热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
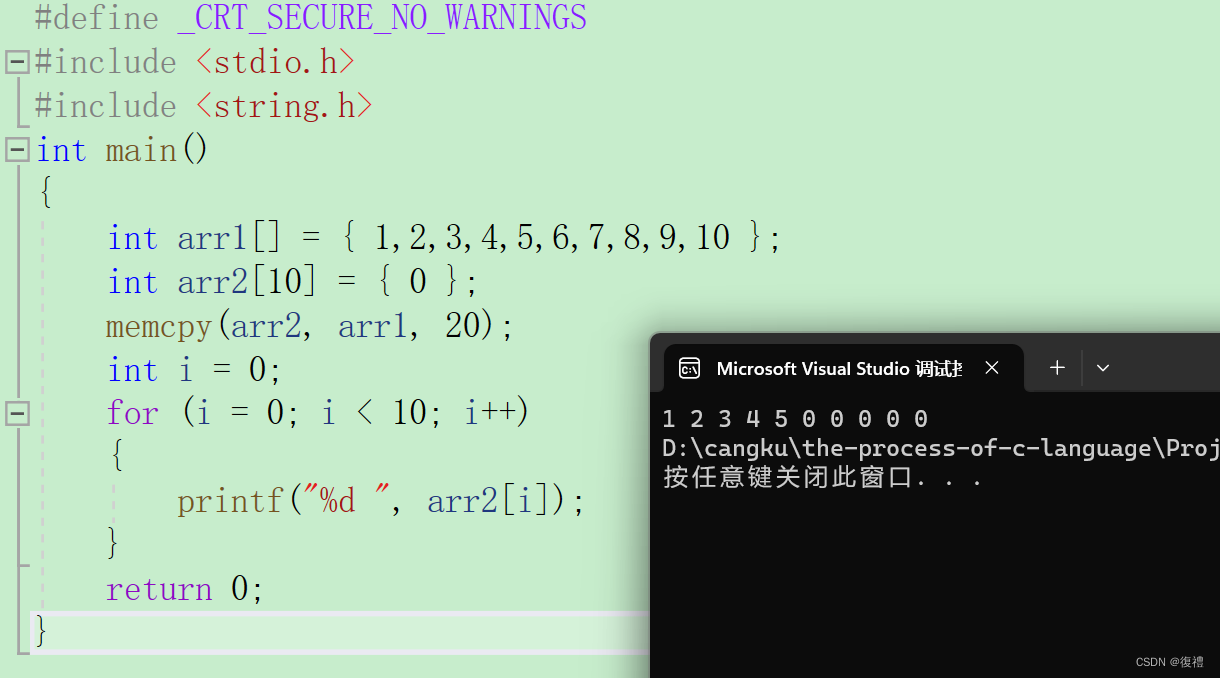
C语言:内存函数(memcpy memmove memset memcmp使用)
顺序队列的初始化、进队和出队(C语言)
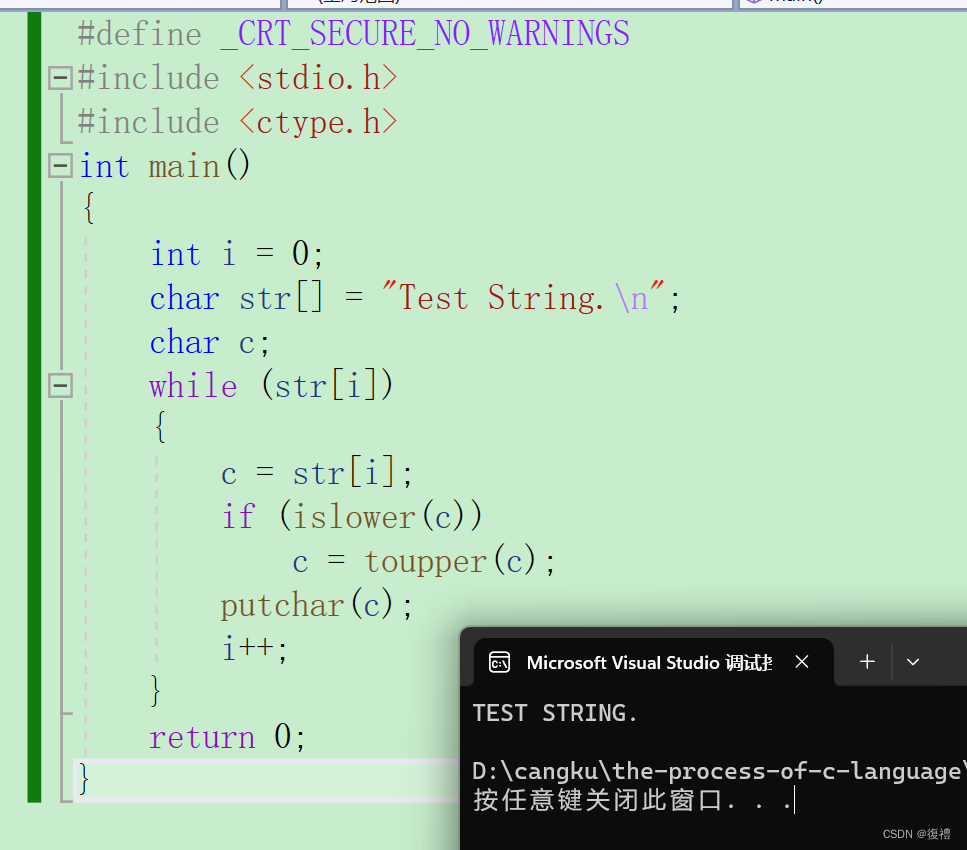
