


众所周知,MySQL8.0之前的版本DDL是非原子的。也就是说对于复合的DDL,比如DROP TABLE t1, t2;执行过程中如果遇到server crash,有可能出现表t1被DROP掉了,但是t2没有被DROP掉的情况。即便是一条DDL,比如CREATE TABLE t1(a int);也可能在server crash的情况下导致建表不完整,有可能在建表失败的情况下遗留.frm或者.ibd文件。
上面情况出现的主要原因就是MySQL不支持原子的DDL。从图1可以看出,MySQL8.0以前,metadata在Server layer是存储在MyISAM引擎的系统表里,对于事务型引擎Innodb则自己存储一份metadata。这也导致MySQL存在如下一些弊端:
- metadata由于存储在Server layer以及存储引擎(这里特指Innodb),两份系统表很容易造成数据的不一致。
- 两份系统表存储的信息有所不同,访问Server layer以及存储引擎需要使用不同API,这种设计导致了不能很好的统一对系统metadata的访问。另外两份API,也同时增加了代码的维护量。
- 由于Server layer的metadata存储在非事务引擎(MyISAM)里,所以在进行crash recovery的时候就不能维持原子性。
- DDL的非原子性使得Replication处理异常情况变得更加复杂。比如DROP TABLE t1, t2; 如果DROP t1成功,但是DROP t2失败,Replication就无法保证主备一致性了。
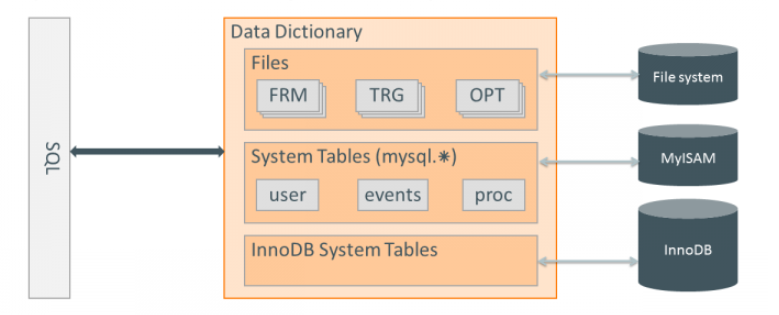
图1: MySQL Data Dictionary before MySQL8.0
MySQL8.0为了解决上面的缺陷,引入了事务型DDL。首先我们看一下MySQL8.0 metadata存储的架构变化:
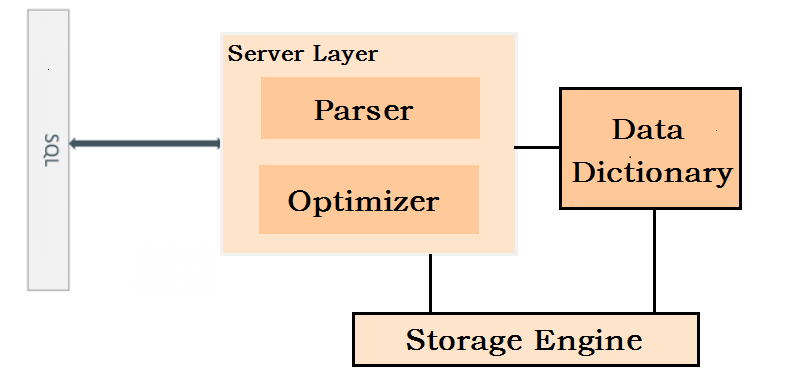
图2: MySQL Data Dictionary in MySQL8.0
图2我们可以看到,Server layer(后面简称SL)以及Storage Engine(后面简称SE) 使用同一份data dictionary(后面简称DD)用来存储metadata。SL和SE将各自需要的metadata存入DD中。由于DD使用Innodb作为存储引擎,所以crash recovery的时候,DD可以安全的进行事务回滚。
下面我们介绍一下MySQL8.0为了实现原子DDL,在源码层面引入的一些重要数据结构:
class Dictionary_client
/*
这个类提供了SL以及SE统一访问DD的接口。每一个THD都有一个访问DD的Dictionary_client类型的成员。 如果需要操作DD,直接调用相关接口函数即可。
这个类成员函数的主要方法是去访问一个多session共享的cache来操作DD存储的各种对象。和其他cache一样,如果在访问过程中,在这个cache里没有找到对应的对象,那么后台会自动读取DD中的相关metadata,进而构建相应的数据表。
*/
{
public:
/*
这个类是用来辅助Dictionary_client自动释放获取的DD对象。该类会自动跟踪当前Dictionary_client获取的每个DD对象。当Dictionary_client对象生命期结束的时候,该对象会自动释放当前session获取的DD对象。
这个类对象可以进行嵌套,Dictionary_client中的m_current_releaser成员变量始终会指向嵌套堆栈最顶层的一个Auto_releaser对象。如果当前的Auto_releaser对象结束了生命期,它会释放掉自己记录的位于共享cache中的DD对象,同时把m_current_releaser指向上一个老的Auto_releaser对象。
*/
class Auto_releaser
{
friend class Dictionary_client;
private:
Dictionary_client *m_client; // 用来指向当前的Dictionary_client对象
Object_registry m_release_registry; // 用来记录从共享cache中获取的DD对象,以便自动释放
Auto_releaser *m_prev; // 用来形成列表,以方便当前实例生命期结束的时候,将Dictionary_client对象中的Auto_releaser重新指向之前创建的实例。
/**
注册一个DD对象
*/
template <typename T>
void auto_release(Cache_element<T> *element)
{
// Catch situations where we do not use a non-default releaser.
DBUG_ASSERT(m_prev != NULL);
m_release_registry.put(element);
}
/**
当一个Auto_releaser对象结束生命期的时候,有的DD对象并不能结束生命期,该函数用来把一个DD对象转移给上一个Auto_releaser对象。
*/
template <typename T>
