笔者最近开始学习InnoDB的内部机制,参照之前的几篇文章整理出InnoDB多版本部分相关的一些实现原理。
[MySQL 5.6] Innodb 新特性之 multi purge thread
对于undo日志,第1篇文章写得非常清楚,图文并茂。本文有关undo的大部分内容也是取自此文,这里只是以笔者的视角重新组织描述一下。
在此特别感谢前面同学多年的积累和热心分享:)
笔者属于学习阶段,如描述有问题请多指正。
Read view
InnoDB支持MVCC多版本,其中RC(Read Committed)和RR(Repeatable Read)隔离级别是利用consistent read view(一致读视图)方式支持的。 所谓consistent read view就是在某一时刻给事务系统trx_sys打snapshot(快照),把当时trx_sys状态(包括活跃读写事务数组)记下来,之后的所有读操作根据其事务ID(即trx_id)与snapshot中的trx_sys的状态作比较,以此判断read view对于事务的可见性。
Read view中保存的trx_sys状态主要包括
- low_limit_id:high water mark,大于等于view->low_limit_id的事务对于view都是不可见的
- up_limit_id:low water mark,小于view->up_limit_id的事务对于view一定是可见的
- low_limit_no:trx_no小于view->low_limit_no的undo log对于view是可以purge的
- rw_trx_ids:读写事务数组
RR隔离级别(除了Gap锁之外)和RC隔离级别的差别是创建snapshot时机不同。 RR隔离级别是在事务开始时刻,确切地说是第一个读操作创建read view的;RC隔离级别是在语句开始时刻创建read view的。
创建/关闭read view需要持有trx_sys->mutex,会降低系统性能,5.7版本对此进行优化,在事务提交时session会cache只读事务的read view。
下次创建read view,判断如果是只读事务并且系统的读写事务状态没有发生变化,即trx_sys的max_trx_id没有向前推进,而且没有新的读写事务产生,就可以重用上次的read view。
Read view创建之后,读数据时比较记录最后更新的trx_id和view的high/low water mark和读写事务数组即可判断可见性。
如前所述,如果记录最新数据是当前事务trx的更新结果,对应当前read view一定是可见的。
除此之外可以通过high/low water mark快速判断:
- trx_id < view->up_limit_id的记录对于当前read view是一定可见的;
- trx_id >= view->low_limit_id的记录对于当前read view是一定不可见的;
如果trx_id落在[up_limit_id, low_limit_id),需要在活跃读写事务数组查找trx_id是否存在,如果存在,记录对于当前read view是不可见的。
由于InnoDB的二级索引只保存page最后更新的trx_id,当利用二级索引进行查询的时候,如果page的trx_id小于view->up_limit_id,可以直接判断page的所有记录对于当前view是可见的,否则需要回clustered索引进行判断。
如果记录对于view不可见,需要通过记录的DB_ROLL_PTR指针遍历history list构造当前view可见版本数据。
回滚段
InnoDB也是采用回滚段的方式构建old version记录,这跟Oracle方式类似。
记录的DB_ROLL_PTR指向最近一次更新所创建的回滚段;每条undo log也会指向更早版本的undo log,从而形成一条更新链。通过这个更新链,不同事务可以找到其对应版本的undo log,组成old version记录,这条链就是记录的history list。
分配rollback segment
MySQL 5.6对于没有显示指定READ ONLY事务,默认为是读写事务。在事务开启时刻分配trx_id和回滚段,并把当前事务加到trx_sys的读写事务数组中。
5.7版本对于所有事务默认为只读事务,遇到第一个写操作时,只读事务切换成读写事务分配trx_id和回滚段,并把当前事务加到trx_sys的读写事务数组中。
分配回滚段的工作在函数trx_assign_rseg_low进行,分配策略是采用round-robin方式。
从5.6开始支持独立的undo表空间,InnoDB支持128个undo回滚段,请参照第1篇文章。
- rseg0:预留在系统表空间ibdata中
- rseg1~rseg32:这32个回滚段存放于临时表的系统表空间中
- rseg33~rseg127:根据配置存放到独立undo表空间中(如果没有打开独立Undo表空间,则存放于ibdata中)
trx_assign_rseg_low判断,如果支持独立的undo表空间,在undo表空间有可用回滚段的情况下避免使用系统表空间的回滚段。
