关于Flume,官方定义如下:
Apache Flume is a distributed, reliable, and available system for efficiently collecting, aggregating and moving large amounts of log data from many different sources to a centralized data store.
The use of Apache Flume is not only restricted to log data aggregation. Since data sources are customizable, Flume can be used to transport massive quantities of event data including but not limited to network traffic data, social-media-generated data, email messages and pretty much any data source possible.
Flume是分布式海量日志收集工具,根据不同的数据来源,Flume并不局限于对日志的收集。
flume有如下特性:
-
内置对多种source和目标类型的支持
-
支持水平扩展
-
支持多种传输方式,例如:multi-hop flows, fan-in fan-out flows, ****...
-
支持contextual routing
-
支持拦截器
-
可靠传递。在flume中每个事件有两个事务,分别在send和receive阶段。 sender发送事件给receiver。接收到数据后,receiver提交自己的事务并发送一个成功信号给sender。sender收到该信号后提交自己的事务。
话说Flume最初是为了从多个web服务把数据流复制到HDFS而设计的,那为什么不直接用put把数据放到HDFS? 假如我们有对快速增长的数据进行实时分析的需求,put过来的数据已经不是实时的了。
同样的,rsync、scp这样的工具也是一样的道理,并不适合实时分析的场景。
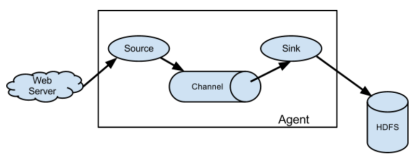
下图是比较常见的部署方式,以此说明Flume的相关概念:
+--------------------------------------------+ | | | +---------------+ | | | | | +----------> | agent1 +-------------+ | | | | | | | | | +---------------+ | | | | | | +---------+----+ | +---------------+ +-------v-------+ | +--------------+| | | | | | | | | | | generators +-----> | agent2 +---> | collector +------> | centrialized || | | | | | | | | store | +---------+----+ | +---------------+ +-------^-------+ | +--------------+ | | | | | | +---------------+ | | | | | | | | +----------> | agent3 +-------------+ | | | | | | +---------------+ | | | +--------------------------------------------+
图中data generator为数据源,它可以是一个接口、队列、文件等。
Flume的agent做为一个独立的进程,从数据源收集数据。
后面的collector事实上也是一个agent,只是将前面agent的输出做为数据源,并对数据进行聚合,最后发送到一个中心存储,比如HDFS。
event在Flume中是数据传输的基本单位,由header和byte payload组成,agent之间传递的就是一个个event。
一个agent包含3个组件,分别为source、channel、sink,一个agent可以有多个source、sink、channel:
+----------+| source | +-------+--+ | +--v----+ | C | | H | | A | | N | | N | | E | | L | +-----+-+ | +--v-----+ | sink | +--------+
-
Source: 用于从数据源接收数据,并将数据传给至少一个channel。Flume支持多种source类型。
-
Channel: 可以把channel理解为一个buffer,或者也可以把channel理解为source和sink之间的一座桥。channel也有多种类型,例如JDBC、file、memory...
-
Sink: sink从channel获取数据并发送到目标,目标也可以是一个agent。
通常来说,source,channel,sink可以满足大多数需求,此外还有一些组件用于应付特殊场景。
-
Interceptor: 可以在source和channel之间进行拦截。
-
Selector: 当一个source关联了两个channel,同一份event应该同时发给两个channel,还是有针对性的发给其中一个channel,selector可以做到这一点。
-
Sink Processor: 当配置了一个sink group,我们可以用sink processor进行故障转移和负载均衡。
基本用法
安装没什么特别的操作,参考:
cd /usr/local wget http://www-us.apache.org/dist/flume/1.7.0/apache-flume-1.7.0-bin.tar.gztar xzvf apache-flume-1.7.0-bin.tar.gz mv apache-flume-1.7.0-bin flume cd flume cp flume-conf.properties.template flume-conf.properties cp flume-env.sh.template flume-env.sh
如果已经安装过Java则再好不过,但要记得export JAVA_HOME:
export JAVA_HOME=/usr/local/jdk1.7.0_75
Flume的配置会根据source和sink的类型会稍有不同,总体而言,无非以下几项:
-
