1. 按照系统类别进行监控
很多朋友在使用SCOM进行监控的时候,往往只是导入管理包,推送代理,并不会思考很多,那么在这种情况下,SCOM在进行监控的时候都是基于缺省的类对象进行监控,比如说Windows计算机,一次就只能以一台Windows计算机的维度去监控,点击一台Windows计算机,下面会是关于这台计算机的进一步信息,比如这台计算机上面的磁盘,CPU,内存,数据库状态。
但是,这种监视方式太狭隘了,而且不便于整体统计,如果企业有很多业务系统呢,每个业务系统下面有很多机器,当企业要统计业务系统整体的运行状况SLA应该怎么办?一台一台的去查看,然后手动统计吗?在SCOM中其实有一种更好的解决方案。
深入研究过SCOM的朋友应该会知道,SCOM监控是按照类对象进行监控,当我们手动去创建监视器或者进行APM监视的时候,都会发现,需要我们指定一个类对象,即我们要对那些进行监控。实际上,在指定类对象的时候,可以指定成为组,针对组来进行监控
例如,一个业务系统具备中间层,Web层,数据库层,我们就可以在SCOM中为这三个三个层创建三个子类组。然后分别将每个业务物理的计算机,加入到逻辑的SCOM组中,建立好了之后,再建立一个大的父类对象组,例如业务系统的名称叫做科研系统,就可以建立建立一个科研系统的父类组,然后将科研系统包括的中间层,Web层,数据库层,加入到科研系统的子组中。
一旦您按照这种方法做了,就意味着,您现在的监控对象,已经不仅仅是针对于计算机级别,或者说是一个磁盘级别,而是按照系统级别进行监控。
比如说,您可以在SCOM监视视图中,针对于不同的业务系统建立不同的文件夹。比如说科研系统文件夹,科研系统文件夹下面又可以包括性能视图、图示视图、警报视图、事件视图等等。
在科研系统监视文件夹下面的图示视图中,您就可以将科研系统的父组作为展示对象添加进来,添加进来之后,您会发现,在图示视图中呈现出来的是上面一个父类组,下面是三个子类组,子类组下面是一台一台的Windows计算机。这种情况下,如果管理员需要巡检系统状态,就可以在图示视图中直接查看最上面的父类组状态,因为父类组会把下面的子类组与子类组中的计算机状态都汇总上来。管理员点开父类组后还可以继续点开子类组,点开后继续点开子类组中的计算机,点开计算机后还可以再点开计算机下面的数据库或者IIS状态,通过这一个过程您应该会发现,整个监视变的直观、整体、方便了起来。
同样,您还可以在科研系统文件夹下,再新建警报视图,警报视图的展示对象也可以按照父类组为展示对象,这样做了之后,您会发现,每一个系统文件夹下面的的警报视图,就会出现,整个科研系统所有的警报,但不会有除科研系统以外的警报。
比较典型的还有性能视图,管理员可以在系统文件夹下再建立不同业务系统的性能视图,同时,性能视图的展示对象也可以按照父类组为展示对象,这样做了之后,您会发现,性能视图中,就会出现所有子类组以及子类组中子对象的性能计数器,同时,整个性能计数器是可定制,可持续保存的。
还有很多视图,其实操作都一样,我就不一一介绍了,通过系统级别进行监控的目的,就是把一个个的子对象,加入到子组中,将子组的对象状态,监视信息汇总到子组级别,再将子组加入到父组,就会把子组里面所有的对象状态和监视信息再汇总到父组。然后在展示的时候,以父组为展示对象,直接会按照级联层次性,把父组下面的子组、子对象展示出来
这个是我们在进行基于ITIL的SCOM监控最佳实践所调优的第一步,通过这一步的调优,在使用SCOM进行监控的时候,已经可以按照系统级别,进行更加直观,更加整体化,更加符合业务需求的监视。
2. 警报分类分人处理
当然,仅仅有了良好的监控视图还不够,一旦目标监控对象出现性能问题,或者故障问题,该如何进行处理,该由谁进行处理呢,该如何利用SCOM里面的功能进行有效的事件分类?