void transfer_release(const T* object);
/**
移除一个DD对象
*/
template <typename T>
Auto_releaser *remove(Cache_element<T> *element);
// Create a new empty auto releaser. Used only by the Dictionary_client.
Auto_releaser();
public:
/**
Create a new auto releaser and link it into the dictionary client
as the current releaser.
@param client Dictionary client for which to install this auto
releaser.
*/
explicit Auto_releaser(Dictionary_client *client);
// Release all objects registered and restore previous releaser.
~Auto_releaser();
// Debug dump to stderr.
template <typename T>
void dump() const;
};
private:
std::vector<Entity_object*> m_uncached_objects; // Objects to be deleted.
Object_registry m_registry_committed; // Registry of committed objects.
Object_registry m_registry_uncommitted; // Registry of uncommitted objects.
Object_registry m_registry_dropped; // Registry of dropped objects.
THD *m_thd; // Thread context, needed for cache misses.
Auto_releaser m_default_releaser; // Default auto releaser.
Auto_releaser *m_current_releaser; // Current auto releaser.
...
}
/**
该类定义了共享的DD对象缓存,该类取代了8.0之前的table_cache。数据库对象会根据对象类型从不同的map中获取对象。所有对DD对象的访问都需要经过该缓存。
*/
class Shared_dictionary_cache
{
private:
// 设置一些缓存的最大容量,目前看来都是硬编码
static const size_t collation_capacity= 256;
static const size_t column_statistics_capacity= 32;
static const size_t charset_capacity= 64;
static const size_t event_capacity= 256;
static const size_t spatial_reference_system_capacity= 256;
/**
Maximum number of DD resource group objects to be kept in
cache. We use value of 32 which is a fairly reasonable upper limit
of resource group configurations that may be in use.
*/
static const size_t resource_group_capacity= 32;
/* 下面是各种不同类型DD对象缓存map */
Shared_multi_map<Abstract_table> m_abstract_table_map;
Shared_multi_map<Charset> m_charset_map;
Shared_multi_map<Collation> m_collation_map;
Shared_multi_map<Column_statistics> m_column_stat_map;
Shared_multi_map<Event> m_event_map;
Shared_multi_map<Resource_group> m_resource_group_map;
Shared_multi_map<Routine> m_routine_map;
Shared_multi_map<Schema> m_schema_map;
Shared_multi_map<Spatial_reference_system> m_spatial_reference_system_map;
Shared_multi_map<Tablespace> m_tablespace_map;
template <typename T> struct Type_selector { }; // Dummy type to use for
// selecting map instance.
