根据看到的图像来回答问题,需要在图像识别和分类的基础上再进一步,形成对图中物体彼此关系的推理和理解,是机器完成复杂任务所需的一项基本能力,也是视觉研究人员目前正在努力攻克的问题。
最近,在视觉推理任务中,模块化的网络展现出了很高的性能,但它们在可解释性方面还多有欠缺。为了解决这个问题,MIT和普朗克航空系统公司的研究人员合作,围绕视觉注意力机制,提出了一组视觉推理原语(primitives),组合起来后得到的模型,能够以明确可解释的方式,执行复杂的视觉推理任务,在视觉理解数据集CLEVR上达到了99.1%的准确率。
他们将这种设计模型的方法称之为“透明设计”(Transparency-by-Design,TbD),使用这种方法设计出的网络则称为“透明设计网络”(TbD-nets)。
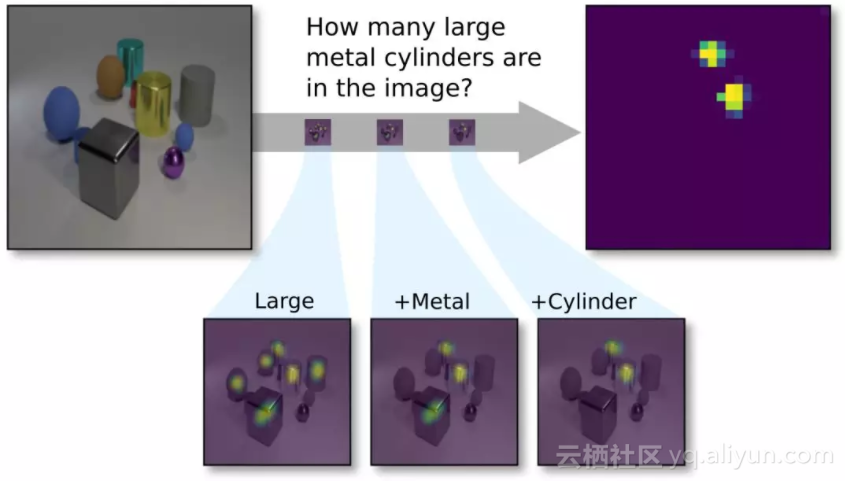
CLEVR视觉问答任务示意:新提出的透明设计网络(TbD-net)组成了一系列的注意力掩码(mask),使其能够正确计数图像中的两个大型(Large)金属(Metal)圆柱体(Cyliner)。
由上可见,模块在输出时,将结果高亮显示,这样人类也能够检查每个模块的中间输出,并且从一个高的层次理解模块的行为,研究人员认为,这样的模型就可以说是“透明”的。他们在论文中写道,这些原语的输出的保真度(fidelity)和可解释性(interpretability),让我们在诊断所得模型的优缺点方面,获得了无与伦比的能力。由此,缩小了现有视觉理解模型在性能和可解释性之间的差距。
他们还表明,当提供给模型的数据集很小,而且其中含有从未见过的新数据时,模型也能很好地学会泛化表示。在CoGenT泛化任务中,得到了比现有最好技术提高了20个百分点的成绩。
相关论文《透明设计:缩小视觉推理中性能和可解释性之间的差距》(Transparency by Design: Closing the Gap Between Performance and Interpretability in Visual Reasoning),已经被CVPR 2018接收。利用开源代码,你也能构建视觉理解模型并在CLEVR数据集上测试,自己问问题,看看模型能否给出正确回答。
论文: https://arxiv.org/abs/1803.05268v1
代码: https://github.com/davidmascharka/tbd-nets
CLEVR:10 万图像+100 万问题,构建视觉理解基准
在介绍成果前,简单介绍一下这项工作的基础——CLEVR数据集。CLEVR是李飞飞领导的斯坦福人工智能实验室和Facebook AI Lab联合提出的一个视觉问题基准,结合语义和推理,测试机器的语言视觉(Language Vision)在语义(Syntax)和推理(Inference)方面的能力。