rseg->skip_allocation为TRUE表示rseg所在的表空间要被truncate,应该避免使用此rseg分配回滚段。此种情况,必须保证有至少2个活跃的undo表空间,并且至少2个活跃的undo slot。
分配成功时,递增rseg->trx_ref_count,保证rseg的表空间不会被truncate。
临时表操作不记redo log,最终调用get_next_noredo_rseg函数进行分配;其他情况调用get_next_redo_rseg。
回滚段实际上是undo文件组织方式,每个回滚段维护了一个段头页(segment header),该page划分了1024个slot(TRX_RSEG_N_SLOTS),每个slot对应到一个undo log对象。
理论上,InnoDB最多支持 96 (128 - 32 /* temp-tablespace */) * 1024个普通事务。
但如果是临时表的事务,可能还需要多分配1个slot(临时表的系统表空间)。
- 只读阶段为临时表分配的,在临时表的系统表空间中分配
- 读写阶段在undo表空间分配
分配undo log
Insert数据只对当前事务或者提交之后可见,所以insert的undo log在事务commit后就可以释放了。
Update/delete的undo记录通常用来维护old version记录,为查询提供服务;只有当trx_sys中没有任何view需要访问那个old version的数据时才可以被释放。
InnoDB对insert和update/delete分配不同的undo slot
- insert的undo slot记在trx->rsegs.m_redo.insert_undo,调用trx_undo_assign_undo分配
- update的undo slot记在trx->rsegs.m_redo.undate_undo,调用trx_undo_assign_undo分配
trx_undo_assign_undo
I. 检查cached队列是否有缓存的undo log(内存中数据结构是trx_undo_t)
- 如果存在,把这个undo log从cached队列移除
-
reuse的逻辑:
a.insert undo:重新初始化undo page的header信息(trx_undo_insert_header_reuse),并在redo log记一条MLOG_UNDO_HDR_REUSE日志
b.update undo:在undo page的header上分配新的undo header(trx_undo_header_create),并在redo log记一条MLOG_UNDO_HDR_CREATE日志
- 预留xid空间
- 重新初始化undo(trx_undo_mem_init_for_reuse)把undo->state设置为TRX_UNDO_ACTIVE,并把undo->state写入到第一个undo page的TRX_UNDO_SEG_HDR+TRX_UNDO_STATE位置上
注1:TRX_UNDO_SEG_HDR表示segment header起始offset 注2:undo segment与事务trx是一一对应关系,undo segment header的状态(TRX_UNDO_STATE)跟事务当前状态也是一一对应的
如下图(引自第1篇文章)
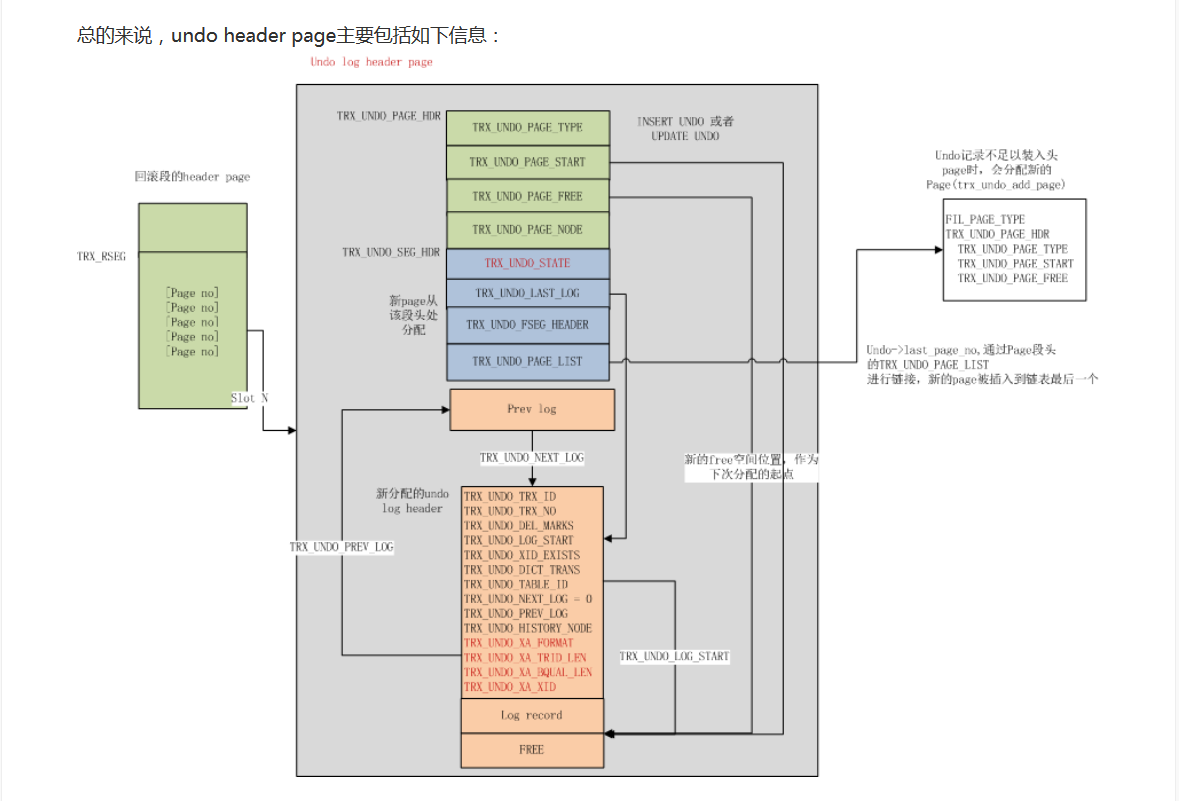
undo segment是个独立的段,每个undo segment包含1个header page(第1个undo page)和若干个记录undo日志的undo page。
第1个undo page中存储的是元信息: 首先存储的是undo page的元信息,位于TRX_UNDO_PAGE_HDR到TRX_UNDO_SEG_HDR之间。
TRX_UNDO_PAGE_START:指向page中第一个undo log TRX_UNDO_PAGE_FREE:指向page中下一个undo log要写到的位置 TRX_UNDO_PAGE_NODE:undo segment所有page组成一个双向链表,每个page的TRX_UNDO_PAGE_NODE字段作为连接件,第一个undo page中的TRX_UNDO_PAGE_LIST作为表头
/* undo page header */
#define TRX_UNDO_PAGE_HDR FSEG_PAGE_DATA
#define TRX_UNDO_PAGE_TYPE 0 /*!< TRX_UNDO_INSERT or
TRX_UNDO_UPDATE */
#define TRX_UNDO_PAGE_START 2 /*!< Byte offset where the undo log
records for the LATEST transaction
start on this page (remember that
in an update undo log, the first page
can contain several undo logs) */