其实在SCOM中有一种很简单的解决办法,叫做警报订阅,只需要在SCOM中简单的配置一下,就可以和企业现有的SMTP服务器进行结合。
具体应该如何做,首先应该先AD中,创建不同的用户组,比如说一线负责监控巡检的监控组,负责开发的应用组,负责服务器运维的服务器组,负责关注主要问题的信息安全组。首先现在AD中把这些安全组建立起来,然后把具体的职责用户再加入到组中。
建立好了之后,第一步完成,接下来,回到SCOM中,我们要根据不同的组,创建不同的订阅方式,这样做的目的是做到警报分类。
比如说,我们建立一个服务器组订阅,由于服务器组可能需要监控管理公司所有的服务器,所以,在创建订阅的时候,就可以把警报订阅内容选择为所有系统对象,但是,服务器组可能并不懂得开发,所以,一些关于APM的警报可以不让服务器组接收。在警报订阅过程中,可以定义警报规则,警报接收时间,以及警报接收人。
除了服务器组,还有应用组,相比较服务器组而言,应用组需要关注的警报可能更少一些,应用人员可能只需要保证他的IIS\SQL\ORACLE\APM业务系统,没有性能问题和故障问题就可以了,所以在创建应用组订阅的时候,警报规则就可以只定义IIS\SQL\ORACLE\APM,这样定义之后,应用组就只会收到这些角色的所有警报,而不会收到其它的警报。
相比较服务器组和应用组而言,信息安全组可能需要关注的警报就更少,因为信息安全组一般都是管理阶层,所以往往只关注于主要系统的可用性,只要可用性不出现问题,就不需要信息安全组知道,所以在对信息安全组进行警报订阅创建的时候,警报规则,只需要定义,比较主要的业务系统,满足警报优先级为严重的,才会发送给信息安全组。这样定义之后,只有当主要业务系统出现严重警报,一般也就是不可用的时候,才通知给信息安全组。
通过以上的定义,大家就可以看出,在SCOM中,什么样的警报,满足什么级别,由谁来看,都是可以进行订阅定制的,这样做了之后,就很好的在一种程度上进行了职责任务隔离,不同的工作人员,只需要专注于自己的领域就可以。
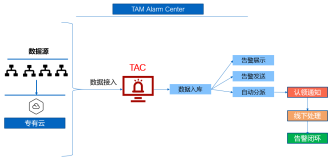
实际上在我们现在定义的,是属于警报的规则定义,即出现警报,什么类型的警报,警报优先级,那些订阅者负责接收警报。在定义好了警报规则之后,实际上,我们还可以去定义通道,通道的意思就是,警报产生了,要以什么方式去通知工程师。默认没有订阅定义的情况下,工程师可以通过SCOM控制台或者SCOM Web控制台的方式,查看到警报。那么有了订阅之后,管理员就可以定义不同的通道,SCOM支持邮件\即时消息\语音\SMS短信猫的方式来做警报通道,企业可以同时使用多个警报通道,也可以自定义第三方的警报通道,警报通道目的就是保证发生警报的时候,可以通过多种方式及时通知给警报的处理人。
以上所述就是SCOM中的警报分类,那么警报分人是什么意思。
定义警报分人的目的,就是为了实现一些ITSM系统平台中的事件派送功能,您可以在SCOM中定义不同的警报解决状态,比如说:发送给一线监控组,发送给服务器运维组,发送给业务应用组,发送给信息安全组,发送给高级工程师组,等等。一旦定义了这些警报解决状态之后,当一线监控组的人员,每天打开SCOM控制台或者打开SCOM Web控制台进行巡检的时候,发现了警报,但是警报并不属于一线监控组的处理范畴,这时候一线运维组就可以在控制台中,选择警报,点击右键,把警报发送给相应的人员,比如发送给服务器运维组,这样当服务器运维组打开SCOM控制台的时候,或者当服务器运维人员收到邮件和短信的时候,就可以看到分配给他的警报,分配警报到服务器运维人员之后,首先服务器运维人员应该先查看警报,以及警报所提供的知识库,如果确定警报可以解决,则把警报更新为已确定状态,如果警报不能解决,服务器运维人员可以再把警报分配给高级工程师或者服务提供商。当警报已经彻底被服务器运维人员解决后,如果警报没有自动消失,可以将警报更新至已解决状态。等待一段时间,如果警报消除在控制台,其实这时候警报还是存储在SCOM的数据仓库中,默认会保存365天,也就意味着,警报会一直存储在数据仓库中,供运维人员进行报表的分析和预测。