为agent和其各个组件命名
-
配置source
-
配置sink
-
配置channel
-
给channel绑定source和sink
下面是Flume支持的source、channel、sink类型:
| source | channel | sink |
|---|---|---|
| Avro Source | Memory Channel | HDFS Sink |
| Thrift Source | JDBC Channel | Hive Sink |
| Exec Source | Kafka Channel | Logger Sink |
| JMS Source | File Channel | Avro Sink |
| Spooling Directory Source | Spillable Memory Channel | Thrift Sink |
| Twitter 1% firehose Source | Pseudo Transaction Channel | IRC Sink |
| Kafka Source | File Roll Sink | |
| NetCat Source | Null Sink | |
| Sequence Generator Source | HBaseSink | |
| Syslog Sources | AsyncHBaseSink | |
| Syslog TCP Source | MorphlineSolrSink | |
| Multiport Syslog TCP Source | ElasticSearchSink | |
| Syslog UDP Source | Kite Dataset Sink | |
| HTTP Source | Kafka Sink | |
| Stress Source | ||
| Legacy Sources | ||
| Thrift Legacy Source | ||
| Custom Source | ||
| Scribe Source |
不同的类型可能会有一些特殊的选项,比如Kafka Source需要指定broker地址、topics等。
这里找一个易上手的source类型,运行看看效果。
以netcat为例,在conf中加入netcat2logger.conf,内容如下:
# namingnc.sources = s_netcat nc.channels = c_mem nc.sinks = k_logger# sourcenc.sources.s_netcat.type = netcat nc.sources.s_netcat.bind = localhost nc.sources.s_netcat.port = 6666# sinknc.sinks.k_logger.type = logger# channelnc.channels.c_mem.type = memory nc.channels.c_mem.capacity = 1000nc.channels.c_mem.transactionCapacity = 100# bindnc.sources.s_netcat.channels = c_mem nc.sinks.k_logger.channel = c_mem
启动flume-ng,参考:
bin/flume-ng agent -n nc -f conf/netcat2logger.conf -Dflume.root.logger=INFO,console
打开telnet,试试输入一些内容:
curl telnet://localhost:6666
上面的例子比较容易上手,但看起来并没有什么用处。
下面再贴出一个比较有用例子,假如我有多个nginx实例在分别不同的机器上,我打算把access log的内容实时传给Kafka。
这样我可以给每台机器配置一个agent,并且将本地日志文件作为source,Kafka作为sink。
配置参考:
t2k.sources=s1 t2k.channels=c1 t2k.sinks=k1 t2k.sources.s1.type=exect2k.sources.s1.command=tail -f /usr/local/openresty/nginx/logs/access.logt2k.channels.c1.type=memory t2k.channels.c1.capacity=10000t2k.channels.c1.transactionCapacity=1000t2k.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink t2k.sinks.k1.kafka.topic=my-topic t2k.sinks.k1.kafka.bootstrap.servers=localhost:9092t2k.sinks.k1.flumeBatchSize=20t2k.sources.s1.channels=c1 t2k.sinks.k1.channel=c1
启动命令参考:
bin/flume-ng agent -n t2k -f conf/tail2Kafka.conf
Flow与Selector
"在一个agent中定义flow",换句话说就是"将source和sink用channel连接起来"。
所以说,虽然在上面的例子中没有做flow相关的配置,但事实上我们用的是default flow。
Flow表达的是event的流向,例如:
-
从一个source流向多个agent,agent的sink各不相同。
-
从一个agent流向另一个agent。
-
从一个source流向多个channel,e.g. fanout、fanin...
这里我们以fanout为例,从一个source流向多个channel。
但是需要考虑一个问题,这几个channel应该作为worker分摊从同一个source过来的event,还是说作为subscriber监听到相同的event?
这就需要用到另外一个概念——selector
所以,selector只有两种类型:
-
multiplexer
-
replicating(default)
两种类型的功能顾名思义,下面举例说明一下。
假设我对一个source配置了replicating selector,该source关联了两个channel,两个channel分别关联两个sink,两个sink输出到不同的目标。
但这样做的效果并不明显,从结果来看,和将两个sink关联到同一个channel没什么区别。
所以我需要一个机制让来自同一个source的event分开流向不同的channel,但这里就需要考虑一个问题——根据什么决定event的流向?
