1、子查询
1.1、子查询简介
子查询是一个嵌套在 SELECT、INSERT、UPDATE 或 DELETE 语句或其他子查询中的查询。任何允许使用表达式的地方都可以使用子查询,换句话说,子查询几乎可以出现在一条 SQL 语句的任意位置上,且必须用一对小括号来包裹子查询的定义。本系列博客的第 12 篇的 4.2 节已经演示了常见的三种子查询写法。子查询也称为内部查询或内部选择,而包含子查询的语句也称为外部查询或外部选择。
本人查阅了大量资料,似乎根本就找不到一种“正确的子查询分类方法”。常见的分类名有:单行子查询、多行子查询、多列子查询、相关子查询、标量子查询、内联视图等,前三个顾名思义,后三个分别简要说明如下:
-
相关子查询:子查询引用了外部查询中包含的一列或多列,也就是说内部查询得依靠外部查询获得值,这样的子查询被称为相关子查询,也称为重复子查询。
-
标量子查询:只返回单一值的子查询称为标量子查询。
-
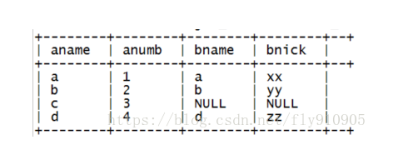
内联视图:一般是指写在 FROM 子句后面的子查询,它本质上是视图,也称内嵌视图,与标准视图的区别主要是无需事先编写创建视图的语句,便于执行查询。
下面我再补充几个 WHERE 子句带子查询的示例:
-- 查询低收入员工的姓名和生日SELECT t.staff_name,t.birthday FROM demo.t_staff t WHERE EXISTS(SELECT 1 FROM demo.t_staff_low n WHERE n.staff_id=t.staff_id);-- 查询岗位工资最高的员工的姓名和生日SELECT t.staff_name,t.birthday FROM demo.t_staff t WHERE t.post_salary = (SELECT MAX(n.post_salary) FROM demo.t_staff n);-- 查询岗位工资高于任何一个部门平均工资的员工姓名和生日SELECT t.staff_name,t.birthday FROM demo.t_staff t WHERE t.post_salary > ALL(SELECT AVG(n.post_salary) FROM demo.t_staff n GROUP BY n.dept_code);-- 查询测试部所有女生的姓名和生日(一般没人这么写,只为演示)SELECT t.staff_name,t.birthday FROM demo.t_staff t WHERE (t.dept_code,t.gender) = (SELECT '010104',0 FROM DUAL);-- 查询任何低收入部门的女生的姓名和生日SELECT t.staff_name,t.birthday FROM demo.t_staff t WHERE (t.dept_code,t.gender) = ANY(SELECT n.dept_code,0 FROM demo.t_staff_low n);-- 查询部门平均岗位工资高于公司平均岗位工资的部门人数和平均岗位工资SELECT t.dept_code,COUNT(1) count_staff,AVG(t.post_salary) avg_salary FROM demo.t_staff t GROUP BY t.dept_code HAVING AVG(t.post_salary)>(SELECT AVG(n.post_salary) FROM demo.t_staff n) ORDER BY t.dept_code;
1.2、WITH 子查询
WITH 子查询的作用类似于内联视图,包括内联视图在内的其它子查询都只能够引用一次;而 WITH 子查询需要在引用之前先定义,一旦定义了在整个查询的后续部分就可以按名称来反复引用,从这点来看又很像临时表。Oracle 从 11g R2 开始支持递归的 WITH,即允许在 WITH 子查询的定义中对自身引用,而其它数据库,如 SQL Server、PostgreSQL、DB2 等都先于 Oracle 支持这一特性。语法示例:
WITH query_name AS(SELECT ...)SELECT ...