C语言:字符函数和字符串函数(strlen strcat strcmp strncmp等函数和模拟实现)
链栈的初始化以及用C语言表示进栈、出栈和判断栈空
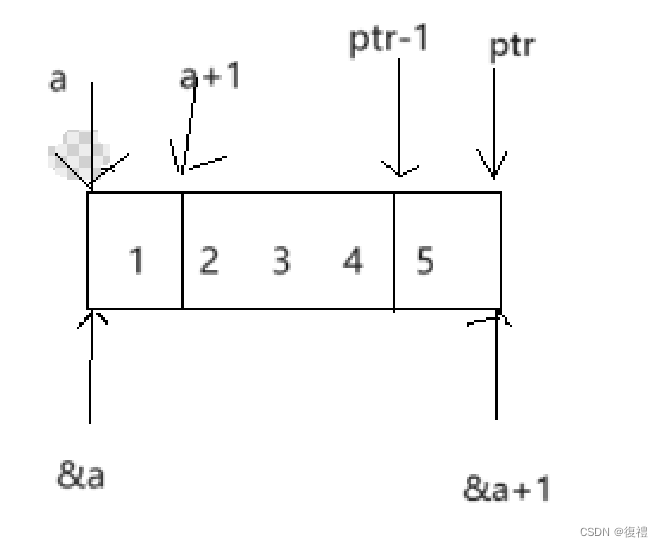
C语言:指针运算笔试题解析(包括令人费解的指针题目)
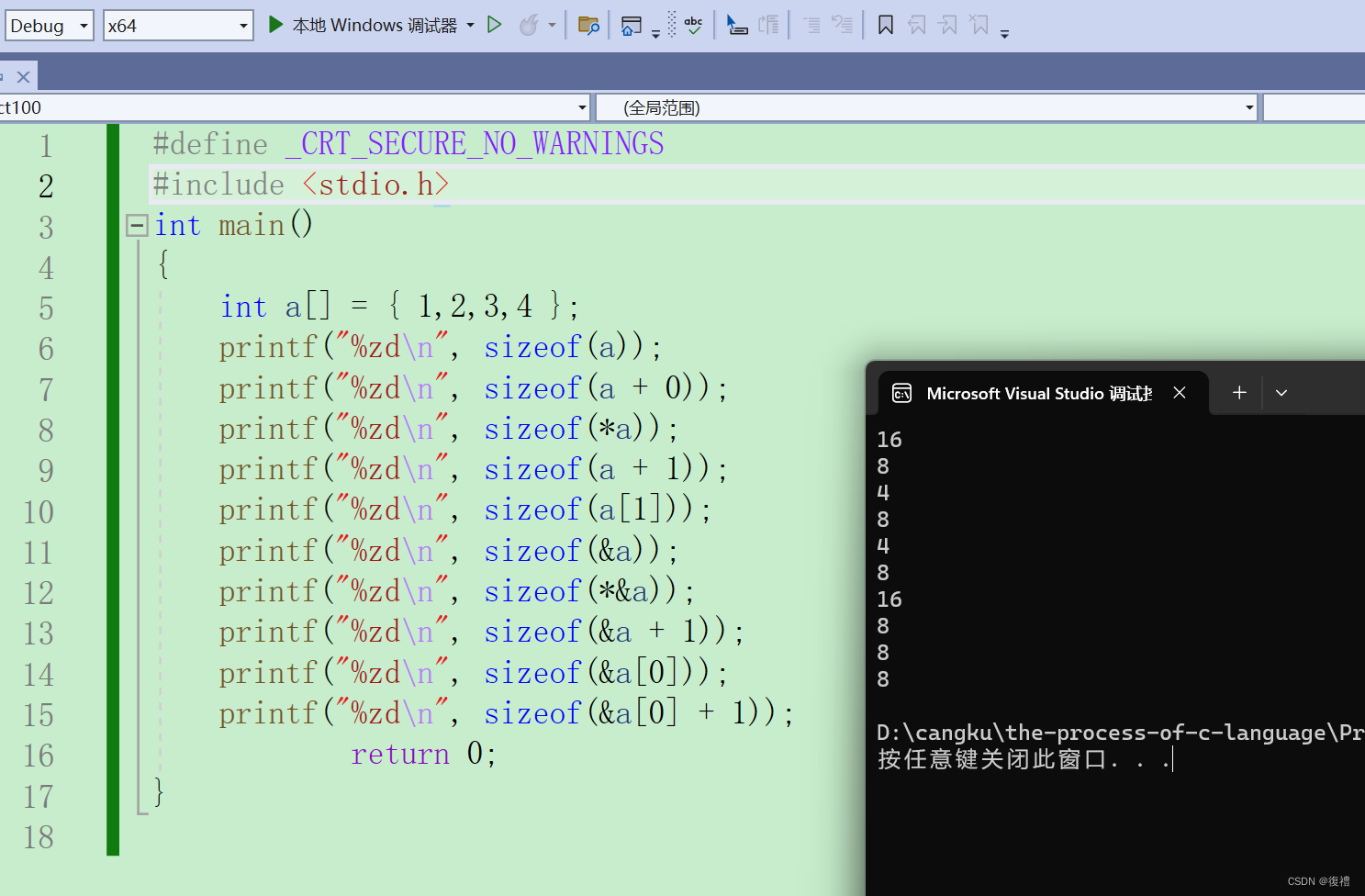
