当前emr最新版本1.3.0没有presto组件,需要额外安装。本文介绍如何用E-MapReduce引导操作来安装presto 0.147版本。引导操作可以在集群创建时执行指定的脚本,详见: 帮助文档 。我们要执行的引导操作是安装配置jdk8,安装配置presto 0.147,安装presto cli(可选)。
准备脚本
上传安装jdk8的脚本
当前emr集群的jdk版本是1.7,由于presto 0.86以上版本最低jdk要求是jdk8,所以需要给集群安装jdk8。以后集群默认jdk版本升级到jdk8以后这一步可以省略。
本地创建一个installjdk8.sh文件,可以直接从oss下载,内容如下,通过oss控制台上传到oss合适位置,例如[yourbucket]/sh/installjdk8.sh。
#!/bin/sh
echo "download jdk8 from oss"
wget http://emr-agent-pack.oss-cn-hangzhou-internal.aliyuncs.com/bootstrap/presto/jdk-8u92-linux-x64.tar.gz
echo "decompress and mv"
tar -zxvf jdk-8u92-linux-x64.tar.gz
mv jdk1.8.0_92/ /usr/lib/jdk8
echo "set bashrc"
echo 'JAVA_HOME=/usr/lib/jdk8' >> /etc/bashrc
echo 'JRE_HOME=/usr/lib/jdk8/jre' >> /etc/bashrc
echo 'PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH' >> /etc/bashrc
echo 'CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib' >> /etc/bashrc
echo 'export JAVA_HOME JRE_HOME PATH CLASSPATH' >> /etc/bashrc这个脚本从E-MapReduce团队提供的一个开放读取的oss地址下载oracle jdk8,解压缩,并设置JAVAHOME环境变量。要注意环境变量的设置对已存在的进程和其子进程是不生效的,后面启动presto前,应 source /etc/bashrc
上传安装presto的脚本
presto的安装流程是下载软件压缩包,解压缩,下载coordinator和worker的默认配置,设置node id和主节点的ip。本地创建一个installpresto.sh文件,可以直接下载,内容如下,通过oss控制台上传到oss的合适位置,例如[yourbucket]/sh/installpresto.sh。
#!/bin/sh
echo "dowanload presto"
wget http://emr-agent-pack.oss-cn-hangzhou-internal.aliyuncs.com/bootstrap/presto/presto-server-0.147.tar.gz
tar -zxvf presto-server-0.147.tar.gz -C /usr/lib/
isMaster=`hostname --fqdn | grep emr-header-1`
if [ -n "$isMaster" ] ;then
echo getcoordinatorconfig
wget http://emr-agent-pack.oss-cn-hangzhou-internal.aliyuncs.com/bootstrap/presto/coordinator-conf.tar.gz
tar -zxvf coordinator-conf.tar.gz -C /usr/lib/presto-server-0.147
rm -rf coordinator-conf.tar.gz
else
echo getworkerconfig
wget http://emr-agent-pack.oss-cn-hangzhou-internal.aliyuncs.com/bootstrap/presto/worker-conf.tar.gz
tar -zxvf worker-conf.tar.gz -C /usr/lib/presto-server-0.147
rm -rf worker-conf.tar.gz
fi
echo "set node id"
echo node.id=`uuidgen` >> /usr/lib/presto-server-0.147/etc/node.properties
echo "set master ip"
masterIp=`cat /etc/hosts | grep emr-header-1|awk '{print $1}'`
echo $masterIp
sed -i "s/localhost/$masterIp/g" /usr/lib/presto-server-0.147/etc/config.properties
sed -i "s/localhost/$masterIp/g" /usr/lib/presto-server-0.147/etc/catalog/hive.properties
echo "set java home"
source /etc/bashrc
echo "start presto"
/usr/lib/presto-server-0.147/bin/launcher start下面详细讲解脚本的内容。
下载presto
echo "dowanload presto"
wget http://emr-agent-pack.oss-cn-hangzhou-internal.aliyuncs.com/bootstrap/presto/presto-server-0.147.tar.gz
tar -zxvf presto-server-0.147.tar.gz -C /usr/lib/从E-MapReduce团队提供的一个开放读取的oss地址下载presto 0.147,解压缩到指定目录。
下载默认配置
isMaster=`hostname --fqdn | grep emr-header-1`
if [ -n "$isMaster" ] ;then
echo getcoordinatorconfig
wget http://emr-agent-pack.oss-cn-hangzhou-internal.aliyuncs.com/bootstrap/presto/coordinator-conf.tar.gz
tar -zxvf coordinator-conf.tar.gz -C /usr/lib/presto-server-0.147
rm -rf coordinator-conf.tar.gz
else
echo getworkerconfig