/**
Overloaded functions to use for selecting map instance based
on a key type. Const and non-const variants.
*/
Shared_multi_map<Abstract_table> *m_map(Type_selector<Abstract_table>)
{ return &m_abstract_table_map; }
Shared_multi_map<Charset> *m_map(Type_selector<Charset>)
{ return &m_charset_map; }
Shared_multi_map<Collation> *m_map(Type_selector<Collation>)
{ return &m_collation_map; }
Shared_multi_map<Column_statistics> *m_map(Type_selector<Column_statistics>)
{ return &m_column_stat_map; }
Shared_multi_map<Event> *m_map(Type_selector<Event>)
{ return &m_event_map; }
Shared_multi_map<Resource_group> *m_map(Type_selector<Resource_group>)
{ return &m_resource_group_map; }
Shared_multi_map<Spatial_reference_system> m_spatial_reference_system_map;
Shared_multi_map<Tablespace> m_tablespace_map;
template <typename T> struct Type_selector { }; // Dummy type to use for
// selecting map instance.
/**
Overloaded functions to use for selecting map instance based
on a key type. Const and non-const variants.
*/
Shared_multi_map<Abstract_table> *m_map(Type_selector<Abstract_table>)
{ return &m_abstract_table_map; }
Shared_multi_map<Charset> *m_map(Type_selector<Charset>)
{ return &m_charset_map; }
Shared_multi_map<Collation> *m_map(Type_selector<Collation>)
{ return &m_collation_map; }
Shared_multi_map<Column_statistics> *m_map(Type_selector<Column_statistics>)
{ return &m_column_stat_map; }
Shared_multi_map<Event> *m_map(Type_selector<Event>)
{ return &m_event_map; }
Shared_multi_map<Resource_group> *m_map(Type_selector<Resource_group>)
{ return &m_resource_group_map; }
Shared_multi_map<Routine> *m_map(Type_selector<Routine>)
{ return &m_routine_map; }
Shared_multi_map<Schema> *m_map(Type_selector<Schema>)
{ return &m_schema_map; }
Shared_multi_map<Spatial_reference_system> *
m_map(Type_selector<Spatial_reference_system>)
{ return &m_spatial_reference_system_map; }
Shared_multi_map<Tablespace> *m_map(Type_selector<Tablespace>)
{ return &m_tablespace_map; }
const Shared_multi_map<Abstract_table> *m_map(Type_selector<Abstract_table>) const
{ return &m_abstract_table_map; }
const Shared_multi_map<Charset> *m_map(Type_selector<Charset>) const
{ return &m_charset_map; }
const Shared_multi_map<Collation> *m_map(Type_selector<Collation>) const
{ return &m_collation_map; }
const Shared_multi_map<Column_statistics> *
m_map(Type_selector<Column_statistics>) const
{ return &m_column_stat_map; }
const Shared_multi_map<Schema> *m_map(Type_selector<Schema>) const
{ return &m_schema_map; }
const Shared_multi_map<Spatial_reference_system> *
m_map(Type_selector<Spatial_reference_system>) const
{ return &m_spatial_reference_system_map; }
const Shared_multi_map<Tablespace> *m_map(Type_selector<Tablespace>) const
{ return &m_tablespace_map; }
const Shared_multi_map<Resource_group> *m_map(
{ return &m_abstract_table_map; }
const Shared_multi_map<Charset> *m_map(Type_selector<Charset>) const
{ return &m_charset_map; }
const Shared_multi_map<Collation> *m_map(Type_selector<Collation>) const
{ return &m_collation_map; }
const Shared_multi_map<Column_statistics> *
m_map(Type_selector<Column_statistics>) const
{ return &m_column_stat_map; }
const Shared_multi_map<Schema> *m_map(Type_selector<Schema>) const
{ return &m_schema_map; }
const Shared_multi_map<Spatial_reference_system> *
m_map(Type_selector<Spatial_reference_system>) const
{ return &m_spatial_reference_system_map; }
const Shared_multi_map<Tablespace> *m_map(Type_selector<Tablespace>) const
{ return &m_tablespace_map; }
const Shared_multi_map<Resource_group> *m_map(
Type_selector<Resource_group>) const
{ return &m_resource_group_map; }
/**
根据DD对象类型获取对应的map对象。
*/
template <typename T>
Shared_multi_map<T> *m_map()
{ return m_map(Type_selector<T>()); }
template <typename T>
const Shared_multi_map<T> *m_map() const
{ return m_map(Type_selector<T>()); }
Shared_dictionary_cache()
{ }
public:
static Shared_dictionary_cache *instance();
// Set capacity of the shared maps.