C语言:数组和指针笔试题解析(包括一些容易混淆的指针题目)
Redis 内存回收
【SpringBoot系列】微服务远程调用Open Feign深度学习
C语言,C++编程软件比较(推荐的编程软件)
操作符详解(C语言基础深入解析)
SpringCloud&Eureka理论与入门
一文解读:阿里云AI基础设施的演进与挑战
函数递归深入解析(C语言)
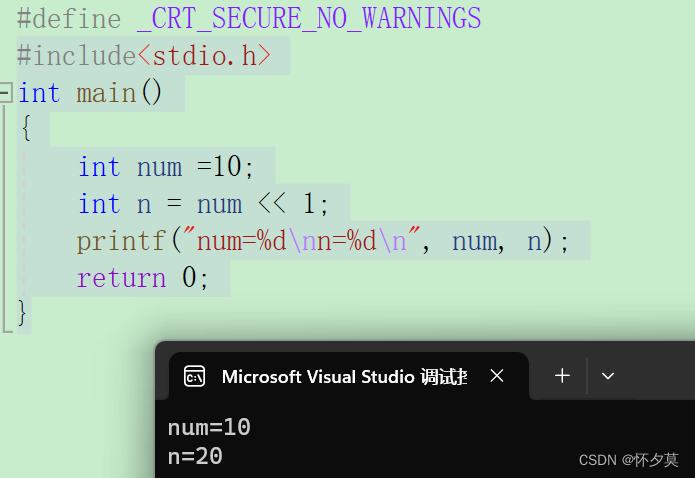
调试技巧vs2022
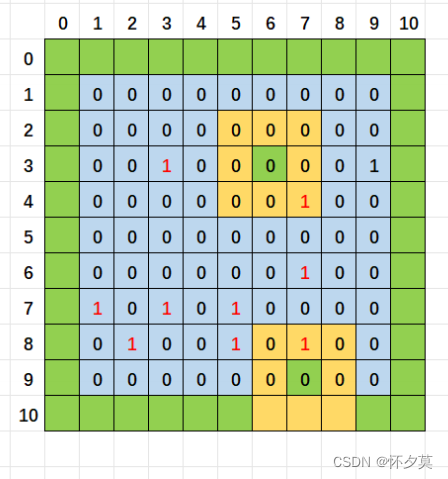
扫雷游戏的实现
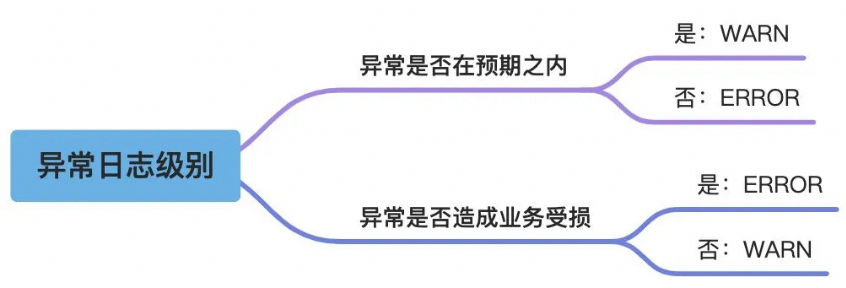
实战总结|系统日志规范及最佳实践
猜数字游戏
函数深入解析(C语言基础入门)