wget http://emr-agent-pack.oss-cn-hangzhou-internal.aliyuncs.com/bootstrap/presto/worker-conf.tar.gz
tar -zxvf worker-conf.tar.gz -C /usr/lib/presto-server-0.147
rm -rf worker-conf.tar.gz
fi根据hostname是否包含指定字符串,分别下载coordinator和worker的默认配置文件到presto的安装目录。两组默认配置文件都包含相同的jvm.config,log.preperties,node.preperties, catalog/hive.preperties, catalog/jmx.preperties文件,区别是config.preperties里前者指定了coordinator=true。默认的配置内容如下所示,如果要修改配置内容,比如修改查询请求的最大内存,您可以额外提供一个脚本修改配置内容。
coordinator的config.preperties
oordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=9090
query.max-memory=5GB
query.max-memory-per-node=1GB
discovery-server.enabled=true
discovery.uri=http://localhost:9090worker的config.preperties
coordinator=false
http-server.http.port=9090
query.max-memory=5GB
query.max-memory-per-node=1GB
discovery.uri=http://localhost:9090后面的脚本会将localhost替换为coordinator的ip
node.preperties
node.environment=production
#node.id=5b47019c-a05c-42a5-9f9c-f17dbe27b42a
node.data-dir=/var/presto/data后面的脚本会用uuid设置node.id的值
jvm.config
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:OnOutOfMemoryError=kill -9 %plog.preperties
com.facebook.presto=INFOcatalog/jmx.properties
connector.name=jmxcatalog/hive.properties
connector.name=hive-hadoop2
hive.metastore.uri=thrift://localhost:9083
hive.config.resources=/etc/emr/hadoop-conf-2.6.0/core-site.xml, /etc/emr/hadoop-conf-2.6.0/hdfs-site.xml
hive.allow-drop-table=true后面的脚本会将localhost替换为metastore所在的master1节点的ip
动态修改配置
echo "set node id"
echo node.id=`uuidgen` >> /usr/lib/presto-server-0.147/etc/node.properties
echo "set master ip"
masterIp=`cat /etc/hosts | grep emr-header-1|awk '{print $1}'`
echo $masterIp
sed -i "s/localhost/$masterIp/g" /usr/lib/presto-server-0.147/etc/config.properties
sed -i "s/localhost/$masterIp/g" /usr/lib/presto-server-0.147/etc/catalog/hive.properties各进程的node id必须 不同,这里用uuid自动生成。
取master1节点的内网ip,设置为discovery和metastore的ip地址。
启动服务进程
echo "set java home"
source /etc/bashrc
echo "start presto"
/usr/lib/presto-server-0.147/bin/launcher start先加载bashrc环境变量,再启动presto服务进程。
上传安装presto cli的脚本(可选)
如果集群要安装presto cli,需要准备一个安装脚本。本地创建一个installprestocli.sh文件,或者直接下载,内容如下,通过oss控制台上传到oss的合适位置,例如[yourbucket]/sh/installprestocli.sh。
#!/bin/sh
wget http://emr-agent-pack.oss-cn-hangzhou-internal.aliyuncs.com/bootstrap/presto/presto-cli-0.147-executable.jar
mv presto-cli-0.147-executable.jar /root/presto
chmod +x /root/presto安装和验证
创建集群
参照 帮助文档 ,创建集群时点击添加引导操作,分别选择刚才上传的installsdk8,installpresto,installprestocli脚本,创建三个引导操作步骤。集群创建好后,通过集群详情页的引导/软件配置:无异常来确定引导操作执行成功
验证
cli验证
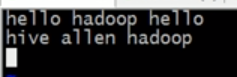
ssh用root用户 登陆master,输入·hive·进入hivecli,创建表并插入一条测试数据:
create table test(id int, name string);
insert into table test select count(id), "tom" from test;退出hive cli,进入presto cli./presto --server localhost:9090 --catalog hive --schema default
执行show tables能看见刚刚创建的表,执行select * from test;能查到刚才插入的数据。如果未显示,可能是还未同步,稍等一会
web验证
默认安全组只能访问集群的22端口,可以通过 本地端口转发来访问presto的web页面,本文配置设置的web地址是masterip:9090,可以查看已执行作业的详细信息。
也可以通过 安全组设置 公网入方向允许白名单Ip访问9090端口。由于公网暴露端口有安全隐患,ip白名单授权对象一定不能设置为0.0.0.0/0,而是应该只允许固定的ip白名单访问。如果没有固定ip,还是用前面端口转发的方式来访问。