定义警报分人的好处,我相信大家已经看到,就是可以按照不同职责,不同Level,进行分配警报,将警报交由不同的人去处理,处理好了后更新警报状态,归档警报至数据仓库,现在已经稍微有一点点ITIL事件处理的味道了。
3. 视图细化授权查看
在默认情况下,以SCOM安装管理员登录进来,你会发现可以看见所有的视图,以及所有的功能,没什么好说的,最大的管理员嘛,那么What about other people,如果一线的监视组需要登录到SCOM控制台,以什么权限,什么账户登录进来吗?难道都用administrator,SCOM最大权限登录?别闹···
在这里,笔者是十分不建议所有人登录SCOM控制台都用administrator或者单一的账户账户登录。这样不仅仅安全性是一个问题,而且没办法进行审计,因为如果所有人都用同样的账户登录,你就没办法审计警报到底是又谁处理的。
那么,既然这样,到底应该怎么进行授权呢,其实在SCOM中提供了非常严谨的视图细化授权设置,在SCOM控制台—管理—安全角色的地方大家就可以看到,默认提供了八种用户角色。
作者
只读操作员
应用程序监视操作员
报表安全操作员
报表操作员
操作员
管理员
高级管理员
具体每一项角色的权限角色是什么样子,大家可以去SCOM中或者去TechNet网站上进行查看,在这里,我只是给出我所认为的最佳实践。
首先,一线监控组,整个组在企业中,往往就扮演着监控巡检的角色,所以一线监控组,并不需要对SCOM具有很高的管理权限,所以在进行授权的时候。只需要为一线监控组创建一个只读操作员的安全角色就可以了,然后把一线监控组的AD安全组,加入到整个安全角色中,顾名思义,只读操作员,所以一线监控组,对于SCOM中所有的东西,都只能进行看的操作,除了只读操作角色,一线监控组可能需要定期生成报表,输出报表去给领导进行查看,所以还需要将一线监控组,加入到报表操作员的安全角色中,所以最终一线运维组的权限就是对于SCOM全局只读,但是可以生成报表,查看报表。
应用组,和一线监控组不同,因为应用组可能需要在SCOM控制台中对IIS和SQL要执行一些管理操作,应用组需要查看APM网站,需要查看报表。所以针对于这一类应用组,首先应该先为期建立一个操作员级别的安全角色,作用域级别和视图仅仅是IIS\SQL\Oracle的SCOM监视视图,将应用组AD组加入到安全角色中,这样做了之后,应用组的人使用应用组的用户账户登录SCOM控制台后,就只能看到属于应用组的IIS\SQL\Oracle 以及对应的系统文件夹,除了安全角色作用域之外的视图,应用组是看不到的,除了操作员角色,应用组可能还需要登录到APM网站去查看.NET和JAVA程序的运行状况,耗时体验,所以还需要为应用组授予应用程序监视操作员角色,让应用组的用户账户,可以登录到APM网站,最后再为应用组加入到报表操作员角色,让应用组可以查看应用程序相关的报表。
服务器运维组,这一类的服务器运维组,往往在企业中具备着所有服务器的管理权,平时也需要对企业内部所有的服务器进行维护,管理的操作,所以他们在SCOM中的安全角色可以授予的大一些,可以把服务器运维组加入到管理员、报表操作员、报表安全操作员安全角色,同时作用域视图设置为全局,让服务器运维组可以在SCOM中看见所有的监控项
信息安全组:这一天类的信息安全组,往往在企业中,扮演着信息部门管理人员的角色,平时可能需要定时去SCOM查看一下整体的运行状况,看一下应用程序状态,以及报表,所以信息安全组的权限可以这样授予:全局作用域,高级管理员,应用程序监视操作员,报表安全操作员