MySQL 锁
数组深入剖析(C语言基础入门)
ES 查看索引的属性的http请求
循坏语句解析(C语言零基础教程)
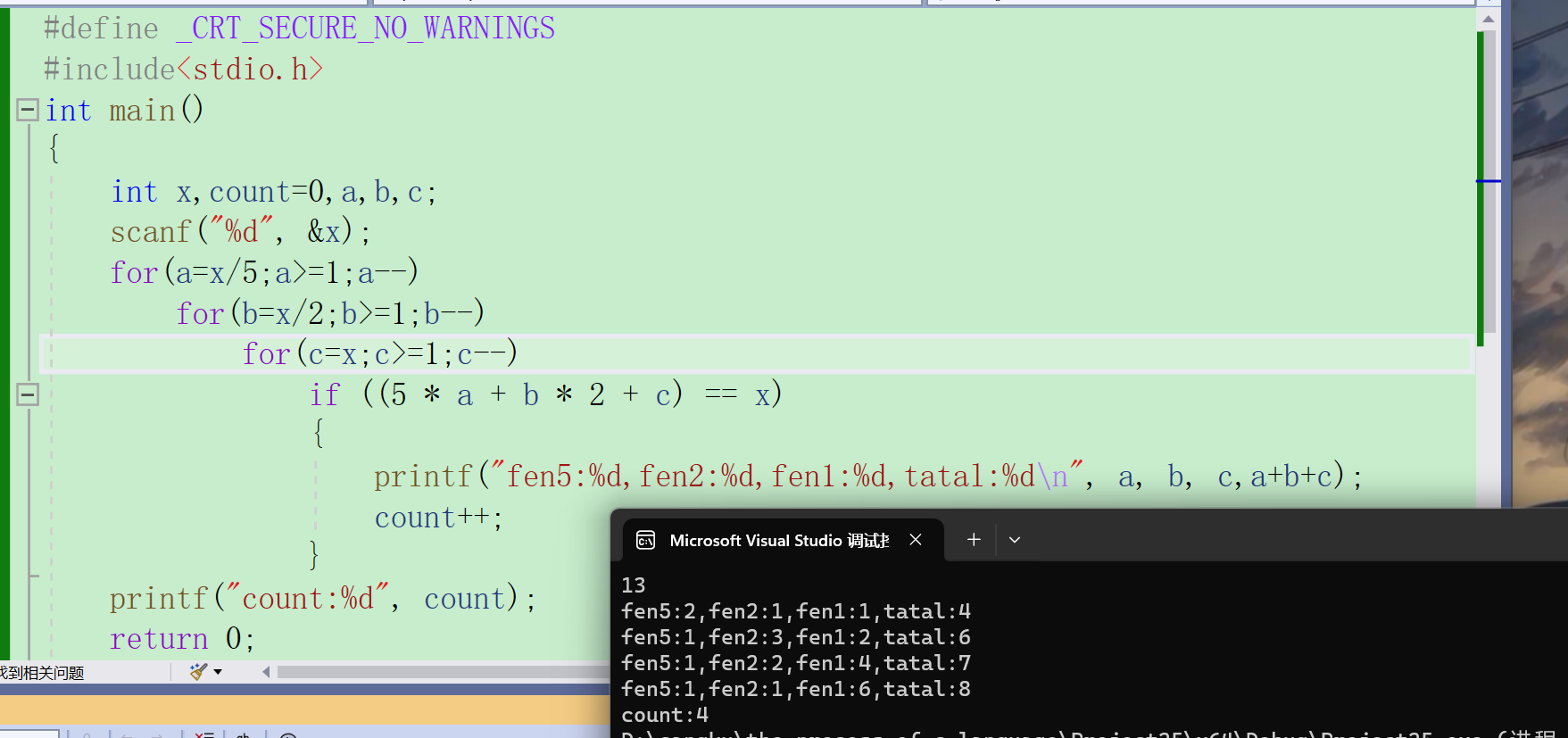
换硬币问题(C语言代码练习)
switch语句
深入理解PHP7的返回类型声明
条件操作符和逻辑操作符(C语言零基础教程)
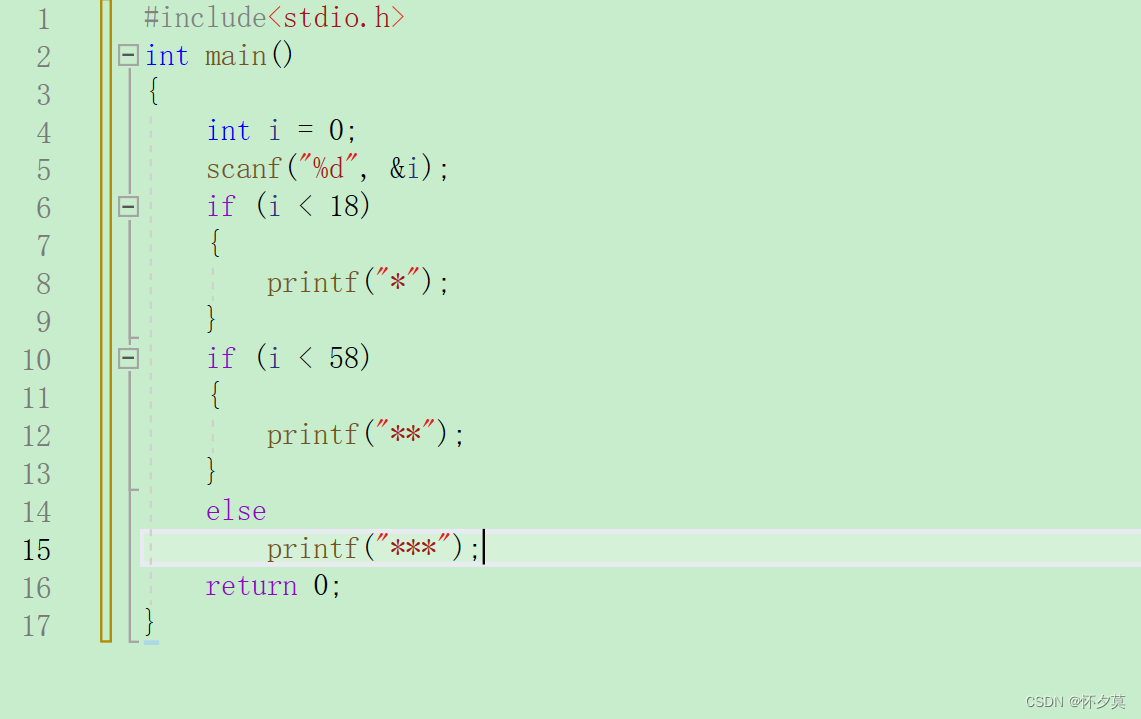
