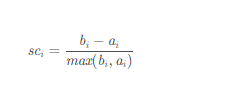一:背景
分类地图业务是指手淘首页首屏的"分类"入口,目前整个产品已经有300万左右日活跃用户和6000多万pv, 目前产品业务点较多,本文重点介绍点击品类词后的商品二跳页模块,具体如下图所示:当用户点击相应的品类词图片后,则会进入该类目下的商品集合。


图1 图2 图3
图2是一跳页推荐的与用户相关的品类词, 图3是点击该品类词后,对应的二跳页排序结果;二跳页是在该品类下,用户所偏好的商品,目前的算法逻辑是u2i商品作为trigger, i2i作为精准推荐,热门商品作为补充,整个逻辑还是偏向基于经验的业务规则,因此我们希望通过一个深度学习模型来进行统一的优化。
二: 业务目标
我们的模型重点优化的就是商品集的召回和排序。分类地图业务今年的重点目标就是让用户逛起来,使得用户在我们的产品中可以更多的产生点击,翻页,切换tab等行为,真正的"逛起来", 因此我们的商品二跳页的重要目标就是用户是否愿意点击商品和翻页,也就是点击率和翻页率。
三: 具体方案
由于淘宝上每个类目下的商品集合非常庞大,达到千万甚至亿级别,而我们分类地图下每个类目最多展示100个商品; 因此首先用星级卖家(星级大于12)筛选出一个初选的商品集合,再基于不同cat的Match网络和Rank网络来生成最终的推荐集合,给用户浏览
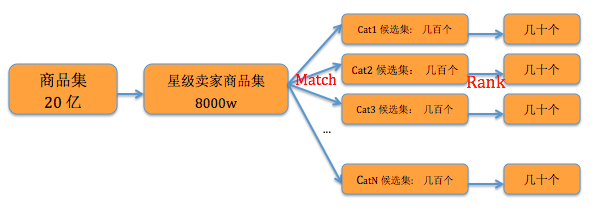
其中在Match阶段,我们尝试了多种方案,包括了"Deep Neural Networks for YouTube Recommendations"论文中的召回阶段模型,该模型适合从海量的候选集里进行粗粒度召回,但实际上我们的高星级卖家商品集合通过叶子类目(全网全部叶子大概有7000多)划分后,平均每个类目下有几万个商品,对于一些热门类目,比如连衣裙,有十几万个商品,而更多的长尾类目下只有几千个,甚至几百个商品;因此最后在召回阶段我们使用了把高星级卖家商品集按照叶子类目划分,然后再用商品热度分数(主要用商品的30天内的全网点击和成交进行拟合)设置一个阈值进行召回。而将重点放在Rank阶段的模型优化上。
3.1 模型目标
提升分类地图二跳页商品的CTR, 翻页率
3.2 样本选择
分类地图商品二跳页自身业务场景的点击日志,点击为正样本,pv为负样本,其中负样本进行随机采样(我们还尝试了将点击商品为正样本,只取被点击商品前面的商品为负样本,这样会造成一些排前面的商品全部被当做负样本,造成效果并不好); 正负样本比例保持在1:3左右; 模型训练分成训练集和测试集,其中训练集样本数:39181025; 测试集样本数400w左右
3.3 模型特征:
user:包括用户性别,年龄,购买力,宝宝年龄,宝宝性别,地域,职业,用户群体等,
item: 包括商品类目,品牌,价格,30天内点击,成交,加购,收藏等统计特征
组合特征: 包括user_id对item_id的点击,成交,收藏,加购等统计特征
特征总数共200多个
同时我们把特征划分为三类:
1) id类稀疏特征 2) 统计类和离散类的稠密特征 3)embedding特征(包括user的历史点击商品属性向量,商品title的词向量),这里需要提到的是,由于商品id过于稀疏,我们在对用户的历史点击行为进行embedding的时候,使用了用户历史点击的商品的属性id向量作为embedding的输入。
3.3 模型原理
模型上我们选择了google的论文Deep & Cross Network for Ad Click Predictions中提到的DCN模型。
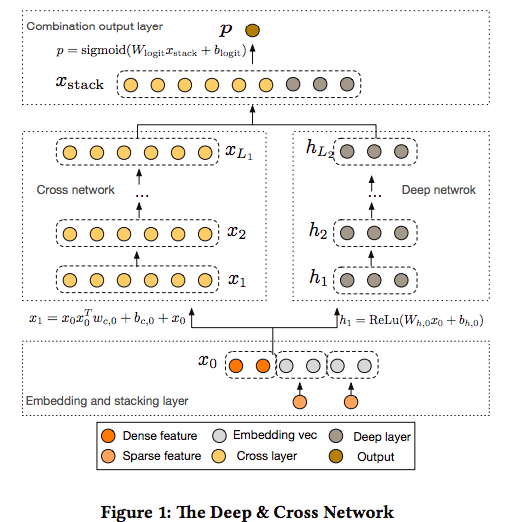