通过定义视图授权,我们又对SCOM使用进行了进一步的优化,没有做授权之前,对于权限不能很好的控制,不能很好地审计操作,经过授权安全角色之后,不同的工作人员就只能看见自己工作范围内的视图,从而避免了误操作误影响等风险,而且每一个人员登录到SCOM之后所执行的操作,都可以在SCOM数据仓库审计到。
4. What about 服务管理
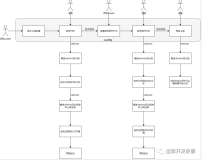
经过了以上三项非常基本简单的优化之后,我们已经可以初步看到依托于SCOM事件处理流程,首先警报发生,一线监控人员,通过Web console、console、邮件告警、声音告警、短信告警、即时消息告警等方式,收到警报,监控人员首先对警报进行基本判断,如果可以使用已有的SCOM知识库或者处理经验进行解决,即在监控人员等级就把警报解决关闭。如果监控人员经过短暂的判断觉得问题解决不了,则把问题分配给服务器组或者应用组,服务器组登录Webconsole or Console 确认警报,如果可以解决,则处理警报,然后更新警报状态为已解决。如果服务器组不能解决,则继续把警报上升分配。最终问题解决了之后,警报状态更新为已解决,归档至SCOM数据仓库,目前的一套流程看似是这样。
其中一个有歧义的地方,就是大家可能会问为什么是由一线监控人员分配警报,其实这里并不一定非要由一线监控人员来进行分配警报,我之所以这样写的原因是,在企业中可能一旦真正的使用了一套运维监控系统之后,那么可能就需要一线监控人员经常在监控平台进行监控,所以我想,有什么警报,可能第一时间是一线监控人员知道。
如果服务器运维人员或者应用人员先于一线监控人员发现警报,当然更好,这样,服务器运维人员就可以直接自己确认警报状态,修复警报,而不需要一线监控人员进行处理。
在这样一套流程中,大家对应着ITIL事件处理流程,可以发现似乎缺少了一个用于事件处理的Protal,但其实在目前,整个Portal是由SCOM的Web Console进行扮演,一切针对于事件警报的处理,分配,更改都是在Web Console上面进行,如果您觉得SCOM的Web Console不够专业,不够闪,在System Center中,您还有一种选择,就是SCSM,感兴趣的朋友可以去了解下SCSM,我将SCSM理解为微软的ITSM服务管理平台,在SCSM提供了很多个连接器,针对于SCOM有两个连接器,一个是CI连接器,通过配置SCSM与SCOM的CI连接器,会把SCOM中的所有监控项同步到SCSM的CMDB,另外一个连接器是警报连接器,通过配置SCSM与SCOM的警报连接器,可以将SCOM中产生的警报,即时自动同步到SCSM中的事件,然后在SCSM的Portal中,针对于事件进行处理。一旦采用了SCSM,那么就不需要我们之前再在SCOM中定义警报分类分人了,采用了SCSM后,就可以在SCSM中定义这种事件处理者,然后不同的事件处理者负责处理一类的事件,和SCOM一样SCSM中也可以警报分配,还可以直接上事件上升为问题,解决问题之后发起变更与发布,相比之下我认为SCSM则是更加完全的贯彻了ITIL的思想
5. What about 自动化
在SCOM或者说SystemCenter中的运维自动化处理,如果要说的话,我暂时能想到的处理形式有三种运维自动化
首先最简单的,直接把自动恢复任务绑定在SCOM的监视器上,比如说,我们建立了一个单元监视器去,去监视SQL组上面的agent服务,一旦发现agent服务停止,自动通过net start恢复命令,将服务启动,这个是最基本的运维自动化。