#define TRX_UNDO_PAGE_FREE 4 /*!< On each page of the undo log this
field contains the byte offset of the
first free byte on the page */
#define TRX_UNDO_PAGE_NODE 6 /*!< The file list node in the chain
of undo log pages */
/*-------------------------------------------------------------*/
#define TRX_UNDO_PAGE_HDR_SIZE (6 + FLST_NODE_SIZE)
/*!< Size of the transaction undo
log page header, in bytes */
之后是undo segment的元信息,位于TRX_UNDO_SEG_HDR到TRX_UNDO_SEG_HDR+TRX_UNDO_SEG_HDR_SIZE
TRX_UNDO_STATE:表示undo segment的状态,一个undo segment可以包含多个undo log,但至多只有1个active undo log,也就是最近的undo log TRX_UNDO_LAST_LOG:指向最近的undo log的header信息 TRX_UNDO_FSEG_HEADER:存储的是undo segment对应的file segment信息,在fseg_create_general中设置(4字节space id,4字节的page no,2字节的page offset)
undo segment从buffer pool移除被persist到磁盘时,就写到file segment指定的位置上
#define TRX_UNDO_SEG_HDR (TRX_UNDO_PAGE_HDR + TRX_UNDO_PAGE_HDR_SIZE)
#define TRX_UNDO_STATE 0 /*!< TRX_UNDO_ACTIVE, ... */
#define TRX_UNDO_LAST_LOG 2 /*!< Offset of the last undo log header
on the segment header page, 0 if
none */
#define TRX_UNDO_FSEG_HEADER 4 /*!< Header for the file segment which
the undo log segment occupies */
#define TRX_UNDO_PAGE_LIST (4 + FSEG_HEADER_SIZE)
/*!< Base node for the list of pages in
the undo log segment; defined only on
the undo log segment's first page */
/*-------------------------------------------------------------*/
/** Size of the undo log segment header */
#define TRX_UNDO_SEG_HDR_SIZE (4 + FSEG_HEADER_SIZE + FLST_BASE_NODE_SIZE)
再之后是undo log header信息,所有的undo log header都存储在第一个undo page上。
II. 从cached队列分配undo失败时,需要真正分配一个undo segment(trx_undo_seg_create)
首先要从rseg分配一个slot(trx_rsegf_undo_find_free),每个rseg至多支持1024个slot。找到空slot返回index。
如果当前rseg已满,trx_undo_seg_create返回DB_TOO_MANY_CONCURRENT_TRXS向上层报错,表示并发事务太多无法创建undo segment。
然后在rseg对应的table space创建一个新的file segment,file segment信息记在segment header的TRX_UNDO_FSEG_HEADER(fseg_create_general)。
trx_undo_seg_create在创建file segment之后,把新创建segment的page no写到rseg对应slot上建立映射关系,并返回新创建segment的page。
file segment与undo segment的映射关系,还有rseg[slot]与file segment对应page的映射关系都是在trx_undo_seg_create绑定的。cached undo不会更新这两个映射关系。
III. trx_undo_seg_create返回的page上创建新的undo header;上层负责初始化trx_undo_t数据结构