CLEVR 包含 10 万张经过渲染的图像和大约 100 万个自动生成的问题,其中有 85.3 万个问题是互不相同的,包含了测试计数、比较、逻辑推理和在记忆中存储信息等视觉推理能力的图像和问题。
CoGenT是CLEVR的一个子任务,全称是Compositional Generalization Test,检验模型在测试时识别新组合的属性的能力。
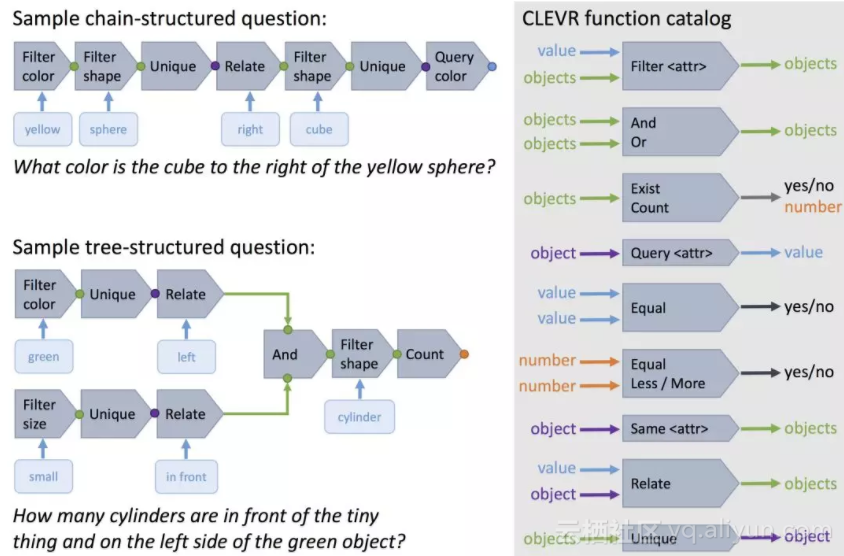
CLEVR中的每个问题都以自然语言和函数编程(functional program)的形式表示,函数编程表示让人能精确确定模型回答每个问题所需的推理技能。
透明设计:围绕注意力机制构建,可解释的视觉推理原语
将一个复杂的推理链分解为一系列较小的子问题,其中每一个子问题都可以独立解决,然后组合起来,这是一种强大而直观的推理手段。像这样的模块化结构还允许在推理过程的每个步骤检查网络的输出,取决于产生可解释输出的模块设计。
受此启发,我们提出一个神经模块网络(neural module network),该网络在图像空间中构建一个注意力机制模型,我们称之为透明设计网络( Transparency by Design network ,TbD-net),因为透明度(Transparency)是我们设计决策的驱动因素。
这个设计决策考虑到一些模块只需要关注图像中某个局部的特征,例如注意力模块(Attention module)只关注不同的对象或特征一样。其他模块则需要在全局环境中执行操作,例如关联模块(Relate modules),它必须要将注意力转移到整个图像上。我们将每个模块任务的先验知识与经验实验相结合,从而为每个操作优化出一套新的模块化架构。
在视觉问题回答任务中,推理链中的大多数步骤都需要对具有一些明显可见属性的对象(例如颜色,材质等)进行定位。我们确保每个执行此类型过滤的TbD模块都输出一维注意力掩模(attention mask),它可以明确地划分相关的空间区域。因此, TbD-net不是在整个网络中细化高维特征映射,而是仅通过其模块之间的attention mask。通过故意强化这种行为,我们产生了一个极好的具有可解释性和直观性的模型。这意味着我们离打开复杂的神经网络的黑盒又近了一步。
图3显示了一个TbDnet如何在整个推理链中适当地转移注意力,它解决了一个复杂的VQA问题,并且通过直接显示它产生的attention mask,可以很容易地解释这个过程。这里显示的所有attention masks都是使用视觉均匀的颜色图生成的。
架构细节
以下描述每个模块的架构。表1显示了所有的模块概览。有几个模块共享输入和输出类型(例如Attention和Relate),但实现方式不同,这取决于它们的特定任务。
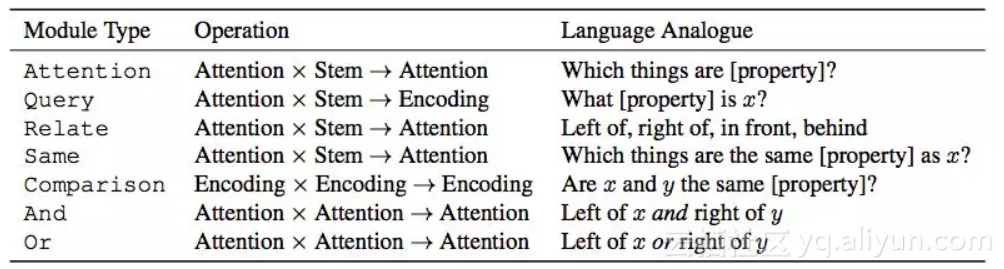
