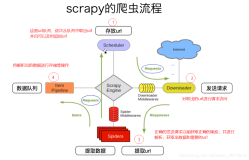
scrapy由下面几个部分组成
spiders:爬虫模块,负责配置需要爬取的数据和爬取规则,以及解析结构化数据
items:定义我们需要的结构化数据,使用相当于dict
pipelines:管道模块,处理spider模块分析好的结构化数据,如保存入库等
middlewares:中间件,相当于钩子,可以对爬取前后做预处理,如修改请求header,url过滤等
参考 :http://python.gotrained.com/scrapy-tutorial-web-scraping-craigslist/
https://doc.scrapy.org/en/latest/
本篇文档只写了常见的spiders例子,其余部分(items、pipelines、settings等)请参考后期blog
例1 在同一个页面上抓取内容 (抓取七月在线精品课程的名称、课程信息、开课时间):
|
1
2
3
4
5
6
7
8
9
10
11
|
import
scrapy
class
julyClassSpider(scrapy.Spider):
name
=
'julyclass'
start_urls
=
[
'https://www.julyedu.com/category/index'
]
def
parse(
self
,response):
for
classinfo
in
response.xpath(
'//div[@class="item"]/div/div'
):
classname
=
classinfo.xpath(
'a[1]/h4/text()'
).extract_first()
classdate
=
classinfo.xpath(
'a[1]/p[2]/text()'
).extract_first()
imageaddr
=
response.url
+
classinfo.xpath(
'a[1]/img[1]/@src'
).extract_first()
#print("classname:%s; classdate:%s; imageaddr: %s " %(classname,classdate,imageaddr))
yield
{
"classname"
:classname,
"classdate"
:classdate,
"imageaddr"
:imageaddr}
|
例2 在连续页面上抓取内容(抓取博客园前10页的精华贴):
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import
scrapy
import
re
class
cnblogsSpider(scrapy.Spider):
name
=
"cnblogs"
start_urls
=
[
'https://www.cnblogs.com/pick/'
+
str
(n)
+
'/'
for
n
in
range
(
1
,
10
)]
def
parse(
self
,response):
for
post
in
response.xpath(
'//div[@class="post_item_body"]'
):
title
=
post.xpath(
'h3/a/text()'
).extract_first()
href
=
post.xpath(
'h3/a/@href'
).extract_first()
pubdate
=
post.xpath(
'div[@class="post_item_foot"]/text()'
)[
1
].extract().strip()
pubdate
=
re.split(
' '
,pubdate)[
1
]
+
' '
+
re.split(
' '
,pubdate)[
2
]
comments
=
post.xpath(
'div[@class="post_item_foot"]/span[1]/a/text()'
).extract_first()
comments
=
re.split(
'\(|\)'
,comments)[
1
]
reads
=
post.xpath(
'div[@class="post_item_foot"]/span[2]/a/text()'
).extract_first()
reads
=
re.split(
'\(|\)'
,reads)[
1
]
#print(title,href,pubdate,comments,reads)
yield
{
'title'
:title,
'url'
:href,
'pubdate'
:pubdate,
'comments'
:comments,
'reads'
:reads}
|
运行:scrapy runspider scrapy2.py
urls是通过for拼接而成的list
例3 通过指定按钮(Next)连续抓取多个页面内容:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import
scrapy
import
re
class
cnblogsSpider(scrapy.Spider):
name
=
"cnblogs"
start_urls
=
[
'https://www.cnblogs.com/pick/'
]
def
parse(
self
,response):
for
post
in
response.xpath(
'//div[@class="post_item_body"]'
):
title
=
post.xpath(
'h3/a/text()'
).extract_first()
href
=
post.xpath(
'h3/a/@href'
).extract_first()
pubdate
=
post.xpath(
'div[@class="post_item_foot"]/text()'
)[
1
].extract().strip()
pubdate
=
re.split(
' '
,pubdate)[
1
]
+
' '
+
re.split(
' '
,pubdate)[
2
]
comments
=
post.xpath(
'div[@class="post_item_foot"]/span[1]/a/text()'
).extract_first()
comments
=
re.split(
'\(|\)'
,comments)[
1
]
reads
=
post.xpath(
'div[@class="post_item_foot"]/span[2]/a/text()'
).extract_first()
reads
=
re.split(
'\(|\)'
,reads)[
1
]
#print(title,href,pubdate,comments,reads)
yield
{
'title'
:title,
'url'
:href,
'pubdate'
:pubdate,
'comments'
:comments,
'reads'
:reads}
#print("========="+response.url+"==========")
url
=
response.xpath(
'//div[@class="pager"]/a[last()]/@href'
).extract()[
0
]
nexturl
=
response.urljoin(url)
yield
scrapy.Request(nexturl,callback
=
self
.parse)
|
通过“Next” 按钮获取下一页的url,然后分析.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
import
scrapy
import
re
class
humorSpider(scrapy.Spider):
name
=
'humor'
start_urls
=
[
'http://quotes.toscrape.com/tag/humor/page/1/'
]
def
parse(
self
,response):
for
humor
in
response.xpath(
'//div[@class="quote"]'
):
sentence
=
humor.xpath(
'span[1]/text()'
).extract_first()
author
=
humor.xpath(
'span[2]/small/text()'
).extract_first()
yield
{
'sentence'
:sentence,
'author'
:author}
next_url
=
response.xpath(
'//ul[@class="pager"]/li/a/@href'
).extract_first()
pattern
=
re.
compile
(r
'/'
)
if
next_url
is
not
None
and
pattern.split(next_url)[
-
2
]>pattern.split(response.url)[
-
2
]:
next_url
=
response.urljoin(next_url)
#print(next_url)
yield
scrapy.Request(next_url,callback
=
self
.parse)
|
例4 通过多个函数分析不同页面
scrapy startproject qqnews
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
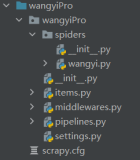
tree
.
|____qqnews
| |______init__.py
| |______pycache__
| |____items.py
| |____middlewares.py
| |____pipelines.py
| |____settings.py
| |____spiders
| | |______init__.py
| | |______pycache__
| | |____qqnews.py
|____scrapy.cfg
|
cd qqnews/spiders/
cat qqnews.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
import
scrapy
class
qqNewsSpider(scrapy.Spider):
name
=
'qqnews'
start_urls
=
[
'http://news.qq.com/'
]
def
parse(
self
,response):
for
url
in
response.xpath(
'//div[@class="text"]/em/a/@href'
).extract():
yield
scrapy.Request(url,callback
=
self
.parse_news)
def
parse_news(
self
,response):
try
:
title
=
response.xpath(
'//div[@class="hd"]/h1/text()'
).extract()[
0
]
type
=
response.xpath(
'//div[@class="a_Info"]/span[1]/a/text()'
).extract()[
0
]
source
=
response.xpath(
'//div[@class="a_Info"]/span[2]/a/text()'
).extract()[
0
]
time
=
response.xpath(
'//span[@class="a_time"]/text()'
).extract()[
0
]
print
(title,
type
,source,time)
except
:
print
(
"exception"
)
|
运行:scrapy crawl qqnews -o news.csv
本文转自 meteor_hy 51CTO博客,原文链接:http://blog.51cto.com/caiyuanji/1982130,如需转载请自行联系原作者