trx_undo_create为新创建的undo header创建内存数据结构trx_undo_t(trx_undo_mem_create),把undo->state设置为TRX_UNDO_ACTIVE。
IV. 分配好的trx_undo_t会加入到事务的insert_undo_list或者update_undo_list队列上
写入undo log
trx_undo_assign_undo分配undo之后,就可往其中写入undo记录。写入的page来自undo->last_page_no,初始情况下等于hdr_page_no。
update undo包含一个重要的部分:记录的当前回滚段指针要写到undo log里面,以便维护记录的历史数据链。
read view需要读老版本数据时,会通过记录中当前的回滚段指针开始向前找到可见版本的数据。
完成Undo log写入后,构建新的回滚段指针并返回(trx_undo_build_roll_ptr),这个指针也就是clustered索引记录的DB_ROLL_PTR。
回滚段指针包括rseg->id、日志所在的page no、以及page内偏移量,需要记录到clustered索引记录中。这里rseg->id用来确定rseg->space,真正用于定位undo log位置的其实是<rseg->space, undo->page,undo->page_offset>三元组。
事务prepare
设置undo->state为TRX_UNDO_PREPARED,并把这个状态写到第一个undo page的(TRX_UNDO_SEG_HDR+TRX_UNDO_STATE)位置上。
除此之外,prepare阶段还要更新xid信息。
事务commit
在事务commit阶段,需要把undo->state设置为完成状态,并把undo加到undo segment的history list。正在提交的undo header被指向history list的第一项,表示当前事务history list最近的undo。
undo->state完成状态包括3种,在trx_undo_set_state_at_finish设置
- undo只占一个page,而且第一个undo page已使用的空间小于3/4 (TRX_UNDO_PAGE_REUSE_LIMIT):状态设置为TRX_UNDO_CACHED
- 不满足1的情况下,如果是insert_undo(TRX_UNDO_INSERT):状态设置为TRX_UNDO_TO_FREE
- 不满足1和2的情况下,状态设置为TRX_UNDO_TO_PURGE,表示undo可能需要purge线程清理
cached undo会被到cached队列上,这个队列就是trx_undo_assign_undo提到的cached队列
设置完undo->state之后,需要把这个状态写入到第一个undo page的(TRX_UNDO_SEG_HDR+TRX_UNDO_STATE)位置上
把undo加到undo segment header的history list
Insert的old version没有实际意义,所以insert undo在事务commit时就可以释放了。
trx_undo_set_state_at_finish里面有cached策略,如果只占1个undo page,并且undo page已使用的空间不足pagesize的3/4可以被reuse,其实大部分insert undo都属于这种情况。
Update undo需要维护history list。这里先提一下trx->no,它维护了事务trx commit顺序,跟事务的trx_id一样,也是使用max_trx_id递增产生。
另外,purge_sys(purge的全局数据结构)维护个最小堆,每个rollback segment第1次事务提交时向最小堆插入数据,旨在找到trx_no最小的rollback segment进行purge。后面每次处理完1个rseg后,会把下一个undo记录的trx_no压入到这个最小堆,作为rseg的cursor。
事务commit时按照trx->no顺序,把事务当前的undo log挂到undo segment history list的表头,指向事务最近的undo log。
History list里的undo都是已提交事务的,当前事务所修改的undo log都记录在这里,按照从新->老方式排列,最老的undo log在尾部。
undo加入到history list的方式是:以undo log的TRX_UNDO_HISTORY_NODE作为连接件,加入到第一个undo page的TRX_RSEG_HISTORY。
一般来说,每次调用trx_purge_add_update_undo_to_history都会把undo加入到history list,只有在undo page无法被reuse时才更新history list大小(可以认为是个优化,最后一次更新history length)。
在此之后,trx_purge_add_update_undo_to_history会把undo log header的TRX_UNDO_TRX_NO更新为trx_no。