static void init();
// Shutdown the shared maps.
static void shutdown();
// Reset the shared cache. Optionally keep the core DD table meta data.
static void reset(bool keep_dd_entities);
// Reset the table and tablespace partitions.
static bool reset_tables_and_tablespaces(THD *thd);
/**
根据DD类型及名称来验证对象是否在缓存中。
*/
template <typename K, typename T>
bool available(const K &key)
{ return m_map<T>()->available(key); }
/**
该函数用来输出调试信息。
*/
template <typename T>
void dump() const
{
#ifndef DBUG_OFF
fprintf(stderr, "================================\n");
fprintf(stderr, "Shared dictionary cache\n");
m_map<T>()->dump();
fprintf(stderr, "================================\n");
#endif
}
};
} // namespace cache
/**
这个类抽象了对DD对象的metadata进行存储的方法。它是一个静态类。对于新创建的对象(表,索引,表空间等)都会通过该类进行一个clone, clone之后该类会将该对象的metadata存储到对应的系统表中。另外,它也提供接口用来从系统表中获取metadata并生成调用需要的DD对象。
该类同时也提供了一个缓存,每次调用存储新对象的时候,它会自动将一个对象clone缓存起来。该类成员函数中core_xxx都是负责操作缓存。
*/
class Storage_adapter
{
friend class dd_cache_unittest::CacheStorageTest;
private:
/**
Use an id not starting at 1 to make it easy to recognize ids generated
before objects are stored persistently.
*/
static const Object_id FIRST_OID= 10001;
/**
为新的对象产生一个ID标识。
*/
template <typename T>
Object_id next_oid();
/**
根据对象名称从缓存中返回一个对象的clone。
*/
template <typename K, typename T>
void core_get(const K &key, const T **object);
Object_registry m_core_registry; // Object registry storing core DD objects.
mysql_mutex_t m_lock; // Single mutex to protect the registry.
static bool s_use_fake_storage; // Whether to use the core registry to
// simulate the storage engine.
Storage_adapter()
{ mysql_mutex_init(PSI_NOT_INSTRUMENTED, &m_lock, MY_MUTEX_INIT_FAST); }
~Storage_adapter()
{
mysql_mutex_lock(&m_lock);
m_core_registry.erase_all();
mysql_mutex_unlock(&m_lock);
mysql_mutex_destroy(&m_lock);
}
public:
/* 这里可以获取到单例。 */
static Storage_adapter *instance();
/**
根据对象类型返回缓存区中所有对象的数量。
*/
template <typename T>
size_t core_size();
/**
获取对象ID标识
*/
template <typename T>
Object_id core_get_id(const typename T::Name_key &key);
/**
该函数可以根据对象类型及名称获取对象。如果该对象已经被缓存,那么调用core_get获取clone对象。否则会根据对象类型到对应的metadata数据表中查找并构造一个对象。
*/
template <typename K, typename T>
static bool get(THD *thd,
const K &key,
enum_tx_isolation isolation,
bool bypass_core_registry,
const T **object);
/**
缓存中清除一个对象.
*/
template <typename T>
void core_drop(THD *thd, const T *object);
/**
从对象所对应的各个metadata数据表中清除相关数据.