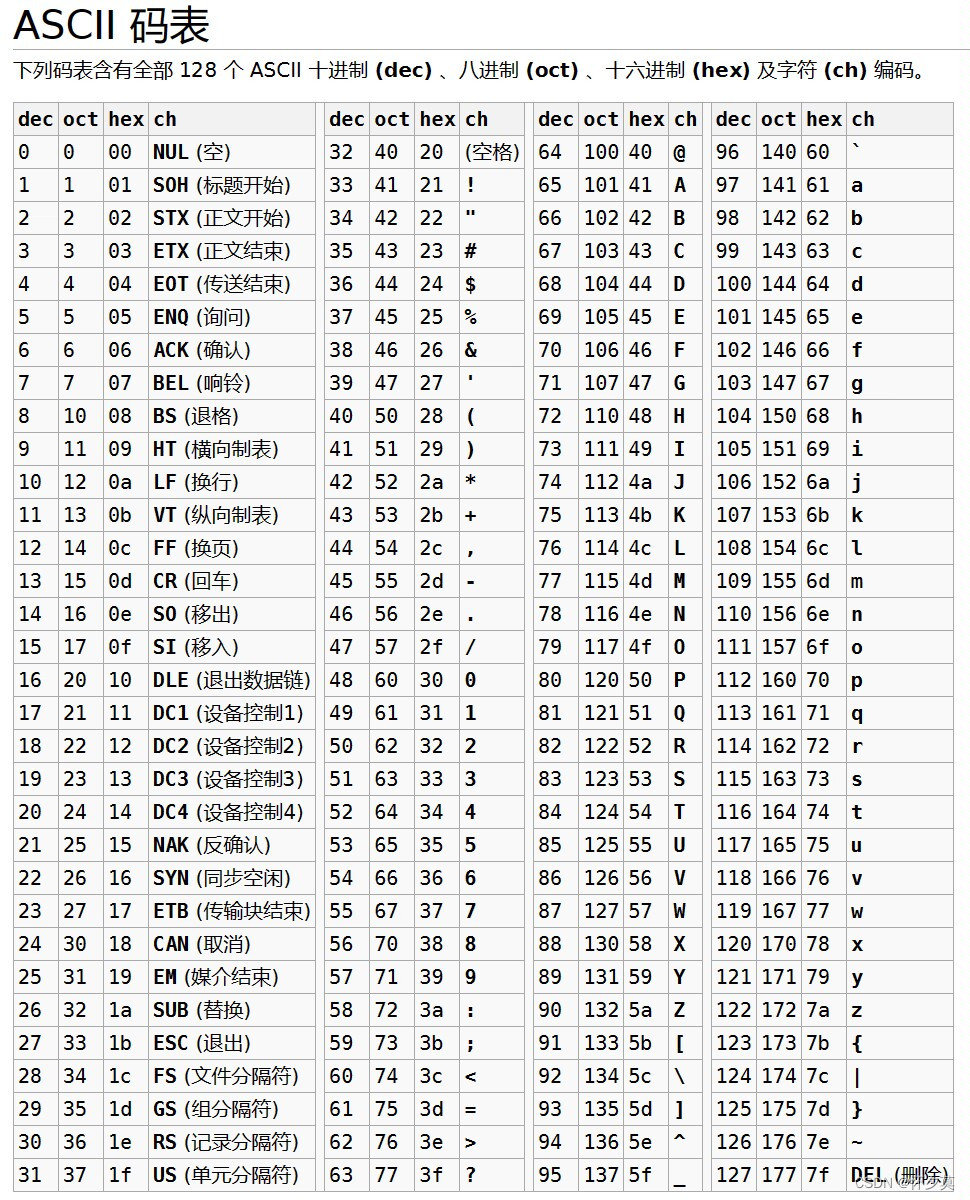
if语句的应用(C语言零基础教程)
C语言数据类型和变量(C语言零基础教程)
图片大搜罗:PHP下载器带你畅游Twitter图像海洋
c语言概念
MySQL SQL优化
数据库期末考试基础——数据库系统概述
【算法】15. 三数之和(多语言实现)