第二种方式,则更加标准正规了一些,通过配置SCOM与SCO的集成,把SCOM的警报传入到SCO中,然后再由SCO通过不同的流程去自动化处理警报,比如说,在SCO中定义一个基本的流程,通过SCO与SCOM同步,去get scom中的警报,一旦发现事件ID为1001,就意味着服务已经停止,这时候,SCO会发一封邮件通知管理员,说服务停止了,等一会如果管理员没有去处理,SCO就会通过后续的标准活动,自动把服务启动,然后告诉管理员,服务已经通过自动化启动,通过SCO与SCOM集成,其实还可以配置很多的地方,比如说满足什么条件的警报再传入到SCO ,SCOM发生警报了,SCO要执行那些什么操作,在SCO中内置了很多个标准活动操作,可以执行很多丰富的自动化维护操作,也可以通过导入IP包,或者自己开发IP包来进行自动化任务。
最后一种方式,也是最正规的自动化处理机制,通过配置SCOM+SCSM+SCO的集成,SCSM与SCO的集成是通过SCO连接器,将SCO里面的Runbook文件夹同步到SCSM中作为Runbook活动模板,然后将自动化任务Runbook与对应的事件进行关联,达到的效果就是,一旦SCOM传入警报到SCSM 形成事件,SCSM首先查看事件是否有对应的Runbook活动,如果有则自动化解决,解决完成后同时关闭SCSM中的事件与SCOM中的警报,然后归档到SCSM的CMDB,如果对应事件没有绑定的Runbook活动,那么就需要管理员手动的去SCSM Portal处理问题。处理完成后,同样会归档至SCSM的CMDB,同时生成SCSM的知识库。
通过实施自动化,大家不难看出,其实SCO\SCOM\SCSM实现出来的是一种过程自动化,略微带有一些系统自动化的成分在,通过过程自动化,可以帮助运维人员处理一些基本的,重复性的运维工作。重要的一点是过程自动化并不意味之过程要简单化,没有规则化,而是意味着过程更加的自动化与标准化,实施自动化的目的是为了减轻运维人员工作量,同时也是为了按照标准化的操作步骤去做降低误操作。
6. 流程回顾
-
警报产生,通过WebConsole、Console、多通道告警机制获知警报
-
判断,如果是SCOM与SCO集成,SCO可以自动化解决,则自动解决警报
-
判断,如果是SCOM与SCSM和SCO集成,SCO可以自动化解决,则自动解决事件与警报
-
如果SCOM没有与其它SC组件集成,警报产生之后,由一线监控人员首先对警报进行基本判断,如果可以使用已有的SCOM知识库或者处理经验进行解决,即在一线监控人员等级就把警报解决关闭。
-
如果一线监控人员经过短暂的判断,认为事件短期内无法解决,则把警报分配给上一级工程师
-
上级工程师收到分配的警报,通过SCOM知识库以及自身经验进行解决,将警报置为已确认状态,如果解决,则将警报更新至已解决状态。
-
如果上级工程师无法解决事件警报,则继续把警报上升。
-
最终,不论是那一级或者说那个部门的工程师解决了警报,警报都会被置为已解决状态,同时归档到SCOM的数据仓库,供日后分析预测。
-
如果使用的是SCOM集成SCO的方式,通过SCO自动解决了SCOM警报,警报事件也会被归档至SCOM的数据仓库。
-
如果使用的是SCOM集成SCSM与SCO的方式,通过SCO自动解决了SCSM中的事件,事件会被归档至SCSM的CMDB数据库,同时也会归档至SCOM的数据仓库。
文章写到这里,衷心的希望各位读者可以看懂,并且可以找到能应用到已有的SCOM/SCSM/SCO上面的地方,可以看得出来,将SCOM+SCSM+SCO融合了之后,就是一套贯彻了ITIL基本思想的实践平台,提供了一套相对来说较完整的事件处理流程响应机制,虽然也许还有不够好的地方,但至少微软望这方面努力做了,在System Center中为ITIL提供了可能,笔者认为,监控运维平台或者说ITSM系统平台也好,如果要真正的在企业中进行落地,真正的改善IT服务管理,光有技术方面的实现还是不够的,一定要有相应的管理政策配合着推下去,才能真正的在企业中把ITIL进行落地,把私有云落地。