*/
template <typename T>
static bool drop(THD *thd, const T *object);
/**
缓冲区中添加一个DD对象
*/
template <typename T>
void core_store(THD *thd, T *object);
/**
该函数会根据DD对象类型,将metadata存入相关的系统表中。后面的建表语句中会对该函数进行详细的解释。
*/
template <typename T>
static bool store(THD *thd, T *object);
/**
同步缓存中的DD对象。
*/
template <typename T>
bool core_sync(THD *thd, const typename T::Name_key &key, const T *object);
/**
Remove and delete all elements and objects from core storage.
*/
void erase_all();
/**
备份缓存中的对象。
*/
void dump();
};
} // namespace cache
} // namespace dd
接下来我们以CREATE TABLE为例从源码上简单看一下MYSQL8.0是如何实现原子DDL的。
CREATE TABLE实现的流程图如下:
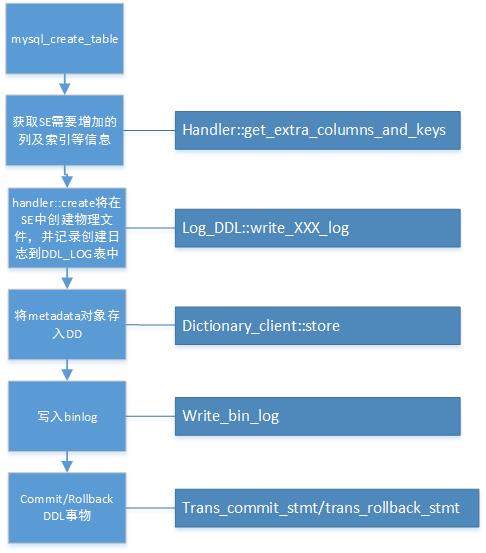
这里我们看一下CREATE TABLE过程中新增加的几个比较重要的函数(这里主要看Innodb存储引擎):
/*
该函数将会为Innodb存储引擎创建它自己需要的系统列。实际上就是把原来Innodb自己的系统表统一到DD中。
*/
int
ha_innobase::get_extra_columns_and_keys(
const HA_CREATE_INFO*,
const List<Create_field>*,
const KEY*,
uint,
dd::Table* dd_table)
{
DBUG_ENTER("ha_innobase::get_extra_columns_and_keys");
THD* thd = ha_thd();
dd::Index* primary = nullptr;
bool has_fulltext = false;
const dd::Index* fts_doc_id_index = nullptr;
/* 检查各个定义的索引是否合法。*/
for (dd::Index* i : *dd_table->indexes()) {
/* The name "PRIMARY" is reserved for the PRIMARY KEY */
ut_ad((i->type() == dd::Index::IT_PRIMARY)
== !my_strcasecmp(system_charset_info, i->name().c_str(),
primary_key_name));
if (!my_strcasecmp(system_charset_info,
i->name().c_str(), FTS_DOC_ID_INDEX_NAME)) {
ut_ad(!fts_doc_id_index);
ut_ad(i->type() != dd::Index::IT_PRIMARY);
fts_doc_id_index = i;
}
/* 验证索引算法是否有效 */
switch (i->algorithm()) {
...
}
/* 验证并处理全文索引 */
if (has_fulltext) {
...
