虚拟化技术
虚拟化技术:
计算机基本部件:控制器+运算器=CPU memory I/O(keyboard monitor)
虚拟化:将底层的计算机资源抽象或者虚拟为多组彼此之间互相隔离的计算平台,每一个平台都具有五大部件中的所有设备。
将计算机的基本设备平均的或者按照某种标准划分成不同的部分
基础架构 用户空间 库级别 的虚拟化
Cpu虚拟化 (少于物理核心数) 切割时间片-->> 进程
分时技术-->>虚拟机
模拟(完全虚拟化):
1,通过软件模拟出来cpu,一个cpu相当于一个进程,当需要调用特权指令时,再向宿主机调用(解码 封装);底层和上次架构不一致,模拟ring 0 1 2 3
2,BT(banary translation)二进制翻译技术。当虚拟机内核进行特权指令调用时,直接翻译成对宿主机的特权指令的调用,边运行,边调用,边翻译,边转换,即运行时翻译。不再需要软件级别的封装和解码。底层和上次不一致。模拟ring0.假设各guest的内核是运行在ring1的。完全虚拟化。Host得支持硬件虚拟化。<软件>
3,HVM<硬件> 硬件辅助的虚拟化
将cpu分成5个环
-1:宿主机。特权指令
0:没了特权指令
HVM硬件虚拟机器
半虚拟化:
Guest知道自己运行在虚拟化技术中,当需要调用特权指令时不直接调用cpu特权指令,而是自己去寻找宿主机的内核去请求
虚拟机监视器:hypervisor(直接管理硬件,相当于内核上,跑在宿主机上),主要是cpu和内存的虚拟,不包括IO设备,hyper call:一般系统调用直接由虚拟内核完成,当需要时由hyper call来提供。直接调用,而不是翻译。调用的不是cpu指令集而是hyper call。
Memory虚拟化:
Memory本身就是虚拟化的,每一个进程看到的是线性地址空间,内核看见的是物理地址空间
1,硬件不支持虚拟物理地址转换成物理地址,需要模拟
进程要访问一个数据,将线性地址提供给虚拟机cpu(cpu无法识别线性地址),然后cpu将线性地址转交给MMU(负责将线性地址转换成物理地址),此时还在虚拟机内,是虚拟物理地址,所以虚拟机内核再将虚拟物理地址转交给hypervisor hypersior软件里面通过虚拟MMu技术将虚拟物理地址转换成物理地址提供给宿主机。
宿主机上的多个虚拟机会出现tlb(转换后源缓存器,缓存mmu中的表中的从线性地址到物理地址转换的对应关系,主要有缓存)很难命中问题:tlb缓存a上关系,虚拟机切换到b上后,又缓存b上关系,需要一直清理缓存,可以用虚拟TLB技术来调优:
TLB虚拟化:
TaggedTLB:直接将GVA-->>HPA,缓存下来,而不需要在缓存中间的GPA等过程
2,硬件支持:
Intel:EPT扩展的页表技术
AMD:NTP嵌套页表
这两种都是虚拟MMU技术
Cpu:时间切割内存:空间切割
I/O虚拟化:
外存:
硬盘,光盘,U盘
网卡:
网卡
显示设备:
VGA(图像设备器):frame buffer机制(焦点捕获方式)
键盘鼠标:
Ps/2,usb
方式:1,对I/O虚拟来讲 模拟==完全虚拟化:完全使用软件来模拟真实硬件简单 性能差
2,半虚拟化:例:数据包的发送 网卡的调用
![]()

IO backend
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() IO frontend
IO frontend
![]()
![]()
![]()
![]()
![]()
![]()
在前端给用户可显示的网卡,并没有实际功能,实则直接发给后端的虚拟网卡设备,hypvisor 的IO栈将虚拟网卡转换成实际网卡调用,在此有个队列,将多个虚拟机的发包进行排队,I/O调用驱动程序来使用网卡等硬件设备
3,IO透传技术IO-through:硬件支持透传