如果undo->del_marks是FALSE,这个函数也会更新TRX_UNDO_DEL_MARKS(undo segment创建或者reuse被初始化为TRUE),澄清这不是delete marker。
如果undo segment自创建以来(也可能是上次purge完成之后)中第1个事务commit,还需要更新purge有关的一些参数,指向下次purge从哪里开始执行。
老版本数据purge
旧版本数据不再被任何view访问就可以被删除了。5.6以上版本支持独立purge线程,用户可以通过参数Innodb_purge_threads设置purge线程个数。
有两类purge线程:
- coordinator thread:srv_purge_coordinator_thread,全局只有1个
- worker thread:srv_worker_thread,系统有innodb_purge_threads - 1个
coordinator thread负责启动worker thread参与到purge工作中。
增加purge线程的策略是:trx_sys->rseg_history_len比上次循环变大了或者rseg_history_len超过某一阈值,需要引进更多的worker thread。
减少purge线程的策略是:如果之前使用多个purge 线程,trx_sys->rseg_history_len并没有变大,可能需要减少worker thread。
在进行purge之前,首先要确定purge线程要做哪些工作,也就是说哪些undo log可以被purged。
purge也是通过read view来确定工作范围,被称为purge view。如果系统有活跃read view,就选取最老的read view作为purge view。
如果不存在就给trx_sys的状态打个snapshot,作为purge view,可以被purge的undo log其trx_no一定是小于系统中所有已提交事务的trx->no。
这里插一句,在事务commit时,会把产生的trx->no加入到trx_sys->serialisation_list链表,这个链表是按照trx->no升序次序排列,也就是维护了trx commit顺序。
InnoDB初始化的时候会初始化purge_sys数据结构,其中一个工作就是创建purge graph。
这是总共3层结构的图:
- 第1层是fork节点
- 第2次是thrd节点(表示purge thread)
- 第3层是node节点(表示purge task)
所有的thrd节点被链入到fork->thrs链表中;fork地址存储在purge_sys->query,可以通过purge_sys直接访问。
执行purge的时候总是遍历purge_sys->query->thrs链表,给每个purge线程分配purge任务(trx_purge_attach_undo_recs)。
解析undo log的调用路径如下:
srv_purge_coordinator_thread -> srv_do_purge -> trx_purge ->
trx_purge_attach_undo_recs -> trx_purge_fetch_next_rec ->
trx_purge_get_next_rec
purge_sys->next_stored为FALSE时,表示rseg_iter当前指向的rseg无效,需要把rseg_iter移到下一个有效的rseg(TrxUndoRsegsIterator::set_next)。
purge_sys->purge_queue维护了一个最小堆,每次pop最顶元素,可以得到trx_no最小的rollback segment(TrxUndoRsegsIterator::set_next)。
5.7支持临时表的noredo的rollback segment,set_next遇到redo rollback segment和noredo rollback segment同时存在的情况会一股脑把这两个rollback segment都pop出来加入到 purge_sys->rseg_iter->m_trx_undo_rsegs数组中,也在TrxUndoRsegsIterator::set_next实现。
如果没有rollback segment需要purge话,purge_sys->rseg设置为NULL,purge线程会去睡眠(trx_purge_choose_next_log)。
一般情况下都是有rollback segment需要处理的,purge_sys->rseg更新成purge_sys->rseg_iter->m_trx_undo_rsegs的第1项(至多2项)。
purge_sys中的相应成员也要更新,指向当前rseg上次purge到的位置(TrxUndoRsegsIterator::set_next)。
update undo的del_marks域正常情况下都是TRUE,因为update/delete操作都需要对old value进行标记删除。