表1:Transparency by Design network中使用的模块。Attention和Encoding分别指前一模块的单维和高维输出。Stem是指训练的神经网络产生的图像特征。变量x和y表示场景中不同的对象,例如[property]表示颜色,形状,大小或材质
我们使用从ResNet-101中提取的图像特征,并通过一个简单的卷积模块“stem”提供这些特征。我们为大多数模块提供了stem特征,这确保了每个模块都可以轻松访问图像特征,并且在长的合成中不会丢失任何信息。stem可以将ResNet的高维特征输入转换为适合我们任务的低维特征。
具体的模块描述如下:
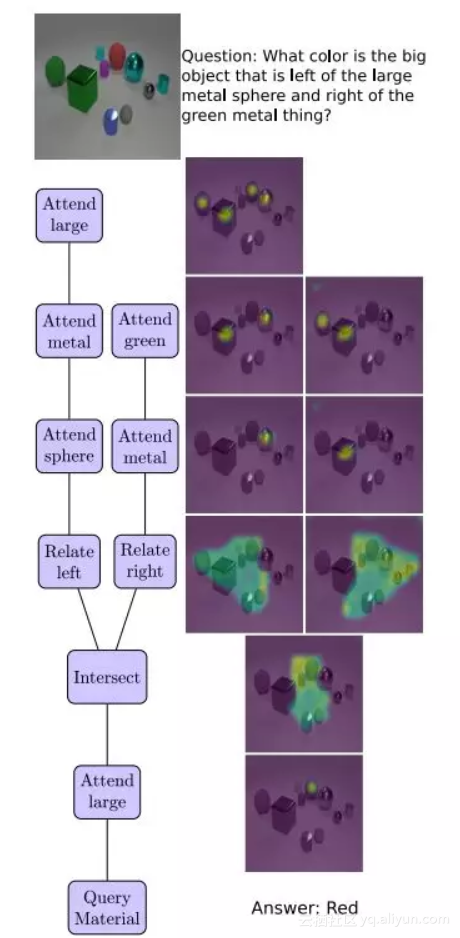
图3. 从上到下看,透明设计网络(TbD-net)组成视觉attention masks来回答关于场景中对象的问题。树形图(左侧)表示TbD-net使用的模块,右侧显示了相应的attention masks。
实验:精度达到99.1%
我们使用CLEVR数据集和CLEVR-CoGenT来评估我们的模型。CLEVR是一个VQA数据集,包含70k图像和700k问题的训练集,以及15k图像和150k问题的测试和验证集。
CLEVR
我们的初始模型在CLEVR数据集上实现了98.7%的测试精度,远远超过其他基于神经网络的方法。我们利用模型生成的attention masks来优化这个初始模型,进而实现99.1%的精确度。考虑到针对CLEVR已有许多高效的模型,我们对模型进行了5次训练,以得到统计性能测量,结果平均验证准确率为99.1%,标准差为0.07。此外,我们注意到其他模型没有一个能够以直观的方式检查它们的推理过程。而我们的模型在视觉推理过程的每个阶段都提供了直接的、可解释的输出。

图4. 输入图像(左)和Attention[large]模块产生的attention mask覆盖在输入图像上。如果不处罚attention mask输出(中间),attention mask会产生噪音并在背景区域产生响应。惩罚attention输出(右图)提供了一个信号来减少外界的attention。
透明度
我们检查了TbD模型的中间模块产生的attention masks。结果显示,我们的模型明确地构成了视觉attention masks以得出答案,从而导致神经网络具有前所未有的透明度(transparency)。
图3显示了整个问题的视觉注意力组成。在本节中,我们提供透明度的定量分析。我们进一步检查了几个模块的输出,表明任何组成的每一步都可以直接解释。

图5. 输入图像(左)和被要求注意蓝色柱状块后面区域以及大的青色椭球块前面区域产生的attention masks,输入特征分别是14×14(中)和28×28(右)。
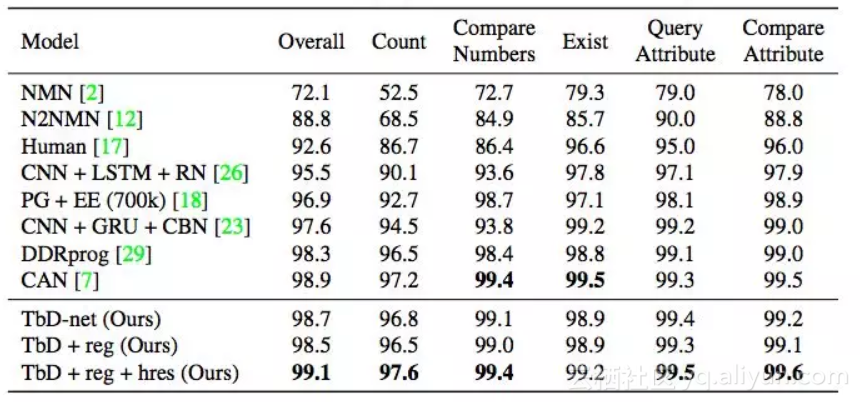