让虚拟机直接使用物理设备(要使用hypervisor进行协调:通过设备管理器将宿主机的设备分配给guest os ,guest os才能使用宿主机的设备)。使用几乎接近硬件物理性能的设备来使用硬件。
Intel:VT-d技术:完成中断映射
基于北桥的硬件辅助的虚拟化技术,提高IO的可靠性和灵活性
DMA:直接内存访问:加速IO访问的方式:将各寄存器中IO设备中的数据保存在读过来直接放在内存中
IOMMU:IO内存管理单元:IO总线到IO地址转换的设备
Guest的用户空间在环3上 内核空间在环1上。
如果在转换时虚拟机和宿主机不是一个操作系统,在调用特权指令时就要 转换 成对应的宿主机的特权指令,此过程中消耗更多资源。
64为兼容32位
用户空间(环三,系统调用)和内核空间(环0 特权指令)
运行普通指令的环三环一和环二未使用 环零中 操作某些寄存器的特权指令
BT技术:guest
两种实现方式:
Type-一型:直接在硬件上没有操作系统,安装hypervisor,直接管理硬件信息,所有运行在硬件上的操作系统都是虚拟机。xen,vmare: ESX/ESXi
Type-二型:在硬件上创建操作系统,在操作系统上安装软件,有软件来创建虚拟机。管理上更可靠。kvm, vmare workstation,vitrtualbox
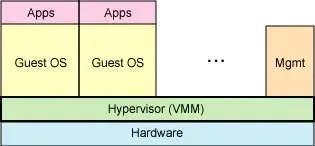
VMM:虚拟机监视器
虚拟化技术的分类:
1,模拟:Qemu 指令转换(高层到底层),不够稳定硬件可任意
虚拟出来的cpu由于和硬件物理机的cpu不兼容,在调用常规或者特权指令时就需要中间软件进行翻译到具体的cpu上,翻译比较慢,翻译完还要再次执行,性能很差
BT二进制翻译技术
2,完全虚拟化:KVMVMware workstation
硬件架构要与宿主机相同,只要不是调用特权或者敏感指令,这些指令就会直接运行在物理cpu上,如果是特权指令,虚拟机监视器VMM就会捕获翻译或者调用hype call的方式。
3,半虚拟化:xen(在硬件辅助之下也支持完全虚拟化,不过必须工作在HVM模式)
Guest os必须修改内核,让其知晓自己运行在虚拟化环境中,当需要操作硬件时,不是直接操作硬件,而是发起hyper call调用
4,OS级别的虚拟化(容器级虚拟化):
没有VMM,将用户空间进行切割虚拟,直接运行在硬件上,分割为多个,彼此之间互相隔离(namespace)。
容器级虚拟化:docker
DockerVZ,LXC(LiunX Container)
5,库级别的虚拟化:
WINE:linux中运行windows中的程序
调优:
跨多个物理主机进行调度管理运行在其上的虚拟机:
Iaas云环境:xen kvm
基础架构服务Infrastructureas a service
Paas云环境:容器级虚拟化 平台服务Platfrom
两种实现方式:
Type-一型:直接在硬件上没有操作系统,安装hypervisor,直接管理硬件信息,所有运行在硬件上的操作系统都是虚拟机。xen,vmare: ESX/ESXi
Type-二型:在硬件上创建操作系统,在操作系统上安装软件,有软件来创建虚拟机。管理上更可靠。kvm, vmare workstation,vitrtualbox
Xen:
开源VMM
Xen Hypervisor必须直接运行在硬件资源上
虚拟化了 CPU,内存(所运行的内核最基本的驱动),所有虚拟机的cpu和内存都是由xen hypervisor提供
硬件如果想被运行在硬件上的应用程序使用,直接运行在硬件上的操作系统的内核就得能加载这个硬件的驱动
IO:第一个虚拟机(Dom0)的内核来实现:
1,提供一个管理其它虚拟机的接口
2,提供一个管理平台内核空间提供了各种IO的驱动