}
/* 如果当前没有定义主键,Innodb将自动增加DB_ROW_ID作为主键。 */
if (primary == nullptr) {
dd::Column* db_row_id = dd_add_hidden_column(
dd_table, "DB_ROW_ID", DATA_ROW_ID_LEN,
dd::enum_column_types::INT24);
if (db_row_id == nullptr) {
DBUG_RETURN(ER_WRONG_COLUMN_NAME);
}
primary = dd_set_hidden_unique_index(
dd_table->add_first_index(),
primary_key_name,
db_row_id);
}
/* 为二级索引增加主键列 */
std::vector<const dd::Index_element*,
ut_allocator<const dd::Index_element*>> pk_elements;
for (dd::Index* index : *dd_table->indexes()) {
if (index == primary) {
continue;
}
pk_elements.clear();
for (const dd::Index_element* e : primary->elements()) {
if (e->is_prefix() ||
std::search_n(index->elements().begin(),
index->elements().end(), 1, e,
[](const dd::Index_element* ie,
const dd::Index_element* e) {
return(&ie->column()
== &e->column());
}) == index->elements().end()) {
pk_elements.push_back(e);
}
}
for (const dd::Index_element* e : pk_elements) {
auto ie = index->add_element(
const_cast<dd::Column*>(&e->column()));
ie->set_hidden(true);
ie->set_order(e->order());
}
}
/* 增加系统列 DB_TRX_ID, DB_ROLL_PTR. */
dd::Column* db_trx_id = dd_add_hidden_column(
dd_table, "DB_TRX_ID", DATA_TRX_ID_LEN,
dd::enum_column_types::INT24);
if (db_trx_id == nullptr) {
DBUG_RETURN(ER_WRONG_COLUMN_NAME);
}
dd::Column* db_roll_ptr = dd_add_hidden_column(
dd_table, "DB_ROLL_PTR", DATA_ROLL_PTR_LEN,
dd::enum_column_types::LONGLONG);
if (db_roll_ptr == nullptr) {
DBUG_RETURN(ER_WRONG_COLUMN_NAME);
}
dd_add_hidden_element(primary, db_trx_id);
dd_add_hidden_element(primary, db_roll_ptr);
/* Add all non-virtual columns to the clustered index,
unless they already part of the PRIMARY KEY. */
for (const dd::Column* c : const_cast<const dd::Table*>(dd_table)->columns()) {
if (c->is_hidden() || c->is_virtual()) {
continue;
}
if (std::search_n(primary->elements().begin(),
primary->elements().end(), 1,
c, [](const dd::Index_element* e,
const dd::Column* c)
{
return(!e->is_prefix()
&& &e->column() == c);
})
== primary->elements().end()) {
dd_add_hidden_element(primary, c);
}
}
DBUG_RETURN(0);
}
template <typename T>
Dictionary_client::store(T* object)
{
...
/* 调用下面函数完成存储 */
if (Storage_adapter::store(m_thd, object))
return true;
...
}
/* 该函数负责将DD对象写入对应的系统表中。 */
template <typename T>
bool Storage_adapter::store(THD *thd, T *object)
{
// 如果是测试或者未到真正需要建表的阶段,只存入缓存,不进行持久化存储。
if (s_use_fake_storage ||
bootstrap::DD_bootstrap_ctx::instance().get_stage() <
bootstrap::Stage::CREATED_TABLES)
{
instance()->core_store(thd, object);
return false;
}
// 这里会验证DD对象的有效性
if (object->impl()->validate())
{
DBUG_ASSERT(thd->is_system_thread() || thd->killed || thd->is_error());
return true;
}
// 切换上下文,包括更新系统表的时候关闭binlog、修改auto_increament_increament增量、设置一些相关变量等与修改DD相关的上下文。
Update_dictionary_tables_ctx ctx(thd);
ctx.otx.register_tables<T>();
DEBUG_SYNC(thd, "before_storing_dd_object");
// object->impl()->store 这里会将DD对象存入相关的系统表。具体比如表,列, 表空间是如何持久化到系统表中的,由于篇幅有限,我们将在以后的月报中继续剖析。
if (ctx.otx.open_tables() || object->impl()->store(&ctx.otx))
{
DBUG_ASSERT(thd->is_system_thread() || thd->killed || thd->is_error());
return true;
}
// Do not create SDIs for tablespaces and tables while creating
// dictionary entry during upgrade.
if (bootstrap::DD_bootstrap_ctx::instance().get_stage() >
bootstrap::Stage::CREATED_TABLES &&
dd::upgrade_57::allow_sdi_creation() &&
sdi::store(thd, object))
return true;
return false;
}
综上篇章简要的描述了MySQL8.0实现原子DDL的背景以及一些重点的数据结构,并对CREATE TABLE过程,以及创建过程中用到的几个重要函数进行了分析。但是原子DDL的实现是一个非常大的工程,本篇月报由于篇幅问题,只是挖了冰山一角。以后的月报会继续对原子DDL的实现进行分析,希望大家持续关注。