答案是根据header中的属性,为channel设置相关属性值,匹配则流向对应的channel。
参考格式如下:
<Agent>.sources.<Source1>.selector.type = multiplexing<Agent>.sources.<Source1>.selector.header = <someHeader><Agent>.sources.<Source1>.selector.mapping.<Value1> = <Channel1><Agent>.sources.<Source1>.selector.mapping.<Value2> = <Channel1> <Channel2><Agent>.sources.<Source1>.selector.mapping.<Value3> = <Channel2><Agent>.sources.<Source1>.selector.default = <Channel2>
所谓optional,就是说selector先试图写到相关的channel,如果事务失败则写入optional channel,如果optional也失败,则忽略。
下面继续用http source写一个例子,根据header流向两个不同的channel,两个channel分别对应两个file sink。
http2logger.conf,参考如下:
HttpAgent.sources = HttpSource HttpAgent.channels = AChannel BChannel HttpAgent.sinks = ASink BSink HttpAgent.sources.HttpSource.type = http HttpAgent.sources.HttpSource.port = 6666HttpAgent.sources.HttpSource.selector.type = multiplexing HttpAgent.sources.HttpSource.selector.header = Host HttpAgent.sources.HttpSource.selector.mapping.A = AChannel HttpAgent.sources.HttpSource.selector.mapping.B = BChannel HttpAgent.sources.HttpSource.selector.mapping.C = AChannel BChannel HttpAgent.sources.HttpSource.channels = AChannel BChannel HttpAgent.channels.AChannel.type = memory HttpAgent.channels.BChannel.type = memory HttpAgent.sinks.ASink.type = logger HttpAgent.sinks.ASink.channel = AChannel HttpAgent.sinks.BSink.type = file_roll HttpAgent.sinks.BSink.channel = BChannel HttpAgent.sinks.BSink.sink.directory = /var/b
启动:
bin/flume-ng agent -n HttpAgent --conf conf -f conf/http2logger.conf -Dflume.root.logger=INFO,console
测试:
curl -X post localhost:6666 -d '[{"headers": {"Host": "A"}, "body": "this is for A"}]'curl -X post localhost:6666 -d '[{"headers": {"Host": "B"}, "body": "this is for B"}]'curl -X post localhost:6666 -d '[{"headers": {"Host": "C"}, "body": "this is for C"}]'
Interceptor
假如我希望event header的符合某个条件时丢弃该event,可能我还需要设置一个selector,并让该event流向一个null sink?
甚至,如果想修改某个event...这时需要用到interceptor。
Flume为我们提供了几种常见的interceptor实现,不同的interceptor会有一些额外的参数,如下:
| implement | desc |
|---|---|
| Timestamp Interceptor | 将timestamp写入header |
| Host Interceptor | 将ip地址或host写入header |
| Static Interceptor | 定义一个常量写入header |
| UUID Interceptor | 将UUID写入header |
| Morphline Interceptor | 根据声明的morphline配置文件进行基本的ETL |
| Search and Replace Interceptor | 根据声明的regex替换内容 |
| Regex Filtering Interceptor | 根据声明的regex过滤event |
| Regex Extractor Interceptor | 将匹配regex的group写入header |
配置interceptor和配置channel一样,多个interceptor需要用空格隔开。
但需要注意,interceptor的声明顺序即执行顺序。
比如配置一个HostInterceptor,参考:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.HostInterceptor$Buildera1.sources.r1.interceptors.i1.preserveExisting = false
a1.sources.r1.interceptors.i1.hostHeader = hostname
a1.sources.r1.interceptors.i2.type = org.apache.flume.interceptor.TimestampInterceptor$Buildera1.sinks.k1.filePrefix = FlumeData.%{CollectorHost}.%Y-%m-%da1.sinks.k1.channel = c1
虽然Flume提供了几种Interceptor实现,但偶尔也需要根据自己的需求实现,接口为org.apache.flume.interceptor.Interceptor。
依赖:compile group: 'org.apache.flume', name: 'flume-ng-core', version: '1.7.0'
这里写一个没什么用的例子,但可以说明相关方法和读取选项的问题:
package com.kavlez.flume.interceptor;import org.apache.flume.Context;import org.apache.flume.Event;import org.apache.flume.interceptor.Interceptor;import java.util.List;public class IllusionInterceptor implements Interceptor{
public static class Builder implements Interceptor.Builder{
private boolean isAllIllusion = false; @Override
public Interceptor build() { return new IllusionInterceptor(isAllIllusion);
} @Override
public void configure(Context context) { this.isAllIllusion = context.getBoolean("illusion");
}
} private boolean isAllIllusion; public IllusionInterceptor(boolean isAllIllusion) { this.isAllIllusion = isAllIllusion;
} @Override
public void initialize() {
} @Override
public Event intercept(Event event) { byte[] modifiedEvent = "Everything is an Illusion".getBytes();
event.setBody(modifiedEvent); return event;
} @Override
public List<Event> intercept(List<Event> list) { for (Event event : list) { this.intercept(event);
} return list;
} @Override
public void close() {
}
}
编译后的jar需要放到/path/to/flume/lib/.下即可。
本文转自zsdnr 51CTO博客,原文链接:http://blog.51cto.com/12942149/1929388,如需转载请自行联系原作者