如上图所示, DCN模型的输入包括了sparse特征,dense特征, embedding特征,而模型训练阶段分成两个部分,右边部分是传统的DNN模型的deep层,其中每个deep层后都接入relu激活层, 把原始特征通过多个隐层使得特征变得更加高阶,而左边的cross layer通过一个递归的特征组合公式:
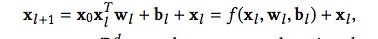
每一层的特征都由其上一层的特征进行交叉组合,并把上一层的原始特征重新加回来。这样既能做特征组合,自动生成交叉组合特征,又能保留低阶原始特征,随着cross层的增加,是可以生成任意高阶的交叉组合特征(而DeepFM模型只有2阶的交叉组合特征)的,且在此过程中没有引入更多的参数,有效控制了模型复杂度。最后把cross层的输出结果和deep层的输出结果组合到一块来进行LR模型训练,在我们的业务场景下,就是预估user_id在<catid, item>pair下的点击概率。
3.4 模型训练
基于pai-tensorflow平台,我们实现了DCN模型,并且在模型训练过程中实验了非常多的版本,迭代了很多次来优化模型超参, 这边重点介绍几个重要的超参对比:
1. deep layer:3 (256, 128, 64); cross layer : 2层, sigmoid回归,loss加入l2正则项; 优化器Adam, 学习率0.01, 每个batch 512个样本 ;训练结果测试集auc 为 0.67
2. 同1, 学习率调整到0.001 ; 训练结果测试集auc 为 0.7
3. 同2, 并加入item的词向量的embedding特征,对embedding分别实验了avg和sum操作;发现sum的效果要好些
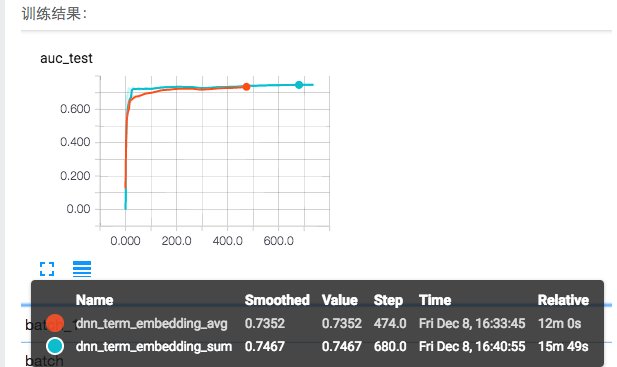
我们最终用于线上预测的版本的auc在0.75左右
3.5 预测及bts上线
我们的预测阶段是放在odps上处理的,将pai-tensorflow上训练的模型通过export和saver的接口来导出Session bundle, 然后在odps上运行DCN模型的整个前向计算过程(在 tensorflow的signature接口中定义) ,预测出userid在每个<catid, item>pair下的点击概率,然后离线产出排序数据。
最后在我们的TPP服务中加载离线产出好的模型预测数据来进行线上bts测试,我们发现DCN模型版本下的二跳页指标都是有一定提升的,具体见下图:
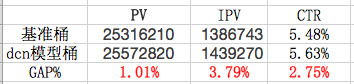
通过pv指标可以看出,二跳页的翻页数提升有1%, 而整个二跳页的CTR提升有2.75%。因此我们业务的核心指标都是有一定正向提升的。
四: 后续展望:
由于个人精力有限和考虑时间成本,整个DCN模型目前仅仅是一个简单的实现,还没有做一些创新和探索。目前使用的deep + cross + sigmoid的组合方式可以通过多种模型组合来进行替换,比如deep层可以替换成残差网络resnet, 变成resnet+cross + simoid, simoid层可以替换成forest模型,变成deep + cross + forest模型等。
同时我们的模型预测是放在离线完成的,后续可以借助于RTP, EAS等服务实现在线预测, 并接入pora平台实现实时模型训练。
最后,非常感谢 @开锋 老师在项目前期的耐心指点, 感谢 @三桐 老师在项目后期的关注和支持!
五:参考文献
1. Deep Neural Networks for YouTube Recommendations
2. Deep & Cross Network for Ad Click Predictions