如果purge_sys->rseg->last_del_marks是FALSE的话,表示这是一个dummy的undo log,不需要做物理删除。这种情况下,把purge_sys->offset设置成0,做个标记表示这个undo log不需要被purged(trx_purge_read_undo_rec)。
正常情况下purge_sys->rseg->last_del_marks是TRUE,可以通过<purge_sys->rseg->space, purge_sys->hdr_page_no, purge_sys->hdr_offset>读取undo log记录(trx_purge_read_undo_rec)。
并把purge_sys以下四个域设置成undo log记录相应的信息(trx_purge_read_undo_rec)。
purge_sys->offset = offset; /* undo log记录的offset */
purge_sys->page_no = page_no; /* undo log记录的pageno */
purge_sys->iter.undo_no = undo_no; /* undo log记录的undo_no,trx内部undo的序列号 */
purge_sys->iter.undo_rseg_space = undo_rseg_space; /* undo log的tablespace */
为了保证purge_sys以上4个域一定是指向下一个有效undo log,每次读取undo log时都会捎带着读取下一个undo log,并把上面这四个域更新为下一个undo log的信息,方面后续访问(trx_purge_get_next_rec)。
如果是dummy undo,trx_purge_get_next_rec会去读prev_undo(trx_purge_rseg_get_next_history_log),用prev_log信息更新rseg中下一个purge信息。
在此之后,还会把rseg->last_trx_no压入最小堆,待后面继续处理这个rseg。 然后调用trx_purge_choose_next_log选择下一个处理的rseg,并读取第一个undo log(trx_purge_get_next_rec)。
就这样挨个读取undo log,trx_purge_attach_undo_recs中有一个大循环,每次调用trx_purge_fetch_next_rec读到一个undo log后,把它存放到purge节点(purge graph的第三级节点) node->undo_recs数组里面,循环下一次执行切换到下一个thr(purge 线程)。
循环的结束条件是:
- 没有新的undo log
- 处理过的undo log达到batch size(一般是300)
达到循环结束条件后,trx_purge_attach_undo_recs返回。如果n_purge_threads > 1 (需要worker线程参与purge),coordinator线程会以round-robin方式启动n_purge_threads - 1个worker线程。
不管有没有worker线程参与purge,coordinator线程都会调用que_run_threads(在trx_purge上下文)去处理purge任务。
purge任务如何处理呢?通俗的说purge就是删除被标记delete marker的记录项。
大致过程如下:
srv_purge_coordinator_thread -> srv_do_purge -> trx_purge ->
que_run_threads -> que_run_threads_low -> que_thr_step
row_purge_step -> row_purge -> row_purge_record ->
row_purge_del_mark -> row_purge_remove_sec_if_poss
一般删除的原则是先删除二级索引再删除clustered索引(row_purge_del_mark)。
另一种情况是聚集索引in-place更新了,但二级索引上的记录顺序可能发生变化,而二级索引的更新总是标记删除 + 插入,因此需要根据回滚段记录去检查二级索引记录序是否发生变化,并执行清理操作(row_purge_upd_exist_or_extern)。
前面提到过在parse undo log时,可能遇到dummy undo log。返回到row_purge执行时需要判读是否是dummy undo,如果是就什么也不做。
truncate undo space
trx_purge在处理完一个batch(通常是300)之后,调用trx_purge_truncate_historypurge_sys对每一个rseg尝试释放undo log(trx_purge_truncate_rseg_history)。
大致过程是:把每个purge过的undo log从history list移除,如果undo segment中所有的undo log都被释放,可以尝试释放undo segment,这里隐式释放file segment到达释放存储空间的目的。
由于篇幅有限,这部分就不深入介绍了。