案例一:查询年龄在25岁及以下,固定工资在5000及以上的员工基本信息。示例:
WITH t AS( SELECT t1.staff_name,t2.enum_name dept_name,DECODE(t1.gender,1,'男',0,'女','未知') gender, EXTRACT(YEAR FROM fn_now)-EXTRACT(YEAR FROM t1.birthday) age,base_salary+post_salary fixed_salary FROM demo.t_staff t1 LEFT JOIN demo.t_field_enum t2 ON t1.dept_code=t2.enum_code AND t2.field_code='DEPT' WHERE t1.is_disabled=0) SELECT t.dept_name,t.staff_name,t.gender,t.age,t.fixed_salary FROM t WHERE t.age<=25 AND t.fixed_salary>=5000
结果:
DEPT_NAME STAFF_NAME GENDER AGE FIXED_SALARY ------------------------------------ ----------------------------------- ------ ---------- ------------ 研发一部 大国 男 25 6500 研发三部 小玲 女 23 5400 研发三部 韩三 男 24 7550 测试部 小燕 女 25 5600
案例二:统计个个部门的人数、总工资、平均工资、最高工资、最低工资。示例:
WITH t1 AS (SELECT n.dept_code FROM demo.t_staff n GROUP BY n.dept_code), t2 AS (SELECT n.enum_code dept_code,n.enum_name dept_name FROM demo.t_field_enum n WHERE n.field_code='DEPT'), t3 AS (SELECT t.dept_code,COUNT(1) count_staff FROM demo.t_staff_salary t GROUP BY t.dept_code), t4 AS (SELECT t.dept_code,SUM(t.fixed_salary) sum_salary FROM demo.t_staff_salary t GROUP BY t.dept_code), t5 AS (SELECT t.dept_code,AVG(t.fixed_salary) avg_salary FROM demo.t_staff_salary t GROUP BY t.dept_code), t6 AS (SELECT t.dept_code,MAX(t.fixed_salary) max_salary FROM demo.t_staff_salary t GROUP BY t.dept_code), t7 AS (SELECT t.dept_code,MIN(t.fixed_salary) min_salary FROM demo.t_staff_salary t GROUP BY t.dept_code)SELECT t2.dept_name,t3.count_staff,t4.sum_salary,t5.avg_salary,t6.max_salary,t7.min_salaryFROM t1,t2,t3,t4,t5,t6,t7WHERE t1.dept_code=t2.dept_code AND t1.dept_code=t3.dept_code AND t1.dept_code=t4.dept_code AND t1.dept_code=t5.dept_code AND t1.dept_code=t6.dept_code AND t1.dept_code=t7.dept_codeORDER BY t1.dept_code;
结果:
DEPT_NAME COUNT_STAFF SUM_SALARY AVG_SALARY MAX_SALARY MIN_SALARY-------------------------------------------------- ----------- ---------- ---------- ---------- ----------研发一部 4 36002 9000.5 10501 6500 研发二部 2 18500 9250 10000 8500 研发三部 2 12950 6475 7550 5400 测试部 2 12700 6350 7100 5600 实施一部 3 18700 6233.33333 8500 5100 实施二部 2 15700 7850 8000 7700
案例二不使用 WITH 的示例:
SELECT t2.enum_name dept_name,t3.count_staff,t4.sum_salary,t5.avg_salary,t6.max_salary,t7.min_salaryFROM(SELECT n.dept_code FROM demo.t_staff n GROUP BY n.dept_code) t1LEFT JOIN demo.t_field_enum t2 ON t1.dept_code=t2.enum_code AND t2.field_code='DEPT'LEFT JOIN(SELECT t.dept_code,COUNT(1) count_staff FROM demo.t_staff_salary t GROUP BY t.dept_code) t3 ON t1.dept_code=t3.dept_codeLEFT JOIN(SELECT t.dept_code,SUM(t.fixed_salary) sum_salary FROM demo.t_staff_salary t GROUP BY t.dept_code) t4 ON t1.dept_code=t4.dept_codeLEFT JOIN(SELECT t.dept_code,AVG(t.fixed_salary) avg_salary FROM demo.t_staff_salary t GROUP BY t.dept_code) t5 ON t1.dept_code=t5.dept_codeLEFT JOIN(SELECT t.dept_code,MAX(t.fixed_salary) max_salary FROM demo.t_staff_salary t GROUP BY t.dept_code) t6 ON t1.dept_code=t6.dept_codeLEFT JOIN(SELECT t.dept_code,MIN(t.fixed_salary) min_salary FROM demo.t_staff_salary t GROUP BY t.dept_code) t7 ON t1.dept_code=t7.dept_codeORDER BY t1.dept_code;
2、集合查询
在数学中可以对集合做交并差运算,在 SQL 中同样可以对查询结果集做交并差操作。这三种 SQL 集合查询对应的操作符关键字分别是 INTERSECT、UNION/UNION ALL、MINUS。
2.1、UNION 和 UNION ALL
最常见的 SQL 集合查询就是并集查询,并集查询操作符有 UNION 和 UNION ALL 两个,用法完全一致。示例:
-- 查询本科学历的女生和 93 后的员工SELECT t1.staff_name,t1.gender,t1.edu_bg,t1.birthday FROM demo.t_staff t1 WHERE t1.gender=0 AND t1.edu_bg=1UNION ALLSELECT t2.staff_name,t2.gender,t2.edu_bg,t2.birthday FROM demo.t_staff t2 WHERE t2.birthday>=TO_DATE('1993-01-01','yyyy-mm-dd');
结果:
STAFF_NAME GENDER EDU_BG BIRTHDAY -------------------------------------------------- ------ ------ ----------- 小玲 0 1 1994-06-17 韩三 1 1 1993-08-18 小玲 0 1 1994-06-17
从 UNION 和 UNION ALL 的查询结果来看,它们的区别之一就是:UNION 会去除重复行,而 UNION ALL 会保留重复行,如果把上例中的 ALL 关键字去掉,第 1、3 行中就会有 1 行被当作重复行去除;区别之二就是:结果集默认的排序不同,UNION ALL 只是按关联次序来组织数据,不再排序,而 UNION 将会按默认规则对整个数据集进行排序。另外,UNION ALL 的运算效率比 UNION 要高,故此,UNION ALL 也相对常用一些。
2.2、MINUS
可通过 MINUS 操作符求两个结果集的差集。差集结果集不包括重复行,且会按默认规则排序。示例:
-- 查询 demo.t_staff 表中有而 demo.t_staff_copy 表中没有的员工SELECT t1.staff_name,t1.gender,t1.birthday FROM demo.t_staff t1MINUSSELECT t2.staff_name,t2.gender,t2.birthday FROM demo.t_staff_copy t2;
结果:
STAFF_NAME GENDER BIRTHDAY -------------------------------------------------- ------ ----------- 大国 1 1992-01-15 李阳 1 1989-01-14 徐来 1 1991-04-01
2.3、INTERSECT
可通过 INTERSECT 操作符求两个结果集的交集。交集结果集不包括重复行,且会按默认规则排序。示例:
-- 查询年轻人中的低收入者SELECT t1.staff_name,t1.gender,t1.dept_code FROM demo.t_staff_young t1INTERSECTSELECT t2.staff_name,t2.gender,t2.dept_code FROM demo.t_staff_low t2;
结果:
STAFF_NAME GENDER DEPT_CODE -------------------------------------------------- ------ -------------------- 王二 1 010101 小红 0 010201
2.4、集合运算与 ORDER BY
无论是交并差中的那种集合查询,只需要在最后一个查询的后面加上 ORDER BY 子句,即可对整个结果集排序。示例:
SELECT t1.staff_name,t1.gender,t1.dept_code FROM demo.t_staff t1 WHERE t1.gender=0 AND ROWNUM <= 1UNION ALLSELECT t2.staff_name,t2.gender,t2.dept_code FROM demo.t_staff_young t2 WHERE ROWNUM <= 1UNION ALLSELECT t3.staff_name,t3.gender,t3.dept_code FROM demo.t_staff_low t3 WHERE t3.gender=0ORDER BY dept_code;
结果:
STAFF_NAME GENDER DEPT_CODE -------------------------------------------------- ------ -------------------------------------------------- 小强 1 010101 小玲 0 010103 小红 0 010201
有个需要注意的细节问题是:这个 ORDER BY 后的排序字段不能加任何别名限定,这个也好理解,毕竟排序操作是针对整个结果集的。也就是说上例中 ORDER BY 后的 dept_code 不属于 t1、t2、t3 中任何一个表,而是整个结果集的。那万一 t1、t2、t3 表中的字段名不相同的话,排序的字段名又改如何确定呢?本人的测试结果是:它一定是第 1 个查询里的字段名或列别名,但前提是后面所有查询的该列都是真实字段名,或列别名与第 1 个查询里的字段名或列别名相同,NULL 除外。如果你嫌这个规则太复杂也不好记,那么也可以给所有查询的该列取一个相同的别名。另外还可以利用 ORDER BY 的另一个语法规则:ORDER BY N,即直接写排序字段的列编号。如上例的查询想要根据第 2 列来排序,这一这么来写:
SELECT t1.staff_name,t1.gender,t1.dept_code FROM demo.t_staff t1 WHERE t1.gender=0 AND ROWNUM <= 1UNION ALLSELECT t2.staff_name,t2.gender,t2.dept_code FROM demo.t_staff_young t2 WHERE ROWNUM <= 1UNION ALLSELECT t3.staff_name,t3.gender,t3.dept_code FROM demo.t_staff_low t3 WHERE t3.gender=0ORDER BY 2;
结果:
STAFF_NAME GENDER DEPT_CODE -------------------------------------------------- ------ -------------------------------------------------- 小玲 0 010103 小红 0 010201 小强 1 010101
3、DISTINCT 子句
DISTINCT 子句的作用就是把一组数据中的重复行去掉,留下唯一的数据。
3.1、普通用法
示例:
SELECT DISTINCT t.dept_code FROM demo.t_staff t; -- 查询所有部门,效果同下SELECT t.dept_code FROM demo.t_staff t GROUP BY t.dept_code;
3.2、做聚合函数的参数
COUNT、SUM、MAX、MIN、AVG 五个常见聚合函数内部都支持 DISTINCT。
语法:
SELECT func(DISTINCT field) FROM table [WHERE conditions];
示例一:
-- 统计有女员工的部门数量SELECT COUNT(DISTINCT t.dept_code) count_dept FROM demo.t_staff t WHERE t.gender=0;
示例二:
-- 统计所有员工的平均工资,若有多人工资相同则只统计其中一人的工资SELECT AVG(DISTINCT t.fixed_salary) avg_salary FROM demo.t_staff_salary t;