /kafka test
启动kafka broker 集群
bin/kafka-server-start.sh config/server.properties
bin/kafka-server-start.sh config/server.properties
bin/kafka-server-start.sh config/server.properties
创建kafka topic
bin/kafka-topics.sh --create --zookeeper localhost:2181/kafka --replication-factor 1 --partitions 1 --topic test
启动kafka consumer
bin/kafka-console-consumer.sh --zookeeper localhost:2181/kafka --topic test --from-beginning
启动flume
bin/flume-ng agent --conf conf --conf-file conf/flume_kafka.properties --name producer -Dflume.root.logger=INFO,console
测试
|
1
|
echo
"this is a test"
>>
/opt/logs/test
.log
|
此时只要能在consumer里现“this is a test”就表示成功
错误总结:
http://472053211.blog.51cto.com/3692116/1655844
本文转自crazy_charles 51CTO博客,原文链接:http://blog.51cto.com/douya/1860896,如需转载请自行联系原作者