当其他虚拟机需要调用IO设备的时候向第一个虚拟机发出请求,第一个虚拟机的内核cpu通过对真实IO设备在用户空间的模拟,提供给其他虚拟机(Qemu来模拟实现)
运行在Dom0上的用户空间的Qemu为每创建的一个虚拟机用到IO设备时,模拟出一个IO设备,并映射到真正的硬件设备上实现
I/O虚拟化的半虚拟化方法是Xen所采用的方法,它也就是广为熟知的分离式驱动模型,由前端驱动和后端驱动两部分构成。 前端驱动运行在Domain U中,而后端驱动运行在Domain 0中,它们通过一块共享内存交互。前端驱动管理客户操作系统的I/O请求,后端驱动负责管理真实的I/O设备并复用不同虚拟机的I/O数据。
底层cpu的一个线程就相当于虚拟机的一个cpu
底层的物理地址进行分段,将其中一部分提供给虚拟机使用(对底层来说可能是分段的,不连续的地址段,但对虚拟机来说是连续的)
组成部分:
1,Xen Hypervisor:Xen的核心组成部分,虚拟化监视器,直接运行在硬件之上,直接将运行能力提供给运行在其上的虚拟机操作系统。
在各虚拟机之间进行CPU和内存的分配,中断请求的分配。
2,Dom0(特权域):
直接运行在硬件上,能和硬件资源进行交互,也能和其他虚拟机进行交互
特权域:IO资源分配
为了支持半虚拟化(前端和后端)
网络设备:net-front net-backend
块设备:block-front(虚拟机中) block-backend(特权域中)
Linux Kernel:2.6.37
提供管理DomU的工具栈:用于实现对虚拟机进行添加,启动,快照,停止,删除等操作。
3,DomU:
非特权域,无权访问硬件资源:根据其虚拟化方式实现,有多重=种类型
只有在硬件资源支持下才能支持完全虚拟化,否则只支持半虚拟化
DomU的虚拟化类型:
PV半虚拟化
HVM硬件辅助虚拟化(完全虚拟化):利用cpu提供的环-1运行Xen Hypervisor,cpu能主动捕获到每一个虚拟机尝试去执行特权指令并通知给XenHypervisor,留下来完成指令转换过程。
PV on HVM:IO半虚拟化 CPU完全虚拟化
Xen的PV技术:
不需要cpuHVM特性,硬件辅助虚拟化,但guest必须知道自己运行在PV环境(内核)上,无需仿真cpu。
Xen的HVM(硬件辅助虚拟化)技术:
依赖于INtel VT或AMD-V硬件扩展,还要依赖于Qemu来模拟IO设备。
运行于DomU中的OS,几乎所有支持此X86平台
Xen的PV on HVM:
Cpu为HVM模式运行
IO设备为PV模式运行
运行于DomU中的OS:只要OS能驱动PV接口类型的IO设备。
Net-front blk-front
guest中要能支持它的前半段,Dom0要能支持后半段。
Xen的工具栈:
Xm/xend:在xen hypervisor的dom0中要启动xend服务
Xm:命令行管理工具,有诸多子命令:create,Destroy,stop,pause
xl(轻量级):基于libxenlight提供的轻量级的命令行工具栈
Xe/xapi:提供了对xen进行管理的api,因此多用于cloud环境。
Virsh/libvirt(库):virt-manager
云栈,云环境:统一对虚拟机资源进行管理
XenStore:
为各domain提供的共享信息存储空间,有着层级结构的名称空间,位于Dom0,由Dom0进行管理,支持事务和原子操作,用于控制DomU中的设置,通过不同方式对它进行访问
Type-I:硬件-->>hypervisor-->>vm
Type-II:硬件-->>host->>VMM-->>vm
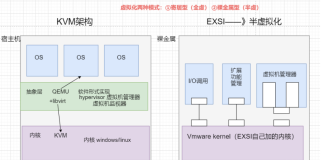
KVM:kernal-based Virtual Machine