表2. CLEVR数据集上 state-of-the-art 模型的性能比较。我们的模型运行良好,同时保持模型透明度。我们在Query问题上实现了最先进的性能表现,同时保持了其他所有类别的竞争力。

图6. 输入图像(左)和Attention[metal]模块(右)产生的attention mask。当attention mask叠加在输入图像顶部(中图)时,显然注意力集中在金属块上。
CLEVR-CoGenT
CLEVR-CoGenT数据集为泛化提供了极好的测试。它与CLEVR数据集的形式完全相同,只是它有两个不同的条件。在条件A中,所有立方体的颜色都是灰色,蓝色,棕色或黄色,并且所有圆柱体都是红色,绿色,紫色或青色中的一种; 在条件B中所有颜色交换。这可以检查模型是否将形状和颜色的概念关联在一起。

图7. 一个输入图像(左)和Relate[right]模块(右)在紫色圆柱体受到注意时产生的attention mask。当attention mask叠加在输入图像顶部(中图)时,很明显注意力集中在紫色圆柱右侧的区域。
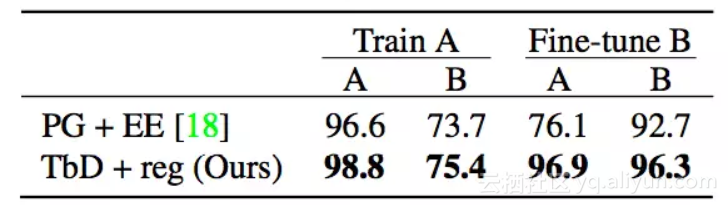
表3. 仅在条件A数据(中间列)上训练,并且在微调具有新属性的少量数据(右侧列)之后的CoGenT数据集上,TbD-net与当前 state-of-the-art 模型的性能比较。
如表3所示,我们的模型在条件A上达到98.8%的准确性,但条件B上只有75.4%。然后我们使用3k图像和条件B数据中的30k个问题对我们的模型进行微调。其他模型在微调后会看到条件A数据的性能显着下降,而我们的模型保持高性能。如表3所示,我们的模型可以从少量的条件B数据中有效地学习。在微调后,我们在条件A上达到96.9%的准确度,在条件B上达到96.3%的准确度,远高于 state-of-the-art模型报告的条件A 76.1%和条件B 92.7%的准确度。
强大的诊断工具,有助于信任视觉推理系统
我们提出Transparency by Design网络,它构成了利用明确的注意力机制来执行推理操作的可视化基元。与此前的模型不同,由此产生的神经组件网络既具有高性能又易于解释。这是利用TbD模型的关键优势——通过生成的attention masks 直接评估模型的学习过程,这是一个强大的诊断工具。
人们可以利用这种能力来检查视觉操作的语义,例如“相同的颜色”,并重新设计模块以解决推理中明显的偏差。利用这些attention作为提高性能的手段,我们在具有挑战性的CLEVR数据集和CoGenT generalization任务上实现了最高的准确度。对神经网络操作的这种洞察也有助于用户建立对视觉推理系统的信任。
原文发布时间为:2018-03-16
本文作者:闻菲、肖琴
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”微信公众号