数据结构中顺序栈的进栈和出栈用C语言表示
线性表、链表、栈和队列的初始化
MySQL 索引
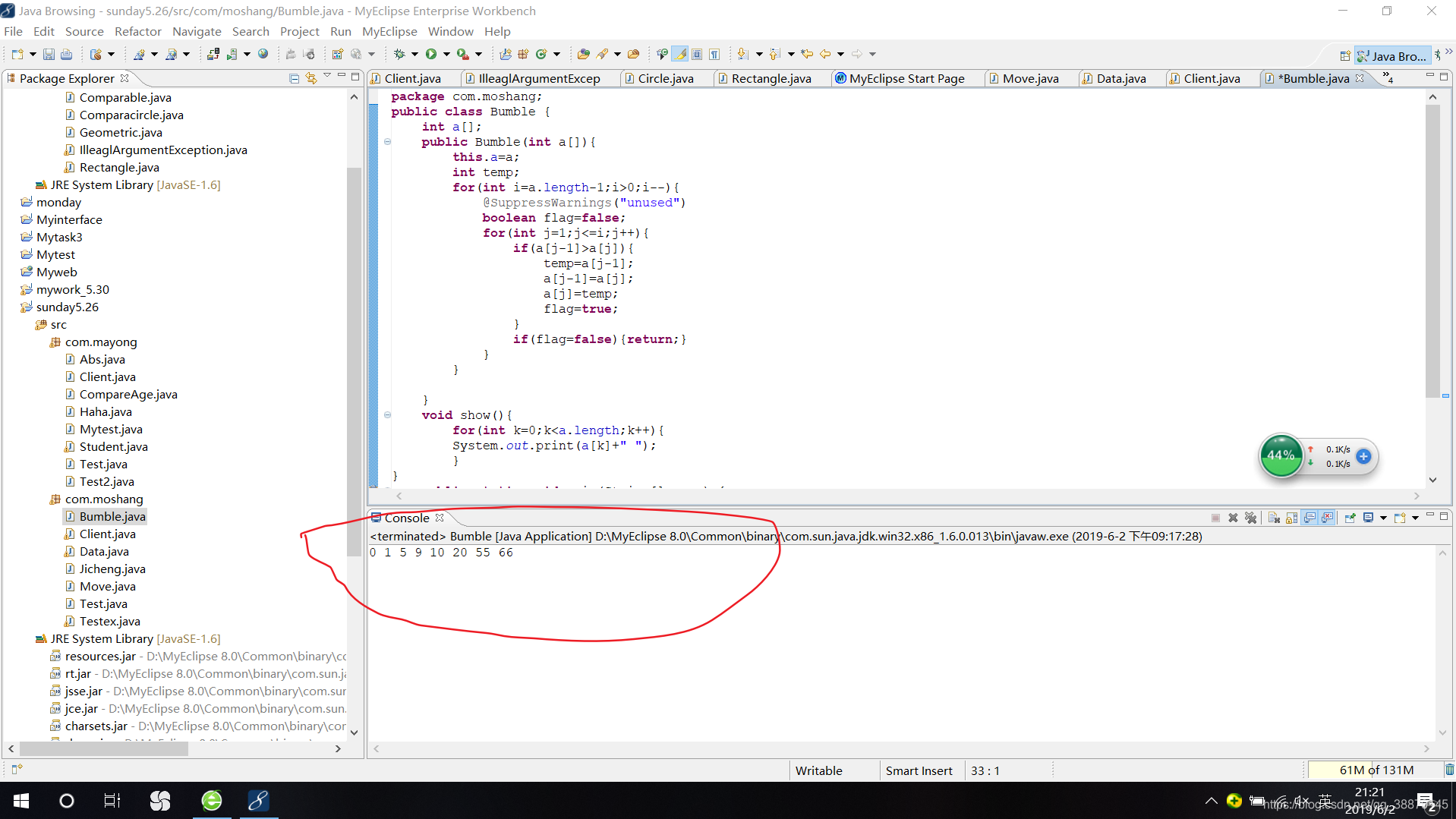
wtf?java的冒泡排序还可以这样写
每天解析一个脚本(37)
构建高效微服务架构:后端开发的新范式
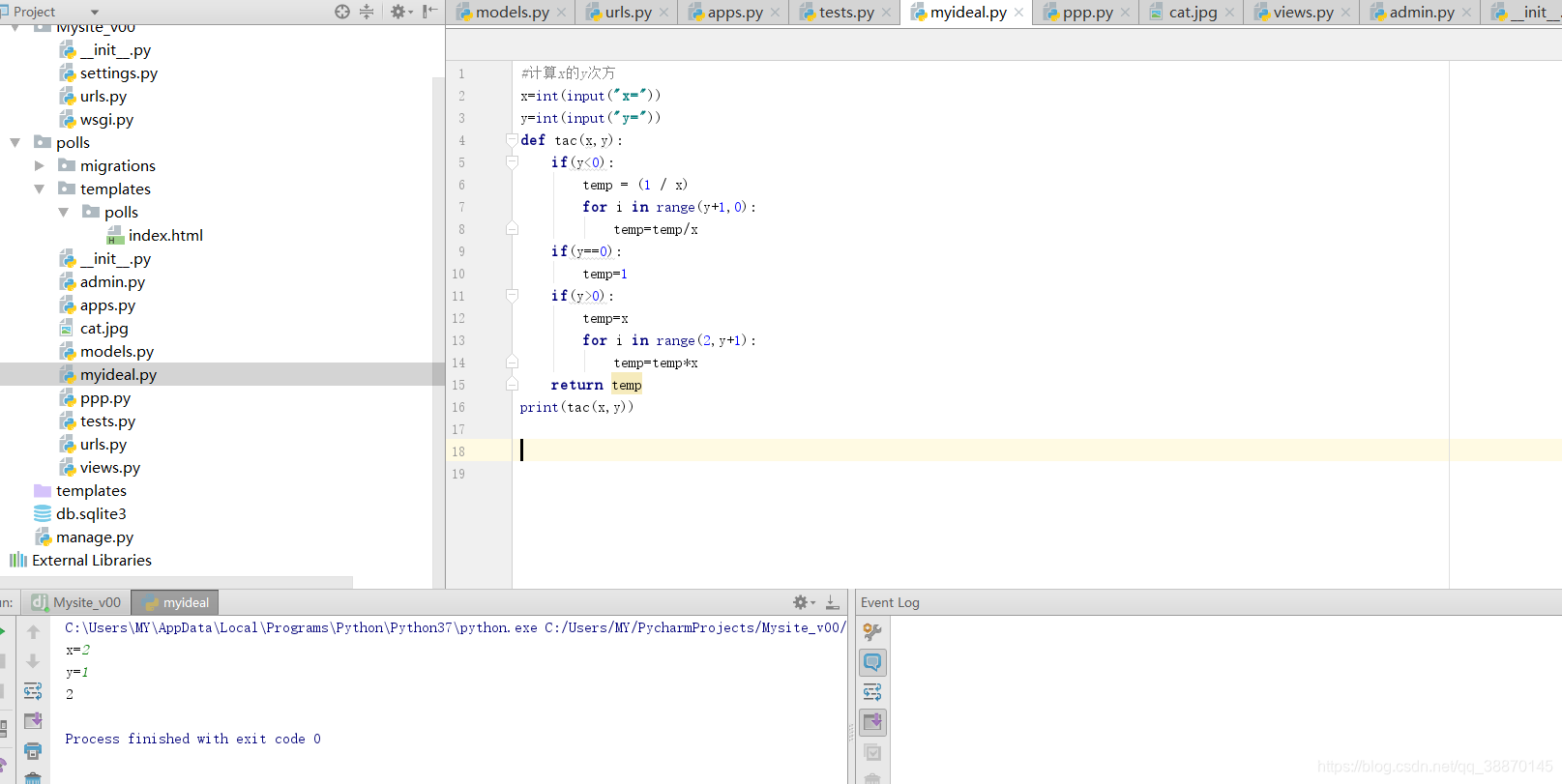
python幂运算——计算x的y次方
构建高效可靠的微服务架构:策略与实践
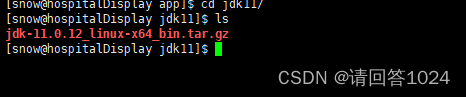
Linux环境安装配置JDK11
什么是比较好的低代码产品?
深入理解PHP7中的返回类型声明
python入门指南
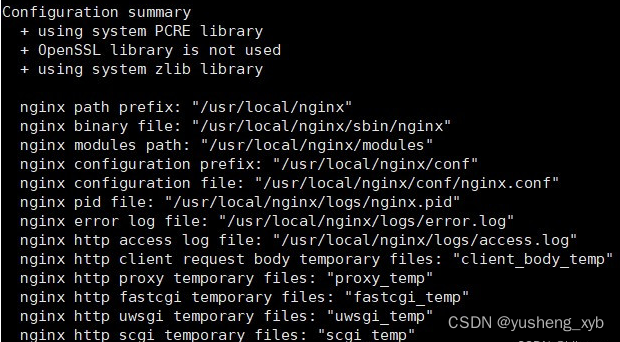
nginx安装在linux上