运行在硬件上的宿主机(host)在安装了KVM之后,宿主机的内核空间转变成Hypervisor,用户空间就成为了这个Hypervisor的控制管理台的接口,用户空间会提供一些接口来创建虚拟机使用,创建的虚拟机就相当于运行在内核上的进程,用户空间的系统管理工具可以拿来管理虚拟实例。
内核cpu通过向宿主机的cpu创建线程来实现
依赖于HVM技术
KVM载入后系统的运行模式:
KVM hypervisor:原来的宿主机的内核由于加入了KVM所以变成了Hypervisor,加入的KVm Driver
内核模式:guest os执行的IO类操作,或其他的特殊指令操作“来宾-内核”模式
用户模式:代表guest os执行IO类操作
来宾模式:guest os非Io类操作,它被称作虚拟机的用户模式,“来宾-用户”模式
虚拟机的cpu调度相当于物理机cpu的一个线程
IO类操作由运行在用户空间的Qemu来实现
KVM组件:
两类组件:
/dev/kvm:工作于hypervisor,在用户空间,可以通过ioctl()系统调用完成vm创建,启动等管理功能,他是一个字符设备
功能:创建Vm,为Vm分配内存,读写Vcpu的寄存器,向Vcpu中注入中断,运行Vcpu等等
qemu进程:工作于用户空间,主要用于实现模拟PC机 的IO设备
KVM特性:
内存管理:分配给虚拟机的内存交换至swap
支持使用Huge Page
支持使用Intel EPT或AMD RVI技术完成内存地址映射:虚拟机的用户空间的线性内存直接到物理内存地址空间:
GVA-->>HPA(直接映射)
(如果没有这个技术,原来阶段就需要影子页表来实现:GVA-->>GPA-->>HPA)
支持KCM(kernal same-page merging)相同页面合并:操作系统和版本一致,内存页面共享,降低内存占用
硬件支持:取决于linux内核
存储:本地存储:
网络附加存储:
存储区域存储:
分布式存储:
实时迁移:多个物理机运行hypervisor,底层硬件相同或者兼容,运行在第一个hypervisor上的虚拟机可以在运行时可以被调度到第二个上面,并且这个虚拟机上运行的程序还不会被终止(使用共享存储存储磁盘映像文件)
当一个物理机上的虚拟机运行时,在本地有对应的内存信息,在实时迁移时将这个内存信息复制到另一个虚拟机上,并创建另一个虚拟机实例,这样原来的虚拟机就结束掉,内存就得到释放。
支持的guest os:linux,windows,OpenBSD
设备驱动:
IO设备的完全虚拟化:模拟硬件
IO设备的半虚拟化:在guest OS中安装驱动,virtio(virtio-blk,virtio-net.virtio-pcl)
KVM局限性:
一般局限性:
Cpu Overcommit:所有虚拟机的虚拟CPU的数量不要大于物理cpu的数量
时间记录难以精确,依赖于时间同步机制。
Mac地址:
Vm量特别大时,存在冲突的可能性
实时迁移:
硬件兼容
性能局限性:
Kvm的工具栈:
Qemu提供的:
Qemu-kvm:与底层KVM打交道,完成虚拟机的创建管理等相关管理操作
Qemu-img:磁盘映像文件的管理
Qemu-io:对IO性能的监控
Libvirt:
Virtual machine manager:
Virsh:命令行工具
Libvirt:进行管理
Virt-viewer:查看
图形化管理工具:virt-manager virt-viewer(查看)
Virsh和virt-manager支持远程管理操作
Qemu主要提供了的一下几部分:
处理器模拟器:
仿真IO设备:
关联模拟的设备至真实设备:
调试器:
与模拟器交互的用户接口
本文转自 Taxing祥 51CTO博客,原文链接:http://blog.51cto.com/12118369/1957620